SpringBoot开发案例之多任务并行+线程池处理

前言
前几篇文章着重介绍了后端服务数据库和多线程并行处理优化,并示例了改造前后的伪代码逻辑。当然了,优化是无止境的,前人栽树后人乘凉。作为我们开发者来说,既然站在了巨人的肩膀上,就要写出更加优化的程序。
改造
理论上讲,线程越多程序可能更快,但是在实际使用中我们需要考虑到线程本身的创建以及销毁的资源消耗,以及保护操作系统本身的目的。我们通常需要将线程限制在一定的范围之类,线程池就起到了这样的作用。
程序逻辑
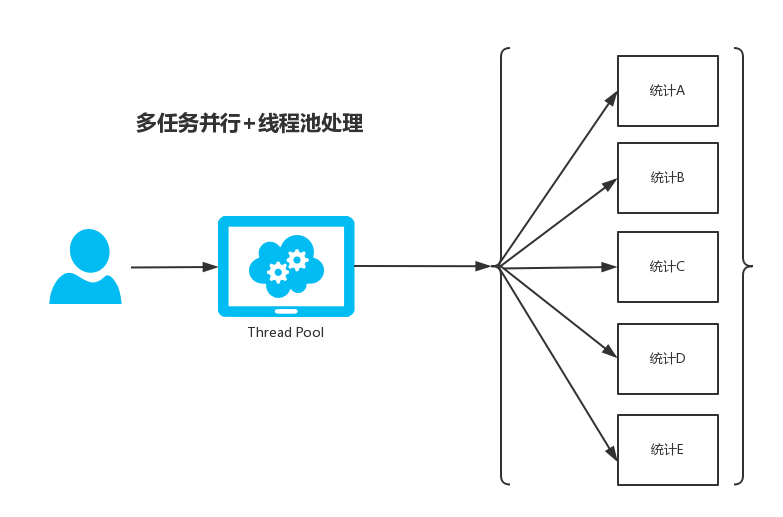
一张图能解决的问题,就应该尽可能的少BB,当然底层原理性的东西还是需要大家去记忆并理解的。
Java 线程池
Java通过Executors提供四种线程池,分别为:
- newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
- newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
- newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
优点
- 重用存在的线程,减少对象创建、消亡的开销,性能佳。
- 可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。
- 提供定时执行、定期执行、单线程、并发数控制等功能。
代码实现
方式一(CountDownLatch)
/**
* 多任务并行+线程池统计
* 创建者 科帮网 https://blog.52itstyle.com
* 创建时间 2018年4月17日
*/
public class StatsDemo {
final static SimpleDateFormat sdf = new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss");
final static String startTime = sdf.format(new Date());
/**
* IO密集型任务 = 一般为2*CPU核心数(常出现于线程中:数据库数据交互、文件上传下载、网络数据传输等等)
* CPU密集型任务 = 一般为CPU核心数+1(常出现于线程中:复杂算法)
* 混合型任务 = 视机器配置和复杂度自测而定
*/
private static int corePoolSize = Runtime.getRuntime().availableProcessors();
/**
* public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,
* TimeUnit unit,BlockingQueue<Runnable> workQueue)
* corePoolSize用于指定核心线程数量
* maximumPoolSize指定最大线程数
* keepAliveTime和TimeUnit指定线程空闲后的最大存活时间
* workQueue则是线程池的缓冲队列,还未执行的线程会在队列中等待
* 监控队列长度,确保队列有界
* 不当的线程池大小会使得处理速度变慢,稳定性下降,并且导致内存泄露。如果配置的线程过少,则队列会持续变大,消耗过多内存。
* 而过多的线程又会 由于频繁的上下文切换导致整个系统的速度变缓——殊途而同归。队列的长度至关重要,它必须得是有界的,这样如果线程池不堪重负了它可以暂时拒绝掉新的请求。
* ExecutorService 默认的实现是一个无界的 LinkedBlockingQueue。
*/
private static ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, corePoolSize+1, 10l, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(1000));
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(5);
//使用execute方法
executor.execute(new Stats("任务A", 1000, latch));
executor.execute(new Stats("任务B", 1000, latch));
executor.execute(new Stats("任务C", 1000, latch));
executor.execute(new Stats("任务D", 1000, latch));
executor.execute(new Stats("任务E", 1000, latch));
latch.await();// 等待所有人任务结束
System.out.println("所有的统计任务执行完成:" + sdf.format(new Date()));
}
static class Stats implements Runnable {
String statsName;
int runTime;
CountDownLatch latch;
public Stats(String statsName, int runTime, CountDownLatch latch) {
this.statsName = statsName;
this.runTime = runTime;
this.latch = latch;
}
public void run() {
try {
System.out.println(statsName+ " do stats begin at "+ startTime);
//模拟任务执行时间
Thread.sleep(runTime);
System.out.println(statsName + " do stats complete at "+ sdf.format(new Date()));
latch.countDown();//单次任务结束,计数器减一
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
方式二(Future)
/**
* 多任务并行+线程池统计
* 创建者 科帮网 https://blog.52itstyle.com
* 创建时间 2018年4月17日
*/
public class StatsDemo {
