TensorFlow之DNN(二):全连接神经网络的加速技巧(Xavier初始化、Adam、Batch Norm、学习率衰减与梯度截断)
在上一篇博客《TensorFlow之DNN(一):构建“裸机版”全连接神经网络》中,我整理了一个用TensorFlow实现的简单全连接神经网络模型,没有运用加速技巧(小批量梯度下降不算哦)和正则化方法,通过减小batch size,也算得到了一个还可以的结果。
那个网络只有两层,而且MINIST数据集的样本量并不算太大。如果神经网络的隐藏层非常多,每层神经元的数量巨大,样本数量也巨大时,可能出现三个问题:
一是梯度消失和梯度爆炸问题,导致反向传播算法难以进行下去;
二是在如此庞大的网络中进行训练,速度会非常缓慢;
三具有数百万个参数的模型可能造成过拟合。
对于梯度消失的问题,我们可以通过合理地初始化权重(Xavier初始化或He初始化)、选择更好的激活函数(relu函数)和使用Batch Normalization来缓解,对于梯度爆炸问题,可以用梯度截断的办法来解决。理论部分我已经整理过了,不嫌弃的话请看《深度学习之激活函数》和《深度学习之Batch Normalization》。
对于训练速度太慢这个问题,可以用梯度下降的优化算法,调整损失函数的梯度(比如Momentum)和学习率(比如RMSProp),或者使用学习率衰减,来加快模型的训练。理论部分可以看《深度学习之优化算法》。
对于可能造成过拟合的问题,可以用Dropout、早停、L1和L2正则化和数据增强等方法,来缓解过拟合现象。理论部分可以看《深度学习之正则化方法》。
内容还是比较多的,这篇博客先整理如何用TensorFlow实现解决梯度消失、梯度爆炸以及训练速度太慢等问题的方法,下一篇博客再整理用TensorFlow实现神经网络的正则化方法。
好,接下来进入到代码环节。
一、解决梯度消失
1、Xavier初始化和He初始化
为了不让梯度在正向传播和反向传播时消失或者爆炸,也就是要保持梯度稳定,那么我们需要神经网络每层的输入值的方差等于其输出值的方差,而用Xavier初始化和He初始化可以近似地做到这一点。
(1)Xavier初始化是针对于Sigmoid函数(也叫Logistic函数)和Tanh函数的初始化方法,有两套方案:
一套是用高斯分布来初始化权重,对于Sigmoid函数的权重,使其服从如下分布,也就是服从一个均值为0的正态分布,其方差σ2是扇入(输入值的维度)和扇出(输出值的维度)的平均值的倒数。
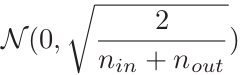 另一套是用均匀分布来初始化权重,对于Sigmoid函数的权重,使其服从[-r , r]上的均匀分布。而r满足:
另一套是用均匀分布来初始化权重,对于Sigmoid函数的权重,使其服从[-r , r]上的均匀分布。而r满足:

Tanh函数的权重初始化见下图(第二行)。
(2)He初始化是针对ReLU函数的权重初始化方法,同样可以用高斯分布或均匀分布来做。其分布的参数如下所示(第三行)。

TensorFlow中提供了 tf.variance_scaling_initializer()这个函数来做He初始化,默认是只考虑扇入(也就是ninputs),而不考虑扇出,如果想要像上面的公式那样用扇入和扇出的平均值来初始化,就要传入mode="FAN_AVG"这个参数。
当然我有个疑问,那就是He初始化是用在第一个隐藏层还是所有隐藏层呢?如果是用在所有的隐藏层,那么刚学习到的参数就被重新初始化了,那不就杨白劳了?不过看书中的示例代码,是在所有隐藏层上进行He初始化。
好,这里只列出关键的代码,稍候我们就用He初始化来初始化权重,应用到MINIST数据集的模型训练中。
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
he_init = tf.variance_scaling_initializer(mode =“FAN_AVG”)
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
kernel_initializer=he_init, name="hidden1")
2、选择更好的损失函数
Sigmoid函数和Tanh函数是两端饱和型激活函数,容易产生梯度消失问题。而RuLU函数在正值部分的导数都是1,不会梯度饱和,而且近似于线性计算,计算速度贼快,因此隐藏层使用RuLU激活函数是标配。
可是RuLE也有不争气的地方,称为死亡ReLU问题,意思是由于ReLU函数在负值区间的梯度为0,那么在训练过程中,当神经元输入的加权和为负值时,这个激活函数会输出0。然后该神经元就死亡了,无法抢救,永远沉睡,永远输出0。这实在是个悲伤的故事。
于是就出现了几种ReLU函数的变体:LeakyReLU、ELU、SELU。
(1)LeakyReLU
LeakyReLU函数定义为max(γx, x),在输入值x < 0时,也能保持一个很小的梯度γ,当神经元非激活时也能更新参数,就像是神经元在峡谷中被妲己的二技能暂时眩晕了,在以后的迭代中还能醒过来继续carry。这个超参数γ一般设定为0.01。
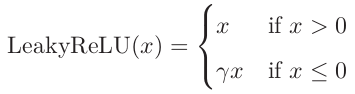
遗憾的是TensorFlow中没有定义这个激活函数,我们可以自己写一个。
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
