信用卡欺诈数据的分析-excel篇
本篇文章为大家提供了数据集分析的思路和步骤,同时也分享了自己的经验。
一、背景
反欺诈是一项识别服务,是对交易诈骗、网络诈骗、电话诈骗、盗卡盗号等行为的一项风险识别。其核心是通过大数据的收集、分析和处理,建立反欺诈信用评分和反欺诈模型,解决不同场景中的风险问题。
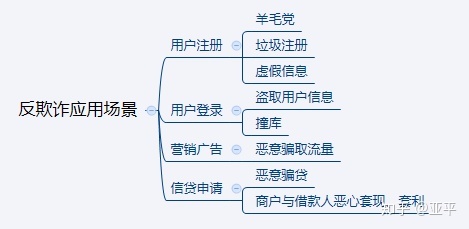
国内常见的提供反欺诈服务的公司有:同盾科技,百融金服,众安保险的Xmodel,腾讯的天御借贷反欺诈AF,阿里云的云盾,蚂蚁金服的蚁盾;模式多为Sass服务,产品形态为客户端控制台+服务端调用反欺诈API。
二、数据集分析
数据样本为2013年9月欧洲持卡人在两天内进行的284,808笔信用卡交易,其中493笔是欺诈交易。数据集非常不平衡,被盗刷占所有交易的0.173%。
它只包含作为PCA转换结果的数字输入变量。不幸的是,由于保密问题,我们无法提供有关数据的原始功能和更多背景信息。
特征V1,V2,… V28是使用PCA获得的主要组件,没有用PCA转换的唯一特征是“时间”和“量”。
特征“时间”包含数据集中每个事务和第一个事务之间经过的秒数。特征“金额”是交易金额,此特征可用于实例依赖的成本认知学习。特征“类”是响应变量,如果发生被盗刷,则取值1,否则为0。
包含:Time(交易时间,需将s转化为hh-mm-ss形式),V1~V28(经PCA转换后的数字变量),Amount(交易金额),Class(交易类型,1为欺诈,0为正常)
三、分析思路
在已知欺诈交易和非欺诈交易的情况下,分析两类的交易指标的四分位数、最大值、最小值、标准差、方差;四分位数和最大最小值可以绘制出该指标的箱线图,找出离群点,也可以观察出该指标中数据的离散程度;
通过方差观察该指标数据的稳定程度,通过标准差观察该指标数据的偏离程度,一般都应符合正态分布;做出图形后,观察欺诈交易在图形中的分布;
通过时间分析,寻找欺诈交易在哪些时间点发生的概率更高;
