Spark RDDs vs DataFrames vs SparkSQL
简介
Spark的 RDD、DataFrame 和 SparkSQL的性能比较。
2方面的比较
单条记录的随机查找
aggregation聚合并且sorting后输出
使用以下Spark的三种方式来解决上面的2个问题,对比性能。
Using RDD’s
Using DataFrames
Using SparkSQL
数据源
在HDFS中3个文件中存储的9百万不同记录
- 每条记录11个字段
总大小 1.4 GB
实验环境
HDP 2.4
Hadoop version 2.7
Spark 1.6
HDP Sandbox
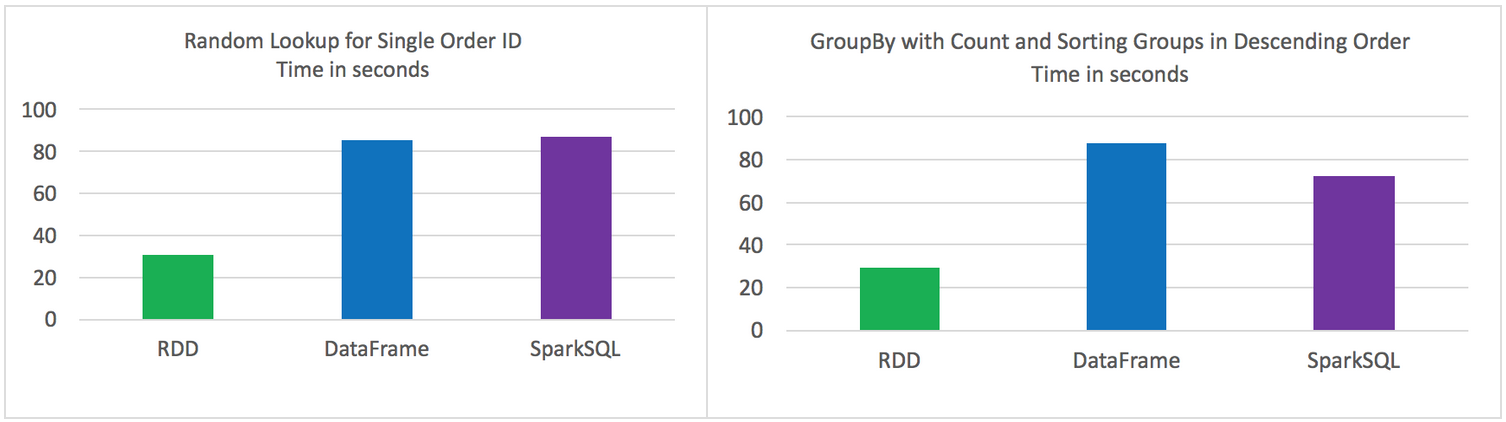
测试结果
原始的RDD 比 DataFrames 和 SparkSQL性能要好
DataFrames 和 SparkSQL 性能差不多
使用DataFrames 和 SparkSQL 比 RDD 操作更直观
Jobs都是独立运行,没有其他job的干扰
2个操作
Random lookup against 1 order ID from 9 Million unique order ID's
GROUP all the different products with their total COUNTS and SORT DESCENDING by product name
代码
RDD Random Lookup
#!/usr/bin/env python from time import time
from pyspark import SparkConf, SparkContext conf = (SparkConf()
.setAppName("rdd_random_lookup")
.set("spark.executor.instances", "")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf) t0 = time() path = "/data/customer_orders*"
lines = sc.textFile(path) ## filter where the order_id, the second field, is equal to 96922894
print lines.map(lambda line: line.split('|')).filter(lambda line: int(line[1]) == 96922894).collect() tt = str(time() - t0)
print "RDD lookup performed in " + tt + " seconds"
DataFrame Random Lookup
#!/usr/bin/env python from time import time
from pyspark.sql import *
from pyspark import SparkConf, SparkContext conf = (SparkConf()
.setAppName("data_frame_random_lookup")
.set("spark.executor.instances", "")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*"
lines = sc.textFile(path) ## create data frame
orders_df = sqlContext.createDataFrame( \
lines.map(lambda l: l.split("|")) \
.map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \
country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) ) ## filter where the order_id, the second field, is equal to 96922894
orders_df.where(orders_df['order_id'] == 96922894).show() tt = str(time() - t0)
print "DataFrame performed in " + tt + " seconds"
SparkSQL Random Lookup
#!/usr/bin/env python from time import time
from pyspark.sql import *
from pyspark import SparkConf, SparkContext conf = (SparkConf()
.setAppName("spark_sql_random_lookup")
.set("spark.executor.instances", "")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*"
lines = sc.textFile(path) ## create data frame
orders_df = sqlContext.createDataFrame( \
lines.map(lambda l: l.split("|")) \
.map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \
country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) ) ## register data frame as a temporary table
orders_df.registerTempTable("orders") ## filter where the customer_id, the first field, is equal to 96922894
print sqlContext.sql("SELECT * FROM orders where order_id = 96922894").collect() tt = str(time() - t0)