def leaky_relu(z, name=None):
return tf.maximum(0.01 * z, z, name=name) hidden1 = tf.layers.dense(X, n_hidden1, activation=leaky_relu, name="hidden1")
(2)ELU
第二种变体是ELU函数,叫做指数线性单元,比LeakyReLU函数效果更好,公式如下。TensorFlow中写好了这个激活函数供我们调用,只要在定义隐藏层时传入即可:hidden = tf.layers.dense(X, n_hidden, activation=tf.nn.elu, name="hidden")
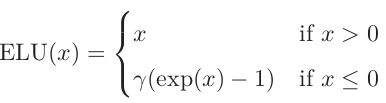
(3)SELU
第三种变体是SELU函数,这是2017年提出来的,是ReLU家族中的新贵,效果更好。为啥?因为它与Xavier初始化、Batch Normalization的思想如出一辄。在训练期间,由使用SELU激活函数的一堆密集层组成的神经网络将自我归一化:每层的输出将倾向于在训练期间保持相同的均值和方差,这解决了消失/爆炸的梯度问题。 而通过调整超参数,使平均值保持接近0,标准差保持接近1,这不就是Batch Normalization在干的事情吗?因此,这种激活函数显着地优于其他激活函数。
TensofFlow也写好了这个激活函数,传入隐藏层即可: hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.selu, name="hidden1")。
下面我们就选择SELU激活函数,应用到MINIST数据集的模型训练中。
3、Batch Normalization
写到这里,内心还是非常鸡冻的,这个Batch Normalization据说是解决梯度不稳定问题的核武器,广受追捧。关于Batch Normalization的详细说明,请移步开头那里鄙人列出的博客,自认为讲得还是蛮清楚的。
用一句话来概括,Batch Normalization就是在用小批量梯度下降算法训练模型时,对每一个隐藏层在激活之前的输入值进行标准归一化(均值为0,方差为1),然后再进行缩放和平移变换,使得每个隐藏层的输入在分布上保持一致。
操作全蕴涵在下面的公式里:
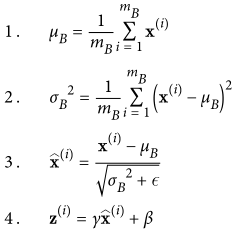
用TensorFlow来实现Batch Normalization的关键语法是tf.layers.batch_normalization(),但是不像定义激活函数那样写一行代码,传入一个函数就能搞定,Batch Normalization要实现起来有点麻烦。具体在完整的模型代码中再说明。
4、选择更好的优化算法
在之前的博客中,我整理了各种优化算法,可以移步开头列出的博客去查看。优化算法非常多,容易把人搞晕,其实这些优化算法都是在梯度下降算法的基础上进行优化的:
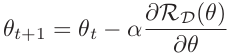
这些优化算法分别对学习率和损失函数的梯度下手,一般被分为以下三类:
第一类优化算法是在训练过程中自动调整学习率,比如AdaGrad、RMSProp、AdaDelta,统称为自适应学习率算法;
第二类优化算法是根据损失函数梯度的方向来改造梯度,比如Momentum、Nesterov加速梯度;
第三类优化算法是结合了前两类的优点,同时对学习率和损失函数的梯度进行改造,比如Adam,是Momentum和RMSProp的结合。
公式我就不贴了,请移步我的博客,哈哈。
我估计有些人一开始会和我一样(可能就我一个,因为我比较笨),对小批量梯度下降、随机梯度下降和这些优化算法的关系不是特别明白,这里也说明一下。
首先梯度下降算法根据一次迭代传入的样本量的多少,可以分为批量梯度下降(Batch Gradient Descent,传入所有训练集样本)、随机梯度下降(Stochastic Gradient Descent,传入一个训练样本)和小批量梯度下降(Mini-Batch Gradient Descent),公式都是上面那个计算公式,只是计算损失所用的样本量不同。
优化算法则是对梯度下降法的学习率和梯度进行改造,可以应用于以上三种梯度下降算法。
一般而言,直接选择Adam优化器就行。
定义这几种优化器的TensorFlow语法整理如下。
-----------------------------------自适应学习率算法----------------------------------------------
# AdaGrad优化器,平滑项选择默认值就行
optimizer = tf.train.AdagradOptimizer(learning_rate=learning_rate) # RMSProp优化器,衰减率默认为0.9
optimizer = tf.train.RMSPropOptimizer(learning_rate=learning_rate,
momentum=0.9, decay=0.9, epsilon=1e-10) -----------------------------------梯度方向优化算法----------------------------------------------
