Logistic回归二分类Winner or Losser----台大李宏毅机器学习作业二(HW2)
一、作业说明
给定训练集spam_train.csv,要求根据每个ID各种属性值来判断该ID对应角色是Winner还是Losser(收入是否大于50K),这是一个典型的二分类问题。
训练集介绍:
(1)、CSV文件,大小为4000行X59列;
(2)、4000行数据对应着4000个角色,ID编号从1到4001;
(3)、59列数据中, 第一列为角色ID,最后一列为分类结果,即label(0、1两种),中间的57列为角色对应的57种属性值;
(4)、数据集地址:https://pan.baidu.com/s/1mG7ndtlT4jWYHH9V-Rj_5g, 提取码:hwzf 。
二、思路分析及实现
2.1 思路分析
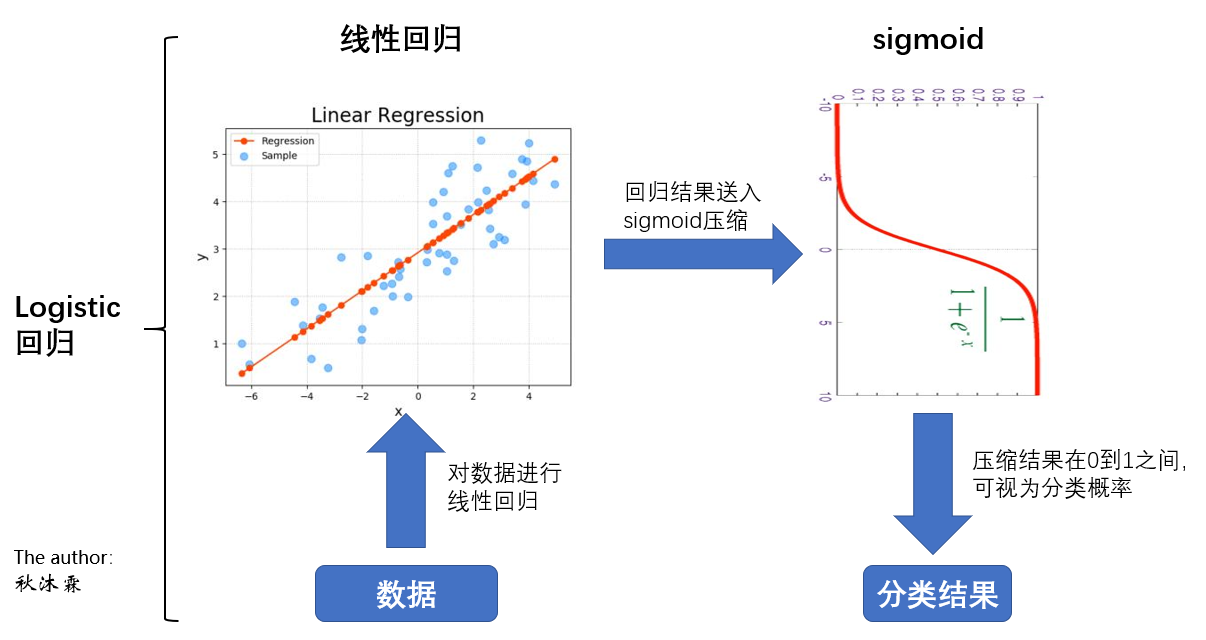
这是一个典型的二分类问题,结合课上所学内容,决定采用Logistic回归算法。
与线性回归用于预测不同,Logistic回归则常用于分类(通常是二分类问题)。Logistic回归实质上就是在普通的线性回归后面加上了一个sigmoid函数,把线性回归预测到的数值压缩成为一个概率,进而实现二分类(关于线性回归模型,可参考上一次作业)。
在损失函数方面,Logistic回归并没有使用传统的欧式距离来度量误差,而使用了交叉熵(用于衡量两个概率分布之间的相似程度)。
2.2 数据预处理
在机器学习中,数据的预处理是非常重要的一环,能直接影响到模型效果的好坏。本次作业的数据相对简单纯净,在数据预处理方面并不需要花太多精力。
首先是空值处理(尽管没看到空值,但为了以防万一,还是做一下),所有空值用0填充(也可以用平均值、中位数等,视具体情况而定)。
接着就是把数据范围尽量scale到同一个数量级上,观察数据后发现,多数数据值为0,非0值也都在1附近,只有倒数第二列和倒数第三列数据值较大,可以将这两列分别除上每列的平均值,把数值范围拉到1附近。
由于并没有给出这57个属性具体是什么属性,因此无法对数据进行进一步的挖掘应用。
上述操作完成后,将表格的第2列至58列取出为x(shape为4000X57),将最后一列取出做label y(shape为4000X1)。进一步划分训练集和验证集,分别取x、y中前3500个样本为训练集x_test(shape为3500X57),y_test(shape为3500X1),后500个样本为验证集x_val(shape为500X57),y_val(shape为500X1)。
数据预处理到此结束。
# 从csv中读取有用的信息
df = pd.read_csv('spam_train.csv')
# 空值填0
df = df.fillna(0)
