kafka快速入门
一、kafka简介
kafka,ActiveMQ,RabbitMQ是当今最流行的分布式消息中间件,其中kafka在性能及吞吐量方面是三者中的佼佼者,不过最近查阅官网时,官方与它的定义为一个分布式流媒体平台。kafka最主要有以下几个方面作用:
- 发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 以容错持久的方式存储记录流。
- 处理记录发生的流
kafka有四个比较核心的API 分别为:
producer:允许应用程序发布一个消息至一个或多个kafka的topic中
consumer:允许应用程序订阅一个或多个主题,并处理所产生的对他们记录的数据流
stream-api: 允许应用程序从一个或多个主题上消费数据然后将消费的数据输出到一个或多个其他的主题当中,有效地变换所述输入流,以输出流。类似于数据中转站的作用
connector-api:允许构建或运行可重复使用的生产者或消费者,将topic链接到现有的应用程序或数据系统。官网给我们的示意图:
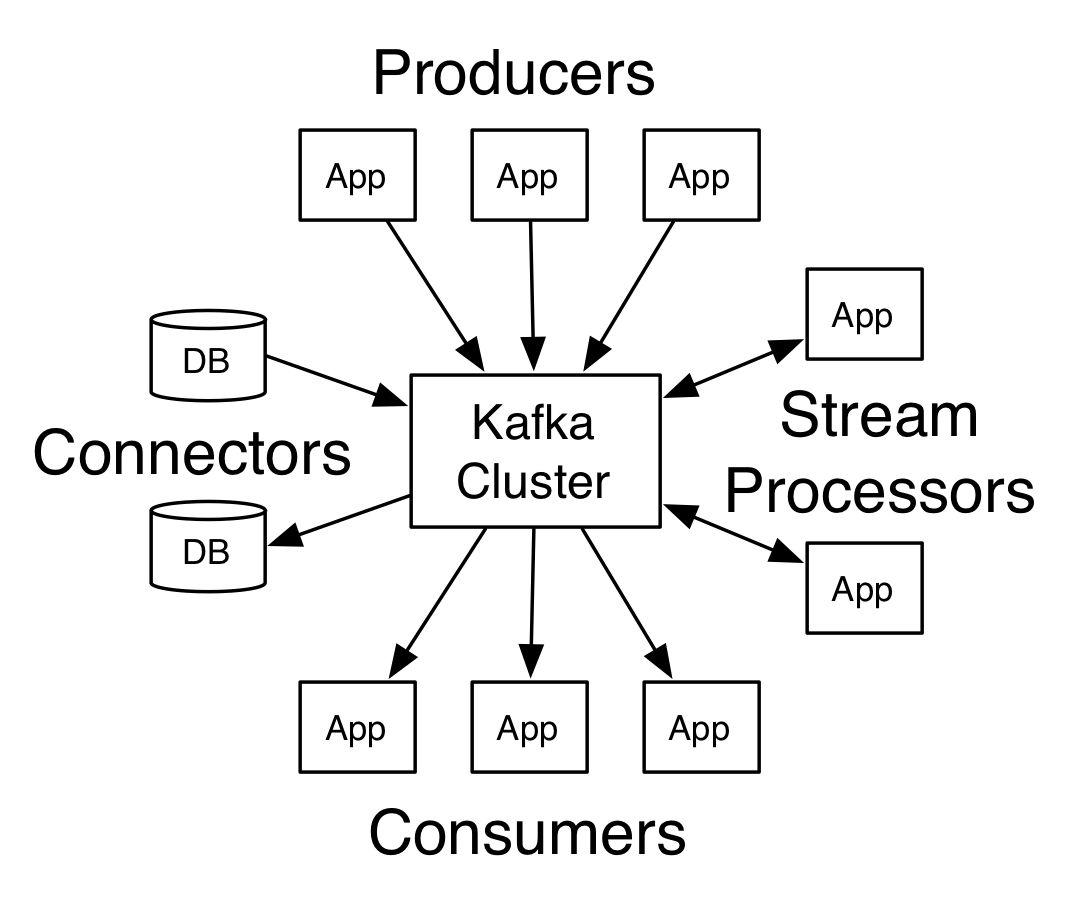
kafka关键名词解释:
- producer:生产者。
- consumer:消费者。
- topic: 消息以topic为类别记录,每一类的消息称之为一个主题(Topic)。为了提高吞吐量,每个消息主题又会有多个分区
- broker:以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker;消费者可以订阅一个或多个主题(topic),并从Broker拉数据,从而消费这些已发布的消息。
每个消息(也叫作record记录,也被称为消息)是由一个key,一个value和时间戳构成。
主题与日志:
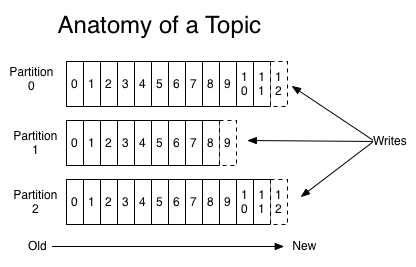
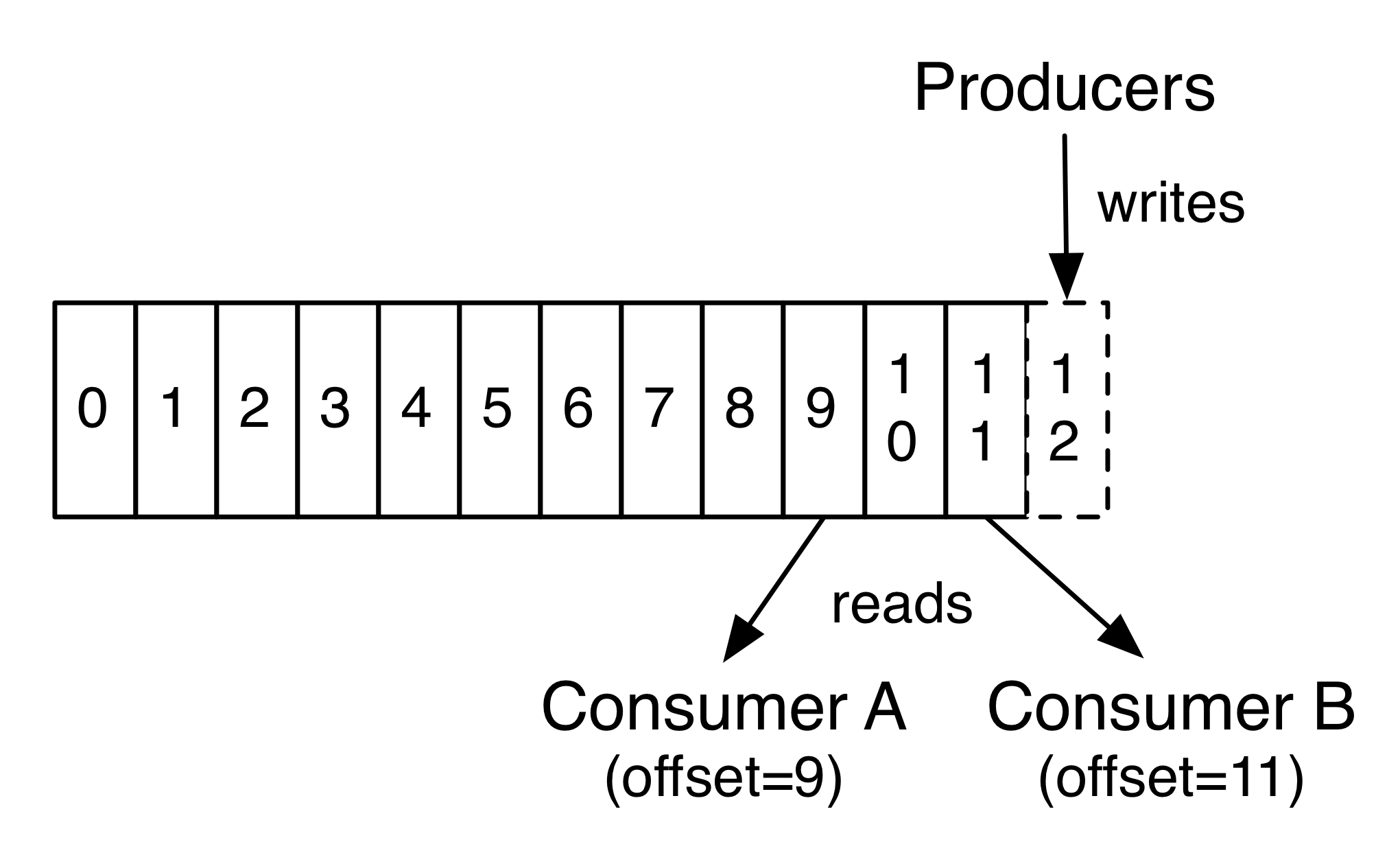
