python 案例:使用BeautifuSoup4的爬虫
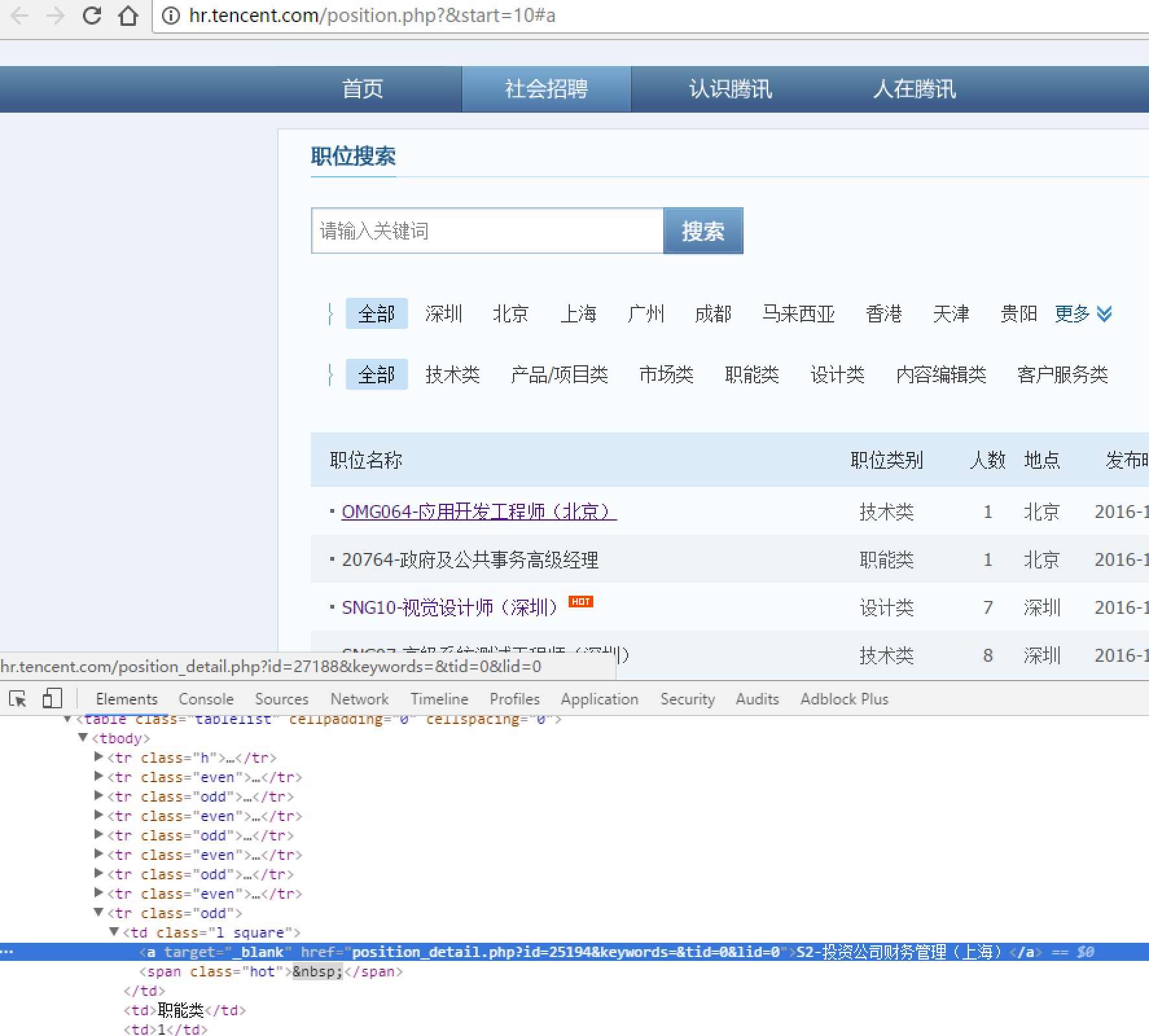
我们以腾讯社招页面来做演示:http://hr.tencent.com/position.php?&start=10#a
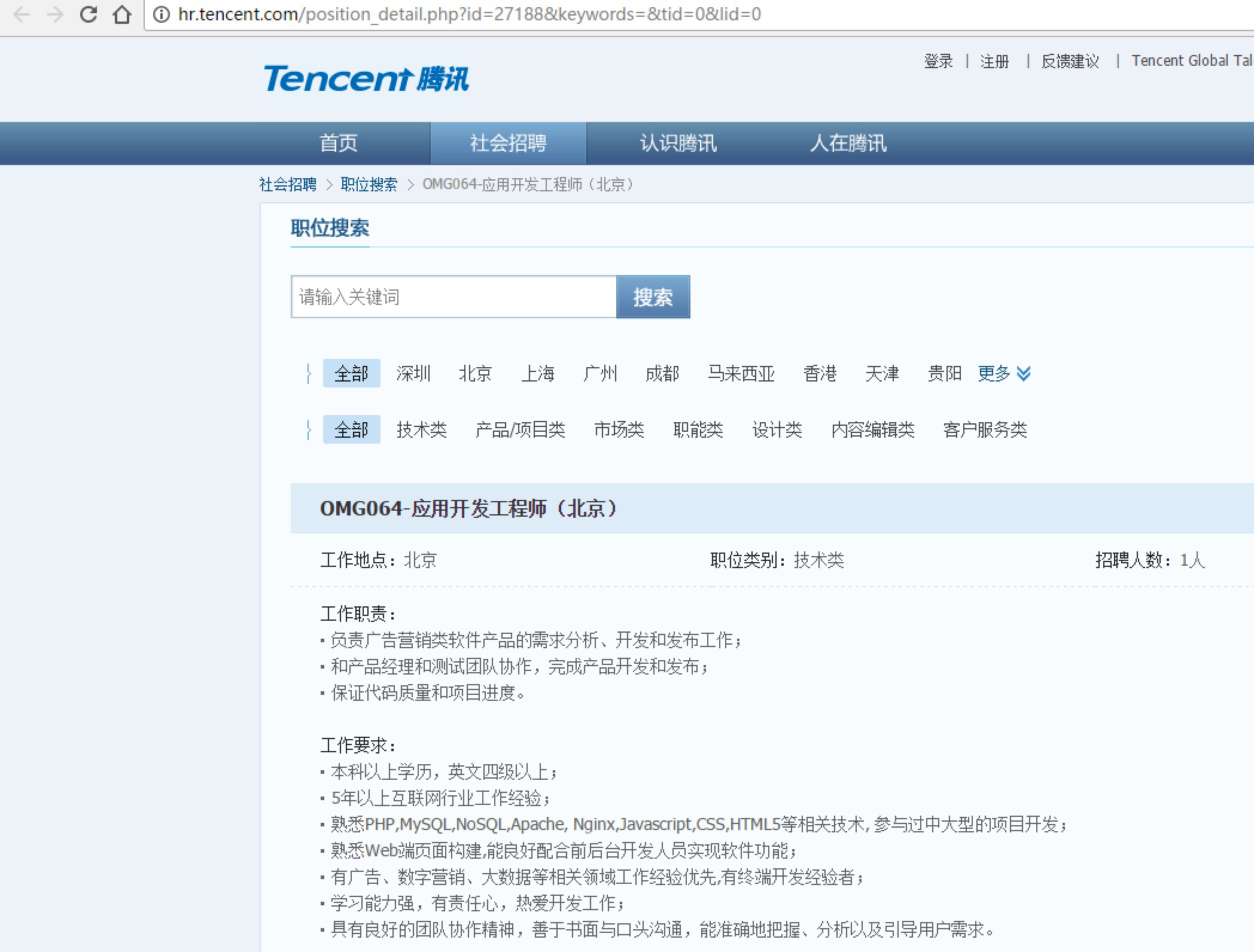
使用BeautifuSoup4解析器,将招聘网页上的职位名称、职位类别、招聘人数、工作地点、发布时间,以及每个职位详情的点击链接存储出来。
# bs4_tencent.py
from bs4 import BeautifulSoup
import urllib2
import urllib
import json # 使用了json格式存储
def tencent():
url = 'http://hr.tencent.com/'
request = urllib2.Request(url + 'position.php?&start=10#a')
response =urllib2.urlopen(request)
resHtml = response.read()
output =open('tencent.json','w')
html = BeautifulSoup(resHtml,'lxml')
# 创建CSS选择器
result = html.select('tr[class="even"]')
result2 = html.select('tr[class="odd"]')
result += result2
items = []
for site in result:
item = {}
name = site.select('td a')[0].get_text()
detailLink = site.select('td a')[0].attrs['href']
catalog = site.select('td')[1].get_text()
recruitNumber = site.select('td')[2].get_text()
workLocation = site.select('td')[3].get_text()
publishTime = site.select('td')[4].get_text()
item['name'] = name
item['detailLink'] = url + detailLink
item['catalog'] = catalog
item['recruitNumber'] = recruitNumber
item['publishTime'] = publishTime
items.append(item)
# 禁用ascii编码,按utf-8编码
line = json.dumps(items,ensure_ascii=False)
output.write(line.encode('utf-8'))
output.close()
if __name__ == "__main__":
tencent()python 案例:使用BeautifuSoup4的爬虫的更多相关文章
- 2.6. 案例:使用BeautifuSoup4的爬虫
案例:使用BeautifuSoup4的爬虫 我们以腾讯社招页面来做演示:http://hr.tencent.com/position.php?&start=10#a 使用BeautifuSou ...