final static SimpleDateFormat sdf = new SimpleDateFormat(
"yyyy-MM-dd HH:mm:ss");
final static String startTime = sdf.format(new Date());
/**
* IO密集型任务 = 一般为2*CPU核心数(常出现于线程中:数据库数据交互、文件上传下载、网络数据传输等等)
* CPU密集型任务 = 一般为CPU核心数+1(常出现于线程中:复杂算法)
* 混合型任务 = 视机器配置和复杂度自测而定
*/
private static int corePoolSize = Runtime.getRuntime().availableProcessors();
/**
* public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,
* TimeUnit unit,BlockingQueue<Runnable> workQueue)
* corePoolSize用于指定核心线程数量
* maximumPoolSize指定最大线程数
* keepAliveTime和TimeUnit指定线程空闲后的最大存活时间
* workQueue则是线程池的缓冲队列,还未执行的线程会在队列中等待
* 监控队列长度,确保队列有界
* 不当的线程池大小会使得处理速度变慢,稳定性下降,并且导致内存泄露。如果配置的线程过少,则队列会持续变大,消耗过多内存。
* 而过多的线程又会 由于频繁的上下文切换导致整个系统的速度变缓——殊途而同归。队列的长度至关重要,它必须得是有界的,这样如果线程池不堪重负了它可以暂时拒绝掉新的请求。
* ExecutorService 默认的实现是一个无界的 LinkedBlockingQueue。
*/
private static ThreadPoolExecutor executor = new ThreadPoolExecutor(corePoolSize, corePoolSize+1, 10l, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(1000));
public static void main(String[] args) throws InterruptedException {
List<Future<String>> resultList = new ArrayList<Future<String>>();
//使用submit提交异步任务,并且获取返回值为future
resultList.add(executor.submit(new Stats("任务A", 1000)));
resultList.add(executor.submit(new Stats("任务B", 1000)));
resultList.add(executor.submit(new Stats("任务C", 1000)));
resultList.add(executor.submit(new Stats("任务D", 1000)));
resultList.add(executor.submit(new Stats("任务E", 1000)));
//遍历任务的结果
for (Future<String> fs : resultList) {
try {
System.out.println(fs.get());//打印各个线任务执行的结果,调用future.get() 阻塞主线程,获取异步任务的返回结果
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
//启动一次顺序关闭,执行以前提交的任务,但不接受新任务。如果已经关闭,则调用没有其他作用。
executor.shutdown();
}
}
System.out.println("所有的统计任务执行完成:" + sdf.format(new Date()));
}
static class Stats implements Callable<String> {
String statsName;
int runTime;
public Stats(String statsName, int runTime) {
this.statsName = statsName;
this.runTime = runTime;
}
public String call() {
try {
System.out.println(statsName+ " do stats begin at "+ startTime);
//模拟任务执行时间
Thread.sleep(runTime);
System.out.println(statsName + " do stats complete at "+ sdf.format(new Date()));
} catch (InterruptedException e) {
e.printStackTrace();
}
return call();
}
}
}
执行时间
以上代码,均是伪代码,下面是2000+个学生的真实测试记录。
2018-04-17 17:42:29.284 INFO 测试记录81e51ab031eb4ada92743ddf66528d82-单线程顺序执行,花费时间:3797
2018-04-17 17:42:31.452 INFO 测试记录81e51ab031eb4ada92743ddf66528d82-多线程并行任务,花费时间:2167
2018-04-17 17:42:33.170 INFO 测试记录81e51ab031eb4ada92743ddf66528d82-多线程并行任务+线程池,花费时间:1717
SpringBoot开发案例之多任务并行+线程池处理的更多相关文章
- springboot之多任务并行+线程池处理
最近项目中做到一个关于批量发短信的业务,如果用户量特别大的话,不能使用单线程去发短信,只能尝试着使用多任务来完成!我们的项目使用到了方式二,即Future的方案 Java 线程池 Java通过Exec ...
- SpringBoot开发案例从0到1构建分布式秒杀系统
前言 最近,被推送了不少秒杀架构的文章,忙里偷闲自己也总结了一下互联网平台秒杀架构设计,当然也借鉴了不少同学的思路.俗话说,脱离案例讲架构都是耍流氓,最终使用SpringBoot模拟实现了部分秒杀场 ...