通过金额分析,寻找欺诈交易金额在哪个区间范围内概率更高,对比非欺诈交易金额的区间范围i;
通过对V1~V28的分析,寻找该字段下欺诈交易与非欺诈交易各自的规则;
通过以上的分析,寻找欺诈交易和非欺诈交易的各自特性,当有新的一笔交易进入时,判断其属于哪一类的概率更高;
由于数据集受限,如果能对单个交易账户分析,在数据中增加交易地点、交易商户类别、交易频率的指标都可以使得分析更全面。
四、分析步骤
第一步:检查数据,是否有缺失值,数据类型是否符合将要进行的分析,结果为无缺失值,同时将欺诈交易与正常交易区分为两个工作表,方便后面分析;数据总计为28.4万条;
第二步:将时间换算为小时,总计为48小时,以1小时为间隔进行分组;
1. 分析交易时间与交易量的关系
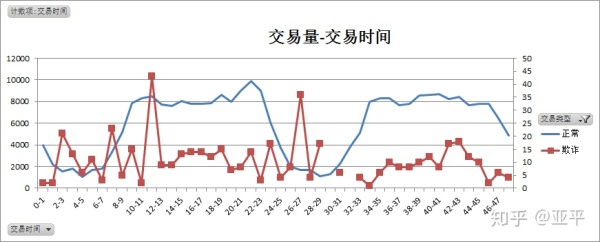
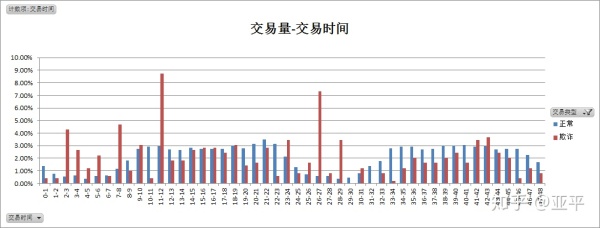
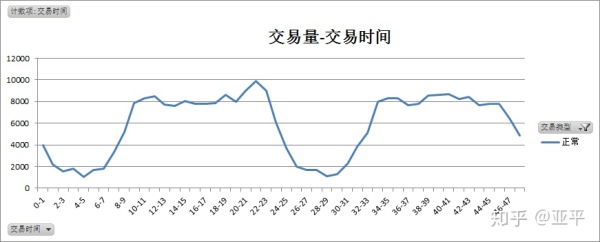
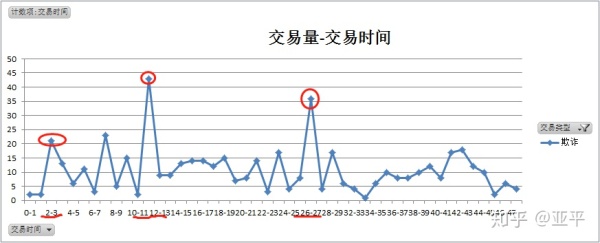
正常交易特点:
正常交易分布聚集度明显,主要集中在上午9点-下午23点,在凌晨0点-上午7点交易量较低。
欺诈交易特点:
欺诈交易的时间离散度高,但在峰值迹象出现在两天的凌晨2-3点,第一天的11-12点,在上午7-12点,下午2-10点,两个时间段的总量分别为88笔、97笔,且每1小时的交易量都比较平均。
综合以上:
在凌晨0点-4点间的交易,为欺诈交易的概率高;在上午9点-下午10点间,欺诈交易多伪装成正常交易。
2. 分析交易金额与交易量的关系
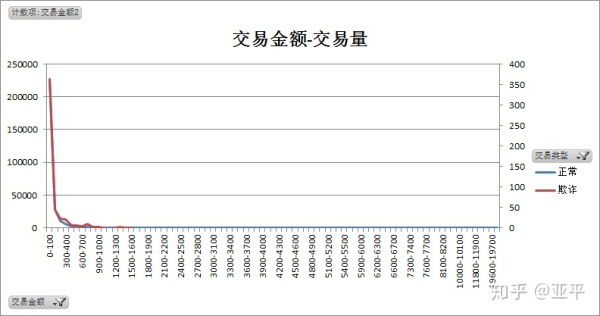
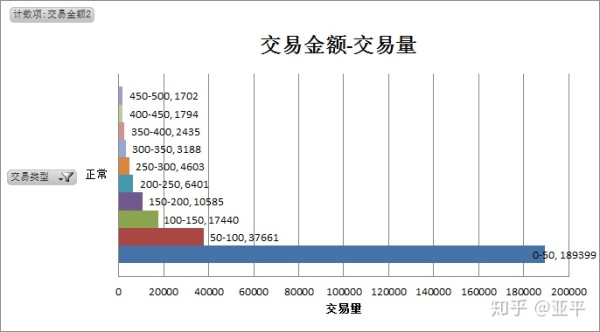
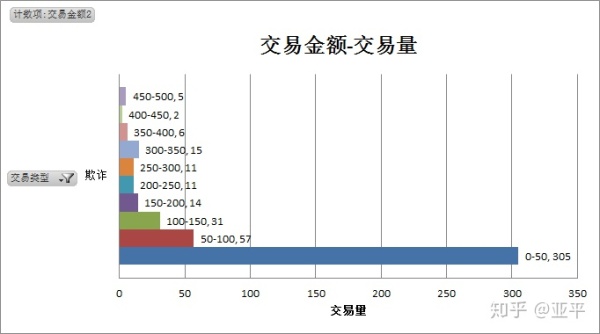
