稀疏编码概率解释(基于1996年Olshausen与Field的理论 )
一、Sparse Coding稀疏编码
稀疏编码算法是一种无监督学习方法,它用来寻找一组“超完备”基向量来更高效地表示样本数据。稀疏编码算法的目的就是找到一组基向量 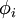 ,使得我们能将输入向量
,使得我们能将输入向量 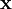 表示为这些基向量的线性组合:
表示为这些基向量的线性组合:
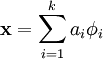
也就是

虽然形如主成分分析技术(PCA)能使我们方便地找到一组“完备”基向量,但是这里我们想要做的是找到一组 “超完备” 基向量来表示输入向量 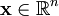 (也就是说,k > n)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数 ai 不再由输入向量 唯一确定。因此,在稀疏编码算法中,我们另加了一个评判标准“稀疏性”来解决因超完备而导致的退化(degeneracy)问题。
(也就是说,k > n)。超完备基的好处是它们能更有效地找出隐含在输入数据内部的结构与模式。然而,对于超完备基来说,系数 ai 不再由输入向量 唯一确定。因此,在稀疏编码算法中,我们另加了一个评判标准“稀疏性”来解决因超完备而导致的退化(degeneracy)问题。
这里,我们把“稀疏性”定义为:只有很少的几个非零元素或只有很少的几个远大于零的元素。要求系数 ai 是稀疏的意思就是说:对于一组输入向量,我们只想有尽可能少的几个系数远大于零。选择使用具有稀疏性的分量来表示我们的输入数据是有原因的,因为绝大多数的感官数据,比如自然图像,可以被表示成少量基本元素的叠加,在图像中这些基本元素可以是面或者线。同时,比如与初级视觉皮层的类比过程也因此得到了提升。
我们把有 m 个输入向量的稀疏编码代价函数定义为:
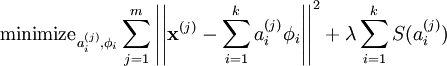
此处 S(.) 是一个稀疏代价函数,由它来对远大于零的 ai 进行“惩罚”。我们可以把稀疏编码目标函式的第一项解释为一个重构项,这一项迫使稀疏编码算法能为输入向量 提供一个高拟合度的线性表达式,而公式第二项即“稀疏惩罚”项,它使 的表达式变得“稀疏”。常量 λ 是一个变换量,由它来控制这两项式子的相对重要性。
虽然“稀疏性”的最直接测度标准是 "L0" 范式,但这是不可微的,而且通常很难进行优化。在实际中,稀疏代价函数 S(.) 的普遍选择是L1 范式代价函数(具体为什么用详见我之前的博文稀疏编码学习笔记)
此外,很有可能因为减小 ai 或增加 至很大的常量,使得稀疏惩罚变得非常小。为防止此类事件发生,我们将限制 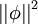 要小于某常量 C 。包含了限制条件的稀疏编码代价函数的完整形式如下:
要小于某常量 C 。包含了限制条件的稀疏编码代价函数的完整形式如下:
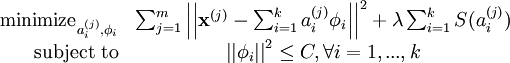
二、Olshausen与Field的理论例子
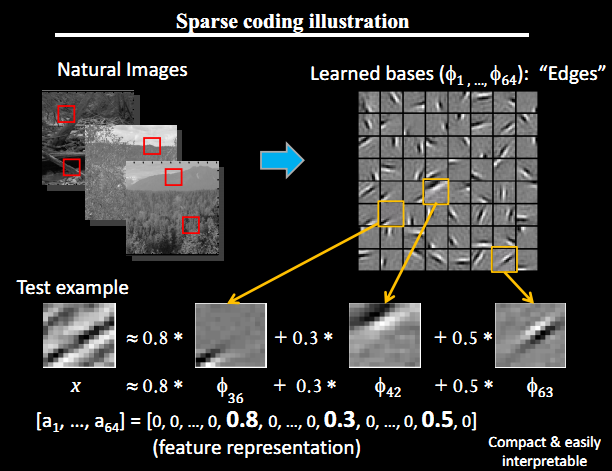
比如在图像的Feature Extraction的最底层要做Edge Detector的生成,那么这里的工作就是从Natural Images中randomly选取一些小patch,通过这些patch生成能够描述他们的”基“,也就是右边的8*8=64个basis组成的basis(具体选取基的方法可以参考http://blog.csdn.net/abcjennifer/article/details/7721834),然后给定一个test patch, 我们可以按照上面的式子通过basis的线性组合得到,而sparse matrix就是a,下图中的a中有64个维度,其中非零项只有3个,故称”sparse“。