# Momentum优化器,引入了超参数,动量belta,一般设置为0.9
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,
momentum=0.9)
# Nesterov加速梯度,传入参数:use_nesterov=True
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate,
momentum=0.9, use_nesterov=True) -----------------------------------学习率与梯度同时优化算法----------------------------------------
# Adam算法,有两个参数,一个用来调整学习率,一个用来调整梯度
optimizer = tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-08)
5、完整的模型代码
好,下面就用上面这些解决梯度消失的方法,再次基于MINIST数据集,构建全连接神经网络,看是否能提升模型的预测结果。
第一步:准备训练集、验证集和测试集,生成小批量样本
这里构建一个具有两个隐藏层(第一个隐藏层有300个神经元,第二个有100个神经元)的全连接神经网络,实话说,这只是浅层网络,而非深层网络(DNN)。然后准备好训练集、验证集和测试集,并打乱顺序,生成小批量样本。
import tensorflow as tf
import numpy as np
from functools import partial
import time
from datetime import timedelta # 记录训练花费的时间
def get_time_dif(start_time):
end_time = time.time()
time_dif = end_time - start_time
#timedelta是用于对间隔进行规范化输出,间隔10秒的输出为:00:00:10
return timedelta(seconds=int(round(time_dif))) # 定义输入层、输出层和中间隐藏层的神经元数量
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10 # 准备训练数据集、验证集和测试集,并生成小批量样本
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data() X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:] def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch
第二步:用He初始化、Batch Norm和SELU激活函数来构建网络层
一行行看以下的代码,首先定义了一个Batch Norm的动量参数,设置为0.9。什么意思?Batch Norm的操作分为训练阶段和推断阶段,在推断阶段,是用整个训练集上输入值的均值和方差来进行标准归一化,而这两个全局统计量,就是对训练阶段用小批量样本计算得到的输入值的均值和方差,进行指数移动平均来计算的。因此这个动量参数就是用来求移动平均的。
然后下面定义了一个training,原谅我其实没太懂这个东西,不过这应该是为了做Batch Norm而定义的,我猜是用来学习输入值的均值、方差、缩放参数和平移参数这四个参数的(全靠猜)。
接下来对权重进行He初始化,注意定义在“dnn”这个名称范围之内,后面我们还会对所有的变量进行初始化,所以把He初始化定义在内部,比较好区分一些。
我们使用Python的partial()函数来构造模块,把相同的参数放进去,避免重复的定义相同的参数。
这里构造了两个模块,因为Batch Norm也可以看作一个隐藏层之前的BN层,所以第一个模块是BN层,相同的函数参数有Batch Norm,training、动量参数。
第二个模块是隐藏层,相同的参数有全连接层和He初始化,需要注意的是tf.layers.dense()中默认activation=None,也就是说我们不传入相应的参数,就没有设置激活函数。这个小细节可谓相当之关键,因为为了在每个隐藏层的激活函数之前进行BN操作,我们需要在BN层之后再手动添加 SELU 激活函数,故在这里先不用激活函数。在代码中可以看到,把BN操作后的输入值再传入到tf.nn.selu()中进行激活。
还要注意最后对输出层的logits值进行BN操作后,并没有用softmax激活函数求出概率分布,这是因为计算损失时用tf.nn.sparse_softmax_cross_entropy_with_logits这个函数,直接由softmax激活之前的值,计算交叉熵损失。
# 测试时,用整个训练集的均值和标准差来进行标准化。这些通常在训练期间使用移动平均值有效地计算,所以有个动量参数。
batch_norm_momentum = 0.9
learning_rate = 0.01 X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y") # 这里也有个train,不太懂什么情况。
training = tf.placeholder_with_default(False, shape=(), name='training') with tf.name_scope("dnn"):
