OverFeat学习
【OverFeat Integrated Recognition,Localization and Detection using Convolutional Networks】
Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus and Yann LeCun, 2014
http://arxiv.org/abs/1312.6229
Abstract
利用卷积网络为分类、定位、检测提供了一个统一的框架。论文展示了在ConvNet中高效地实现多尺度(multiscale)滑动窗口方法,介绍了一种新的深度学习方法,通过学习预测对象边界来进行定位。Bounding box最后被累积计算而非抑制,以提高检测的置信度。论文指出不同的任务可以用相同的网络来同时学习。该框架为ILSVRC2013定位任务的winner,而且在检测与分类任务也取得不错的成绩。
Introduction
分类任务:ConvNets解决该任务的优势是整个系统是端到端,直接从raw pixel得到最后的结果。因此大大减少了设计一个合理的特征提取器的人工工作。缺点是需要大量labeled的数据。
论文的关键点是训练一个卷积网络以同时完成分类、定位、检测,可以提高这几个任务的精度。论文提出通过累积计算预测得到的bounding box来完成定位与检测任务。因为把局部的预测结果结合起来,检测任务就不需要在背景样本上训练。这可以减少时间开销,以及复杂的前置训练流程。(检测任务要找到图中的所有物体,相应地也要知道什么是背景)。不用在背景数据集上训练也使得网络更关注正确的分类任务。
虽然ImageNet的分类数据集大多数是包含一个近乎位于中心且几乎充满整个图的对象,但有时我们感兴趣的对象在图中的位置和大小很不同。解决这个问题又几种思路:1.在图中不同的位置用不同的窗口大小做ConvNet训练;2.如果一个窗口包含了物体很明显可辨识的部位,而非整个对象,则会导致分类做得好,但定位和检测效果不好(比如,你只要看到一只狗的头就可以知道它是狗)。所以,对于每个窗口只产生各个类出现的比例分布,而不进行bounding box的位置和大小的预测;3. 对每个分类在每个位置和大小做置信度的叠加。
本文基于AlexNet,第一次提出如何利用ConvNets来完成图像的定位与检测。
Vision Tasks(ILSVRC2013)
分类classification:一个图片有一个label对应于图中主要的对象(可以有5个猜测,因为图中可能包含没有标签的对象)
定位 localization:同样可以有5个类别猜测,另外每个猜测需要返回一个对应的bounding box,而且与groundtruth的相交至少50%
检测detection:与localization不同之处在于它可以有任意数量的对象。false positives(训练得出的对象但实际不存在)将被惩罚(mAP mean average precision策略)
localization可以作为classification和detection的中间步骤。classification和localization使用相同的数据集,而detection会有另外的数据,其中的对象会比较小。
Classification
- 模型设计
输入:和AlexNext一样training时使用固定输入,但分类时会变成multi-scale。对数据进行降采样,使得最小维度为256pixel。接着,随机5次裁剪得到(221x221)pixels作为输入
超参数
| 超参数 | mini-batch | weight初始化 | 梯度下降算法 | 学习率 | dropout |
| 取值 | 128 | $(\miu, \sigma)=(0, 1x10-2)$ | SGD(momentum: 0.2, l2权重衰减1x10-5) |
5x10-2 在(30,50,60,70,80)epoch后,以0.5为系数减小 |
0.5 |