每一个分区(partition)都是一个顺序的、不可变的消息队列,并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。Kafka集群保持所有的消息,直到它们过期,无论消息是否被消费了。实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。 可以看到这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。 再说说分区。Kafka中采用分区可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。
二、kafka速成
1、下载kafka并解压
kafka下载地址,注意kafka需要zookeeper的服务,因此请确保kafka服务启动之前先运行zookeeper,请参考这篇文章。在kafka的bin目录下有 windows的文件夹 用于在windows环境下启动kafka
2、启动kafka服务
> bin/kafka-server-start.sh config/server.properties
[-- ::,] INFO Verifying properties (kafka.utils.VerifiableProperties)
[-- ::,] INFO Property socket.send.buffer.bytes is overridden to (kafka.utils.VerifiableProperties)
...
3、创建一个主题
我们用一个分区和一个副本创建一个名为“test”的主题:
> bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic test
然后我们可以运行如下命令查看是否已经创建成功:
> bin/kafka-topics.sh --list --zookeeper localhost:
test
当发送的主题不存在且想自动创建主题时,我们可以编辑config/server.properties
auto.create.topics.enable=true
default.replication.factor=
4、发送消息
Kafka附带一个命令行客户端,它将从文件或标准输入中获取输入,并将其作为消息发送到Kafka集群。默认情况下,每行将作为单独的消息发送。
> bin/kafka-console-producer.sh --broker-list localhost: --topic test
This is a message
This is another message
5、消费消息
> bin/kafka-console-consumer.sh --bootstrap-server localhost: --topic test --from-beginning
This is a message
This is another message
6、集群搭建
首先我们为每个代理创建一个配置文件(在Windows上使用该copy命令):
> cp config/server.properties config/server-.properties
> cp config/server.properties config/server-.properties
分别编辑上述文件:
config/server-.properties:
broker.id=
listeners=PLAINTEXT://:9093
log.dir=/tmp/kafka-logs- config/server-.properties:
broker.id=
listeners=PLAINTEXT://:9094
log.dir=/tmp/kafka-logs-
分别启动:
> bin/kafka-server-start.sh config/server-.properties &
...
> bin/kafka-server-start.sh config/server-.properties &
...
