python+flask 分分钟完美解析阿里云日志
拿到了自己阿里云服务器的日志,对其需要进行处理。
class Read_Rizhi:
def __init__(self,filename):
self.filename=filename
def open_file(self):
try:
f = open(self.filename, 'r', encoding='utf-8')
resuly = {'code': 1, 'result': f}
except Exception as e:
resuly = {'code': 0, 'result': e}
return resuly
def read_line(self):
result=self.open_file()
if result['code']==0:
return {'read':'fail','relust':result['result']}
elif result['code']==1:
return {'read':'pass','relust':result['result'].readlines()}
else:
return {'read':'error','relust':'未知错误'}
def print_eachline(self,splist:str):
eachline=self.read_line()
if eachline['read']=='pass':
for rizhi in eachline['relust']:
ri=rizhi.split(splist)
print('请求ip:', ri[0])
print('请求时间磋:', ri[3])
print('请求方式:', ri[5])
print('请求路径:', ri[6])
print('请求协议:', ri[7])
print('返回状态吗:', ri[8])
elif eachline['read']=='fail':
print('读取失败!原因:%s'%eachline['relust'])
else:
print('读取异常')
if __name__=='__main__':
rizhi=Read_Rizhi('access.log')
rizhi.print_eachline(' ')
对日志解析进行封装,对日志的需求进行了自己的分析,

学了flask,你能不能吧这个日志给我放到flask 给一个前端的界面去展示呢,答案是没有问题的,对代码进行修改:
class Read_Rizhi:
def __init__(self,filename):
self.filename=filename
def open_file(self):
try:
f = open(self.filename, 'r', encoding='utf-8')
resuly = {'code': 1, 'result': f}
except Exception as e:
resuly = {'code': 0, 'result': e}
return resuly
def read_line(self):
result=self.open_file()
if result['code']==0:
return {'read':'fail','relust':result['result']}
elif result['code']==1:
return {'read':'pass','relust':result['result'].readlines()}
else:
return {'read':'error','relust':'未知错误'}
def print_eachline(self,splist:str):
eachline=self.read_line()
if eachline['read']=='pass':
ip_list=[]
for rizhi in eachline['relust']:
ri=rizhi.split(splist)
ip_list.append({'ip':ri[0],'time':ri[3],
'meth':ri[5],'path':ri[6],'xieyi':ri[7],
'code':ri[8]})
relust={'code':1,'result':ip_list}
