Spark学习之编程进阶总结(二)
五、基于分区进行操作
基于分区对数据进行操作可以让我们避免为每个数据元素进行重复的配置工作。诸如打开数据库连接或创建随机数生成器等操作,都是我们应当尽量避免为每个元素都配置一次的工作。Spark 提供基于分区的 map 和 foreach ,让你的部分代码只对 RDD 的每个分区运行一次,这样可以帮助降低这些操作的代价。
当基于分区操作 RDD 时,Spark 会为函数提供该分区中的元素的迭代器。返回值方面,也返回一个迭代器。除 mapPartitions() 外,Spark 还有一些别的基于分区的操作符,列在了表中。

1、mapPartitions
与map类似,不同点是map是对RDD的里的每一个元素进行操作,而mapPartitions是对每一个分区的数据(迭代器)进行操作,具体可以看上面的表格。下面同时用map和mapPartitions实现WordCount,看一下mapPartitions的用法以及与map的区别。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别 val input = sc.parallelize(Seq("Spark Hive hadoop", "Hadoop Hbase Hive Hbase", "Java Scala Spark"))
val words = input.flatMap(line => line.split(" "))
val counts = words.map(word => (word, 1)).reduceByKey { (x, y) => x + y }
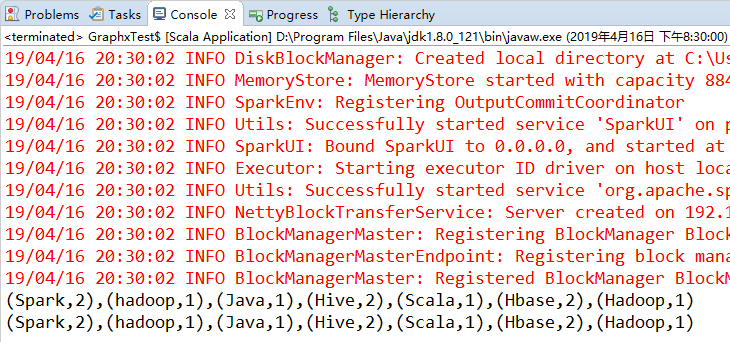
println(counts.collect().mkString(","))
val counts1 = words.mapPartitions(it => it.map(word => (word, 1))).reduceByKey { (x, y) => x + y }
println(counts1.collect().mkString(",")) }
}
2、mapPartitionsWithIndex
和mapPartitions一样,只是多了一个分区的序号,下面的代码实现了将Rdd的元素数字n变为(分区序号,n*n)。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别 val rdd = sc.parallelize(1 to 10, 5) // 5 代表分区数
val res = rdd.mapPartitionsWithIndex((index, it) => {
it.map(n => (index, n * n))
})
println(res.collect().mkString(" ")) }
}

3、foreachPartitions
foreachPartitions和foreach类似,不同点也是foreachPartitions基于分区进行操作的。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
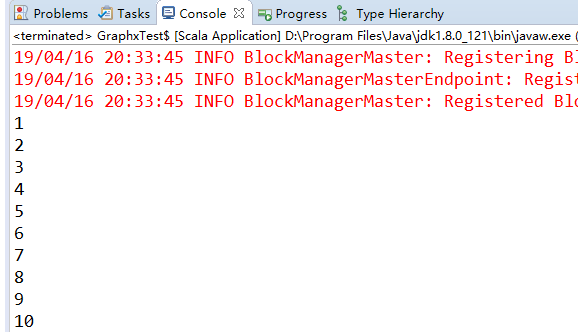
val rdd = sc.parallelize(1 to 10, 5) // 5 代表分区数
rdd.foreachPartition(it => it.foreach(println)) }
}
六、与外部程序间的管道
Spark 提供了一种通用机制,可以将数据通过管道传给用其他语言编写的程序,比如 R 语言脚本。
Spark 在 RDD 上提供 pipe() 方法。Spark 的 pipe() 方法可以让我们使用任意一种语言实现 Spark 作业中的部分逻辑,只要它能读写 Unix 标准流就行。通过 pipe() ,你可以将 RDD 中的各元素从标准输入流中以字符串形式读出,并对这些元素执行任何你需要的操作,然后把结果以字符串的形式写入标准输出——这个过程就是 RDD 的转化操作过程。这种接口和编程模型有较大的局限性,但是有时候这恰恰是你想要的,比如在 map 或filter 操作中使用某些语言原生的函数。
有时候,由于你已经写好并测试好了一些很复杂的软件,所以会希望把 RDD 中的内容通过管道交给这些外部程序或者脚本来进行处理并重用。很多数据科学家都用 R写好的代码 ,可以通过pipe() 与 R 程序进行交互。
七、数值RDD的操作
Spark 的数值操作是通过流式算法实现的,允许以每次一个元素的方式构建出模型。这些统计数据都会在调用 stats() 时通过一次遍历数据计算出来,并以 StatsCounter 对象返回。表列出了 StatsCounter 上的可用方法。