he_init = tf.variance_scaling_initializer()
# 便于下面复用
my_batch_norm_layer = partial(
tf.layers.batch_normalization,
training=training,
momentum=batch_norm_momentum) my_dense_layer = partial(
tf.layers.dense,
kernel_initializer=he_init) hidden1 = my_dense_layer(X, n_hidden1, name="hidden1")
bn1 = tf.nn.selu(my_batch_norm_layer(hidden1))
hidden2 = my_dense_layer(bn1, n_hidden2, name="hidden2")
bn2 = tf.nn.selu(my_batch_norm_layer(hidden2))
logits_before_bn = my_dense_layer(bn2, n_outputs, name="outputs")
logits = my_batch_norm_layer(logits_before_bn)
第三步:定义损失函数、Adam优化器,和模型评估指标
关键在“train”这一段代码处,首先定义了Adam优化器,然后定义了一个用来更新Batch Norm参数的op:extra_update_ops。最后通过最小化交叉熵损失来求模型的参数,要基于Batch Norm的参数来定义一个op:training_op。于是这里有两个op。
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.AdamOptimizer(learning_rate)
# 这是需要额外更新batch norm的参数
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
# 模型参数的优化依赖于batch norm参数的更新
with tf.control_dependencies(extra_update_ops):
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
第四步:训练模型和保存模型
这里需要注意的有两点,我们看 sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})这段代码。
第一点是本来有两个op要放入到sess.run()里去执行的,也就是传入[training_op, extra_update_ops],可是由于前面让模型的最小化损失函数的操作取决于Batch Norm的更新操作:with tf.control_dependencies(extra_update_ops),所以这里只需要把training_op放进去就行。
第二点是在feed_dict中,要把{training: True}放进去,进行Batch Norm参数的学习。
init = tf.global_variables_initializer()
saver = tf.train.Saver() n_epochs = 40
batch_size = 200 with tf.Session() as sess:
init.run()
start_time = time.time()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(training_op,
feed_dict={training: True, X: X_batch, y: y_batch})
if epoch % 5 ==0 or epoch == 39:
accuracy_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
print(epoch, "Batch accuracy:", accuracy_batch,"Validation accuracy:", accuracy_val)
time_dif = get_time_dif(start_time)
print("\nTime usage:", time_dif)
save_path = saver.save(sess, "./my_model_final_speed.ckpt")
耗时32秒,最后一轮的验证精度为98.44%,还不错。
0 Batch accuracy: 0.975 Validation accuracy: 0.962
5 Batch accuracy: 0.99 Validation accuracy: 0.9772
10 Batch accuracy: 1.0 Validation accuracy: 0.981
15 Batch accuracy: 1.0 Validation accuracy: 0.9822
20 Batch accuracy: 1.0 Validation accuracy: 0.9818
25 Batch accuracy: 1.0 Validation accuracy: 0.9828
30 Batch accuracy: 1.0 Validation accuracy: 0.9802
