Spark RPC框架源码分析(三)Spark心跳机制分析
一.Spark心跳概述
前面两节中介绍了Spark RPC的基本知识,以及深入剖析了Spark RPC中一些源码的实现流程。
具体可以看这里:
这一节我们来看看一个Spark RPC中的运用实例--Spark的心跳机制。当然这次主要还是从代码的角度来看。
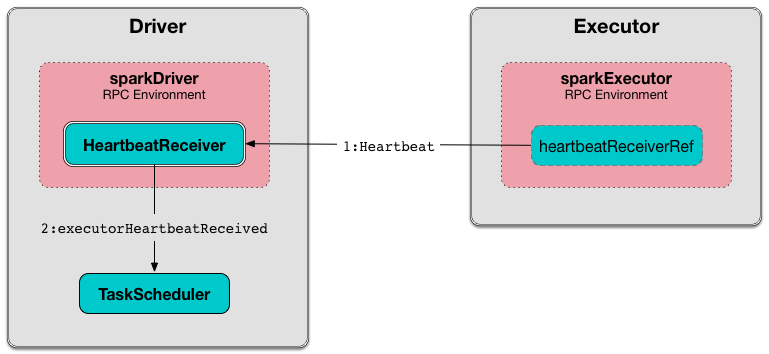
我们首先要知道Spark的心跳有什么用。心跳是分布式技术的基础,我们知道在Spark中,是有一个Master和众多的Worker,那么Master怎么知道每个Worker的情况呢,这就需要借助心跳机制了。心跳除了传输信息,另一个主要的作用就是Worker告诉Master它还活着,当心跳停止时,方便Master进行一些容错操作,比如数据转移备份等等。
与之前讲Spark RPC一样,我们同样分成两部分来分析Spark的心跳机制,分为服务端(Spark Context)和客户端(Executor)。
二. Spark心跳服务端heartbeatReceiver解析
我们可以发现,SparkContext中有关于心跳的类以及RpcEndpoint注册代码。
class SparkContext(config: SparkConf) extends Logging {
......
private var _heartbeatReceiver: RpcEndpointRef = _
......
//向 RpcEnv 注册 Endpoint。
_heartbeatReceiver = env.rpcEnv.setupEndpoint(HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
......
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
......
}
这里rpcEnv已经在上下文中创建好,通过setupEndpoint向rpcEnv注册一个心跳的Endpoint。还记得上一节中HelloworldServer的例子吗,在setupEndpoint方法中,会去调用Dispatcher创建这个Endpoint(这里就是HeartbeatReceiver)对应的Inbox和EndpointRef,然后在Inbox监听是否有新消息,有新消息则处理它。注册完会返回一个EndpointRef(注意这里有Refer,即是客户端,用来发送消息的)。
所以这一句
_heartbeatReceiver = env.rpcEnv.setupEndpoint(HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
就已经完成了心跳服务端监听的功能。
那么这条代码的作用呢?
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
这里我们要看上面那句val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode),它会根据master url创建SchedulerBackend和TaskScheduler。这两个类都是和资源调度有关的,所以需要借助心跳机制来传送消息。其中TaskScheduler负责任务调度资源分配,SchedulerBackend负责与Master、Worker通信收集Worker上分配给该应用使用的资源情况。
这里主要是告诉HeartbeatReceiver(心跳)的监听端,告诉它TaskScheduler这个东西已经设置好啦。HeartbeatReceiver就会回应你说好的,我知道的,并持有这个TaskScheduler。
到这里服务端heartbeatReceiver就差不多完了,我们可以发现,HeartbeatReceiver除了向RpcEnv注册并监听消息之外,还会去持有一些资源调度相关的类,比如TaskSchedulerIsSet。
三. Spark心跳客户端发送心跳解析
发送心跳发送在Worker,每个Worker都会有一个Executor,所以我们可以发现在Executor中发送心跳的代码。
private[spark] class Executor(
executorId: String,
executorHostname: String,
env: SparkEnv,
userClassPath: Seq[URL] = Nil,
isLocal: Boolean = false)
extends Logging {
......
// must be initialized before running startDriverHeartbeat()
//创建心跳的 EndpointRef
private val heartbeatReceiverRef = RpcUtils.makeDriverRef(HeartbeatReceiver.ENDPOINT_NAME, conf, env.rpcEnv)
......
startDriverHeartbeater()
......
/**
* Schedules a task to report heartbeat and partial metrics for active tasks to driver.