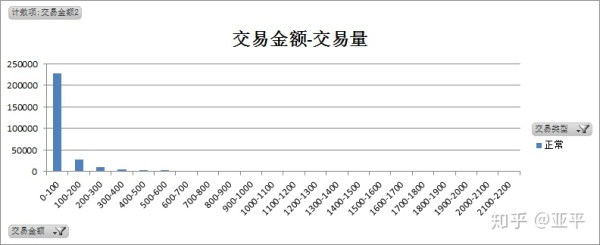
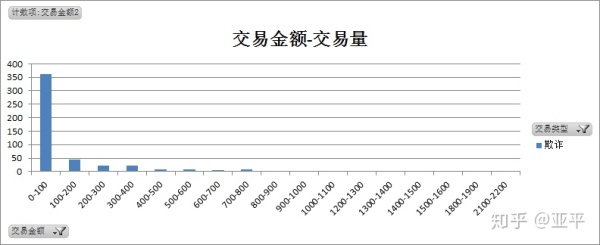
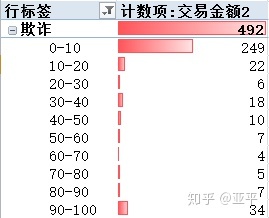
从交易金额与交易量中明显看出,无论是欺诈交易还是正常交易,单笔交易金额都比较低,大量聚集在100元以下,将交易金额下钻至0-500元范围内,对比欺诈交易与正常交易的特点。
正常交易:
正常交易共284315笔,单笔最大值为25,691.16,其中单笔500元以下的交易共有27.5万笔,占交易总量的96.8%。
欺诈交易:
欺诈交易共492笔,单笔最大值为2,125.87,单笔金额多为50元以下,总计305笔占欺诈交易总量的62%,其中10元以下共249笔占欺诈交易总量50%,其次为90-100元,总计34笔。
综合以上:
欺诈交易和正常交易在图形的趋势上相似,都聚集于小额交易,单笔交易金额50元以下的为欺诈交易的概率更高。
3. 分析不同交易类型的映射值特点
通过对正常交易与欺诈交易的映射值对比分析,可以建立两种交易的映射值模型。
这批数据的处理过程中着实麻烦,每个字段下有20万+数据,excel经常出现崩溃,原本我的思路是得出每个映射值的描述统计,使用切片器在数据透视表中对不同的映射值对应的同一描述统计字段进行视图。
最后改变策略为取映射值在-1~1之间,相同数量范围内观察映射值的特点;其实这样做是有缺点的,所取某个范围内的样本不具有普遍代表性。
期间我还尝试过另一种方法,在每个映射值中随机抽取500个样本,输出描述统计,与欺诈交易的描述统计作比较,在此就不再上图。
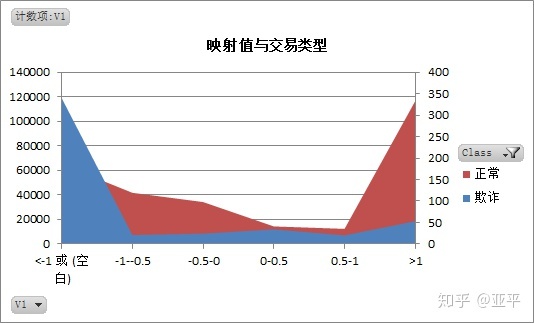
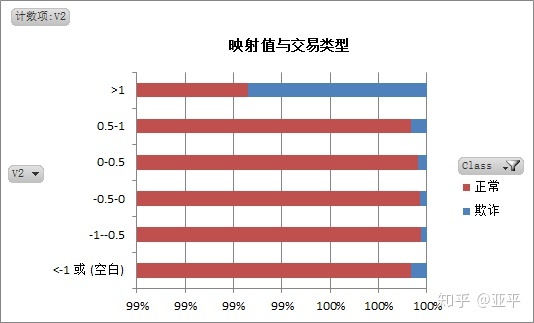
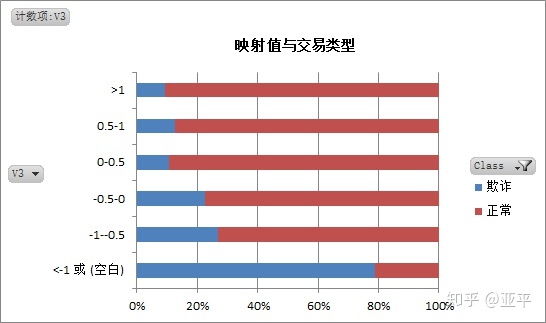
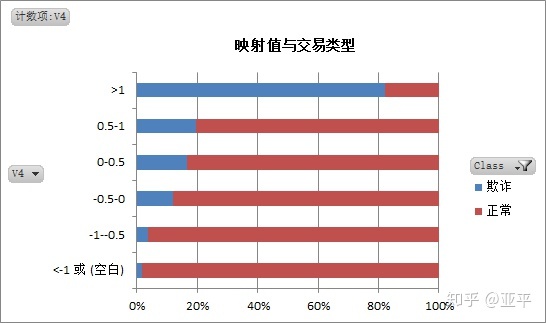
