汽车之家店铺商品详情数据抓取 DotnetSpider实战[二]
一、迟到的下期预告
自从上一篇文章发布到现在,大约差不多有3个月的样子,其实一直想把这个实战入门系列的教程写完,一个是为了支持DotnetSpider,二个是为了.Net 社区发展献出一份绵薄之力,这个开源项目作者一直都在更新,相对来说还是很不错的,上次教程的版本还是2.4.4,今天浏览了一下这个项目,最近一次更新是在3天前,已经更新到了2.5.0,而且项目star也已经超过1000了,还是挺受大家所喜爱的,也在这感谢作者们不断的努力。

之所以中间这么长一段时间没有好好写文章,是因为笔者为参加3月份PMP考试备考了,然后考完差不多就到4月份,到了4月份,项目催的急,所以一直拖到了现在才有一点空余时间,希望我的文章完成之后,会对大家有一定的帮助。
二、更新DotnetSpider库
刚刚提到DotnetSpider升级到了2.5.0,所以我们更新一下库,使用最新的版本,技术要与时俱进嘛,将下图中两个类库添加进去就行了。
三、分析汽车之家商品详情页面
3.1分析商品详情页数据
①上次我们发现,当点击参数配置的时候,页面会发送两个ajax请求,分别去获取车型的基本参数,和配置参数,返回的数据是JSON格式。
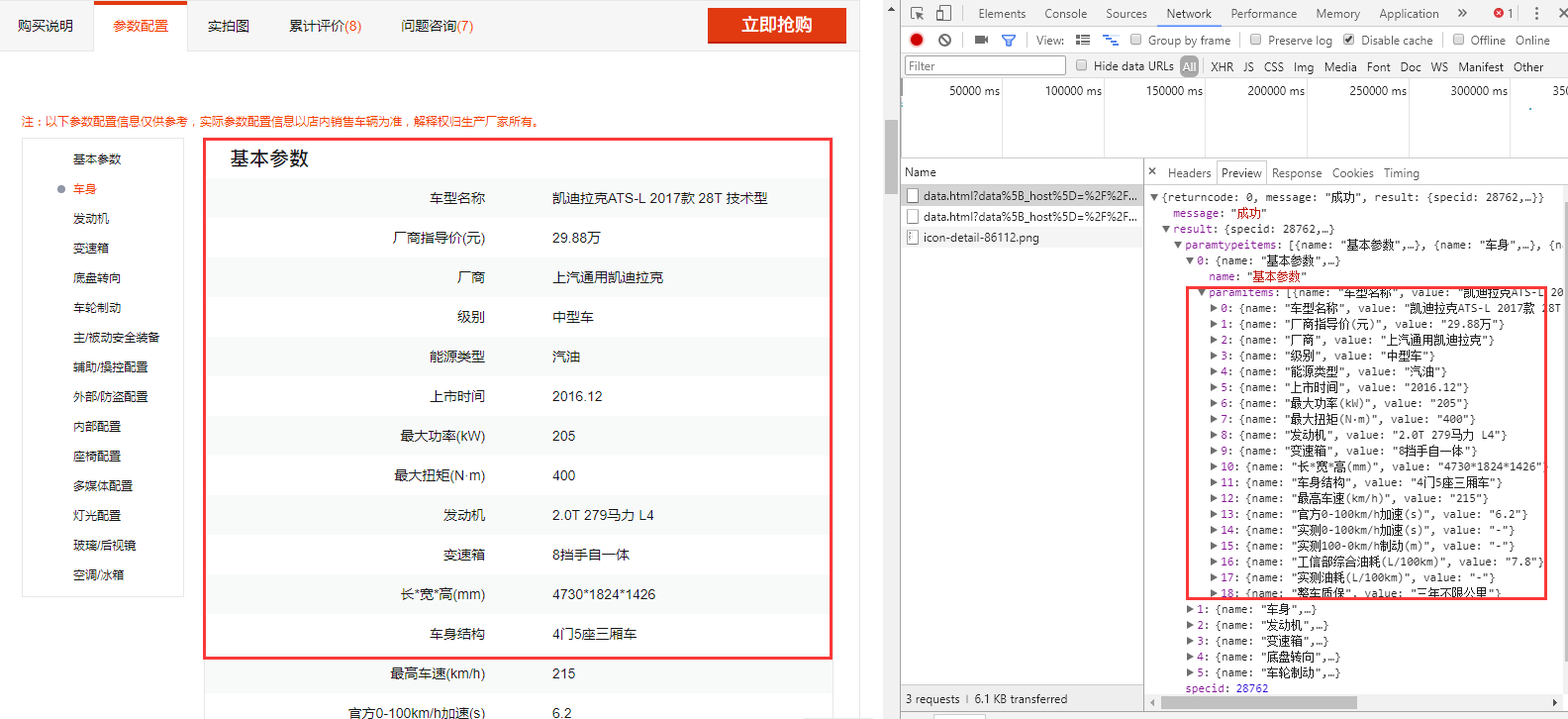
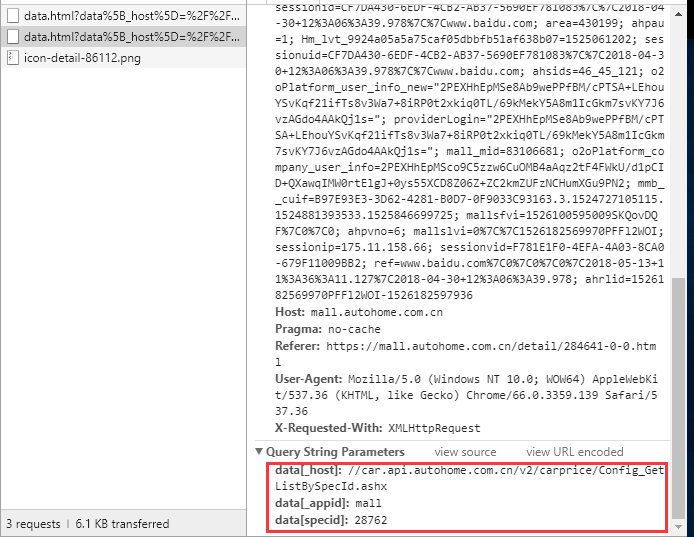
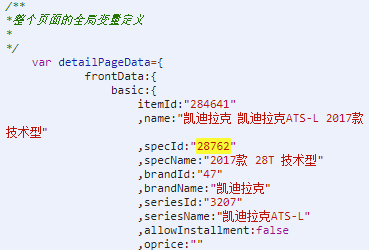