这里可能大家会有疑问,为什么把底层作为Edge Detector呢?上层又是什么呢?这里做个简单解释大家就会明白,之所以是Edge Detector是因为不同方向的Edge就能够描述出整幅图像,所以不同方向的Edge自然就是图像的basis了……
而上一层的basis组合的结果,上上层又是上一层的组合basis……(具体请往下看)
如下图所示:
其他的例子同理:注意看下面的文字(第二条)

那究竟自然图像的基是如何选取呢?稀疏编码的代价函数又从何而来,基本的理论上是这么分析的
为了寻找到一个稀疏的、超完备基向量集,来覆盖我们的输入数据空间。现在换一种方式,我们可以从概率的角度出发,将稀疏编码算法当作一种“生成模型”。
我们将自然图像建模问题看成是一种线性叠加,叠加元素包括 k 个独立的源特征 以及加性噪声 ν :
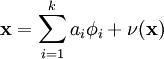
我们的目标是找到一组特征基向量 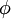 ,它使得图像的分布函数
,它使得图像的分布函数 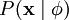 尽可能地近似于输入数据的经验分布函数
尽可能地近似于输入数据的经验分布函数 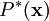 。一种实现方式是,最小化 与 之间的 KL 散度,此 KL 散度表示如下:
。一种实现方式是,最小化 与 之间的 KL 散度,此 KL 散度表示如下:
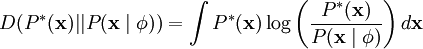
因为无论我们如何选择 ,经验分布函数 都是常量,也就是说我们只需要最大化对数似然函数 。 假设 ν 是具有方差 σ2 的高斯白噪音,则有下式:
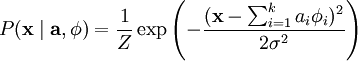
为了确定分布 ,我们需要指定先验分布 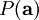 。假定我们的特征变量是独立的,我们就可以将先验概率分解为:
。假定我们的特征变量是独立的,我们就可以将先验概率分解为:
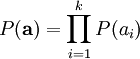
此时,我们将“稀疏”假设加入进来——假设任何一幅图像都是由相对较少的一些源特征组合起来的。因此,我们希望 ai 的概率分布在零值附近是凸起的,而且峰值很高。一个方便的参数化先验分布就是:
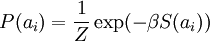
这里 S(ai) 是决定先验分布的形状的函数。
当定义了 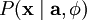 和 后,我们就可以写出在由 定义的模型之下的数据 的概率分布:
和 后,我们就可以写出在由 定义的模型之下的数据 的概率分布:
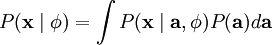
那么,我们的问题就简化为寻找:
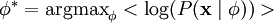
这里 < . > 表示的是输入数据的期望值。
不幸的是,通过对 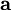 的积分计算 通常是难以实现的。虽然如此,我们注意到如果 的分布(对于相应的 )足够陡峭的话,我们就可以用 的最大值来估算以上积分。估算方法如下:
的积分计算 通常是难以实现的。虽然如此,我们注意到如果 的分布(对于相应的 )足够陡峭的话,我们就可以用 的最大值来估算以上积分。估算方法如下:
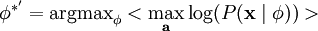