# (4000, 59)
array = np.array(df)
# (4000, 57)
x = array[:, 1:-1]
# scale
x[-1] /= np.mean(x[-1])
x[-2] /= np.mean(x[-2])
# (4000, )
y = array[:, -1] # 划分训练集与验证集
x_train, x_val = x[0:3500, :], x[3500:4000, :]
y_train, y_val = y[0:3500], y[3500:4000]
2.3 模型建立
2.3.1 线性回归
先对数据做线性回归,得出每个样本对应的回归值。下式为对第n个样本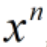 的回归,回归结果为
的回归,回归结果为 。
。
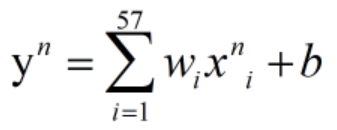
y_pre = weights.dot(x_val[j, :]) + bias
2.3.2 sigmoid函数压缩回归值
之后将回归结果送进sigmoid函数,得到概率值。
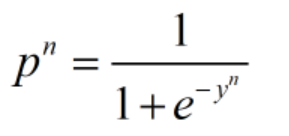
sig = 1 / (1 + np.exp(-y_pre)
2.3.3 误差反向传播
接着就到重头戏了。众所周知,不管线性回归还是Logistic回归,其关键和核心就在于通过误差的反向传播来更新参数,进而使模型不断优化。因此,损失函数的确定及对各参数的求导就成了重中之重。在分类问题中,模型一般针对各类别输出一个概率分布,因此常用交叉熵作为损失函数。交叉熵可用于衡量两个概率分布之间的相似、统一程度,两个概率分布越相似、越统一,则交叉熵越小;反之,两概率分布之间差异越大、越混乱,则交叉熵越大。
下式表示k分类问题的交叉熵,P为label,是一个概率分布,常用one_hot编码。例如针对3分类问题而言,若样本属于第一类,则P为(1,0,0),若属于第二类,则P为(0,1,0),若属于第三类,则为(0,0,1)。即所属的类概率值为1,其他类概率值为0。Q为模型得出的概率分布,可以是(0.1,0.8,0.1)等。
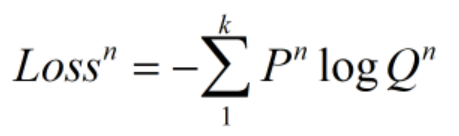
在实际应用中,为求导方便,常使用以e为底的对数。
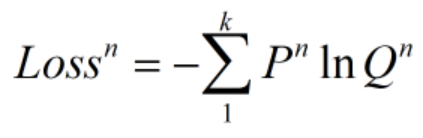
针对本次作业而言,虽然模型只输出了一个概率值p,但由于处理的是二分类问题,因此可以很快求出另一概率值为1-p,即可视为模型输出的概率分布为Q(p,1-p)。将本次的label视为概率分布P(y,1-y),即Winner(label为1)的概率分布为(1,0),分类为Losser(label为0)的概率分布为(0,1)。