35 Batch accuracy: 1.0 Validation accuracy: 0.9842
39 Batch accuracy: 1.0 Validation accuracy: 0.9844 Time usage: 0:00:32
第五步:调用模型和测试模型
测试精度为98.08%,还可以。
with tf.Session() as sess:
saver.restore(sess, "./my_model_final_speed.ckpt") # or better, use save_path
X_test_20 = X_test[:20]
# 得到softmax之前的输出
Z = logits.eval(feed_dict={X: X_test_20})
# 得到每一行最大值的索引
y_pred = np.argmax(Z, axis=1)
print("Predicted classes:", y_pred)
print("Actual calsses: ", y_test[:20])
# 评估在测试集上的正确率
acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test})
print("\nTest_accuracy:", acc_test)
INFO:tensorflow:Restoring parameters from ./my_model_final_speed.ckpt
Predicted classes: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 8 4]
Actual calsses: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 3 4] Test_accuracy: 0.9808
为了和上一篇博客中的“裸机版”全连接神经网络进行对比,同样的,我把batch size分别设置为200、100、50、10,得到如下结果。batch size 为50时,预测结果最好,测试精度为98.44%。
batch size = 200 Test_accuracy: 0.9808
batch size = 100 Test_accuracy: 0.9811
batch size = 50 Test_accuracy: 0.9844
batch size = 10 Test_accuracy: 0.9821
“裸机版”全连接神经网络在不同的batch size 下的测试精度如下。可见运用以上这些加速优化方法,的确提升了模型的准确性。
但是由于是浅层神经网络,数据量也不是太大,所以提升的效果其实不太明显。而且由于使用了SELU函数这种非线性激活函数,与使用ReLU激活函数相比,训练速度反而下降了。
batch_size = 200 Test_accuracy: 0.9576
batch_size = 100 Test_accuracy: 0.9599 batch_size = 50 Test_accuracy: 0.9781 batch_size = 10 Test_accuracy: 0.9812
二、学习率衰减
学习率衰减一方面是为了加快训练速度,另一方面是为了跳出局部最优解,尽量找到全局最优。
学习率衰减的想法是先从一个比较大的学习率(比如0.1)开始进行梯度下降, 此时损失下降比较快,然后一旦损失下降变得比较慢了就降低学习率。实操中可以分为几个阶段来降低学习率,迭代n步以后就降低学习率,而在每个阶段内的学习率是固定的。
其中一种做法叫指数衰减,将学习率设置为步数r的函数,学习率每r步就下降10倍。
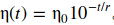
AdaGrad,RMSProp和Adam这些优化算法会自动调整学习率,所以一般不再进行学习率衰减,其他的如Momentum优化算法可以用。
用TensorFlow来实现学习率的指数衰减比较简单,在定义损失和优化器的步骤中,可以进行如下的操作。
with tf.name_scope("train"):
# 学习率指数衰减的初始化值为0.1
initial_learning_rate=0.1
# 10000步后降低学习率
decay_steps = 10000
# 每次都衰减10倍。
decay_rate = 1/10
# 用来跟踪当前迭代次数
global_step = tf.Variable(0, trainable=False, name="global_step")
# 用学习率指数衰减算法来定义学习率
learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step,
decay_steps, decay_rate)
# 用学习率指数衰减定义的学习率来构建优化器
optimizer = tf.train.MomentumOptimizer(learning_rate,momentum=0.9)
training_op = optimizer.minimize(loss, global_step=global_step)
好了,那我们就在前一部分模型的基础上,运用学习率指数衰减算法,来进一步优化模型。正如上文所说,Adam算法会自动调整学习率,就用不着再额外去做学习率衰减了,所以我们选择Momentum优化器来做。
原谅我又要把老长的代码再贴一遍,真的不是为了让博客的字数更多!
