selenium之元素定位-xpath
被测试网页的HTML代码
<html>
<body>
<div id="div1" style="text-align:center">
<img alt="div1-img1"
src="http://www.sogou.com/images/logo/new/sogou.png"
href="http://www.sogou.com">sogou image</img><br />
<input name="div1input">
<a href="http://www.sogou.com">搜狗搜索</a>
<input type="button" value="查询">
</div>
<br>
<div id="div2" style="text-align:center">
<img alt="div2-img2"
src="http://www.baidu.com/img/bdlogo.png"
href="http://www.baidu.com">baidu image</img><br />
<input name="div2input">
<a href="http://www.baidu.com">百度搜索</a>
<input type="button" value="查询">
</div>
</body>
</html>
被测试代码
使用上面的代码生成被测试网页,基于此网页来实现各种不同的页面元素的xpath定位方法
①xpath绝对路径定位元素
绝对路径表示页面元素在被测网页的HTML代码结构中,从根节点一层层地搜索到需要被定位的页面元素,绝对路径起始于正斜杠(/),每一步均被斜杠分割。
目的
在被测网页中查找第一个div标签下的“查询”按钮
xpath定位表达式:
/html/body/div/input[@value="查询"]
python定位语句:
element = driver.find_element_by_xpath('/html/body/div/input[@value="查询"]')
代码解释
上述xpath定位表达式从html dom树的根节点(html节点)开始逐层查找,最后定位到“查询”按钮节点。路径表达式“/”表示跟节点。
使用绝对路径定位页面元素的好处在于可以验证页面是否发生变化。如果页面结构发生变化,可以会造成原先有效的xpath表达式失败。使用绝对历经定位是十分脆弱的,因为即便页面代码结构只发生了微小的变化,也可能会造成原先有效的xpath定位表达式定位失败。因此,建议在自动化测试的定位实施环节中,优先考录使用后面将要介绍的相对路径进行定位。
②xpath相对路径定位元素
相对路径的每一步都根据当前节点集之中的节点来进行计算,起始于双//。
目的
在被测试网页中,查找第一个div标签下的“查询”按钮。
xpath定位表达式:
//div[@value='查询']
python定位语句:
element = driver.find_element_by_xpath('//div[@value='查询']')
代码解释
上述xpath定位表达式中//表示从匹配选择的当前节点开始选择文档中的节点,而不考虑特面的位置。input[@value="查询"]表示定位value值为“查询”两个字的input页面元素。
相对路径的xpath定位表达式更加简洁,不管页面发生了何种变化,只要input标签的value属性值没变,始终都可以定位到。推荐使用相对路径的xpath表达式,并且越简洁越好,可大大降低测试脚本中定位表达式的维护成本。
③xpath使用索引号定位元素
索引号表示某个被定位的页面元素在其父元素节点下的同名元素中的位置符号,需要从1开始。
目的
在被测网页中,查找第一个div标签下的“查询”按钮
xpath定位表达式:
//input[1]
python定位语句:
element=driver.find_element_by_xpath("//input[1]")
代码解释
索引号定位方式是根据该页面元素在页面中相同标签名之间出现的索引位置来进行定位。上述xpath定位表达式表示查找页面中第二个出现的input元素,即被测试页面上的“查询”按钮。
若在Firefox浏览器的插件(try xpath,新版本的firepath已经没有了!真的挺伤心的)中使用上述的定位方式你会发现定位到两个元素,两个div标签下的input都被定位到了,这和只查找第一个input元素相冲突,这是由于被测网页中两个div标签都包含了input标签,xpath再查找的时候把每个div节点都当作相同的起始层级开始查找,所以用//input[1]表达式会同时查找到两个div节点下的第一个input元素。如果再两div标签下还有嵌套的div,并且嵌套的div下也有input标签,也会被定位到。因此在使用索引号定位页面元素的时候,需要注意网页html代码中是否包含了多个层级完全相同的代码结构,若出现了这种情况,就需要修改定位表达式,以确保自动化测试脚本中使用的定位表达式能唯一定位所需要的元素。如果想同时定位多个相同的input页面元素可以使用下面的python语句:
elementList=driver.find_elements_by_xpath("//input[1]")
将定位的多个元素存储到list中,然后根据list索引号获取想要的页面元素。但如果发现页面元素会经常增加或减少,就不建议使用索引号定位方式。
