Coursera 机器学习 第6章(下) Machine Learning System Design 学习笔记
Machine Learning System Design
下面会讨论机器学习系统的设计。分析在设计复杂机器学习系统时将会遇到的主要问题,给出如何巧妙构造一个复杂的机器学习系统的建议。
6.4 Building a Spam Classifier
6.4.1 Prioritizing What to Work On
首先是在设计机器学习系统时需要着重考虑什么问题。
以垃圾邮件分类为例。
1.确定用监督学习的方法进行学习和预测。
2.确定关于邮件的特征。关于挑选特征,实际工作中,是遍历整个训练集,选出出现次数最多的n歌单词,将这些单词作为特征。

3.构造分类器。用什么方法来改进分类器,从而使得垃圾邮件分类器具有较高的准确度。
1)收集大量的数据。盲目地收集数据是不可取的。
2)从邮件标题出发,构建基于邮件路径的更复杂的特征向量。
3)从邮件正文出发,构建基于邮件正文的更复杂的特征向量。
4)利用更复杂的算法检测错误拼写。

后面将会讲误差分析和怎样用一个比较系统的方法从一堆方法中选取合适的那一个方法。
做题:
答案:

6.4.2 Error Analysis
误差分析地概念。
误差分析:怎样用一个更加系统的方法从一堆不同的可能会提高算法表现的方法中选取合适的的方法。
面对一个机器学习的实际问题,推荐的解决步骤:

1.快速实现一个简单的机器学习算法,执行并测试交叉验证数据。先实现一个快速但不完美的算法的目的是为了找出什么类型的数据,这种算法最难分类正确。
2.画出学习曲线分析决定是否需要更多的数据、特征等。判断假设是否处于高偏差或者高方差的情况。
3.误差分析。通过误差分析看当前算法存在的缺陷,来决定优化的方法。注意要用交叉验证集来实施误差分析,不要用测试集。这个过程可以启发构造新的特征变量,或者当前系统存在的短处。
误差分析的方法:
1)手动检查分类错误的样本被分类错误的原因。比如在垃圾邮件分类中,明确有哪些类型的邮件被分类错误;根据错误的分类结果看哪种类型的邮件最容易被错误分类,然后改进算法,使这样类型的邮件不再轻易被分类错误。

2)保证能有一种数值计算的方式来评估当前机器学习算法。用数值计算的方法可以使评估结果有数值的直观体现,从而更加直观告诉实验者当前的学习算法改变是否确实提高了学习算法的表现。例如在垃圾邮件分类中,关于是否使用词干提取法,分别得到交叉验证误差。

一个快速但不完美的算法加上一个数值的评估方法方便尝试新的想法,快速发现这些改进是否真的有利于算法表现的提高。
做题:
答案:

6.5 Handling Skewed Data
6.5.1 Error Metrics for Skewed Classes
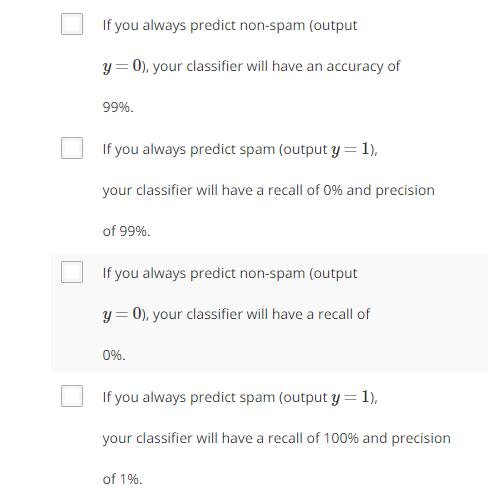
偏斜类问题:总体样本分布中,一个类的样本量远远大于另一个类的样本量。这使得改动算法后,如果误差率下降并不意味着改进是有效的。存在偏斜类问题时,用分类精确度并不能很好地衡量算法。
比如在诊断癌症的例子中,如果只依赖于改进算法后的数值评估方法:尽管我们的假设的误差率是1%,但实际上总的样本分布中,只有0.5%的样本是患有癌症,于是如果将假设改为“无视输入特征,一直输出无癌症的结果”的话,误差率是0.5%,这显然是不合理的。这里患有癌症的样本输出h=1。
于是需要其他的评估度量值。比如查准率和召回率。
假设h,实际值y。如果样本满足以下情况,称样本为:
h=1,y=1,真阳性;h=0,y=0,真阴性;h=1,y=0,假阳性;h=0,y=1,假阴性。一般,在分类问题中,假设不经常出现的类y=1。
查准率:真阳性样本数量/预测y=1的样本数量=真阳性样本数量/(真阳性的样本数量+假阳性的样本数量)。即“你的预测有多少是对的”。
召回率:真阳性样本数量/确实y=1的样本数量=真阳性样本数量/(真阳性的样本数量+假阴性的样本数量)。即“正例里你的预测覆盖了多少”。
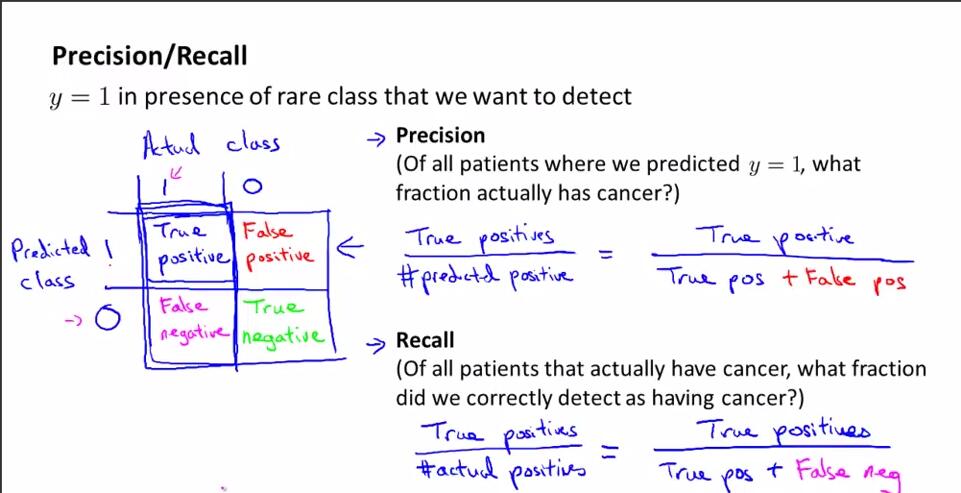
如果一个算法具有高召回率和高查准率,那么这个算法就是好的。查准率和召回率作为遇到偏斜率问题的评估度量值。