把batch size分别设置为200、100、50、10,得到测试精度分别为98.45%、98.34%、98.2%、98.4%。可见取batch size=200,取得还不错的效果。
import tensorflow as tf
import numpy as np
from functools import partial
import time
from datetime import timedelta # 记录训练花费的时间
def get_time_dif(start_time):
end_time = time.time()
time_dif = end_time - start_time
#timedelta是用于对间隔进行规范化输出,间隔10秒的输出为:00:00:10
return timedelta(seconds=int(round(time_dif))) # 定义输入层、输出层和中间隐藏层的神经元数量
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10 # 准备训练数据集、验证集和测试集,并生成小批量样本
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data() X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:] def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch # 测试时,用整个训练集的均值和标准差来进行标准化。这些通常在训练期间使用移动平均值有效地计算,所以有个动量参数。 batch_norm_momentum = 0.9 X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y") training = tf.placeholder_with_default(False, shape=(), name='training') with tf.name_scope("dnn"):
he_init = tf.variance_scaling_initializer()
# 便于下面复用
my_batch_norm_layer = partial(
tf.layers.batch_normalization,
training=training,
momentum=batch_norm_momentum) my_dense_layer = partial(
tf.layers.dense,
kernel_initializer=he_init) hidden1 = my_dense_layer(X, n_hidden1, name="hidden1")
bn1 = tf.nn.selu(my_batch_norm_layer(hidden1))
hidden2 = my_dense_layer(bn1, n_hidden2, name="hidden2")
bn2 = tf.nn.selu(my_batch_norm_layer(hidden2))
logits_before_bn = my_dense_layer(bn2, n_outputs, name="outputs")
logits = my_batch_norm_layer(logits_before_bn) with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss") # 在这里做学习率衰减
with tf.name_scope("train"): initial_learning_rate=0.1
decay_steps = 10000
decay_rate = 1/10
global_step = tf.Variable(0, trainable=False, name="global_step")
learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step,
decay_steps, decay_rate)
# 用学习率指数衰减定义的学习率来构建优化器
optimizer = tf.train.MomentumOptimizer(learning_rate,momentum=0.9)
# 这是需要额外更新batch norm的参数
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
# 模型参数的优化依赖与batch norm参数的更新
with tf.control_dependencies(extra_update_ops):
training_op = optimizer.minimize(loss) with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) init = tf.global_variables_initializer()
saver = tf.train.Saver() n_epochs = 40
batch_size = 50 with tf.Session() as sess:
init.run()
start_time = time.time()
for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(training_op,
feed_dict={training: True, X: X_batch, y: y_batch})
if epoch % 5 ==0 or epoch == 39:
accuracy_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
print(epoch, "Batch accuracy:", accuracy_batch,"Validation accuracy:", accuracy_val)
time_dif = get_time_dif(start_time)
print("\nTime usage:", time_dif)
save_path = saver.save(sess, "./my_model_final_scheduling.ckpt") with tf.Session() as sess:
saver.restore(sess, "./my_model_final_scheduling.ckpt") # or better, use save_path
X_test_20 = X_test[:20]
# 得到softmax之前的输出
Z = logits.eval(feed_dict={X: X_test_20})
# 得到每一行最大值的索引
y_pred = np.argmax(Z, axis=1)
print("Predicted classes:", y_pred)
print("Actual calsses: ", y_test[:20])
# 评估在测试集上的正确率
acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test})
print("\nTest_accuracy:", acc_test)
三、解决梯度爆炸-梯度截断
前面用到的Batch Norm是缓解梯度爆炸问题的一个比较好的方法,而另一个比较好的方法是在反向传播过程中对梯度进行简单地截断,使它们永远不会超过某个阈值,这称为梯度截断(Gradient Clipping)。 这种方法简单粗暴有效。一般来说,人们现在更喜欢用Batch Norm来解决问题。
用TensorFlow实现梯度截断的步骤如下:
- 先调用优化器的compute_gradients()方法来计算和获取当前的梯度;
- 然后使用clip_by_value()函数将梯度限制在[-1,1]的区间内;
- 最后使用优化程序的apply_gradients()方法应用梯度截断。
threshold = 1.0
with tf.name_scope("train"):
optimizer = tf.train.AdamOptimizer(learning_rate)
# 首先计算和获取梯度
grads_and_vars = optimizer.compute_gradients(loss)