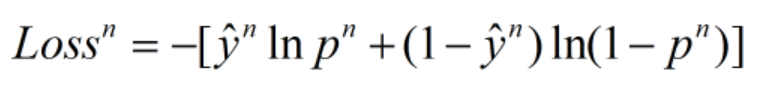
损失函数对权重w求偏导,可得:
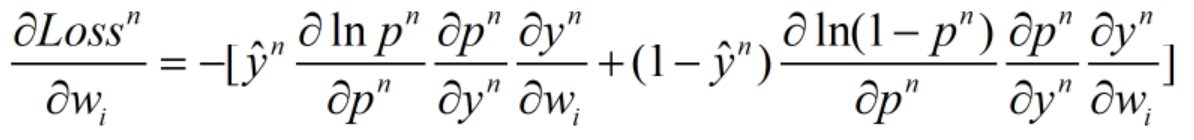
因为:
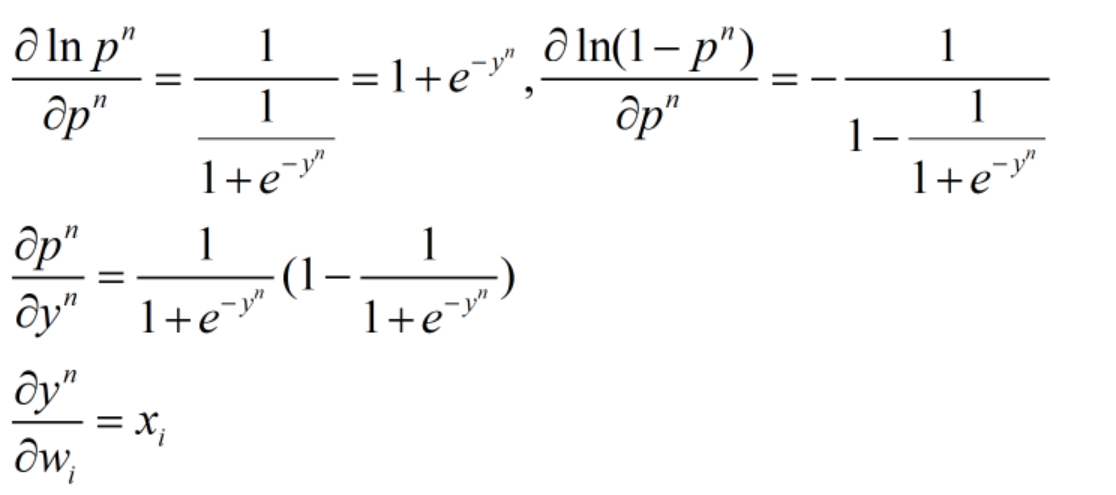
所以有:
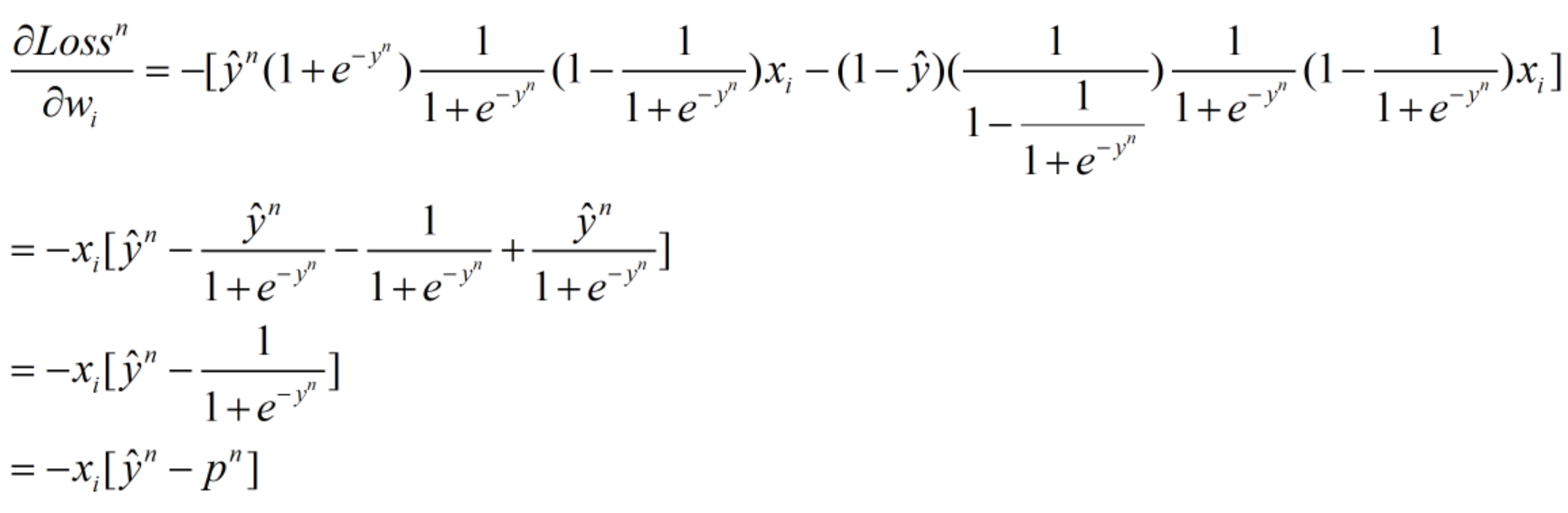
同理,损失函数对偏置b求偏导,可得:
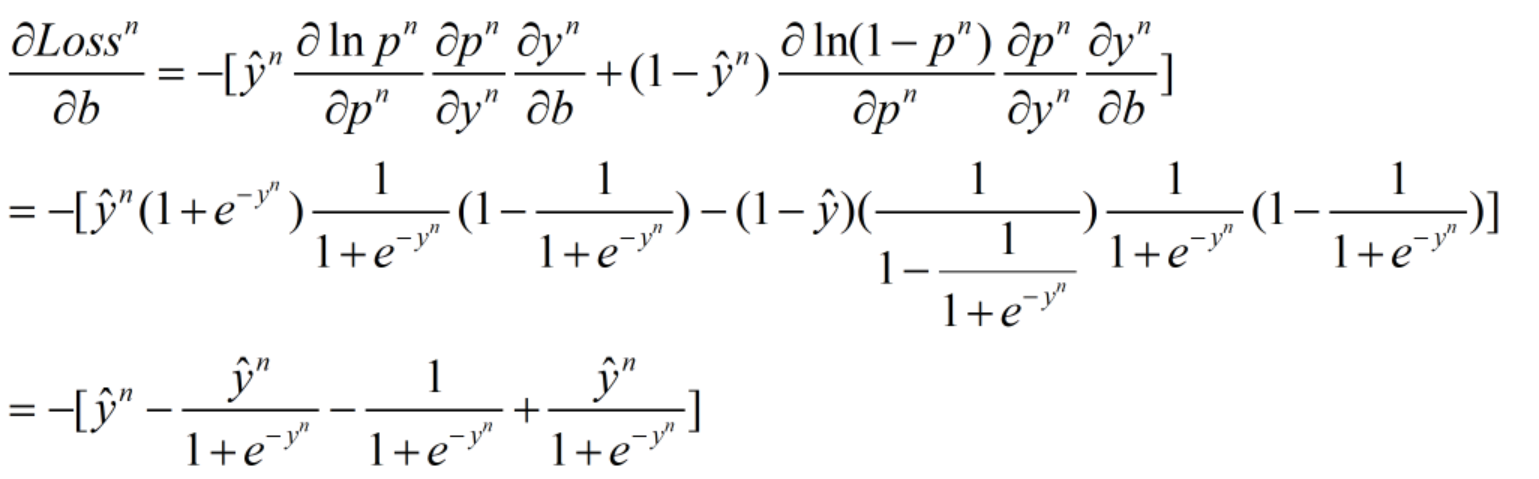

# 在所有数据上计算梯度,梯度计算时针对损失函数求导,num为样本数量
for j in range(num):
# 线性函数
y_pre = weights.dot(x_train[j, :]) + bias
# sigmoid函数压缩回归值,求得概率
sig = 1 / (1 + np.exp(-y_pre))
# 对偏置b求梯度
b_g += (-1) * (y_train[j] - sig)
# 对权重w求梯度,2 * reg_rate * weights[k] 为正则项,防止过拟合
for k in range(dim):
w_g[k] += (-1) * (y_train[j] - sig) * x_train[j, k] + 2 * reg_rate * weights[k]
2.3.4 参数更新
求出梯度后,再拿原参数减去梯度与学习率的乘积,即可实现参数的更新。
# num为样本数量
b_g /= num
w_g /= num # adagrad
bg2_sum += b_g**2
wg2_sum += w_g**2 # 更新权重和偏置
bias -= learning_rate/bg2_sum**0.5 * b_g
weights -= learning_rate/wg2_sum**0.5 * w_g
三、代码分享与结果展示
3.1 源代码
import pandas as pd
import numpy as np # 更新参数,训练模型
def train(x_train, y_train, epoch):
num = x_train.shape[0]
dim = x_train.shape[1]
bias = 0 # 偏置值初始化
weights = np.ones(dim) # 权重初始化
learning_rate = 1 # 初始学习率
reg_rate = 0.001 # 正则项系数
bg2_sum = 0 # 用于存放偏置值的梯度平方和
wg2_sum = np.zeros(dim) # 用于存放权重的梯度平方和 for i in range(epoch):