6.5.2 Trading Off Precision and Recall
实现查准率和召回率的平衡。
通过改变阈值来实现查准率和召回率的取舍。比如在预测癌症的例子中:
1.如果我们谨慎一些,只有当十分有把握的时候再告知病人患了癌症,那么预测函数的阈值>0.5,比如0.7、0.9。这时假设具有高查准率和低召回率。
2.如果我们不想漏过一个患者,宁可错杀,也不愿意放过,那么预测函数的阈值<0.5,比如0.3。这时假设具有低查准率和高召回率。
如图中坐标所示,查准率和召回率有个平衡关系。
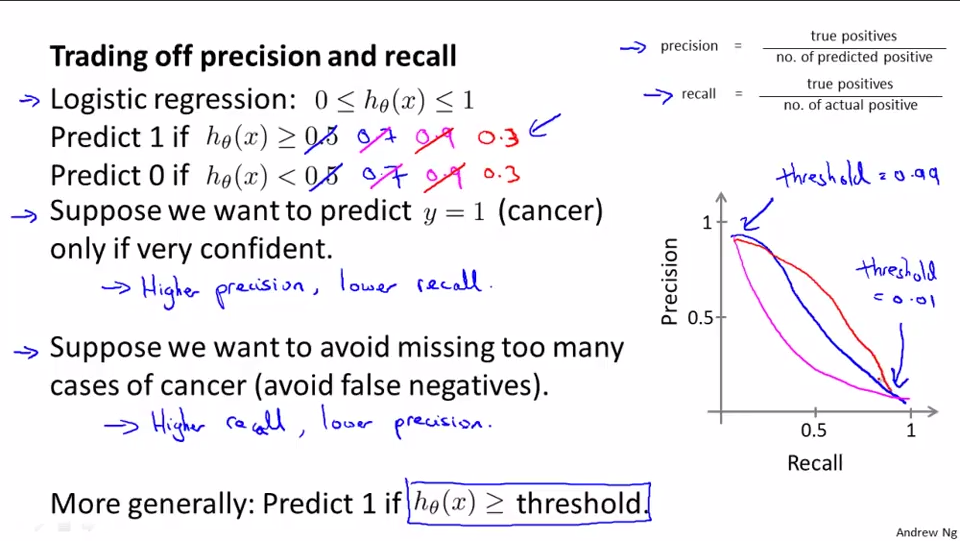
自动选择临界值。有不同的实现算法的时候,如何比较不同算法之间的查准率和召回率。
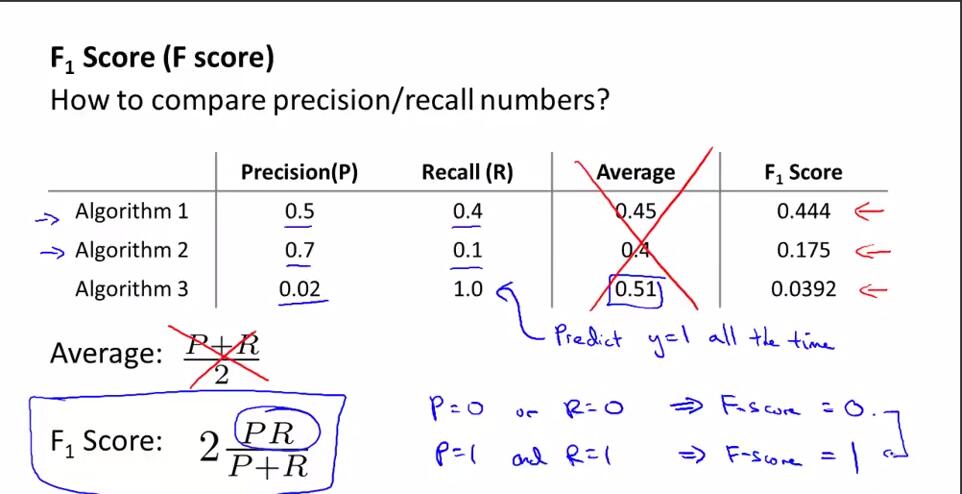
不能用平均值的原因:在癌症预测的例子中,Algothrim3其实就是不管输入是什么,一律输出y=1的模型,可以看到尽管Algothrim3的PR平均值最高,但是Algothrim3明显不是一个好假设。
F值,2PR/(P+R),用来权衡查准率和召回率的评估度量值。会考虑一部分查准率和召回率的平均值,会给查准率和召回率中较小值更高的权重。
做道题:
答案:训练集用来训练出特定模型对应的参数;交叉验证集用来调整模型;测试集是模型从来没有见过的数据,只能用来衡量模型性能。
这也是自动选择临界值的方法:改变到不同的临界值,在交叉验证集上验证,取F值最高对应的临界值。