- python Cmd实例之网络爬虫应用
python Cmd实例之网络爬虫应用 标签(空格分隔): python Cmd 爬虫 废话少说,直接上代码 # encoding=utf-8 import os import multiproces ...
- 获取字段唯一值工具- -ArcPy和Python案例学习笔记
获取字段唯一值工具- -ArcPy和Python案例学习笔记 目的:获取某一字段的唯一值,可以作为工具使用,也可以作为函数调用 联系方式:谢老师,135-4855-4328,xiexiaokui# ...
- 使用python做最简单的爬虫
使用python做最简单的爬虫 --之心 #第一种方法import urllib2 #将urllib2库引用进来response=urllib2.urlopen("http://www.ba ...
- 14.python案例:爬取电影天堂中所有电视剧信息
1.python案例:爬取电影天堂中所有电视剧信息 #!/usr/bin/env python3 # -*- coding: UTF-8 -*- '''======================== ...
- 第7.27节 Python案例详解: @property装饰器定义属性访问方法getter、setter、deleter
上节详细介绍了利用@property装饰器定义属性的语法,本节通过具体案例来进一步说明. 一. 案例说明 本节的案例是定义Rectangle(长方形)类,为了说明问题,除构造函数外,其他方法都只 ...
- 第7.25节 Python案例详解:使用property函数定义与实例变量同名的属性会怎样?
第7.25节 Python案例详解:使用property函数定义与实例变量同名的属性会怎样? 一. 案例说明 我们上节提到了,使用property函数定义的属性不要与类内已经定义的普通实例变量重 ...
- 第7.24节 Python案例详解:使用property函数定义属性简化属性访问代码实现
第7.24节 Python案例详解:使用property函数定义属性简化属性访问代码实现 一. 案例说明 本节将通过一个案例介绍怎么使用property定义快捷的属性访问.案例中使用Rectan ...
- 案例:使用BeautifuSoup4的爬虫
使用BeautifuSoup4解析器,将招聘网页上的招聘单位名称存储出来.其他信息可类似爬取即可 # -*- coding:utf-8 -*- from bs4 import BeautifulSou ...
随机推荐
- ORACLE查看并修改最大连接数的具体步骤
第一步,在cmd命令行,输入sqlplus 第二步,根据提示输入用户名与密码 1. 查看processes和sessions参数 SQL> show parameter processes ...
- 刷新神经网络新深度:ImageNet计算机视觉挑战赛微软中国研究员夺冠
微软亚洲研究院首席研究员孙剑 世界上最好计算机视觉系统有多精确?就在美国东部时间12月10日上午9时,ImageNet计算机视觉识别挑战赛结果揭晓——微软亚洲研究院视觉计算组的研究员们凭借深层神经网络 ...
- 如何看待Linux操作系统的用户空间和内核空间
作为中央核心处理单元的CPU,除了生产工艺的不断革新进步外,在处理数据和响应速度方面也需要有权衡.稍有微机原理基础的人都知道Intel X86体系的CPU提供了四种特权模式ring0~ring3,其中 ...
- C#写的一个视频转换解码器
C#写的一个视频转换解码器 using System; using System.Collections.Generic; using System.Linq; using System.Text; ...
- socket编程演示样例(多线程)
client代码例如以下: import java.io.*; import java.net.*; import java.util.Scanner; public class SimpleChat ...
- rap 实现分页效果
1.官网 http://rapapi.org/org/index.do 2.账号(1) react_native_developer 3.结构 4.查看接口 5.访问接口 6.数据格式
- vue 项目中 自定义 webpack 的 配置文件(webpack.config.babel.js)
webpack.config.babel.js,这样命名是想让webpack在编译的时候自动识别es6的语法,现在貌似不需要这样命名了,之前用webpack1.x的时候貌似是需要的 let path ...
- CentOS 7上安装Zabbix(高速安装监控工具Zabbix)
前提要求(optional) 安装Zabbix监控工具前,先安装必要的执行工具包 yum install gcc gcc-c++ make openssl-devel curl wget net-sn ...
- C语言 | 计算器实现 version 2.
在之前版本中使用栈结构来实现,但由于51单片机不支持malloc函数,所以使用C语言又写了一个计算器版本. 通过数组存放值和操作符模拟栈操作. 实现代码: #include <stdio.h&g ...
- javascript 捕获异常方法
捕获异常的实例: var str="fasdfsadfsad$$异常信息$$你看不到我"; var arr=str.split("$$"); arr[1]; 通 ...