结构(accurate版本):后面的分析是基于accurate版本

1-5层与AlexNet相似,不同点:1.没有使用contrast normalization; 2. 池化区域没有相交;3. 1-2层因为有更小的stride(2而非4),所以特征map更大。更大的stride可以加快速度,但是会损害准确性
- 特征提取
AlexNet通过multi-view voting的方法来提高性能:测试时,network从256x256中抽出5个224x224patch(就是四个角和中心的区域)以及水平翻转得到10个patch,将10个patch的softmax预测平均值作为结果。这种方式会忽略掉图像的很多区域,而且重叠部分会重复计算。另外,它只适合在单一scale(视窗的大小都一样)中运用。
Multi-scale:测试阶段对图片进行各种scale缩放,然后在图上各个位置密度执行网络。滑动窗口方法在ConvNets中有天生的高效率。它可以给出更多的窗口以供voting,帮助提高鲁棒性。
网路中下采样的比例为36(网络中各个stride的乘积2x3x1x2x1x1x1x3),所以密度执行网络,最后只能每个维度的每36个像素产生一个分类向量。
过程:
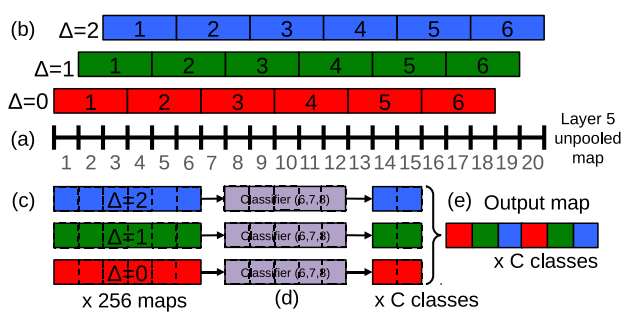
(a)对于一个图和一个给定的scale(决定网络的输入大小不同),从layer 5未池化的特征map开始
(b)对应offset={0,1,2},偏移($\Delta_{x}, \Delta_{y}$)可以有3x3种组合。每个组合对应一个未被池化的map,对每个map进行(pool size=3x3,stride=3x3)的最大池操作
(c)产生一系列的池化后的特征map,大小为(每个map池化后大小)x(3x3)
(d)分类器(6,7,8层)输入为固定的5x5,通过滑动窗口,对每个(5x5)输入产生C-dimensional分类向量
(e)不同的$(\Delta_{x},\Delta_{y})$组合可以reshape成一个3D输出图(two spatial dimensions x C classes)
以一维的数据为例:
(a)layer 5未池化的特征map为20个像素
(b)对应offset={0,1,2},可以从原来的map产生3个不同的数据集{0:, 1:, 2: }。对各个新的map做池化操作(pool size=3x3, stride=3x3),池化后得到池化的结果为6个像素
(c)和(b)一样
(d)分类器(6,7,8层)输入为固定的5(x5)。所以需要用滑动窗口(大小为5)的方式来应用分类器。每个窗口输入最后可以得到相应的分类结果(C个类的概率分布)
(e)不同的$(\Delta_{x},\Delta_{y})$结果可以reshape成一个3D输出图(offset个数 x 滑动窗口运用次数 x C classes)
上述操作相当于:在layer 5的未池化map的任意offset组合应用池化和全连接(任意连续的3个像素会被cover到,其实就是filter=3x3,stride=1x1的计算)
- 获得最终分类结果
(1)对于各个输入(不同scale、翻转),得到每个类可能的概率的最大值
(2)计算概率平均值(被判断成为该类的概率)
(3)取概率为top-1或top-5的元素为分类结果
- 卷积计算vs滑动窗口
计算的过程是一样的,但思想不同
卷积计算(特征提取):一次在整个图上执行完卷积操作
滑动窗口(分类):在不同的位置和scale下,以固定的窗口大小5x5作为分类器的输入,穷举(stride=1)计算各种可能的位置,也就是一个物体在图中各种可能的分布位置
Localization
- generate 预测
对于已经训练好的分类网络,将分类层(6,7,8)替换成一个回归网络,通过训练它来预测物体的bounding box。在softmax输出中,对每个分类c也有一个相应的置信分数(分类为c的对象出现在相应视野中的概率,其实就是softmax的计算结果)
- 回归网络训练
