BiLstm与CRF实现命名实体标注
众所周知,通过Bilstm已经可以实现分词或命名实体标注了,同样地单独的CRF也可以很好的实现。既然LSTM都已经可以预测了,为啥要搞一个LSTM+CRF的hybrid model? 因为单独LSTM预测出来的标注可能会出现(I-Organization->I-Person,B-Organization ->I-Person)这样的问题序列。
但这种错误在CRF中是不存在的,因为CRF的特征函数的存在就是为了对输入序列观察、学习各种特征,这些特征就是在限定窗口size下的各种词之间的关系。
将CRF接在LSTM网络的输出结果后,让LSTM负责在CRF的特征限定下,依照新的loss function,学习出新的模型。
基于字的模型标注:
假定我们使用Bakeoff-3评测中所采用的的BIO标注集,即B-PER、I-PER代表人名首字、人名非首字,B-ORG、I-ORG代表组织机构名首字、组织机构名非首字,O代表该字不属于命名实体的一部分
- B-Person
- I- Person
- B-Organization
- I-Organization
- O
加入CRF layer对LSTM网络输出结果的影响
为直观的看到加入后的区别我们可以借用网络中的图来表示:其中\(x\)表示输入的句子,包含5个字分别用\(w_1\),\(w_2\),\(w_3\),\(w_4\),\(w_5\)表示
**没有CRF layer的网络示意图 **
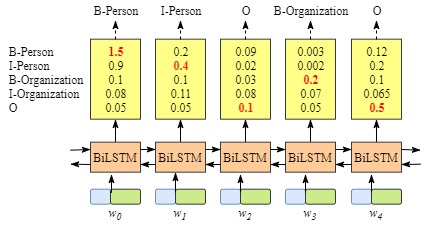
含有CRF layer的网络输出示意图
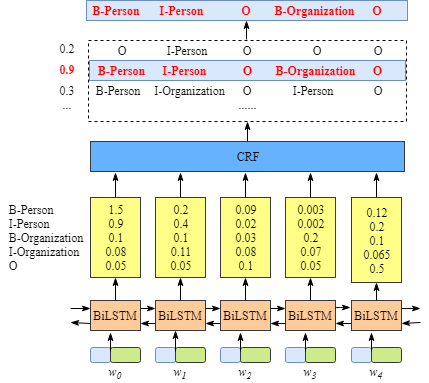
上图可以看到在没有CRF layer的情况下出现了 B-Person->I-Person 的序列,而在有CRF layer层的网络中,我们将 LSTM 的输出再次送入CRF layer中计算新的结果。而在CRF layer中会加入一些限制,以排除可能会出现上文所提及的不合法的情况
CRF loss function
CRF loss function 如下:
Loss Function = \(\frac{P_{RealPath}}{P_1 + P_2 + … + P_N}\)
主要包括两个部分Real path score 和 total path scroe
1、Real path score
\(P_{RealPath}\) =\(e^{S_i}\)
因此重点在于求出:
\(S_i\) = EmissionScore + TransitionScore
EmissionScore=\(x_{0,START}+x_{1,B-Person}+x_{2,I-Person}+x_{3,O}+x_{4,B-Organization}+x_{5,O}+x_{6,END}\)

因此根据转移概率和发射概率很容易求出\(P_{RealPath}\)
2、total score
total scroe的计算相对比较复杂,可参看https://createmomo.github.io/2017/11/11/CRF-Layer-on-the-Top-of-BiLSTM-5/
实现代码(keras版本)
1、搭建网络模型
使用2.1.4版本的keras,在keras版本里面已经包含bilstm模型,但crf的loss function还没有,不过可以从keras contribute中获得,具体可参看:https://github.com/keras-team/keras-contrib
构建网络模型代码如下:
model = Sequential()
model.add(Embedding(len(vocab), EMBED_DIM, mask_zero=True)) # Random embedding
model.add(Bidirectional(LSTM(BiRNN_UNITS // 2, return_sequences=True)))
crf = CRF(len(chunk_tags), sparse_target=True)
model.add(crf)
model.summary()
model.compile('adam', loss=crf.loss_function, metrics=[crf.accuracy])
2、清洗数据
清晰数据是最麻烦的一步,首先我们采用网上开源的语料库作为训练和测试数据。语料库中已经做好了标记,其格式如下:
月 O
油 O
印 O
的 O
《 O
北 B-LOC
京 I-LOC
文 O
物 O
保 O
存 O
保 O
管 O
语料库中对每一个字分别进行标记,比较包括如下几种:
'O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"
分别表示,其他,人名第一个,人名非第一个,位置第一个,位置非第一个,组织第一个,非组织第一个
train = _parse_data(open('data/train_data.data', 'rb'))
test = _parse_data(open('data/test_data.data', 'rb'))