* 用一个 task 来报告活跃任务的信息以及发送心跳。
*/
private def startDriverHeartbeater(): Unit = {
val intervalMs = conf.getTimeAsMs("spark.executor.heartbeatInterval", "10s")
// Wait a random interval so the heartbeats don't end up in sync
val initialDelay = intervalMs + (math.random * intervalMs).asInstanceOf[Int]
val heartbeatTask = new Runnable() {
override def run(): Unit = Utils.logUncaughtExceptions(reportHeartBeat())
}
//heartbeater是一个单线程线程池,scheduleAtFixedRate 是定时执行任务用的,和 schedule 类似,只是一些策略不同。
heartbeater.scheduleAtFixedRate(heartbeatTask, initialDelay, intervalMs, TimeUnit.MILLISECONDS)
}
......
}
可以看到,在Executor中会创建心跳的EndpointRef,变量名为heartbeatReceiverRef。
然后我们主要看startDriverHeartbeater()这个方法,它是关键。
我们可以看到最后部分代码
val heartbeatTask = new Runnable() {
override def run(): Unit = Utils.logUncaughtExceptions(reportHeartBeat())
}
heartbeater.scheduleAtFixedRate(heartbeatTask, initialDelay, intervalMs, TimeUnit.MILLISECONDS)
heartbeatTask是一个Runaable,即一个线程任务。scheduleAtFixedRate则是java concurrent包中用来执行定时任务的一个类,这里的意思是每隔10s跑一次heartbeatTask中的线程任务,超时时间30s。
为什么到这里还是没看到heartbeatReceiverRef呢,说好的发送心跳呢?别急,其实在heartbeatTask线程任务中又调用了另一个方法,我们到里面去一探究竟。
private[spark] class Executor(
executorId: String,
executorHostname: String,
env: SparkEnv,
userClassPath: Seq[URL] = Nil,
isLocal: Boolean = false)
extends Logging {
......
private def reportHeartBeat(): Unit = {
// list of (task id, accumUpdates) to send back to the driver
val accumUpdates = new ArrayBuffer[(Long, Seq[AccumulatorV2[_, _]])]()
val curGCTime = computeTotalGcTime()
for (taskRunner <- runningTasks.values().asScala) {
if (taskRunner.task != null) {
taskRunner.task.metrics.mergeShuffleReadMetrics()
taskRunner.task.metrics.setJvmGCTime(curGCTime - taskRunner.startGCTime)
accumUpdates += ((taskRunner.taskId, taskRunner.task.metrics.accumulators()))
}
}
val message = Heartbeat(executorId, accumUpdates.toArray, env.blockManager.blockManagerId)
try {
//终于看到 heartbeatReceiverRef 的身影了
val response = heartbeatReceiverRef.askWithRetry[HeartbeatResponse](
message, RpcTimeout(conf, "spark.executor.heartbeatInterval", "10s"))
if (response.reregisterBlockManager) {
logInfo("Told to re-register on heartbeat")
env.blockManager.reregister()
}
heartbeatFailures = 0
} catch {
case NonFatal(e) =>
logWarning("Issue communicating with driver in heartbeater", e)
heartbeatFailures += 1
if (heartbeatFailures >= HEARTBEAT_MAX_FAILURES) {
logError(s"Exit as unable to send heartbeats to driver " +
s"more than $HEARTBEAT_MAX_FAILURES times")
System.exit(ExecutorExitCode.HEARTBEAT_FAILURE)
}
}
}
......
}
可以看到,这里heartbeatReceiverRef和我们上一节的例子,HelloworldClient类似,核心也是调用了askWithRetry()方法,这个方法是通过同步的方式发送Rpc消息。而这个方法里其他代码其实就是获取task的信息啊,或者是一些容错处理。核心就是调用askWithRetry()方法来发送消息。
看到这你就明白了吧。Executor初始化便会用一个定时任务不断发送心跳,同时当有task的时候,会获取task的信息一并发送。这就是心跳的大概内容了。
总的来说Spark心跳的代码也是比较杂的,不过这些也都是为了让设计更加高耦合,低内聚,让这些代码更加方便得复用。不过通过层层剖析,我们还是发现其实它底层就是我们之前说到的Spark RPC框架的内容!!
OK,Spark RPC三部曲完毕。如果你能看到这里那不容易呀,给自己点个赞吧!!
推荐阅读 :
从分治算法到 MapReduce
大数据存储的进化史 --从 RAID 到 Hadoop Hdfs
一个故事告诉你什么才是好的程序员
Spark RPC框架源码分析(三)Spark心跳机制分析的更多相关文章
- Spark RPC框架源码分析(一)简述
Spark RPC系列: Spark RPC框架源码分析(一)运行时序 Spark RPC框架源码分析(二)运行时序 Spark RPC框架源码分析(三)运行时序 一. Spark rpc框架概述 S ...