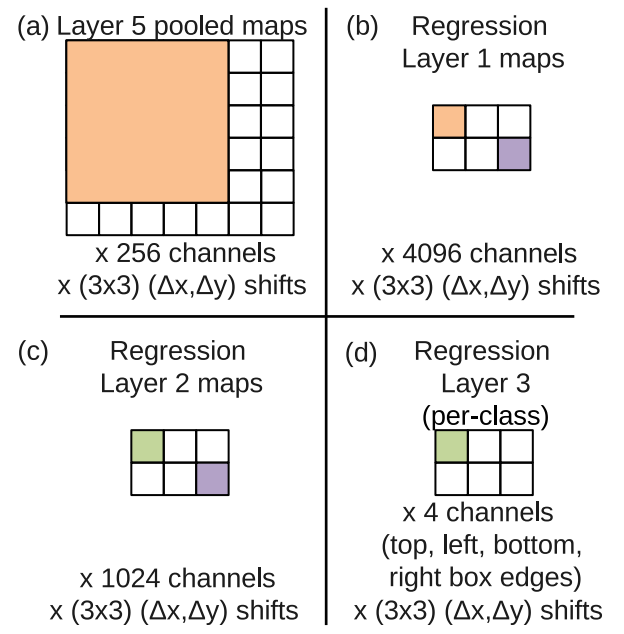 |
固定1-5层(分类训练后)结果(完成特征提取,通过后面的FC可以得到较好的分类结果) (a)回归网络输入:layer 5池化后的特征map(特定scale情况下大小6x7) (b)经过(回归网络)第一个FC(5x5x4096),回归后每个单元都与layer 5中5x5的一个区域关联。相当于用5x5的核(stride=1x1)在layer 5特征图计算 (c)经过(回归网络)第二个FC(1x1x1024),每个色块与(b)中一一对应 (d)回归网络第三层(4 channel)输出:每个类输出4个单元,(left, top, right, bottom)定义了box的左上、右下两个点 利用$l_2$ loss来训练回归网络 |
- 通过贪心方式来combine各预测
- 找出每个scale中最可能的top $k$个分类(记为$C_{s}$)
- $B_{s}$={$C_{s}$中每个类对应的bounding box}
- $B=U_{s}B_{s}$
- 重复下列操作
- 从B中找出使match_score(两个bounding box中心距离及box交叉面积的和)最小的(b1,b2)组合。$(b^{*}_{1},b^{*}_{2})=argmin_{b_{1} \neq b_{2} \in B}match\_score(b_{1},b_{2})$
- 若$match\_score(b^{*}_{1},b^{*}_{2})>t$,则停止。否则对$b^{*}_{1},b^{*}_{2}$进行合并(使用两者的平均值)
Detection
vs classification:使用空间的方式
vs location:当没有包含对象时,需要预测一个background类。传统方式是把负样本随机输入,然后把导致最多错误的在bootstrapping passes时添加到训练集中。单独的bootstrapping passes会增加训练的复杂度,而且bootstrapping passes需要进行tune以保证训练不会在一个小数据集上overfit。本文的方式:从每个图中找出感兴趣的一些负样本(如随机crop或最不喜欢的)。这种方式计算代价昂贵,但是过程会比较简单(不用bootstrapping passes),而且特征提取在分类任务中已经完成,检测时进行fine-tuning并不难。
Discussion
- 贡献
提出一个multi-scale, sliding window方法,可以同时用于classification、localization和detection
解释了如何用ConvNets高效地完成detection和localization任务
提出了一个integratd pipeline,可以在共享一个特征提取(layer 1-5)下完成多个不同的任务
- 优化
localization任务中,没有在整个网络执行back-propping
使用$l_{2}$ loss,而不是直接优化IOU(用于评估性能)(IOU可微)
bounding box的可选参数化可以让输出的去相关化
其它
1. https://www.jianshu.com/p/6d441e208547 这个文章解答了自己的一些疑惑
OverFeat学习的更多相关文章
- 深度学习论文翻译解析(十一):OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
论文标题:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 标题翻译: ...
- 对 OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 一文的理解
一点最重要的学习方法: 当你读一篇论文读不懂时,如果又读了两遍还是懵懵懂懂时怎么办???方法就是别自己死磕了,去百度一下,如果是很好的论文,大多数肯定已经有人读过并作为笔记了的,比如我现在就把我读过 ...
- Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
摘要 卷积网络在特征分层领域是非常强大的视觉模型.我们证明了经过端到端.像素到像素训练的卷积网络超过语义分割中最先进的技术.我们的核心观点是建立"全卷积"网络,输入任意尺寸,经过有 ...
- #Deep Learning回顾#之基于深度学习的目标检测(阅读小结)
原文链接:https://www.52ml.net/20287.html 这篇博文主要讲了深度学习在目标检测中的发展. 博文首先介绍了传统的目标检测算法过程: 传统的目标检测一般使用滑动窗口的框架,主 ...
- 深度学习笔记(四)VGG14
Very Deep Convolutional Networks for Large-Scale Image Recognition 1. 主要贡献 本文探究了参数总数基本不变的情况下,CNN随着层数 ...
- 第四弹:overfeat
overfeat是在AlexNet出现后,推出来的模型,其不仅用于物体分类,来用于定位,检测等,可以说是一个涉及很多应用场景的通用模型,值得看看. 本文将从两个方面来讲解,第一部分从论文角度来说一说, ...
- 学习笔记TF050:TensorFlow源代码解析
TensorFlow目录结构. ACKNOWLEDGMENTS #TensorFlow版本声明 ADOPTERS.md #使用TensorFlow的人员或组织列表 AUTHORS #TensorFlo ...
- 【转】cs231n学习笔记-CNN-目标检测、定位、分割
原文链接:http://blog.csdn.net/myarrow/article/details/51878004 1. 基本概念 1)CNN:Convolutional Neural Networ ...
- 深度学习笔记(六)VGG14
Very Deep Convolutional Networks for Large-Scale Image Recognition 1. 主要贡献 本文探究了参数总数基本不变的情况下,CNN随着层数 ...
随机推荐
- 深入理解SpringIOC容器
转载来源:[https://www.cnblogs.com/fingerboy/p/5425813.html] 前言: 在逛博客园的时候突然发现一篇关于事务的好文章,说起spring事物就离不开AOP ...
- Linux(Ubuntu)------常用命令汇总
文件 unzip -O cp936 file.zip unzip -O cp936 file.zip -d dir tar -zxvf file -C dir mv [-i ] file1 file2 ...
- React笔记:快速构建脚手架(1)
1. Create React APP React官方提供的脚手架工程Create React App:https://github.com/facebook/create-react-app Cre ...
- Manual write code to record error log in .net by Global.asax
完整的Glabal.asax代码: <%@ Application Language="C#" %> <script RunAt="server&quo ...
- Windows 上连接本地 Linux虚拟机上的 mysql 数据库
查看本机ip ifconfig 查看当前的 3306 端口状态 netstat -an|grep 3306 当前是外部无法连接状态 修改访问权限 默认的 mysql 是只能本机连接, 因此需要修改配 ...
- js 调用打印机方法
<button onclick="localdy({php echo $item['order']['id'];})" class="btn btn-xs orde ...
- 什么是GPIO?
”通用输入/输出口”(GPIO)是一个灵活的由软件控制的数字信号.他们可由多种芯片提供,且对于从事嵌入式和定制硬件的Linux开发者来说是比较熟 悉.每个GPIO都代表一个连接到特定引脚或球栅阵列(B ...
- atlassian-jira部署文档
部署mysql数据库,我这里使用mariadb数据库,并且创建jira的数据库和用户,下面是创建jira数据库和用户的操作,安装数据库mysq过程略.(MYSQL数据库也是可以的,不过mysql的驱动 ...
- vscode笔记(一)- vscode自动生成文件头部注释和函数注释
VsCode 自动生成文件头部注释和函数注释 作者:狐狸家的鱼 本文链接:vscode自动生成文件头部注释和函数注释 GitHub:sueRimn 1.安装插件KoroFileHeader 2.设置 ...
- 理解依赖注入,laravel IoC容器
在看laravel文档的时候,有一个服务容器(IoC)的概念.它是这样介绍的:Laravel 服务容器是一个用于管理类依赖和执行依赖注入的强大工具.依赖注入听上去很花哨,其实质是通过构造函数或者某些情 ...