朴素贝叶斯分类法 Naive Bayes ---R
朴素贝叶斯算法
【转载时请注明来源】:http://www.cnblogs.com/runner-ljt/
Ljt 勿忘初心 无畏未来
作为一个初学者,水平有限,欢迎交流指正。
朴素贝叶斯分类法是一种生成学习算法。
假设:在y给定的条件下,各特征Xi 之间是相互独立的,即满足 : P(x1,x2.....xm | y)=∏ P(xi | y) (该算法朴素的体现之处)
原理: 贝叶斯公式
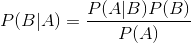
思想:对于待分类样本,求出在该样本的各特征出现的条件下,其属于每种类别的概率(P(Yi|X)),哪种类别的概率大就将该样本判别为哪一种类别。
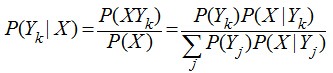
(P(X)为x的先验概率,与Y无关,在具体计算是分母可以直接忽略,只计算分子)
P(xi | y)的估计
(1)特征属性为离散值
直接用每一类别中各名录出现的频率作为其概率值P(xi|y)
(2)特征属性为连续性值
假设特征属性服从正太分布,用各类别的样本均值及标准差作为正态分布的参数。


Laplace 平滑
在训练样本中,某一特征的属性值可能没有出现,为了保证一个属性出现次数为0时,能够得到一个很小但是非0的概率值。
在计算P(xi|y)时分子加上 Pi*U ; 分母加上 U 。
其中Pi 表示xi 出现的先验概率,数值较大的U表示这些先验值是比较重要的,数值较小的U表示这些先验值的影响较小;
一般情况下,Pi=1/N . (N为该特征所含有的属性类的数目)
R实现
包:e1071 ; 函数:naiveBayes
>
> library(e1071)
> head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
> classifier<-naiveBayes(iris[,c(1:4)],iris[,5])
> classifier Naive Bayes Classifier for Discrete Predictors Call:
naiveBayes.default(x = iris[, c(1:4)], y = iris[, 5]) A-priori probabilities:
iris[, 5]
setosa versicolor virginica
0.3333333 0.3333333 0.3333333 Conditional probabilities:
Sepal.Length
iris[, 5] [,1] [,2]
setosa 5.006 0.3524897
versicolor 5.936 0.5161711
virginica 6.588 0.6358796 Sepal.Width
iris[, 5] [,1] [,2]
setosa 3.428 0.3790644
versicolor 2.770 0.3137983
virginica 2.974 0.3224966 Petal.Length
iris[, 5] [,1] [,2]
setosa 1.462 0.1736640
versicolor 4.260 0.4699110
virginica 5.552 0.5518947 Petal.Width
iris[, 5] [,1] [,2]
setosa 0.246 0.1053856
versicolor 1.326 0.1977527
virginica 2.026 0.2746501 > #A-priori probabilities 为 样本中个类别出现的频率
> #Conditional probabilities (该样本的特征属于连续型值)该值表示各特征在各类别上的服从正太分布下的均值和标准差
>
>
>
> #检验分类器效果
> table(predict(classifier,iris[,-5]),iris[,5]) setosa versicolor virginica
setosa 50 0 0
versicolor 0 47 3
virginica 0 3 47
>
> #构造新数据并进行预测
> newdata<-data.frame(Sepal.Length=5, Sepal.Width=2.3, Petal.Length=3.3, Petal.Width=1)
> predict(classifier,newdata)
[1] versicolor
Levels: setosa versicolor virginica
>
>
朴素贝叶斯分类法 Naive Bayes ---R的更多相关文章
- 数据挖掘十大经典算法(9) 朴素贝叶斯分类器 Naive Bayes
贝叶斯分类器 贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类.眼下研究较多的贝叶斯分类器主要有四种, ...
- 十大经典数据挖掘算法(9) 朴素贝叶斯分类器 Naive Bayes
贝叶斯分类器 贝叶斯分类分类原则是一个对象的通过先验概率.贝叶斯后验概率公式后计算,也就是说,该对象属于一类的概率.选择具有最大后验概率的类作为对象的类属.现在更多的研究贝叶斯分类器,有四个,每间:N ...
- 分类算法之朴素贝叶斯分类(Naive Bayesian Classification)
1.什么是分类 分类是一种重要的数据分析形式,它提取刻画重要数据类的模型.这种模型称为分类器,预测分类的(离散的,无序的)类标号.例如医生对病人进行诊断是一个典型的分类过程,医生不是一眼就看出病人得了 ...