- SpringBoot开发案例之整合Dubbo分布式服务
前言 在 SpringBoot 很火热的时候,阿里巴巴的分布式框架 Dubbo 不知是处于什么考虑,在停更N年之后终于进行维护了.在之前的微服务中,使用的是当当维护的版本 Dubbox,整合方式也是使 ...
- 【玩转SpringBoot】异步任务执行与其线程池配置
同步代码写起来简单,但就是怕遇到耗时操作,会影响效率和吞吐量. 此时异步代码才是王者,但涉及多线程和线程池,以及异步结果的获取,写起来颇为麻烦. 不过在遇到SpringBoot异步任务时,这个问题就不 ...
- Springboot学习笔记(一)-线程池的简化及使用
工作中经常涉及异步任务,通常是使用多线程技术,比如线程池ThreadPoolExecutor,它的执行规则如下: 在Springboot中对其进行了简化处理,只需要配置一个类型为java.util.c ...
- SpringBoot异步使用@Async原理及线程池配置
前言 在实际项目开发中很多业务场景需要使用异步去完成,比如消息通知,日志记录,等非常常用的都可以通过异步去执行,提高效率,那么在Spring框架中应该如何去使用异步呢 使用步骤 完成异步操作一般有两种 ...
- SpringBoot开发案例之整合Kafka实现消息队列
前言 最近在做一款秒杀的案例,涉及到了同步锁.数据库锁.分布式锁.进程内队列以及分布式消息队列,这里对SpringBoot集成Kafka实现消息队列做一个简单的记录. Kafka简介 Kafka是由A ...
- SpringBoot开发案例之打造私有云网盘
前言 最近在做工作流的事情,正好有个需求,要添加一个附件上传的功能,曾找过不少上传插件,都不是特别满意.无意中发现一个很好用的开源web文件管理器插件 elfinder,功能比较完善,社区也很活跃,还 ...
- SpringBoot开发案例之整合Activiti工作流引擎
前言 JBPM是目前市场上主流开源工作引擎之一,在创建者Tom Baeyens离开JBoss后,JBPM的下一个版本jBPM5完全放弃了jBPM4的基础代码,基于Drools Flow重头来过,目前官 ...
随机推荐
- 怎样把Linux的私钥文件id_rsa转换成putty的ppk格式
在Linux VPS下产生的私钥文件putty是不认识的,putty只认识自己的ppk格式,要在这两种格式之间转换,需要PuTTYgen这个程序. puttygen是putty的配套程序,putty的 ...
- .Net开发之旅(一个年少轻狂的程序员的感慨)
高端大气上档次.这次当时一个身为懵懂初中生的我对程序员这一职位的描述.那时虽不是随处都能看到黑客大军的波及,但至少是知道所谓的黑客爸爸的厉害,一言不合说被黑就被黑.对于懵懂的我那是一种向往.自己也曾想 ...
- 客户端(winform)更新
winform更新有两种情况,一种是在线更新在线使用:直接右击项目发布出去就可以更新在线使用了.还有一种更新是不用一直连接网络的模式. 1:C#Winform程序如何发布并自动升级--------ht ...
- JavaWeb学习笔记九 过滤器、注解
过滤器Filter filter是对客户端访问资源的过滤,符合条件放行,不符合条件不放行,并且可以对目标资源访问前后进行逻辑处理. 步骤: 编写一个过滤器的类实现Filter接口 实现接口中尚未实现的 ...
- Java基础学习笔记十 Java基础语法之final、static、匿名对象、内部类
final关键字 继承的出现提高了代码的复用性,并方便开发.但随之也有问题,有些类在描述完之后,不想被继承,或者有些类中的部分方法功能是固定的,不想让子类重写.可是当子类继承了这些特殊类之后,就可以对 ...
- Redux----Regular的Redux实现整理
Regular的Redux实现整理 什么问题? 组件的树形结构决定了数据的流向,导致的数据传递黑洞 怎么解决? 所有组件都通过中介者传递共享数据 方案: 中介者: (function create ...
- C语言的第二次作业
一.PTA实验作业 题目1. 计算分段函数 本题目要求计算下列分段函数f(x)的值: 1.本题代码 #include<stdio.h> #include<math.h> int ...
- 2017-2018-1 我爱学Java 第二周 作业
Android Game Discussion Questions Answers 20162309邢天岳 20162311张之睿 20162312张家铖 20162313苑洪铭 20162324春旺 ...
- iOS 播放音频的几种方法
Phone OS 主要提供以下了几种播放音频的方法: System Sound Services AVAudioPlayer 类 Audio Queue Services OpenAL 1. Syst ...
- 201421123042 《Java程序设计》第8周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图或其他)归纳总结集合相关内容. 2. 书面作业 1. ArrayList代码分析 1.1 解释ArrayList的contains源代码 源代码: 答:查找 ...