word_counts = Counter(row[0].lower() for sample in train for row in sample)
vocab = [w for w, f in iter(word_counts.items()) if f >= 2]
chunk_tags = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]
# save initial config data
with open('model/config.pkl', 'wb') as outp:
pickle.dump((vocab, chunk_tags), outp)
train = _process_data(train, vocab, chunk_tags)
test = _process_data(test, vocab, chunk_tags)
return train, test, (vocab, chunk_tags)
3、训练数据
在处理好数据后可以训练数据,本文中将batch-size=16获得较为高的accuracy(99%左右),进行了10个epoch的训练。
import bilsm_crf_model
EPOCHS = 10
model, (train_x, train_y), (test_x, test_y) = bilsm_crf_model.create_model()
# train model
model.fit(train_x, train_y,batch_size=16,epochs=EPOCHS, validation_data=[test_x, test_y])
model.save('model/crf.h5')
4、验证数据
import bilsm_crf_model
import process_data
import numpy as np
model, (vocab, chunk_tags) = bilsm_crf_model.create_model(train=False)
predict_text = '中华人民共和国国务院总理周恩来在外交部长陈毅的陪同下,连续访问了埃塞俄比亚等非洲10国以及阿尔巴尼亚'
str, length = process_data.process_data(predict_text, vocab)
model.load_weights('model/crf.h5')
raw = model.predict(str)[0][-length:]
result = [np.argmax(row) for row in raw]
result_tags = [chunk_tags[i] for i in result]
per, loc, org = '', '', ''
for s, t in zip(predict_text, result_tags):
if t in ('B-PER', 'I-PER'):
per += ' ' + s if (t == 'B-PER') else s
if t in ('B-ORG', 'I-ORG'):
org += ' ' + s if (t == 'B-ORG') else s
if t in ('B-LOC', 'I-LOC'):
loc += ' ' + s if (t == 'B-LOC') else s
print(['person:' + per, 'location:' + loc, 'organzation:' + org])
输出结果如下:
['person: 周恩来 陈毅, 王东', 'location: 埃塞俄比亚 非洲 阿尔巴尼亚', 'organzation: 中华人民共和国国务院 外交部']
源码地址:https://github.com/stephen-v/zh-NER-keras
BiLstm与CRF实现命名实体标注的更多相关文章
- 基于keras的BiLstm与CRF实现命名实体标注
众所周知,通过Bilstm已经可以实现分词或命名实体标注了,同样地单独的CRF也可以很好的实现.既然LSTM都已经可以预测了,为啥要搞一个LSTM+CRF的hybrid model? 因为单独LSTM ...
- bi-Lstm +CRF 实现命名实体标注
1. https://blog.csdn.net/buppt/article/details/82227030 (Bilstm+crf中的crf详解,包括是整体架构) 2. 邹博关于CRF的讲解视频 ...
- 用CRF做命名实体识别(一)
用CRF做命名实体识别(二) 用CRF做命名实体识别(三) 用BILSTM-CRF做命名实体识别 博客园的markdown格式可能不太方便看,也欢迎大家去我的简书里看 摘要 本文主要讲述了关于人民日报 ...
- 用CRF做命名实体识别(二)
用CRF做命名实体识别(一) 用CRF做命名实体识别(三) 一. 摘要 本文是对上文用CRF做命名实体识别(一)做一次升级.多添加了5个特征(分别是词性,词语边界,人名,地名,组织名指示词),另外还修 ...