基于实例中的被测网页,下面给出更多的通过索引号定位的实例
| 预期定位圆面的元素 | 定位表达式实例 | 使用的属性值 |
| 定位第二个div下的超链接 | //div[last()]/a | div[last()]表示最后一个div元素,last()函数获取的是指定元素的最后的索引号 |
| 定位第一个div中的超链接 | //div[last()-1]/a | div[last()-1]表示倒数第二个div元素 |
| 定位最前面一个属于div元素的子元素中的input元素 | //div/input[position()<2] | position()函数获取当前元素input的位置序号 |
④xpath使用页面元素的属性值定位元素
在定位页面元素的时候 ,经常会遇到各种复杂的结构的被测试网页,并且很多页面元素也没有设计ID,Name等属性,同时又不想使用绝对路径或索引号来定位页面元素,但是发现要被要被定位的页面元素拥有某些固定不变的属性及属性值,此时推荐属性定位方式来定位页面元素。
目的
定位被测网页中的第一张img元素
xpath定位表达式:
//input[@alt='div1-img1']
python定位语句:
img = driver.find_element_by_xpath("//input[@alt='div1-img1']")
代码解释
表达式使用了相对路径再结合元素拥有的特定属性方法进行定位,定位元素img的属性是“alt”,值为“div1-img1”,使用@符号指明后面接的是属性,并同属性及属性值一起写到元素后的方括号中。
被测试网页的元素通常会包含各种各样的属性值,并且很多属性值具有唯一性。若能确认属性值不常变并且唯一,强烈建议使用相对路径再结合属性的定位方式来编写xpath定位方式,使用此方法可以解决99%的页面元素定位问题。下面给出更多的定位实例。
| 预定位的页面元素 | 定位表达式实例 | 使用的属性值 |
| 定位页面的第一张图片 | //img[@href=""http://www.sogou.com] | 使用img标签的属性href值 |
| 定位第二个div中第一个input输入框 | //div[@id="div2"]/input[@name="div2input"]或者//inuput[@name="div2input"] |
使用div变迁的name值 使用input标签的name属性值 |
| 定位第一个div中的第一个链接 | //div[@id="div1"]/a[@href="http://www.sogou.com"] |
使用div标签的ID属性值 使用a标签的href属性值 |
| 定位页面的查询按钮 | //input[@type="button"] | 使用input标签的type属性值 |
⑤xpath使用模糊属性值定位元素
模糊属性值定位方式表示使用属性值的一部分内容定位。在自动化测试的实施过程中,常常会遇到页面元素的属性值是动态生成的,也就是说每次访问属性值都不一样,此类页面元素会加大定位难度,使用模糊属性值定位方式可以解决一部分类似难题,但前提是属性值中有一部分内容是不变的,xpath提供了一些可以实现模糊属性值的定位需求的函数。
| xpath函数 | 定位表达式实例 | 表达式解释 |
| starts-with(str1,str2) | //img[starts-with(@alt,"div1")] | 查找属性alt的属性值以div1关键字开始的页面元素 |
| contains(str1,str2) | //img[contains(@alt,"img")] | 查找alt属性的属性值包含img关键字的页面元素,只要包含即可,无需考虑位置 |
contains函数属于xpath的高级用法,使用场景比较多,尽管页面元素的属性值经常变化,但只要其属性值有几个固定不变的关键词,就可以使用cotains函数进行定位。
⑥xpath使用xpath轴定位元素
轴可以定义相对于当前节点的节点集。使用xpath定位方式可以根据再文档树中的元素相对位置关系进行页面元素定位。先找到一个相对好定位的元素,让它作为轴,根据它和要定位元素间的相对位置关系进行定位,可解决一些点定位难的问题。
我们根据被测页面的代码来画一下结构图:
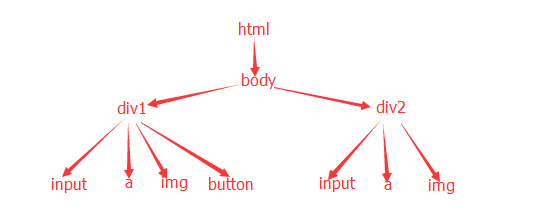
xpath常用轴关键字:
| xpath轴关键字 | 轴的含义说明 | 定位表达式实例 | 表达式解释 |
| parent | 选择定钱节点的上一层父节点 | //img[@alt='div2-img2']/parent::div | 查找到属性alt的属性值为div2-img2的img元素,并基于该img元素的位置找到它上一级的div页面元素 |
| child | 选择当前节点的下层所有子节点 | //div[@id='div1']/child::img | 查找到ID属性值为div1的div元素,并基于div的位置找到它下层节点中的img页面元素 |
| ancestor | 选择当前节点所有上层节点 | //img[@alt='div2-img2']/ancestor::div | 查找到属性alt的属性值为div2-img2的img元素,并基于该img元素的位置找到它上级的div元素 |