跟之前一样,我们可以通过减小 ai 或增大 来增加概率的估算值(因为 P(ai) 在零值附近陡升)。因此我们要对特征向量 加一个限制以防止这种情况发生。
最后,我们可以定义一种线性生成模型的能量函数,从而将原先的代价函数重新表述为:
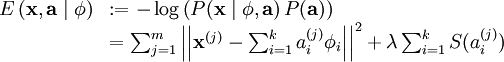
其中 λ = 2σ2β ,并且关系不大的常量已被隐藏起来。因为最大化对数似然函数等同于最小化能量函数,我们就可以将原先的优化问题重新表述为:
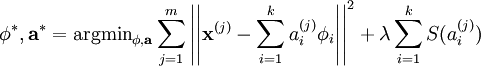
使用概率理论来分析,我们可以发现,选择 L1 惩罚和 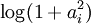 惩罚作为函数 S(.) ,分别对应于使用了拉普拉斯概率
惩罚作为函数 S(.) ,分别对应于使用了拉普拉斯概率 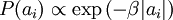 和柯西先验概率
和柯西先验概率 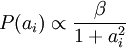 。
。
至此,对于概率的解释完毕
三、学习算法
使用稀疏编码算法学习基向量集的方法,是由两个独立的优化过程组合起来的。第一个是逐个使用训练样本 来优化系数 ai ,第二个是一次性处理多个样本对基向量 进行优化。
如果使用 L1 范式作为稀疏惩罚函数,对 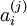 的学习过程就简化为求解 由 L1 范式正则化的最小二乘法问题,这个问题函数在域 内为凸,已经有很多技术方法来解决这个问题(诸如CVX之类的凸优化软件可以用来解决L1正则化的最小二乘法问题)。如果 S(.) 是可微的,比如是对数惩罚函数,则可以采用基于梯度算法的方法,如共轭梯度法。
的学习过程就简化为求解 由 L1 范式正则化的最小二乘法问题,这个问题函数在域 内为凸,已经有很多技术方法来解决这个问题(诸如CVX之类的凸优化软件可以用来解决L1正则化的最小二乘法问题)。如果 S(.) 是可微的,比如是对数惩罚函数,则可以采用基于梯度算法的方法,如共轭梯度法。
用 L2 范式约束来学习基向量,同样可以简化为一个带有二次约束的最小二乘问题,其问题函数在域 内也为凸。标准的凸优化软件(如CVX)或其它迭代方法就可以用来求解 ,虽然已经有了更有效的方法,比如求解拉格朗日对偶函数(Lagrange dual)。
·······未完待续
参考资料 http://deeplearning.stanford.edu/wiki/index.php/%E7%A8%80%E7%96%8F%E7%BC%96%E7%A0%81
http://blog.csdn.net/abcjennifer/article/details/7804962
稀疏编码概率解释(基于1996年Olshausen与Field的理论 )的更多相关文章
- Sparsity稀疏编码(一)
稀疏编码来源于神经科学,计算机科学和机器学习领域一般一开始就从稀疏编码算法讲起,上来就是找基向量(超完备基),但是我觉得其源头也比较有意思,知道根基的情况下,拓展其应用也比较有底气.哲学.神经科学.计 ...
- 稀疏编码(Sparse Coding)的前世今生(一) 转自http://blog.csdn.net/marvin521/article/details/8980853
稀疏编码来源于神经科学,计算机科学和机器学习领域一般一开始就从稀疏编码算法讲起,上来就是找基向量(超完备基),但是我觉得其源头也比较有意思,知道根基的情况下,拓展其应用也比较有底气.哲学.神经科学.计 ...
- 转载 deep learning:八(SparseCoding稀疏编码)
转载 http://blog.sina.com.cn/s/blog_4a1853330102v0mr.html Sparse coding: 本节将简单介绍下sparse coding(稀疏编码),因 ...