# 把超过阈值的梯度截断在[-1,1]之间
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
# 用截断后的梯度继续进行训练
training_op = optimizer.apply_gradients(capped_gvs)
浅层神经网络一般是不会产生梯度爆炸的问题,于是我们基于MINIST数据集构建一个包含5个隐藏层的全连接神经网络。为了突出梯度截断的操作,这次就不再叠加上面的各种优化技巧了。
选择Adam优化器,batch size 取100,得到测试精度为96.68%。
import tensorflow as tf
import numpy as np
import time
from datetime import timedelta # 记录训练花费的时间
def get_time_dif(start_time):
end_time = time.time()
time_dif = end_time - start_time
#timedelta是用于对间隔进行规范化输出,间隔10秒的输出为:00:00:10
return timedelta(seconds=int(round(time_dif))) n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 50
n_hidden3 = 50
n_hidden4 = 50
n_hidden5 = 50
n_outputs = 10 (X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data() X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0
X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0
y_train = y_train.astype(np.int32)
y_test = y_test.astype(np.int32)
X_valid, X_train = X_train[:5000], X_train[5000:]
y_valid, y_train = y_train[:5000], y_train[5000:] def shuffle_batch(X, y, batch_size):
rnd_idx = np.random.permutation(len(X))
n_batches = len(X) // batch_size
for batch_idx in np.array_split(rnd_idx, n_batches):
X_batch, y_batch = X[batch_idx], y[batch_idx]
yield X_batch, y_batch X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int32, shape=(None), name="y") with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3")
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4")
hidden5 = tf.layers.dense(hidden4, n_hidden5, activation=tf.nn.relu, name="hidden5")
logits = tf.layers.dense(hidden5, n_outputs, name="outputs") with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss") learning_rate = 0.01
# 把梯度截断的阈值设置为1.0
threshold = 1.0 with tf.name_scope("train"):
optimizer = tf.train.AdamOptimizer(learning_rate)
# 首先计算和获取梯度
grads_and_vars = optimizer.compute_gradients(loss)
# 把超过阈值的梯度截断在[-1,1]之间
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
# 用截断后的梯度继续进行训练
training_op = optimizer.apply_gradients(capped_gvs) with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy") init = tf.global_variables_initializer()
saver = tf.train.Saver() n_epochs = 40
batch_size = 100 with tf.Session() as sess:
init.run()
start_time = time.time() for epoch in range(n_epochs):
for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
if epoch % 5 == 0 or epoch == 39:
acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch})
acc_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid})
print(epoch, "Batch accuracy:", acc_batch, "Val accuracy:", acc_val) time_dif = get_time_dif(start_time)
print("\nTime usage:", time_dif)
save_path = saver.save(sess, "./my_model_final_clip.ckpt") with tf.Session() as sess:
saver.restore(sess, "./my_model_final_clip.ckpt") # or better, use save_path
X_test_20 = X_test[:20]
# 得到softmax之前的输出
Z = logits.eval(feed_dict={X: X_test_20})
# 得到每一行最大值的索引
y_pred = np.argmax(Z, axis=1)
print("Predicted classes:", y_pred)
print("Actual calsses: ", y_test[:20])
# 评估在测试集上的正确率
acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test})
print("\nTest_accuracy:", acc_test)
参考资料:
《Hands On Machine Learning with Scikit-Learn and TensorFlow》
TensorFlow之DNN(二):全连接神经网络的加速技巧(Xavier初始化、Adam、Batch Norm、学习率衰减与梯度截断)的更多相关文章
- TensorFlow之DNN(一):构建“裸机版”全连接神经网络
博客断更了一周,干啥去了?想做个聊天机器人出来,去看教程了,然后大受打击,哭着回来补TensorFlow和自然语言处理的基础了.本来如意算盘打得挺响,作为一个初学者,直接看项目(不是指MINIST手写 ...
- tensorflow中使用mnist数据集训练全连接神经网络-学习笔记
tensorflow中使用mnist数据集训练全连接神经网络 ——学习曹健老师“人工智能实践:tensorflow笔记”的学习笔记, 感谢曹老师 前期准备:mnist数据集下载,并存入data目录: ...
- 【TensorFlow/简单网络】MNIST数据集-softmax、全连接神经网络,卷积神经网络模型
初学tensorflow,参考了以下几篇博客: soft模型 tensorflow构建全连接神经网络 tensorflow构建卷积神经网络 tensorflow构建卷积神经网络 tensorflow构 ...