elif eachline['read']=='fail':
relust = {'code':2, 'result':eachline['relust']}
else:
relust = {'code': 3, 'result':'读取异常'}
return relust
flask部分代码如下:
from flask import Flask,render_template
from jiexi import Read_Rizhi
app = Flask(__name__)
@app.route('/')
def hello_world():
rizhi = Read_Rizhi(r'C:\\Users\Administrator\Desktop\\untitled1\access.log')
relust = rizhi.print_eachline(' ')
if relust['code'] == 1:
f_list = relust['result']
return render_template('rizi.html',f_lis=f_list)
if __name__ == '__main__':
app.run()
rizi.html部分代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>阿里云日志分析</title>
</head>
<body>
<h1 style="text-align: center">阿里云日志分析</h1>
<table style="width: 60%;margin-top: 40px" border="1">
<tbody>
<tr>
<td>ip</td>
<td>时间</td>
<td>请求方式</td>
<td>请求路径</td>
<td>协议</td>
<td>状态码</td>
</tr>
{% for item in f_lis%}
<tr>
<td>{{ item.ip }}</td>
<td>{{ item.time }}</td>
<td>{{ item.meth }}</td>
<td>{{ item.path }}</td>
<td>{{ item.xieyi }}</td>
<td>{{ item.code }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</body>
</html>
启动flask模块,
访问:
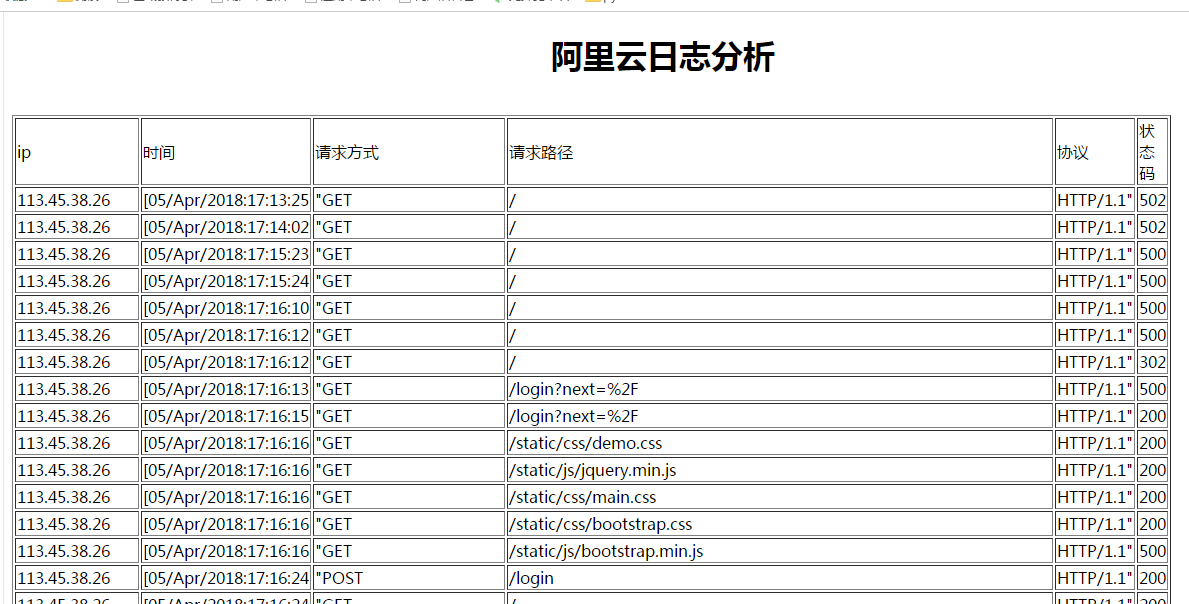
这样我们进一步优化就结束了,其实还可以进行优化,
这样还得需要我们进一步去的优化,部分切割还是不完善的。简单的切割,展示完成。十分钟就能实现的一个小功能。
python+flask 分分钟完美解析阿里云日志的更多相关文章
- flask项目部署到阿里云 ubuntu16.04
title: flask项目部署到阿里云 ubuntu16.04 date: 2018.3.6 项目地址: 我的博客 部署思路参考: Flask Web开发>的个人部署版本,包含学习笔记. 开始 ...
- 自建k8s集群日志采集到阿里云日志服务
自建k8s集群 的master 节点安装 logtail 采集工具 wget http://logtail-release-cn-hangzhou.oss-cn-hangzhou.aliyuncs.c ...
- 杂项-分布式-EDAS:深度解析阿里云EDAS服务
ylbtech-杂项-分布式-EDAS:深度解析阿里云EDAS服务 1.返回顶部 1. 深度解析阿里云EDAS服务 弹性伸缩 摘要: 第一种只适用于业务较少的情况,而在新业务不断增加的情况下,增加新应 ...
- 阿里云日志服务 ilogtail 卸载方法
之前使用阿里云日志服务,按照文档安装了ilogtail.后面不需要了,却找不到卸载文档.仔细查看ilogtail的安装脚本后,发现里面有卸载方法. wget http://logtail-releas ...
- ACK容器服务虚拟节点使用阿里云日志服务来收集业务容器日志
按照这篇博文的介绍,可以在ACK集群上通过Helm的方式部署虚拟节点,提升集群的弹性能力.现在,通过虚拟节点部署的ECI弹性容器实例也支持将stdout输出.日志文件同步到阿里云日志服务(SLS)进行 ...