print "SparkSQL performed in " + tt + " seconds"
RDD with GroupBy, Count, and Sort Descending
#!/usr/bin/env python from time import time
from pyspark import SparkConf, SparkContext conf = (SparkConf()
.setAppName("rdd_aggregation_and_sort")
.set("spark.executor.instances", "")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf) t0 = time() path = "/data/customer_orders*"
lines = sc.textFile(path) counts = lines.map(lambda line: line.split('|')) \
.map(lambda x: (x[5], 1)) \
.reduceByKey(lambda a, b: a + b) \
.map(lambda x:(x[1],x[0])) \
.sortByKey(ascending=False) for x in counts.collect():
print x[1] + '\t' + str(x[0]) tt = str(time() - t0)
print "RDD GroupBy performed in " + tt + " seconds"
DataFrame with GroupBy, Count, and Sort Descending
#!/usr/bin/env python from time import time
from pyspark.sql import *
from pyspark import SparkConf, SparkContext conf = (SparkConf()
.setAppName("data_frame_aggregation_and_sort")
.set("spark.executor.instances", "")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*"
lines = sc.textFile(path) ## create data frame
orders_df = sqlContext.createDataFrame( \
lines.map(lambda l: l.split("|")) \
.map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \
country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) ) results = orders_df.groupBy(orders_df['product_desc']).count().sort("count",ascending=False) for x in results.collect():
print x tt = str(time() - t0)
print "DataFrame performed in " + tt + " seconds"
SparkSQL with GroupBy, Count, and Sort Descending
#!/usr/bin/env python from time import time
from pyspark.sql import *
from pyspark import SparkConf, SparkContext conf = (SparkConf()
.setAppName("spark_sql_aggregation_and_sort")
.set("spark.executor.instances", "")
.set("spark.executor.cores", 2)
.set("spark.dynamicAllocation.enabled", "false")
.set("spark.shuffle.service.enabled", "false")
.set("spark.executor.memory", "500MB"))
sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*"
lines = sc.textFile(path) ## create data frame
orders_df = sqlContext.createDataFrame(lines.map(lambda l: l.split("|")) \
.map(lambda r: Row(product=r[5]))) ## register data frame as a temporary table
orders_df.registerTempTable("orders") results = sqlContext.sql("SELECT product, count(*) AS total_count FROM orders GROUP BY product ORDER BY total_count DESC") for x in results.collect():
print x tt = str(time() - t0)
print "SparkSQL performed in " + tt + " seconds"
原文:https://community.hortonworks.com/articles/42027/rdd-vs-dataframe-vs-sparksql.html
Spark RDDs vs DataFrames vs SparkSQL的更多相关文章
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Effective Spark RDDs with Alluxio【转】
转自:http://kaimingwan.com/post/alluxio/effective-spark-rdds-with-alluxio 1. 介绍 2. 引言 3. Alluxio and S ...