b_g = 0
w_g = np.zeros(dim)
# 在所有数据上计算梯度,梯度计算时针对损失函数求导
for j in range(num):
y_pre = weights.dot(x_train[j, :]) + bias
sig = 1 / (1 + np.exp(-y_pre))
b_g += (-1) * (y_train[j] - sig)
for k in range(dim):
w_g[k] += (-1) * (y_train[j] - sig) * x_train[j, k] + 2 * reg_rate * weights[k]
b_g /= num
w_g /= num # adagrad
bg2_sum += b_g ** 2
wg2_sum += w_g ** 2
# 更新权重和偏置
bias -= learning_rate / bg2_sum ** 0.5 * b_g
weights -= learning_rate / wg2_sum ** 0.5 * w_g # 每训练100轮,输出一次在训练集上的正确率
# 在计算loss时,由于涉及到log()运算,因此可能出现无穷大,计算并打印出来的loss为nan
# 有兴趣的同学可以把下面涉及到loss运算的注释去掉,观察一波打印出的loss
if i % 3 == 0:
# loss = 0
acc = 0
result = np.zeros(num)
for j in range(num):
y_pre = weights.dot(x_train[j, :]) + bias
sig = 1 / (1 + np.exp(-y_pre))
if sig >= 0.5:
result[j] = 1
else:
result[j] = 0 if result[j] == y_train[j]:
acc += 1.0
# loss += (-1) * (y_train[j] * np.log(sig) + (1 - y_train[j]) * np.log(1 - sig))
# print('after {} epochs, the loss on train data is:'.format(i), loss / num)
print('after {} epochs, the acc on train data is:'.format(i), acc / num) return weights, bias # 验证模型效果
def validate(x_val, y_val, weights, bias):
num = 500
# loss = 0
acc = 0
result = np.zeros(num)