如果你只想计算这些统计数据中的一个,也可以直接对 RDD 调用对应的方法,比如 rdd.mean() 或者 rdd.sum() 。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("test").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val rdd = sc.parallelize(List(1,2,3,4))
val res = rdd.stats
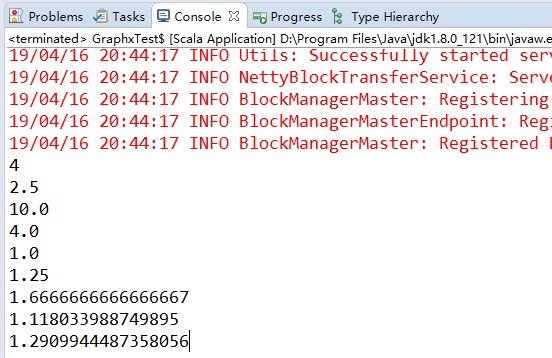
println(res.count) // 4 统计元素个数
println(res.mean) // 2.5 平均值
println(res.sum) // 10 总和
println(res.max) // 4 最大值
println(res.min) // 1 最小值
println(res.variance) // 1.25 方差
println(res.sampleVariance) //1.667 采样方差
println(res.stdev) // 1.11803 标准差
println(res.sampleStdev) //1.29099 采样标准差
}
}
这篇博文主要来自《Spark快速大数据分析》这本书里面的第六章,内容有删减,还有关于本书的一些代码的实验结果。
Spark学习之编程进阶总结(二)的更多相关文章
- Spark学习之编程进阶——累加器与广播(5)
Spark学习之编程进阶--累加器与广播(5) 1. Spark中两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable).累加器对信息进行聚合,而广播变 ...
- Spark学习之编程进阶总结(一)
一.简介 这次介绍前面没有提及的 Spark 编程的各种进阶特性,会介绍两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable).累加器用来对信息进行聚合 ...
- Java多线程编程——进阶篇二
一.线程的交互 a.线程交互的基础知识 线程交互知识点需要从java.lang.Object的类的三个方法来学习: void notify() 唤醒在此对象监视器上等待的单个 ...
- Spark学习之路 (十二)SparkCore的调优之资源调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 一.概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都 ...
- Spark学习之路(十二)—— Spark SQL JOIN操作
一. 数据准备 本文主要介绍Spark SQL的多表连接,需要预先准备测试数据.分别创建员工和部门的Datafame,并注册为临时视图,代码如下: val spark = SparkSession.b ...
- Spark学习之路 (十二)SparkCore的调优之资源调优[转]
概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如 ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark函数式编程进阶
函数式编程进阶 1.函数和变量一样作为Scala语言的一等公民,函数可以直接复制给变量: 2.函数更长用的方式是匿名函数,定义的时候只需要说明输入参数的类型和函数体即可,不需要名称,但是匿名函数赋值给 ...
- python学习_数据处理编程实例(二)
在上一节python学习_数据处理编程实例(二)的基础上数据发生了变化,文件中除了学生的成绩外,新增了学生姓名和出生年月的信息,因此将要成变成:分别根据姓名输出每个学生的无重复的前三个最好成绩和出生年 ...
随机推荐
- 推荐两个国外公共CDN服务
最近这个国家信息安全问题舆论形势又见紧张,Google的访问又被强力堵截,谷歌的公共CDN也顺带被波及,像AngularJS这样的前卫js库,国内几大公共CDN服务都不提供支持.国外目前两大第三方公共 ...
- C 四则运算表达式解析器
下载实例:http://www.wisdomdd.cn/Wisdom/resource/articleDetail.htm?resourceId=1074 程序主要包括:基础结构定义.词法分析.语法分 ...
- python3学习笔记1---引用http://python3-cookbook.readthedocs.io/zh_CN/latest/
2018-02-28数据结构和算法(1) 1.1解压序列赋值给多个变量: 任何的序列(或者是可迭代对象)可以通过一个简单的赋值语句解压并赋值给多个变量. 唯一的前提就是变量的数量必须跟序列元素的数量是 ...
- RDC去省赛玩前の日常训练 Chapter 2
2018.4.9 施展FFT ing! 马上就要和前几天学的斯特林数双剑合璧了!
- python的统一编码规范
请注意这一点:没有编码规范的代码没有阅读价值,也更谈不上复用. 目前业界比较流行的Python的编码规范目前主要有PEP8的编程.Google的编码风格.Python Guide和Pocoo Styl ...
- 专业、稳定的微信域名被封检测API平台!
裂变程序最佳配套api,实时检测域名在微信中是否被封,防止见红 还在手动测试域名在微信是否可用?你OUT了! API文档:最简单的GET接口调用方式 API响应:毫秒级响应效率,100%准确率 AP ...
- JavaScript (一、ECMAScript )
一.js简介和变量 1.JavaScript的概述组成和特点 a.JavaScript 是脚本语言,是世界上最流行的编程语言,这门语言可用于 HTML 和 web,更可广泛 用于服务器.PC.笔记本电 ...
- 火狐兼容window.event.returnValue=false;
火狐中window.event是未定义的,可用e.preventDefault();替代window.event.returnValue=false; 直接上图
- 【转】Javascript错误处理——try…catch
无论我们编程多么精通,脚本错误怎是难免.可能是我们的错误造成,或异常输入,错误的服务器端响应以及无数个其他原因. 通常,当发送错误时脚本会立刻停止,打印至控制台. 但try...catch语法结构可以 ...
- https://doc.opensuse.org/projects/kiwi/doc/
KIWI 是用于创建操作系统映像的系统.映像是带有一个文件的目录,该文件包含操作系统.其应用程序与配置.操作系统的文件系统结构.可能的附加元数据,以及(取决于映像类型)磁盘几何属性和分区表数据.通过 ...