- Tensorflow 多层全连接神经网络
本节涉及: 身份证问题 单层网络的模型 多层全连接神经网络 激活函数 tanh 身份证问题新模型的代码实现 模型的优化 一.身份证问题 身份证号码是18位的数字[此处暂不考虑字母的情况],身份证倒数第 ...
- 深度学习tensorflow实战笔记(1)全连接神经网络(FCN)训练自己的数据(从txt文件中读取)
1.准备数据 把数据放进txt文件中(数据量大的话,就写一段程序自己把数据自动的写入txt文件中,任何语言都能实现),数据之间用逗号隔开,最后一列标注数据的标签(用于分类),比如0,1.每一行表示一个 ...
- MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网络训练实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前两篇文章MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网 ...
- 如何使用numpy实现一个全连接神经网络?(上)
全连接神经网络的概念我就不介绍了,对这个不是很了解的朋友,可以移步其他博主的关于神经网络的文章,这里只介绍我使用基本工具实现全连接神经网络的方法. 所用工具: numpy == 1.16.4 matp ...
- 基于MNIST数据集使用TensorFlow训练一个包含一个隐含层的全连接神经网络
包含一个隐含层的全连接神经网络结构如下: 包含一个隐含层的神经网络结构图 以MNIST数据集为例,以上结构的神经网络训练如下: #coding=utf-8 from tensorflow.exampl ...
- Keras入门——(1)全连接神经网络FCN
Anaconda安装Keras: conda install keras 安装完成: 在Jupyter Notebook中新建并执行代码: import keras from keras.datase ...
随机推荐
- Django Push 的一些资料
先来中文的: 主要讲Orbited: http://sunsetsunrising.com/2009/django_comet.html#gsc.tab=0 再来英文的: http://www.rkb ...
- ruby the diference between gets and gets.chomp()
ruby the diference between gets and gets.chomp() 二者都是可以获取用户命令行输入的函数,但是 gets获取内容后,后面 附带了 多余的换行符号'\n'; ...
- spring cloud 入门系列六:使用Zuul 实现API网关服务
通过前面几次的分享,我们了解了微服务架构的几个核心设施,通过这些组件我们可以搭建简单的微服务架构系统.比如通过Spring Cloud Eureka搭建高可用的服务注册中心并实现服务的注册和发现: 通 ...
- mysql-索引、关系、范式
索引 几乎所有的索引都是建立在字段之上 索引:系统根据某种算法,将已有的数据(未来可能新增的数据也算),单独建立一个文件,这个文件能够快速的匹配数据,并且能够快速的找到对应的表中的记录 索引意义 能够 ...
- webpack4 splitChunksPlugin && runtimeChunkPlugin 配置杂记
webpack2 还没研究好,就发现升级到4了,你咋这么快~ 最近要做项目脚手架,项目构建准备重新做,因为之前写的太烂了...然后发现webpack大版本已经升到4了(又去看了一眼,4.5了),这么快 ...
- Python_添加行号
filename='demo.py' with open(filename,'r')as fp: lines=fp.readlines() #读取所有行 maxLength=max(map(len,l ...
- python_方法说明
方法用来描述对象所具有的行为,例如,列表对象的追加元素.插入元素.删除原宿.排序,字符串对象的分隔.连接.排版.替换.烤箱的温度设置.烘烤,等等 在类中定义的方法可以粗略分为四大类:公有方法.私有方法 ...
- Ubuntu 16.04 安装 Docker
在Ubuntu上安装Docker, 非常简单, 我测试过 16.04, 17.04, 以及最新版 18.04,都是可以成功安装,并使用的. 第一步: 启动root账号 第二步: 配置网络,能上网 ...
- C# 使用 SmtpClient.SendAsync 方法发送邮件失败,总是返回 Cancelled
问题: 调用 SmtpClient.SendAsync,在 SendCompleted 的回调函数里面总是获取到 e.Cancelled 为 true. 后来测试了一下,相同的代码,只是把 SmtpC ...
- Pat1108: Finding Average
1108. Finding Average (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue The b ...