| descendant | 选择当前节点所有下层的节点(子,孙等) | //div[@name='div2']/descendant::img | 查找到属性name的属性值为div2的div元素,并基于该元素的位置找到它下级所有节点中的img页面元素 |
| following | 选择当前节点之后显示的所有节点 | //div[@id='div1']/following::img | 查找到ID属性值为div1的div页面元素,并基于div的位置找到它后面节点中的img页面元素 |
| following-sibling | 选择当前节点后续所有兄弟节点 | //a[@href='http://www.sogou.com']/following-sibling::input | 查找到链接地址为http://www.sogou.com的链接页面元素a,并基于链接的位置找到它后续兄弟节点中的input页面元素 |
| preceding | 选择当前节点前面的所有节点 | //img[@alt='div2-img2']/preceding::div | 查找到属性alt的属性值为div2-img2的图片页面元素img,并基于图片的位置找到它前面节点中的div页面元素 |
| preceding-sibling | 选择当前节点前面的 所有兄弟节点 | //input[@value='查询']/preceding-sibling::a[1] | 查找到value属性值为“查询”的输入框页面元素,并基于该输入框的位置找到他前面同级节点中的第一个链接页面元素 |
有时候我们会再轴后面加一个星号*, 便是通配符,如://input[@value="查询"]/preceding::*,它表示查找属性value的值为“查询”的输入框input元素前面所有的同级元素,但不包括input元素本身
⑦xpath使用页面元素的文本定位元素
通过text()函数可以定位到元素文本包含某些关键内容的页面元素。
xpath表达式:
1.//a[text()="搜狗搜索"] 2.//a[.="搜狗搜索"] 3.//a[contains(.,"百度")] 4.//a[contains(text(),'百度')] 5.//a[contains(text(),"百度")]/preceding::div 6.//a[contains(. , "百度")]/..
python定位语句:
sogou_a=driver.find_element_by_xpath('//a[text()="搜狗搜索"]')
sogou_a=driver.find_element_by_xpath('//a[.="搜狗搜索"]')
baidu_a=driver.find_element_by_xpath('//a[contains(.,"百度")]')
baidu_a=driver.find_element_by_xpath('//a[contains(text(),'百度')]')
div=driver.find_element_by_xpath('//a[contains(text(),"百度")]/preceding::div')
div=driver.find_element_by_xpath('//a[contains(. , "百度")]/..')
代码解释
xpath表达式1和表达式2等价,都是查找文本内容为“搜狗搜索”的链接页面元素,使用的是精准匹配方式,也就是说文本内容必须完全匹配,不能多一个字也不能少一个字。第二个xpath语句中使用了以个点. 这里的点等价于text(),都指代的是当前节点的文本内容
xpath表达式3和表达式4等价,都是查找文本内容包含“百度”关键字的链接页面元素,使用的是模糊匹配方式,即可以根据部分文本关键字进行匹配。
xpath表达式5和表达式6等价,都是查找文本内容包含“百度”关键字的链接页面元素a的上层父元素div,6最后使用了两个点。。,它表示选取当前节点的父节点,等价于preceding::div。
使用文本内容匹配模式进行定位,为定位复杂元素又提供了一种强大的定位模式,再遇到定位困难时,可以优先考虑使用此方式进行定位。建议大家对此定位方式进行练习,一边做到随意定位页面的任意元素。
总结
好了,以上差不多就时xpath所有的定位方式了,大家可以根据实际工作中遇到的不同问题选择不同的定位方式。 如果文中有错误请留言指出,大家一起学习一起进步,欢迎多多指教!最后再说一句,实践出真知,多看多学多练多写,没有谁出生就是大牛,得经过漫长的岁月慢慢挤奶才变成大牛!哈哈
selenium之元素定位-xpath的更多相关文章
- python3 selenium webdriver 元素定位xpath定位骚操作
源文http://www.cnblogs.com/qingchunjun/p/4208159.html By.xpath() 这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元 ...
- 《手把手教你》系列技巧篇(十四)-java+ selenium自动化测试-元素定位大法之By xpath上卷(详细教程)
1.简介 按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍定位倒数二个方法:By xpath.xpath 的定位方法, 非常强大. 使用这种方法几乎可以定位到页面上的任意元素. ...