- 朴素贝叶斯 Naive Bayes
2017-12-15 19:08:50 朴素贝叶斯分类器是一种典型的监督学习的算法,其英文是Naive Bayes.所谓Naive,就是天真的意思,当然这里翻译为朴素显得更学术化. 其核心思想就是利用 ...
- 机器学习算法实践:朴素贝叶斯 (Naive Bayes)(转载)
前言 上一篇<机器学习算法实践:决策树 (Decision Tree)>总结了决策树的实现,本文中我将一步步实现一个朴素贝叶斯分类器,并采用SMS垃圾短信语料库中的数据进行模型训练,对垃圾 ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
- R语言学习笔记—朴素贝叶斯分类
朴素贝叶斯分类(naive bayesian,nb)源于贝叶斯理论,其基本思想:假设样本属性之间相互独立,对于给定的待分类项,求解在此项出现的情况下其他各个类别出现的概率,哪个最大,就认为待分类项属于 ...
- 【机器学习速成宝典】模型篇05朴素贝叶斯【Naive Bayes】(Python版)
目录 先验概率与后验概率 条件概率公式.全概率公式.贝叶斯公式 什么是朴素贝叶斯(Naive Bayes) 拉普拉斯平滑(Laplace Smoothing) 应用:遇到连续变量怎么办?(多项式分布, ...
- javascript实现朴素贝叶斯分类与决策树ID3分类
今年毕业时的毕设是有关大数据及机器学习的题目.因为那个时间已经步入前端的行业自然选择使用JavaScript来实现其中具体的算法.虽然JavaScript不是做大数据处理的最佳语言,相比还没有优势,但 ...
随机推荐
- Git 常用命令速查表(图文+表格)
一. Git 常用命令速查 git branch 查看本地所有分支git status 查看当前状态 git commit 提交 git branch -a 查看所有的分支git branch -r ...
- Node.js 工具模块
在 Node.js 模块库中有很多好用的模块.接下来我们为大家介绍几种常用模块的使用: 序号 模块名 & 描述 1 OS 模块 提供基本的系统操作函数. 2 Path 模块提供了处理和转换文件 ...
- MongoDB 关系
MongoDB 的关系表示多个文档之间在逻辑上的相互联系. 文档间可以通过嵌入和引用来建立联系. MongoDB 中的关系可以是: 1:1 (1对1) 1: N (1对多) N: 1 (多对1) N: ...
- 初识在Spring Boot中使用JPA
前面关于Spring Boot的文章已经介绍了很多了,但是一直都没有涉及到数据库的操作问题,数据库操作当然也是我们在开发中无法回避的问题,那么今天我们就来看看Spring Boot给我们提供了哪些疯狂 ...
- 改善database schema
本文地址:http://blog.csdn.net/sushengmiyan/article/details/50422102 本文作者:苏生米沿 Hibernate 读取你java模型类的映射元数据 ...
- [OpenCV] 编译源程序 2.4.10 以支持 CUDA
对源代码进行如下修改: H:\Software\opencv\sources\modules\gpu\src\nvidia\core\NCV.cu中添加 #include <algorithm& ...
- python 列表解析与map和filter函数
不知哪儿看到一个说法,大概是当map的函数参数可以直接引用一个已有的函数变量时(比如内建函数int,str之类的),用map更优美些,否则还是用列表解析更直观和快速. 我同意此说法. 昨天在写一个函数 ...
- activiti 数据库连接配置
1.1.1. 前言 在activiti 动态配置 activiti 监听引擎启动和初始化(高级源码篇)一文中,我们讲解了如何动态的配置DataSource 当我们程序配置了DataSource,act ...
- SQLite 创建表(http://www.w3cschool.cc/sqlite/sqlite-create-table.html)
SQLite 创建表 SQLite 的 CREATE TABLE 语句用于在任何给定的数据库创建一个新表.创建基本表,涉及到命名表.定义列及每一列的数据类型. 语法 CREATE TABLE 语句的基 ...
- 3.关于QT中的MainWindow窗口,MenuBar,ToolBar,QuickTip等方面的知识点
1 新建一个空Qt项目 编写12MainWindow.pro HEADERS += \ MyMainWindow.h \ MyView.h SOURCES += \ MyMainWindow.c ...