- Spark RPC框架源码分析(二)RPC运行时序
前情提要: Spark RPC框架源码分析(一)简述 一. Spark RPC概述 上一篇我们已经说明了Spark RPC框架的一个简单例子,Spark RPC相关的两个编程模型,Actor模型和Re ...
- 框架源码系列三:手写Spring AOP(AOP分析、AOP概念学习、切面实现、织入实现)
一.AOP分析 问题1:AOP是什么? Aspect Oriented Programming 面向切面编程,在不改变类的代码的情况下,对类方法进行功能增强. 问题2:我们需要做什么? 在我们的框架中 ...
- Java集合框架源码(三)——arrayList
1. ArrayList概述: ArrayList是List接口的可变数组的实现.实现了所有可选列表操作,并允许包括 null 在内的所有元素.除了实现 List 接口外,此类还提供一些方法来操作内部 ...
- Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend
本文是Scheduler模块源码分析的第二篇,第一篇Spark Scheduler模块源码分析之DAGScheduler主要分析了DAGScheduler.本文接下来结合Spark-1.6.0的源码继 ...
- 【原】Spark中Client源码分析(二)
继续前一篇的内容.前一篇内容为: Spark中Client源码分析(一)http://www.cnblogs.com/yourarebest/p/5313006.html DriverClient中的 ...
- 【原】Spark中Master源码分析(一)
Master作为集群的Manager,对于集群的健壮运行发挥着十分重要的作用.下面,我们一起了解一下Master是听从Client(Leader)的号召,如何管理好Worker的吧. 1.家当(静态属 ...
- Spark Scheduler模块源码分析之DAGScheduler
本文主要结合Spark-1.6.0的源码,对Spark中任务调度模块的执行过程进行分析.Spark Application在遇到Action操作时才会真正的提交任务并进行计算.这时Spark会根据Ac ...
- Apache Spark源码走读之6 -- 存储子系统分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 Spark计算速度远胜于Hadoop的原因之一就在于中间结果是缓存在内存而不是直接写入到disk,本文尝试分析Spark中存储子系统的构成,并以数据写入和数 ...
随机推荐
- Cenots7下安装运行.NET Core、MicroSoft SQL Server 2019 preview 的基础实践
一:概要 适应人群:.Net初学者.想了解.Net Core在Linux系统中的运行环境搭建者.初次且想在linux上应用.Net Core开发应用程序者: 基础技能:了解.NET基础开发技能者.有一 ...
- 学JAVA第二十天,接触异常处理,自定义异常
1.java.lang.NullPointerException(经常报)(运行时异常) 属于运行时异常,是编译器无法预知的异常,比如你定义了一个引用变量String a,但是你确没有用new关键字去 ...
- Sharepoint模态窗体(实战)
分享人:广州华软 无名 一. 前言 对SharePoint二次开发时,需要知道SharePoint有什么.没有什么,才能在开发过程中避免重复造轮子.SharePoint提供了许多开箱即用的功能,这次要 ...
- 【转载】 Sqlserver中查看自定义函数被哪些对象引用
Sqlserver数据库中支持自定义函数,包含表值函数和标量值函数,表值函数一般返回多个数据行即数据集,而标量值函数一般返回一个值,在数据库的存储过程中可调用自定义函数,也可在该自定义函数中调用另一个 ...
- windows系统以及linux系统的优缺点以及区别
一.Linux以及Windows系统的优缺点对比 Windows Linux 优点 Windows Server系统相对于其他服务器系统而言,极其易用,极大降低使用者的学习成本. Linux系统是 ...
- 判断HTML中的checkbox是否被选中
//合法性验证 function checkValidity() { var userNameCheck = $("#userNameCheck").attr('checked') ...
- 多标签分类的结果评估---macro-average和micro-average介绍
一,多分类的混淆矩阵 多分类混淆矩阵是二分类混淆矩阵的扩展 祭出代码,画线的那两行就是关键啦: 二,查看多分类的评估报告 祭出代码,使用了classicfication_report() 三,宏平均与 ...
- 线性回归预测PM2.5----台大李宏毅机器学习作业1(HW1)
一.作业说明 给定训练集train.csv,要求根据前9个小时的空气监测情况预测第10个小时的PM2.5含量. 训练集介绍: (1)CSV文件,包含台湾丰原地区240天的气象观测资料(取每个月前20天 ...
- Python-网络爬虫模块-requests模块之请求
Python原生库urllib库不太方便使用,本着"人生苦短, 我用Python"的珍惜生命精神, 基于urllib, 开发了一个对人类来说, 更好使用的一个库——requests ...
- 【Linux篇】--awk的使用
一.前述 awk是一个强大的文本分析工具.相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,(空格,制表符)为默认分隔符将每行切片 ...