- 《手把手教你》系列技巧篇(十五)-java+ selenium自动化测试-元素定位大法之By xpath中卷(详细教程)
1.简介 按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍定位倒数二个方法:By xpath.xpath 的定位方法, 非常强大. 使用这种方法几乎可以定位到页面上的任意元素. ...
- 《手把手教你》系列技巧篇(十六)-java+ selenium自动化测试-元素定位大法之By xpath下卷(详细教程)
1.简介 按宏哥计划,本文继续介绍WebDriver关于元素定位大法,这篇介绍定位倒数二个方法:By xpath.xpath 的定位方法, 非常强大. 使用这种方法几乎可以定位到页面上的任意元素. ...
- 【基础】selenium中元素定位的常用方法(三)
一.Selenium中元素定位共有八种 id name className tagName linkText partialLinkText xpath cssSelector 其中前六种都比较简单, ...
- 页面元素定位 XPath 简介
页面元素定位 XPath 简介 本文所说的 Xpath 是用于 Selenium 自动化测试所使用到的,是针对XHTML网页而言的一种页面元素的定位表示法. XPath 背景 XPath即为XML路径 ...
- selenium界面元素定位
一. Selenium界面元素定位 本文元素定位以das2为例 #导入包 from selenium import webdriver #打开火狐驱动 driver=webdriver ...
- python+selenium遇到元素定位不到的问题,顺便记录一下自己这次的错误(报错selenium.common.exceptions.NoSuchElementException)
今天在写selenium一个发送邮件脚本时,遇到一些没有找到页面元素的错误.经过自己反复调试,找原因百度,终于解决了.简单总结一下吧,原因有以下几点: 一:Frame控件嵌套,.Frame/Ifram ...
- Selenium Web元素定位方法
Selenium是用于Web应用测试的自动化测试框架,可以实现跨浏览器和跨平台的Web自动化测试.Selenium通过使用WebDriver API来控制web浏览器,每个浏览器都都有一个特定的Web ...
随机推荐
- Redis Sentinel集群双机房容灾实施步骤
概要目标防止双机房情况下任一个机房完全无法提供服务时如何让Redis继续提供服务.架构设计A.B两机房,其中A机房有一Master一Slave和两个Sentinel,B机房只有2个Sentinel,如 ...
- caffe安装教程(Ubuntu14+GPU+pycaffe+anaconda2)
caffe安装教程 本文所使用的底层环境配置:cuda8.cudnn6.OpenCV2.4.5.anaconda2(Python2.7).如使用其他版本的环境,如cuda,可安装自己的版本,但须在相应 ...
- 基于python语言的tensorflow的‘端到端’的字符型验证码识别源码整理(github源码分享)
基于python语言的tensorflow的‘端到端’的字符型验证码识别 1 Abstract 验证码(CAPTCHA)的诞生本身是为了自动区分 自然人 和 机器人 的一套公开方法, 但是近几年的 ...
- 微信公众平台网页登录授权多次重定向跳转,导致code使用多次问题
背景:微信网站开发 昨天我负责的一个项目忽然出现了一个十分诡异的bug,进行微信授权登录的时候请求code的时候安卓手机会多次重定向调转我的接口接收code的接口(redirect_uri 微信请求调 ...
- 【Android Studio安装部署系列】六、在模拟器上运行项目
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 概述 在模拟器上运行项目的步骤.不过在实际开发中,一般不采用这种方式,因为影响电脑的运行,所以一般使用真机运行项目. 运行项目 创建模拟器 ...
- .net core自定义高性能的Web API服务网关
网关对于服务起到一个统一控制处理的作用,也便于客户端更好的调用:通过网关可以灵活地控制服务应用接口负载,故障迁移,安全控制,监控跟踪和日志处理等.由于网关在性能和可靠性上都要求非常严格,所以针对业务需 ...
- 『练手』004 Laura.SqlForever如何扩展 导航栏 工具栏 右键菜单 插件
004 Laura.SqlForever如何扩展 导航栏 工具栏 右键菜单 插件 导航栏 插件扩展 比如下图的 窗口 > 关闭所有文档 这个导航栏: 在 任何程序集,任何命名空间,任 ...
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- 研究windows下SVN备份及还原恢复方案
windows下SVN备份方案 备份策略 svn备份一般采用三种方式: 1)svnadmin dump 2)svnadmin hotcopy 3)svnsync. 注意,svn备份不宜采用普通的 ...
- 从PRISM开始学WPF(四)Prism-Module-更新至Prism7.1
0x4Modules Modules是能够独立开发.测试.部署的功能单元,Modules可以被设计成实现特定业务逻辑的模块(如Profile Management),也可以被设计成实现通用基础设施或服 ...