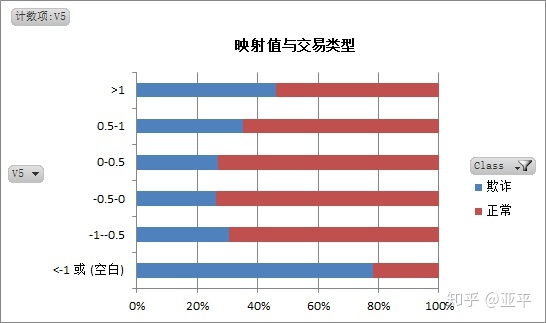
综合以上:
通过对交易金额、交易时间、交易的映射值进行大量数据统计分析,建立欺诈交易和正常交易的模型,当一笔交易进入时,在模型中根据各个特性的得分,得到最终评分,以某阈值为分界点,将交易判定为正常或欺诈。
五、经验分享
1. 在输出前要明确自己分析的目标和思路,可以做模糊假设,在分析的过程中谨慎求证;输出的结果要检查是否为真,是否符合源数据,避免如数据类型的转换过程中出现错误;
2. excel中的数据透视图和数据分析很好用,在数据分析中有其他的方法比如随机抽样,回归等,虽然还不明白,但觉得里面嵌入的功能很多且高级;
3. 本次数据分析中,并没有使用到太多vlookup的关联查询,在之后的练习中找一个关于此类查询进行练习。
信用卡欺诈数据的分析-excel篇的更多相关文章
- 从信用卡欺诈模型看不平衡数据分类(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制。过采样后模型选择RF、xgboost、神经网络能够取得非常不错的效果。(2)模型层面:使用模型集成,样本不做处理,将各个模型进行特征选择、参数调优后进行集成,通常也能够取得不错的结果。(3)其他方法:偶尔可以使用异常检测技术,IF为主
总结:不平衡数据的分类,(1)数据层面:使用过采样是主流,过采样通常使用smote,或者少数使用数据复制.过采样后模型选择RF.xgboost.神经网络能够取得非常不错的效果.(2)模型层面:使用模型 ...
- 鸿蒙内核源码分析(管道文件篇) | 如何降低数据流动成本 | 百篇博客分析OpenHarmony源码 | v70.01
百篇博客系列篇.本篇为: v70.xx 鸿蒙内核源码分析(管道文件篇) | 如何降低数据流动成本 | 51.c.h.o 文件系统相关篇为: v62.xx 鸿蒙内核源码分析(文件概念篇) | 为什么说一 ...