②通过Chrome的Network抓包可以发现,这两个请求有一个共同点,提交的参数都有data[specid]:28762,我猜测这应该是skuid,大家可以试着在浏览器直接打开这两个地址,直接就可以返回出车型的相关信息,所以问题的关键就是要解决如何获取skuid的问题,获取到了这些车型的数据那不就是手到擒来了。
3.2如何获取商品的sku
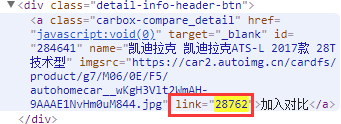
其实这个确实是让我很苦恼的一个问题,因为我们打开页面的时候页面的链接中并未包含skuid,[https://mall.autohome.com.cn/detail/284641-0-0.html],所以从URL中获取是不太现实的了,所以我用Element去页面中搜索这个skuid的值,结果发现两个地方有这个值,一个存在于HTML元素中,一个是存在js全局变量中,相比较而言,我认为HTML元素中的相对来说会比较好处理一点,直接获取元素的属性就行了。
四、开发
4.1准备Processor
这次为什么要单独的写一段准备Processor呢,因为此次准备了三个Processor,分别用来处理3个数据,第一个用于获取skuid,第二个用于获取车型基本参数,第三个用于获取车型配置,细心的小伙伴们肯定会发现,这次我们每个Processor都使用了构造函数,里面可以清晰的看到有我们熟悉的正则表达式(PS正则表达式写的很烂,自己有更好的正则写法可以回复在评论里面,让我膜拜一下,嘻嘻),肯定会有人问为什么要这么写呢?