for j in range(num):
y_pre = weights.dot(x_val[j, :]) + bias
sig = 1 / (1 + np.exp(-y_pre))
if sig >= 0.5:
result[j] = 1
else:
result[j] = 0 if result[j] == y_val[j]:
acc += 1.0
# loss += (-1) * (y_val[j] * np.log(sig) + (1 - y_val[j]) * np.log(1 - sig))
return acc / num def main():
# 从csv中读取有用的信息
df = pd.read_csv('spam_train.csv')
# 空值填0
df = df.fillna(0)
# (4000, 59)
array = np.array(df)
# (4000, 57)
x = array[:, 1:-1]
# scale
x[:, -1] /= np.mean(x[:, -1])
x[:, -2] /= np.mean(x[:, -2])
# (4000, )
y = array[:, -1] # 划分训练集与验证集
x_train, x_val = x[0:3500, :], x[3500:4000, :]
y_train, y_val = y[0:3500], y[3500:4000] epoch = 30 # 训练轮数
# 开始训练
w, b = train(x_train, y_train, epoch)
# 在验证集上看效果
acc = validate(x_val, y_val, w, b)
print('The acc on val data is:', acc) if __name__ == '__main__':
main()
3.2 结果展示

可以看出,在训练30轮后,分类正确率能达到94%左右。
参考资料:
李宏毅老师机器学习课程视频:https://www.bilibili.com/video/av10590361
李宏毅老师机器学习课程讲义资料:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
Logistic回归二分类Winner or Losser----台大李宏毅机器学习作业二(HW2)的更多相关文章
- 基于卷积神经网络的面部表情识别(Pytorch实现)----台大李宏毅机器学习作业3(HW3)
一.项目说明 给定数据集train.csv,要求使用卷积神经网络CNN,根据每个样本的面部图片判断出其表情.在本项目中,表情共分7类,分别为:(0)生气,(1)厌恶,(2)恐惧,(3)高兴,(4)难过 ...