- Sparsity稀疏编码(二)
为了更进一步的清晰理解大脑皮层对信号编码的工作机制(策略),需要把他们转成数学语言,因为数学语言作为一种严谨的语言,可以利用它推导出期望和要寻找的程式.本节就使用概率推理(bayes v ...
- 稀疏编码直方图----一种超越HOG的轮廓特征
该论文是一篇来自CMU 的CVPR2013文章,提出了一种基于稀疏编码的轮廓特征,简称HSC(Histogram of Sparse Code),并在目标检测中全面超越了HOG(Histogram o ...
- 稀疏编码(Sparse Coding)的前世今生(二)
为了更进一步的清晰理解大脑皮层对信号编码的工作机制(策略),须要把他们转成数学语言,由于数学语言作为一种严谨的语言,能够利用它推导出期望和要寻找的程式.本节就使用概率推理(bayes views)的方 ...
- Sparsity稀疏编码(三)
稀疏编码(sparse coding)和低秩矩阵(low rank)的区别 上两个小结介绍了稀疏编码的生命科学解释,也给出一些稀疏编码模型的原型(比如LASSO),稀疏编码之前的探讨文章 ...
- UFLDL深度学习笔记 (七)拓扑稀疏编码与矩阵化
UFLDL深度学习笔记 (七)拓扑稀疏编码与矩阵化 主要思路 前面几篇所讲的都是围绕神经网络展开的,一个标志就是激活函数非线性:在前人的研究中,也存在线性激活函数的稀疏编码,该方法试图直接学习数据的特 ...
- 基于字典SR各种方法【稀疏编码多种方法】
基于字典的图像超分辨率实现 - CSDN博客 http://blog.csdn.net/u011630458/article/details/65635155 简介 这段时间在看基于字典的单帧图像超分 ...
随机推荐
- 操作Excel的宏
有时候在Excel中,需要循环的算每一列的值,而这一列的值是某几列的求和或者某种运算后的结果,比如如下的C4=C3+B4 可以用一个宏来实现,宏代码如下: Dim i As In ...
- 云计算之路-阿里云上:Web服务器请求到达量突降
今天下午遇到了自使用阿里云以来首次遇到的新情况——http.sys的ArrivalRate突降(说明请求到达IIS的请求数量少了),而且SLB中的3台ECS都出现了这个问题. 1. 10.161.24 ...
- 【连载】Maven系列(四)——配置私服
相关文章 1.<用起来超爽的Maven——入门篇> 2.<用起来超爽的Maven——进阶篇> 3.<Maven系列(三) 进阶> 一.为什么需要私服 有些公司并不提 ...
- EntityFramewrok 使用
1.使用一些查询比较复杂或者需要拼接的查询的时候最好一直保持IQueryable.一直到最后取数据的时候才进行查询.例如分页之类的条件拼接. var query = dbset.Where(expre ...
- BZOJ 1968 [Ahoi2005]COMMON 约数研究:数学【思维题】
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=1968 题意: 设f(x) = x约数的个数.如:12的约数有1,2,3,4,6,12,所以 ...
- jmeter+ant的使用
1.安装ant 下载ant,解压到某盘 2.配置环境变量: 变量名称 变量值 备注 ANT_HOME F:\apache-ant-1.10.3 Ant的解压路径 Path %ANT_HOME%\bin ...
- 《百词斩·象形9000》第一册(上) 符号Symbol 1
001-upon prep. 在......上面 Wish upon a star.#对着星星许愿. 002-think V. 想,思索,认为:以为,预料 What do you think?#你认为 ...
- 1098 Insertion or Heap Sort (25 分)(堆)
这里的第二序列相当于是排序还没拍好的序列 对于第二个样例的第二个序列其实已经是大顶堆了 然后才进行的堆排序 知道这个就好做了 #include<bits/stdc++.h> using n ...
- MVC项目用Windsor注入
第一步创建controler 注入类 public class ApiControllersInstaller : IWindsorInstaller { public void Install(I ...
- [leetcode-640-Solve the Equation]
Solve a given equation and return the value of x in the form of string "x=#value". The equ ...