现在创建一个复制因子为三的新主题:
> bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic my-replicated-topic
我们可以通过以下命令查看状态:
> bin/kafka-topics.sh --describe --zookeeper localhost: --topic my-replicated-topic
Topic:my-replicated-topic PartitionCount: ReplicationFactor: Configs:
Topic: my-replicated-topic Partition: Leader: Replicas: ,, Isr: ,,
7、外网配置kafka注意事项
请编辑server.properties添加如下配置:
broker.id主要做集群时区别的编号
port 默认kafka端口号
host.name 设置为云内网地址
advertised.host.name 设置为云外网映射地址
三、spring中使用kafka
1、编辑gradle配置文件:
dependencies {
// https://mvnrepository.com/artifact/org.springframework/spring-context
compile group: 'org.springframework', name: 'spring-context', version: '5.0.4.RELEASE'
// https://mvnrepository.com/artifact/org.springframework/spring-web
compile group: 'org.springframework', name: 'spring-web', version: '5.0.4.RELEASE'
// https://mvnrepository.com/artifact/org.springframework/spring-context-support
compile group: 'org.springframework', name: 'spring-context-support', version: '5.0.4.RELEASE'
// https://mvnrepository.com/artifact/org.springframework/spring-webmvc
compile group: 'org.springframework', name: 'spring-webmvc', version: '5.0.4.RELEASE'
// https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka
compile group: 'org.springframework.kafka', name: 'spring-kafka', version: '2.1.4.RELEASE'
// https://mvnrepository.com/artifact/org.slf4j/slf4j-api
compile group: 'org.slf4j', name: 'slf4j-api', version: '1.7.25'
// https://mvnrepository.com/artifact/ch.qos.logback/logback-core
compile group: 'ch.qos.logback', name: 'logback-core', version: '1.2.3'
// https://mvnrepository.com/artifact/ch.qos.logback/logback-classic
testCompile group: 'ch.qos.logback', name: 'logback-classic', version: '1.2.3'
testCompile group: 'junit', name: 'junit', version: '4.12'
}
2、编写AppConfig配置文件类:
package com.hzgj.lyrk.spring.study.config; import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.*;
import org.springframework.stereotype.Component; import java.util.HashMap;
import java.util.Map; @Configuration
@EnableKafka
@ComponentScan
public class AppConfig { @Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> props = new HashMap<>(8);
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(props);
} @Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory(), true);
} @Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>(8);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return new DefaultKafkaConsumerFactory<>(props); } @Bean
public KafkaListenerContainerFactory kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConcurrency(3);
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setPollTimeout(3000);
return factory;
} @Component
static class Listener { @KafkaListener(id="client_one",topics = "test")
public void receive(String message) {
System.out.println("收到的消息为:" + message);
}
@KafkaListener(id="client_two",topics = "test1")
public void receive(Integer message) {
System.out.println("收到的的Integer消息为:" + message);
} }
}
3. 编写Main方法
package com.hzgj.lyrk.spring.study; import com.hzgj.lyrk.spring.study.config.AppConfig;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFutureCallback; public class Main { public static void main(String[] args) {
AnnotationConfigApplicationContext applicationContext = new AnnotationConfigApplicationContext(AppConfig.class);
KafkaTemplate<String, String> kafkaTemplate = applicationContext.getBean(KafkaTemplate.class);
kafkaTemplate.send("test", 0,"msg","{\"id\":2}").addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable ex) {
ex.printStackTrace();
} @Override
public void onSuccess(SendResult<String, String> result) {
System.out.println("发送消息成功....");
}
});
}
}
执行成功后得到如下结果:
kafka快速入门的更多相关文章
- docker安装kafka快速入门
docker安装kafka快速入门 1.安装zookeeper docker search zookeeperdocker pull zookeeperdocker run -d -v /home/s ...
- kafka快速入门(官方文档)
第1步:下载代码 下载 1.0.0版本并解压缩. > tar -xzf kafka_2.11-1.0.0.tgz > cd kafka_2.11-1.0.0 第2步:启动服务器 Kafka ...
- kafka快速入门到精通
目录 1. 消息队列两种模式 1.1 消息队列作用 1.2 点对点模式(一对一,消费者主动拉取数据,消息收到后消息删除) 1.3 发布/订阅模式(一对多,消费数据之后不会删除消息) 1.4 kafka ...