相比上次的教程,这次的抓取流程更为的复杂了,上次我们只是抓了一个列表页,一个接口完全可以搞定,此次我们的流程变成了,第一步,我们需要获取车型详情页的页面,从页面中找到skuid,第二部,将获取的skuid拼接好request放入爬虫的请求集合中,通过新构造的请求去获取数据,那么我们怎么知道哪个请求用哪个Processor进行处理呢,DotnetSpider提供了对url进行校验的进行判断,使用哪个Processor对数据进行处理。
private class GetSkuProcessor : BasePageProcessor //获取skuid
{
public GetSkuProcessor()
{
TargetUrlsExtractor = new RegionAndPatternTargetUrlsExtractor(".", @"^https:\/\/mall.autohome.com.cn\/detail\/*[0-9]+-[0-9]+-[0-9]+\.html$");
}
protected override void Handle(Page page)
{
string skuid = string.Empty;
skuid = page.Selectable.XPath(".//a[@class='carbox-compare_detail']/@link").GetValue();
page.AddResultItem("skuid", skuid);
page.AddTargetRequest(@"https://mall.autohome.com.cn/http/data.html?data[_host]=//car.api.autohome.com.cn/v1/carprice/spec_paramsinglebyspecid.ashx&data[_appid]=mall&data[specid]=" + skuid);
page.AddTargetRequest(@"https://mall.autohome.com.cn/http/data.html?data[_host]=//car.api.autohome.com.cn/v2/carprice/Config_GetListBySpecId.ashx&data[_appid]=mall&data[specid]=" + skuid);
} }
private class GetBasicInfoProcessor : BasePageProcessor //获取车型基本参数
{
public GetBasicInfoProcessor()
{
TargetUrlsExtractor = new RegionAndPatternTargetUrlsExtractor(".", @"^https://mall\.autohome\.com\.cn/http/data\.html\?data\[_host\]=//car\.api\.autohome\.com\.cn/v1/carprice/spec_paramsinglebyspecid\.ashx*");
}
protected override void Handle(Page page)
{
page.AddResultItem("BaseInfo", page.Content);
}
} private class GetExtInfoProcessor : BasePageProcessor //获取车型配置
{
public GetExtInfoProcessor()
{
TargetUrlsExtractor = new RegionAndPatternTargetUrlsExtractor(".", @"^https://mall\.autohome\.com\.cn\/http\/data\.html\?data\[_host\]=//car\.api\.autohome\.com\.cn/v2/carprice/Config_GetListBySpecId\.ashx*");
}
protected override void Handle(Page page)
{
page.AddResultItem("ExtInfo", page.Content);
}
}
4.2、创建Pipeline
Pipeline基本上变化不大,稍微改造了一下,so easy。
private class PrintSkuPipe : BasePipeline
{ public override void Process(IEnumerable<ResultItems> resultItems, ISpider spider)
{
foreach (var resultItem in resultItems)
{
if (resultItem.GetResultItem("skuid") != null)
{
Console.WriteLine(resultItem.Results["skuid"] as string);
}
if (resultItem.GetResultItem("BaseInfo") != null)
{
var t = JsonConvert.DeserializeObject<AutoCarParam>(resultItem.Results["BaseInfo"]);
//Console.WriteLine(resultItem.Results["BaseInfo"]);
}
if (resultItem.GetResultItem("ExtInfo") != null)
{
var t = JsonConvert.DeserializeObject<AutoCarConfig>(resultItem.Results["ExtInfo"]);
//Console.WriteLine(resultItem.Results["ExtInfo"]);
} } }
}