- Spark(十二)SparkSQL简单使用
一.SparkSQL的进化之路 1.0以前: Shark 1.1.x开始:SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Datafram ...
- Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .SparkSQL的发展历程 1.1 Hive and Shark SparkSQL的前身是 ...
- Spark入门实战系列--6.SparkSQL(中)--深入了解SparkSQL运行计划及调优
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1.1 运行环境说明 1.1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软 ...
- Spark入门实战系列--6.SparkSQL(下)--Spark实战应用
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .运行环境说明 1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软件:VMwa ...
- 一个spark SQL和DataFrames的故事
package com.lin.spark import org.apache.spark.sql.{Row, SparkSession} import org.apache.spark.sql.ty ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark记录-SparkSql官方文档中文翻译(部分转载)
1 概述(Overview) Spark SQL是Spark的一个组件,用于结构化数据的计算.Spark SQL提供了一个称为DataFrames的编程抽象,DataFrames可以充当分布式SQL查 ...
随机推荐
- Acer Aspire E1 471G 加装SSD+机械盘后无法启动的问题
老笔记本 Acer Aspire E1 471G 加装了一块 SSD 作为系统盘(win10),原机械盘格式化后,装在光驱托架上作为数据盘. 可能会出现: 系统无法启动,显示找不到启动设备,并且在F2 ...
- 设计模式之 外观模式详解(Service第三者插足,让action与dao分手)
作者:zuoxiaolong8810(左潇龙),转载请注明出处,特别说明:本博文来自博主原博客,为保证新博客中博文的完整性,特复制到此留存,如需转载请注明新博客地址即可. 各位好,LZ今天给各位分享一 ...
- 两种设计模式和XML解析
两种设计模式 1.单例模式 模式的保证步骤:单例(是说在一个类中只能有一个对象)三条件 1.1类构造设置私有 private Play() { } 1.2 定义一个私有的静态的 类类型 变量 ...
- Python中的PYTHONPATH环境变量
PYTHONPATH是Python中一个重要的环境变量,用于在导入模块的时候搜索路径.可以通过如下方式访问: >>> import sys >>> sys.path ...
- Java基础学习笔记二十七 DBUtils和连接池
DBUtils 如果只使用JDBC进行开发,我们会发现冗余代码过多,为了简化JDBC开发,本案例我们讲采用apache commons组件一个成员:DBUtils.DBUtils就是JDBC的简化开发 ...
- JavaScript(第二天)【语法,变量】
一.语法构成 区分大小写 ECMAScript中的一切,包括变量.函数名和操作符都是区分大小写的.例如:text和Text表示两种不同的变量. 标识符 所谓标识符,就是指变量.函数.属性的名字,或 ...
- Beta阶段敏捷冲刺报告-DAY4
Beta阶段敏捷冲刺报告-DAY4 Scrum Meeting 敏捷开发日期 2017.11.5 会议时间 11:30 会议地点 羽毛球场 参会人员 全体成员 会议内容 bug的原因讨论, 测试内容安 ...
- 2017-2018-1 我爱学Java 第四五周 作业
<打地鼠>Android游戏--需求规格说明书 工作流程 组员分工及工作量比例 <需求规格说明书>的码云链接 总结与反思 参考资料 工作流程 小组成员预先参考蓝墨云班课第八周中 ...
- DML数据操作语言之查询(二)
当我们查询出了N条记录之后 ,我们知道一共是几条记录,或者这些记录某一字段(列值)的最大值,最小值,平均值等,就可以使用聚合函数. 1.聚合函数 聚合函数会将null 排除在外.但是count(*)例 ...
- 最短路算法模板SPFA、disjkstra、Floyd
朴素SPFA(链表建边) #include <iostream> #include <cstdio> #include <cstring> #include < ...