6.6 Using Large Data Sets
6.6.1 Data For Machine Learning
前面一些内容讨论了评价指标。这里来讨论数据的作用。
数据有时确实可以起到一定的作用,事实证明,在一定条件下,得到大量数据并在某种学习算法中进行训练可以是获得一个具有良好性能的学习算法的一种有效的方法。
比如下面的例子:
由图可以得出:
1.随着训练集大小的变化,算法们都具有相同的趋势。
2.随着训练集的大小的增加,算法们的准确率也对应地得到增强。
那么什么情况下,数据真的对于一个算法而言至关重要?看下图:

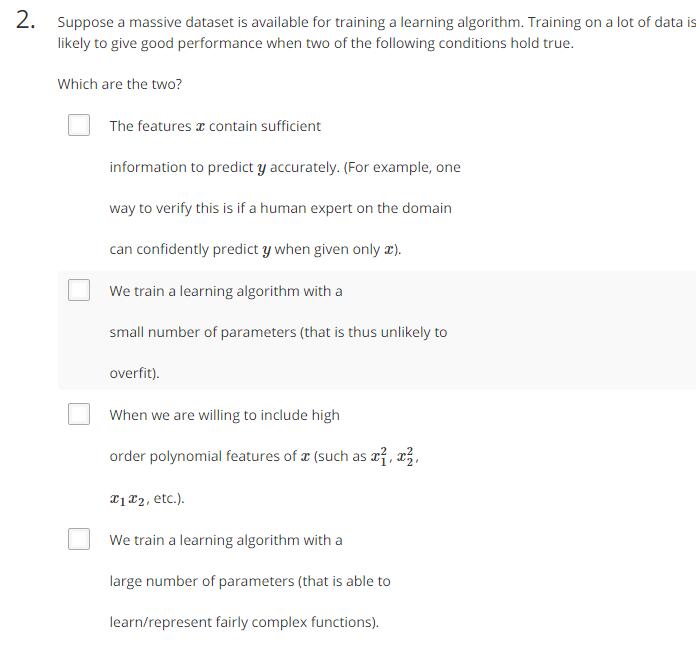
1.特征值有足够的信息量。
2.较好的函数,函数具有较多参数,能较好地拟合训练集。
3.大量数据。数据量非常大的时候,不易过拟合。
1和2保证算法低偏差性,使算法很好地拟合数据,也保证了算法的低训练误差。3保证算法的低方差,使得测试误差接近训练误差。在1和2都满足的前提下,3才能发挥作用。
在满足1、2、3的条件下,则算法的测试误差也会较小,算法的性能表现会比较好。
做道题:

答案:

习题: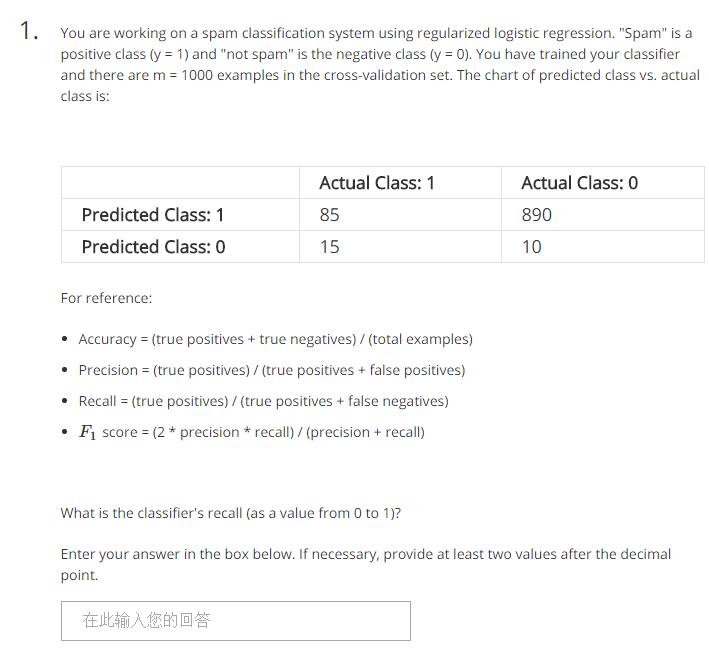
0.85
AD

A

ACD


BC
Coursera 机器学习 第6章(下) Machine Learning System Design 学习笔记的更多相关文章
- Coursera 机器学习 第9章(上) Anomaly Detection 学习笔记
9 Anomaly Detection9.1 Density Estimation9.1.1 Problem Motivation异常检测(Density Estimation)是机器学习常见的应用, ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 11—Machine Learning System Design 机器学习系统设计
Lecture 11—Machine Learning System Design 11.1 垃圾邮件分类 本章中用一个实际例子: 垃圾邮件Spam的分类 来描述机器学习系统设计方法.首先来看两封邮件 ...
- Stanford机器学习笔记-7. Machine Learning System Design
7 Machine Learning System Design Content 7 Machine Learning System Design 7.1 Prioritizing What to W ...
- Machine Learning - XI. Machine Learning System Design机器学习系统的设计(Week 6)
http://blog.csdn.net/pipisorry/article/details/44119187 机器学习Machine Learning - Andrew NG courses学习笔记 ...
- Machine Learning - 第6周(Advice for Applying Machine Learning、Machine Learning System Design)
In Week 6, you will be learning about systematically improving your learning algorithm. The videos f ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning Deciding what to try next 现在我们已学习了线性回归.逻辑回归.神经网络等机器学习算法,接下来 ...
- Coursera 机器学习 第5章 Neural Networks: Learning 学习笔记
5.1节 Cost Function神经网络的代价函数. 上图回顾神经网络中的一些概念: L 神经网络的总层数. sl 第l层的单元数量(不包括偏差单元). 2类分类问题:二元分类和多元分类. 上 ...
- 斯坦福第十一课:机器学习系统的设计(Machine Learning System Design)
11.1 首先要做什么 11.2 误差分析 11.3 类偏斜的误差度量 11.4 查全率和查准率之间的权衡 11.5 机器学习的数据 11.1 首先要做什么 在接下来的视频中,我将谈到机器 ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
随机推荐
- DateType--字符类型
--=====================================================字符集 ASCII (American Standard Code for Informa ...
- c# 如何筛选datatable
对DataTable数据各种筛选 筛选一个DataTable的数据,赋值给另外一个DataTable 假设: 有2个DataTable:DataTable A.DataTable B. 要求: 筛选D ...
- Asp.net负载均衡之Session
在WEB场中,动态网页往往会因为几台主机做了负载而产生SESSION丢失的问题,网上也有很多的介绍,我这里只将我经历的过程给大家分享一下: 系统要运行在负载平衡的 Web 场环境中,而系统配置文件we ...
- 题解 P1434 【滑雪】
题目链接 此题运用功能强大的 ~~暴力搜索~~ 记忆化搜索才是重点!!! 然而,这是一道经典的DP问题 如果我们用$dis[i][j]$来表示坐标为$(i,j)$时的高度 $cnt[i][j]$ 是我 ...
- 运行Scrapy工程,报错ModuleNotFoundError: No module named 'win32api'解决方法
1.运行爬虫scrapy crawl name,报错ScrpyModuleNotFoundError: No module named 'win32api' 2.解决方法: 在https://gith ...
- SpringMVC的简单介绍及使用
一.简介 1.SpringMVC和Spring的关系: >软件开发的三层架构: web层[表示层.表现层]---->Service层---->Dao[DataBase Access ...
- Application received signal SIGABRT
Application received signal SIGABRT (null) (( 0 CoreFoundation 0x0000000182bbadc8 <redacted> + ...
- PHP7 关于变量的基本判断
刚学 PHP ,一些基础还不太牢固,边实践边记录. about NULL $class_name = null; 语句结束后,$class_name 是空,没有,什么都没有的“空”.用 is_null ...
- HDU_6298 Maximum Multiple 【找规律】
一.题目 Given an integer $n$, Chiaki would like to find three positive integers $x$, $y$ and $z$ such t ...
- 石头剪刀布(2019Wannafly winter camp day3 i) 带权并查集+按秩合并 好题
题目传送门 思路: 按照题意描述,所有y挑战x的关系最后会形成一棵树的结构,n个人的总方案数是 3n 种,假设一个人被挑战(主场作战)a次,挑战别人(客场)b次,那么这个人存活到最后的方案数就是3n* ...