- 你别告诉我你还在用Excel做数据透视分析吧,太low了!
来到大数据分析的时代,大量的大数据分析软件涌现,尽管如此,如果今天有人问起最常用的数据透视分析工具是什么的时候,我猜想Excel应该是大家的不二之选. 但是其实我想说,用现在的手机来打比方,Excel ...
- 第二篇:智能电网(Smart Grid)中的数据工程与大数据案例分析
前言 上篇文章中讲到,在智能电网的控制与管理侧中,数据的分析和挖掘.可视化等工作属于核心环节.除此之外,二次侧中需要对数据进行采集,数据共享平台的搭建显然也涉及到数据的管理.那么在智能电网领域中,数据 ...
- 海外支付:抵御信用卡欺诈的CyberSource
海外支付:抵御信用卡欺诈的CyberSource 吴剑 2014-06-04 原创文章,转载必需注明出处:http://www.cnblogs.com/wu-jian 吴剑 http://www.cn ...
- ML.NET 示例:二元分类之信用卡欺诈检测
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- 【Social listening实操】作为一个合格的“增长黑客”,你还得重视外部数据的分析!
本文转自知乎 作者:苏格兰折耳喵 ----------------------------------------------------- 在本文中,作者引出了"外部数据"这一概 ...
- 机器学习_线性回归和逻辑回归_案例实战:Python实现逻辑回归与梯度下降策略_项目实战:使用逻辑回归判断信用卡欺诈检测
线性回归: 注:为偏置项,这一项的x的值假设为[1,1,1,1,1....] 注:为使似然函数越大,则需要最小二乘法函数越小越好 线性回归中为什么选用平方和作为误差函数?假设模型结果与测量值 误差满足 ...
随机推荐
- WEUI滚动加载
var row = 6, page = 1; var loading = false; //状态标记 $(document.body).infinite().on("infinite&quo ...
- python模块的使用
这位老师的文章说的很清楚:模块 这里我只说一下,我在使用过程中的一些注意事项. 比如,我创建了一个包,该包下面有两个模块:model1和model2,如下图 那么我们再python中怎样去使用自己创建 ...
- oracle 增加大字段项
--不同类型增加大字段项 alter table 表名 add 新增一个字段B clob; --将需要改成大字段的项内容copy到大字段中 update 表名 set 新增一个字段B=字段A; --将 ...
- orm 扩展
"""ORM小练习 如何在一个Python脚本或文件中 加载Django项目的配置和变量信息""" import os if __name_ ...
- @keyframs实现图片gif效果
页面中使用动效图 一般让设计出一个gif格式的图,但是git图效果都很差,有一个替代gif图做动效的方法:使用@keyframes 具体思路: 1.设计两个互斥的图片(相当于把gif图分割成一帧一帧的 ...
- Hadoop之HDFS概述
一.HDFS产生背景及定义 1.HDFS产生背景 随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文 ...
- introduce explaining variable 引入解释变量
一段复杂的计算的表达式(一般 逻辑判断 if(a!=1 && b!=Null && a>b ) && .... 直接在代码中参与到 代码的逻辑 ...
- spoj839Optimal Marks
题意:略 怎样判断属于S,T集合. 如果从S出发到不了某点,该点出发也到不了T,那么割给那边都行. 如果S出发能到该点,该点出发也能到T,这种情况下dinic没结束. 只能从S到该点:只能分到S集.只 ...
- xlwt模块的使用
前记:Python处理表格时会用到xlwt和xlrd模块 xlwt设置行高:row sheet.row(2).set_style(xlwt.easyxf('font:height 440;')) 13 ...
- LINUX内核PCI扫描过程
LINUX内核PCI扫描过程 内核版本 3.10.103 1. ACPI热插拔扫描subsys_initcall(acpi_init)@drivers/acpi/bus.c |-acpi_scan_i ...