- 02-15 Logistic回归(鸢尾花分类)
目录 Logistic回归(鸢尾花分类) 一.导入模块 二.获取数据 三.构建决策边界 四.训练模型 4.1 C参数与权重系数的关系 五.可视化 更新.更全的<机器学习>的更新网站,更有p ...
- 《转》Logistic回归 多分类问题的推广算法--Softmax回归
转自http://ufldl.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92 简介 在本节中,我们介绍Softmax回归模型,该模型是log ...
- 神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词.看完后有一些自己的小想法,也想做一个玩儿一玩儿.用到的原理是深度学习里 ...
- 【2008nmj】Logistic回归二元分类感知器算法.docx
给你一堆样本数据(xi,yi),并标上标签[0,1],让你建立模型(分类感知器二元),对于新给的测试数据进行分类. 要将两种数据分开,这是一个分类问题,建立数学模型,(x,y,z),z指示[0,1], ...
- 台大《机器学习基石》课程感受和总结---Part 1(转)
期末终于过去了,看看别人的总结:http://blog.sina.com.cn/s/blog_641289eb0101dynu.html 接触机器学习也有几年了,不过仍然只是个菜鸟,当初接触的时候英文 ...
- 台大《机器学习基石》课程感受和总结---Part 2 (转)
转自:http://blog.sina.com.cn/s/blog_641289eb0101e2ld.html Part 2总结一下一个粗略的建模过程: 首先,弄清楚问题是什么,能不能用机器学习的思路 ...
- 机器学习之三:logistic回归(最优化)
一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大.如果非要应用进入,可以使用logistic回归. logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
随机推荐
- 学习MySQL我们应该知道哪些东西?
随笔:小编由于年前一直在找工作,而年后找到工作后又一直在忙工作,所以也很少有时间给大家写点什么,总的来说呢,回顾一下之前面试的几次经历,也曾小小的总结了一下自己的不足,发现自己虽然一直在原有的公司(外 ...
- Linux(二十一)Shell编程
21.1 为什么要学习Shell编程 (1)Linux运维工程师在进行服务器集群管理时,需要编写Shell程序来进行服务器管理. (2)对于JavaEE和Python程序员来说,工作的需要,你的老大会 ...
- Java基础:内存模型
1. 引言 2. Java内存模型 3. 内存间的交互操作 1. 引言 考虑到计算机组成的内容: 原始的计算机是CPU用于计算+硬盘用于存储,由于CPU的高速发展和硬盘的缓慢发展,高速的存储需要持续供 ...
- python!!!!惊了,这世上居然还有这么神奇的东西存在
第一次接触到python的时候实在看学习3Blue1Brown的视频线性代数的本质的时候.惊奇的是里面的视频操作,例如向量的变化,线性变换等都是由python用代码打出来的.那时的我只是以为pytho ...
- mysql SQL Layer各个模块介绍
https://blog.csdn.net/cymm_liu/article/details/45821929
- 关于内核转储(core dump)的设置方法
原作者:http://blog.csdn.net/wj_j2ee/article/details/7161586 1. 内核转储作用 (1) 内核转储的最大好处是能够保存问题发生时的状态. (2) 只 ...
- SSM-SpringMVC-12:SpringMVC中BeanNameViewResolver这种视图解析器
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 视图解析器,这个很熟悉啊,之间就用过,就是可以简写/和.jsp的InternalResourceViewRes ...
- Linux时间子系统之(十六):clockevent
专题文档汇总目录 Notes:介绍struct clocke_event_device及其功能feature.模式:触发event接口clockevents_program_event:clockev ...
- shell 中各种括号的作用()、(())、[]、[[]]、{}
一.小括号,圆括号 () 1.单小括号 () 命令组.括号中的命令将会新开一个子shell顺序执行,所以括号中的变量不能够被脚本余下的部分使用.括号中多个命令之间用分号隔开,最后一个命令可以没有分号, ...
- FPGA学习笔记(三)—— 数字逻辑设计基础(抽象的艺术)
FPGA设计的是数字逻辑,在开始用HDL设计之前,需要先了解一下基本的数字逻辑设计-- 一门抽象的艺术. 现实世界是一个模拟的世界,有很多模拟量,比如温度,声音······都是模拟信号,通过对模拟信号 ...