- Apache Kafka 快速入门
概述 Apache Kafka是一个分布式发布-订阅消息系统和强大的队列,可以处理大量的数据,将消息从一个端点传递到另一个端点.Kafka适合离线和在线消息消费,Kafka消息保存在磁盘上,并在集群内 ...
- Kafka 快速入门
Kafka Kafka 核心概念 什么是 Kafka Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.该项目的目标是为处理实时数据提供一个统一.高吞吐.低延迟 ...
- Kafka快速上手(2017.9官方翻译)
为了帮助国人更好了解.上手kafka,特意翻译.修改了个文档.官方Wiki : http://kafka.apache.org/quickstart 快速开始 本教程假定您正在开始新鲜,并且没有现有的 ...
- RocketMQ快速入门
前面几篇文章介绍了为什么选择RocketMQ,以及与kafka的一些对比: 阿里 RocketMQ 优势对比,方便大家对于RocketMQ有一个简单的整体了解,之后介绍了:MQ 应用场景,让我们知道M ...
- logstash快速入门实战指南-Logstash简介
作者其他ELK快速入门系列文章 Elasticsearch从入门到精通 Kibana从入门到精通 Logstash是一个具有实时流水线功能的开源数据收集引擎.Logstash可以动态统一来自不同来源的 ...
- Scala快速入门 - 基础语法篇
本篇文章首发于头条号Scala快速入门 - 基础语法篇,欢迎关注我的头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_tech)获取更多干货,也欢迎关注我的 ...
随机推荐
- Java 多线程 从无到有
个人总结:望对屏幕对面的您有所帮助 一. 线程概述 进程: 有独立的内存控件和系统资源 应用程序的执行实例 启动当前电脑任务管理器:taskmgr 进程是程序(任务)的执行过程,它持有资源(共享内存, ...
- 使用cxf创建webservice 出现timeOut的问题,设置spring超时时间
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.sp ...
- Linux知识积累(6) 系统目录及其用途
linux系统常见的重要目录以及各个目作用:/ 根目录.包含了几乎所有的文件目录.相当于中央系统.进入的最简单方法是:cd /./boot引导程序,内核等存放的目录.这个目录,包括了在引导过程中所必需 ...
- 新概念英语(1-55)The Sawyer family
新概念英语(1-55)The Sawyer family When do the children do their homework? The Sawyers live at 87 King Str ...
- Docker:云栖社区开源论题及Spark开源论题
https://yq.aliyun.com/topic/78?spm=5176.8290451.656547.7.rMYhAF https://yq.aliyun.com/activity/155?u ...
- [Kaggle] dogs-vs-cats之建立模型
建立神经网络模型,下面要建立的模型如下: (上图来源:训练网络时,打开tensorboard即可观察网络结构,在下一节模型训练的时候会讲到) 下面为具体步骤: Step 0:导入相关库 import ...
- STM32-正弦波可调(50HZ~20KHZ可调、峰峰值0~3.3V可调)
1.原理: 通过定时器每隔一段时间触发一次DAC转换,然后通过DMA发送正玄波码表值给DAC. 当需要改变频率HZ时,只需要修改定时器频率即可(最高只能达到20KHz) 当需要改变正玄波的正峰峰值/负 ...
- Python3 面向对象编程之程序设计思想发展
概述 1940年以前:面向机器 1940年以前:面向机器 最早的程序设计都是采用机器语言来编写的,直接使用二进制码来表示机器能够识别和执行的指令和数 据.简单来说,就是直接编写 和 的序列来代表程序语 ...
- SpringContextUtil 的配置和调用
首先:在springmvc里面配置 <bean id="springContextUtil" class="com.hna.hka.rmc.common.util. ...
- [LeetCode] Redundant Connection II 冗余的连接之二
In this problem, a rooted tree is a directed graph such that, there is exactly one node (the root) f ...