新增两个实体类AutoCarParam,AutoCarConfig,其实有重复的,子项可以再进行抽象一下,代码可以减少,还可以节省一点硬盘空间
public class AutoCarConfig
{
public string message { get; set; }
public ConfigResult result { get; set; }
public string returncode { get; set; }
}
public class ConfigResult
{
public string specid { get; set; } public List<configtypeitem> configtypeitems { get; set; }
} public class configtypeitem
{
public string name { get; set; }
public List<configitem> configitems { get; set; }
}
public class configitem
{
public string name { get; set; }
public string value { get; set; }
} public class AutoCarParam
{
public string message { get; set; }
public ParamResult result { get; set; }
public string returncode { get; set; }
} public class ParamResult
{
public string specid { get; set; } public List<paramtypeitem> paramtypeitems { get; set; }
} public class paramtypeitem
{
public string name { get; set; }
public List<paramitem> paramitems { get;set;}
}
public class paramitem
{
public string name { get; set; }
public string value { get; set; }
}
4.3、构造爬虫
这一块变化也不是很大,变化的的地方看我的注释,因为我们需要有多个Processor,把这几个都添加进去就行。
var site = new Site
{
CycleRetryTimes = ,
SleepTime = ,
Headers = new Dictionary<string, string>()
{
{ "Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8" },
{ "Cache-Control","no-cache" },
{ "Connection","keep-alive" },
{ "Content-Type","application/x-www-form-urlencoded; charset=UTF-8" },
{ "User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"}
} };
List<Request> resList = new List<Request>();
Request res = new Request();
res.Url = "https://mall.autohome.com.cn/detail/284641-0-0.html";
res.Method = System.Net.Http.HttpMethod.Get;
resList.Add(res);
var spider = Spider.Create(site, new QueueDuplicateRemovedScheduler(), new GetSkuProcessor(),new GetBasicInfoProcessor(),new GetExtInfoProcessor()) //因为我们有多个Processor,所以都要添加进来
.AddStartRequests(resList.ToArray())
.AddPipeline(new PrintSkuPipe());
spider.ThreadNum = ;
spider.Run();
Console.Read();
五、执行结果
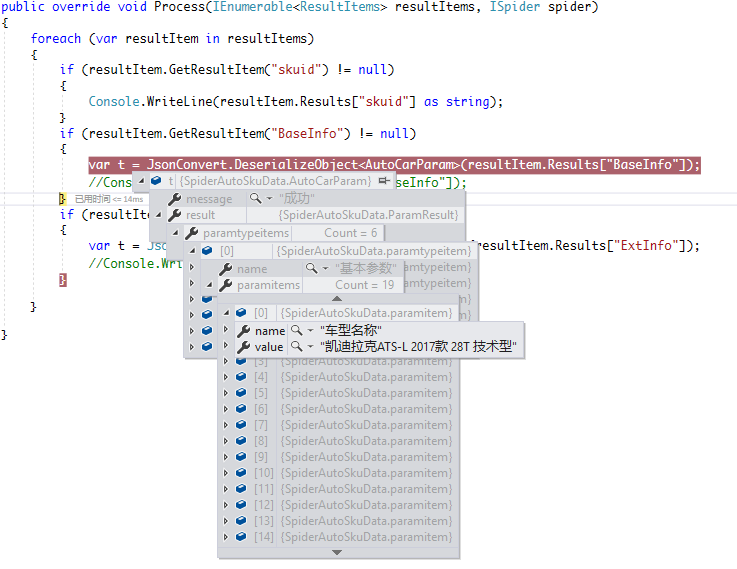
六、总结
这次憋了那么久才写第二篇文章的,实属惭愧,本来2月底这篇文章就要出来的,一直拖到现在,上一篇文章的阅读量整体来说还是不错的超出了我的预期,下面评论也有小伙伴希望我快点出这篇文章,整体来说还是不错的。这次的文章我希望就是说不仅仅是大家学会了如何去使用DotnetSpider,并且能够让大家了解一下如何爬数据,给大家提供一点点思路,所以我会结合实际场景来写这篇文章,不然的话,感觉会太过于枯燥了。
希望大家多多拍砖
七、下期预告
下次文章会涉及文件抓取
顺便说一句,有需要参加PMP或者高项考试的可以联系我,我有一些资料可以提供
2018年5月13日
汽车之家店铺商品详情数据抓取 DotnetSpider实战[二]的更多相关文章
- 汽车之家店铺数据抓取 DotnetSpider实战[一]
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- 汽车之家店铺数据抓取 DotnetSpider实战
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- 汽车之家汽车品牌Logo信息抓取 DotnetSpider实战[三]
一.正题前的唠叨 第一篇实战博客,阅读量1000+,第二篇,阅读量200+,两篇文章相差近5倍,这个差异真的令我很费劲,截止今天,我一直在思考为什么会有这么大的差距,是因为干货变少了,还是什么原因,一 ...