- 阿里云日志服务SLS
前言: 刚入职实习了几天,我发现我的任务就是学习阿里云日志服务这块业务内容,这个功能和mysql一样,但是速度和视觉却是甩mysql这类数据库几条街. 当得知公司没人会这项技术后(在这之前我也没听过, ...
- 消费阿里云日志服务SLS
此文档只关心消费接入,不关心日志接入,只关心消费如何接入,可直接跳转到[sdk消费接入] SLS简介 日志服务: 日志服务(Log Service,简称 LOG)是针对日志类数据的一站式服务,在阿里巴 ...
- 用python发送短消息(基于阿里云平台)
新版短信接口在线测试页面:https://api.aliyun.com/new#/?product=Dysmsapi&api=SendSms¶ms={}&tab=DEM ...
- 阿里云日志服务采集自建Kubernetes日志(标准输出日志)
日志服务支持通过Logtail采集Kubernetes集群日志,并支持CRD(CustomResourceDefinition)进行采集配置管理.本文主要介绍如何安装并使用Logtail采集Kuber ...
随机推荐
- SEO优化策略
原文:http://www.upwqy.com/details/186.html 1 首先了解seo是什么 SEO是英文Search Engine Optimization的缩写,中文译为" ...
- JS中的闭包问题
一.闭包:在函数外也可使用局部变量的特殊语法现象 全局变量 VS 局部变量: 全局变量:优点:可共享,可重用; 缺点:在任意位置都可随意修改——全局污染 局部变量:优点:安全 缺点:不可共享,不可重用 ...
- python数据类型:序列(字符串,元组,列表,字典)
序列通常有2个特点: 1,可以根据索引取值 2,可以切片操作 字符串,元组,列表,字典,都可以看做是序列类型 我的操作环境:Ubuntu16.04+python2.7 一.字符串类型 >按索引获 ...
- IO模式和IO多路复用
网络编程里常听到阻塞IO.非阻塞IO.同步IO.异步IO等概念,总听别人装13不如自己下来钻研一下.不过,搞清楚这些概念之前,还得先回顾一些基础的概念. 1 基础知识回顾 注意:咱们下面说的都是Lin ...
- redis笔记总结之redis数据类型及常用命令
三.常用命令 3.1 字符串类型(string) 字符串类型是Redis中最基本的数据类型,一个字符串类型的键允许存储的数据的最大容量为512MB. 3.1.1 赋值与取值: SET key valu ...
- Lintcode208 Assignment Operator Overloading (C++ Only) solution 题解
[题目描述] Implement an assignment operator overloading method. Make sure that: The new data can be copi ...
- windows下 python3.5+tensorflow 安装
个人随笔,备忘参考 首先最近的tensorflow 对python3.5.x友好,我先装了Python3.6,查其他的一些博客说出现问题,后来重装3.5.0.下载用迅雷,超快. 安装比较简单,官网下载 ...
- RESTful接口设计原则和优点
RESTful架构优点: 前后端分离,减少流量 安全问题集中在接口上,由于接受json格式,防止了注入型等安全问题 前端无关化,后端只负责数据处理,前端表现方式可以是任何前端语言(android,io ...
- SignalR Self Host+MVC等多端消息推送服务(3)
一.概述 最近项目确实太忙,而且身体也有点不舒服,慢性咽炎犯了,昨晚睡觉时喘不过气来,一直没休息好,也没什么时间写博客,今天朋友问我什么时候能出web端的消息发送的文章时,我还在忙着改项目的事,趁着中 ...
- centos7上安装0penStack
centos7上安装0penStack author:headsen chen 2017-10-09 20:41:54 个人原创,欢迎转载,请注明作者,出去,否则依法追究责任 一,准备工作(配置ip ...