- 使用CRF做命名实体识别(三)
摘要 本文主要是对近期做的命名实体识别做一个总结,会给出构造一个特征的大概思路,以及对比所有构造的特征对结构的影响.先给出我最近做出来的特征对比: 目录 整体操作流程 特征的构造思路 用CRF++训练 ...
- PyTorch 高级实战教程:基于 BI-LSTM CRF 实现命名实体识别和中文分词
前言:译者实测 PyTorch 代码非常简洁易懂,只需要将中文分词的数据集预处理成作者提到的格式,即可很快的就迁移了这个代码到中文分词中,相关的代码后续将会分享. 具体的数据格式,这种方式并不适合处理 ...
- NLP入门(八)使用CRF++实现命名实体识别(NER)
CRF与NER简介 CRF,英文全称为conditional random field, 中文名为条件随机场,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机 ...
- Bi-LSTM+CRF在文本序列标注中的应用
传统 CRF 中的输入 X 向量一般是 word 的 one-hot 形式,前面提到这种形式的输入损失了很多词语的语义信息.有了词嵌入方法之后,词向量形式的词表征一般效果比 one-hot 表示的特征 ...
- Pytorch: 命名实体识别: BertForTokenClassification/pytorch-crf
文章目录基本介绍BertForTokenClassificationpytorch-crf实验项目参考基本介绍命名实体识别:命名实体识别任务是NLP中的一个基础任务.主要是从一句话中识别出命名实体.比 ...
随机推荐
- 【前端】Vue2全家桶案例《看漫画》之一、添加四个导航页
转载请注明出处:http://www.cnblogs.com/shamoyuu/p/vue_vux_app_1.html 项目github地址:https://github.com/shamoyuu/ ...
- caffe+GPU︱AWS.G2+Ubuntu14.04+GPU+CUDA8.0+cudnn8.0
国服亚马逊的GPU实例G2.2xlarge的python+caffe的安装过程,被虐- 一周才装出来- BVLC/caffe的在AWS安装的官方教程github: https://github.com ...
- hi3531的hifb显示1080p60Hz
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h&g ...
- JSP标签c:forEach报错(一)
1.jsp标签c:forEach报错,具体错误如下: 三月 31, 2014 9:31:14 下午 org.apache.catalina.core.StandardWrapperValve invo ...
- 做一个合格的Team Leader -- 基本概念
1.领导和管理 人们乐于被领导:他们不喜欢被管理,不喜欢像牛一样被驱赶或指挥. 管理者强迫人们服从他们的命令,而领导者则会带领他们一起工作. 管理是客观的,没有个人感情因素,它假定被管理者没有思想和感 ...
- FAT32文件系统的存储组织结构(二)
前面已经基于一个格式化的空U盘分析了一下FAT32文件系统存储的组织结构,下面我们从文件操作的角度来分析一下文件系统的运作机制.由于换了个U盘,所以仍然贴出刚格式化的空U盘的几个重要的数据区如下: ...
- Android 开发环境搭建与Hello World
Hello World 到这里, 环境搭建就没问题了. 接下来, 创建一个Android 的Hello World. 1. 添加一个安卓虚拟设备 直接点击虚拟设备管理图标或是 Window--&g ...
- 如何注册Filter
AX文件的一个对外接口DllRegisterServer,由外部调用,比如注册AX的时候:regsvr32 xxx.ax 通常情况下,我们的filter可能注册在"Direct ...
- VMware vSphere学习整理
知识点整理 内存选择 一般来说,每个虚拟机需要的内存在1~4GB甚至更多,还要为VMware ESXi预留一部分内存 2个6核的2U服务器配置64GB内存,4个6核或8核心的4U服务器配置128GB或 ...
- java 中的值传递和引用传递
public class PassValue { /** * 值传递 基本数据类型参数 * 值传递:方法调用时,实际参数吧他的值传递给对应的形式参数,方法执行中形式参数值的改变不影响实际参数的值 */ ...