- Hawk 数据抓取工具 使用说明(二)
1. 调试模式和执行模式 1.1.调试模式 系统能够通过拖拽构造工作流.在编辑流的过程中,处于调试模式,为了保证快速地计算和显示当前结果(只显示前20个数据,可在调试的采样量中修改),此时,所有执行器 ...
- 用Vue来实现音乐播放器(二十一):歌手详情数据抓取
第一步:在api文件夹下的singer.js中抛出getSingerDetail方法 第二步:在singer-detail.vue组件中引入api文件夹下的singer.js和config.js 第三 ...
- Twitter数据抓取的方法(二)
Scraping Tweets Directly from Twitters Search Page – Part 2 Published January 11, 2015 In the previo ...
- Python爬虫:新浪新闻详情页的数据抓取(函数版)
上一篇文章<Python爬虫:抓取新浪新闻数据>详细解说了如何抓取新浪新闻详情页的相关数据,但代码的构建不利于后续扩展,每次抓取新的详情页时都需要重新写一遍,因此,我们需要将其整理成函数, ...
- Phantomjs+Nodejs+Mysql数据抓取(1.数据抓取)
概要: 这篇博文主要讲一下如何使用Phantomjs进行数据抓取,这里面抓的网站是太平洋电脑网估价的内容.主要是对电脑笔记本以及他们的属性进行抓取,然后在使用nodejs进行下载图片和插入数据库操作. ...
- 网页数据抓取工具,webscraper 最简单的数据抓取教程,人人都用得上
Web Scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据.例如知乎回答列表.微博热门.微博评论.淘宝.天猫.亚马逊等电商 ...
随机推荐
- my golib:db query Result
go提供了一套统一操作database的sql接口,任何第三方都可以通过实现相应的driver来访问感兴趣的数据库.譬如我们项目中使用的Go-MySQL-Driver. go提供了一套很好的机制来处理 ...
- Git的纯命令操作,Install,Clone , Commit,Push,Pull,版本回退,撤销更新,分支的创建/切换/更新/提交/合并,代码冲突
Git的纯命令操作,Install,Clone , Commit,Push,Pull,版本回退,撤销更新,分支的创建/切换/更新/提交/合并,代码冲突 这篇是接着上篇分布式版本库--Windows下G ...
- Linux下实现秒级定时任务的两种方案(crontab 每秒运行)
第一种方案,当然是写一个后台运行的脚本一直循环,然后每次循环sleep一段时间. while true ;do command sleep XX //间隔秒数 done 第二种方案,使用crontab ...
- zookeeper+kafka集群安装之一
zookeeper+kafka集群安装之一 准备3台虚拟机, 系统是RHEL64服务版. 1) 每台机器配置如下: $ cat /etc/hosts ... # zookeeper hostnames ...
- OpenCV 直线检测
/*------------------------------------------------------------------------------------------*\ This ...
- Stackoverflow上人气最旺的10个Java问题
1. 为什么两个(1927年)时间相减得到一个奇怪的结果? (3623个赞) 如果执行下面的程序,程序解析两个间隔1秒的日期字符串并比较: 01 public static void main(Str ...
- MySQL 5.6初始配置调优
原文链接: What to tune in MySQL 5.6 after installation原文日期: 2013年09月17日翻译日期: 2014年06月01日翻译人员: 铁锚 随着 大量默认 ...
- unix下的ACL
acl可以针对user,组,目录默认属性(mask)来控制. acl需要文件系统支持,ext2/3,jfs,xfs等都支持. getfacl setfacl 对于mac os X系统的acl 可以使用 ...
- leetcode之旅(9)-Reverse Linked List
题目描述: Reverse a singly linked list. click to show more hints. Hint: A linked list can be reversed ei ...
- Android开发学习总结(二)——使用Android Studio搭建Android集成开发环境
有很长一段时间没有更新博客了,最近实在是太忙了,没有时间去总结,现在终于可以有时间去总结一些Android上面的东西了,很久以前写过这篇关于使用Android Studio搭建Android集成开发环 ...