【Spark篇】---Spark中Transformations转换算子
一、前述
Spark中默认有两大类算子,Transformation(转换算子),懒执行。action算子,立即执行,有一个action算子 ,就有一个job。
通俗些来说由RDD变成RDD就是Transformation算子,由RDD转换成其他的格式就是Action算子。
二、常用Transformation算子
假设数据集为此:
1、filter
过滤符合条件的记录数,true保留,false过滤掉。
Java版:
package com.spark.spark.transformations; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
/**
* filter
* 过滤符合符合条件的记录数,true的保留,false的过滤掉。
*
*/
public class Operator_filter {
public static void main(String[] args) {
/**
* SparkConf对象中主要设置Spark运行的环境参数。
* 1.运行模式
* 2.设置Application name
* 3.运行的资源需求
*/
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("filter");
/**
* JavaSparkContext对象是spark运行的上下文,是通往集群的唯一通道。
*/
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("./words.txt");
JavaRDD<String> resultRDD = lines.filter(new Function<String, Boolean>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Boolean call(String line) throws Exception {
return !line.contains("hadoop");//这里是不等于
} }); resultRDD.foreach(new VoidFunction<String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(String line) throws Exception {
System.out.println(line);
}
});
jsc.stop();
}
}
scala版:
函数解释:
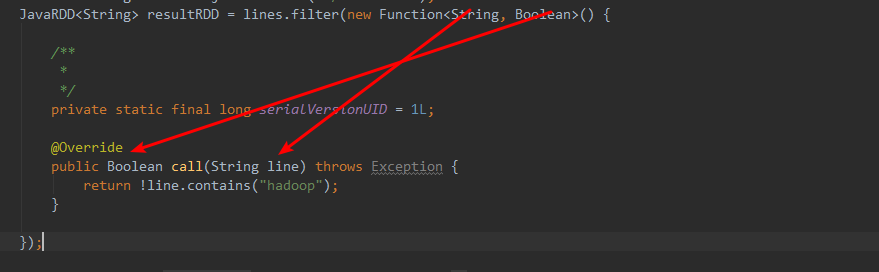
进来一个String,出去一个Booean.
结果:

2、map
将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。
特点:输入一条,输出一条数据。
/**
* map
* 通过传入的函数处理每个元素,返回新的数据集。
* 特点:输入一条,输出一条。
*
*
* @author root
*
*/
public class Operator_map {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("map");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> line = jsc.textFile("./words.txt");
JavaRDD<String> mapResult = line.map(new Function<String, String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public String call(String s) throws Exception {
return s+"~";
}
}); mapResult.foreach(new VoidFunction<String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(String t) throws Exception {
System.out.println(t);
}
}); jsc.stop();
}
}
函数解释:
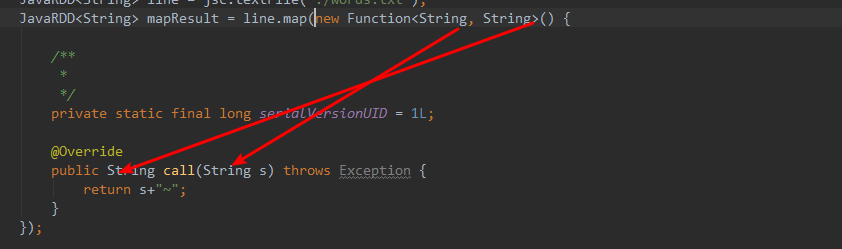
进来一个String,出去一个String。
函数结果:

3、flatMap(压扁输出,输入一条,输出零到多条)
先map后flat。与map类似,每个输入项可以映射为0到多个输出项。
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.VoidFunction; /**
* flatMap
* 输入一条数据,输出0到多条数据。
* @author root
*
*/
public class Operator_flatMap {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("flatMap"); JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("./words.txt");
JavaRDD<String> flatMapResult = lines.flatMap(new FlatMapFunction<String, String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String s) throws Exception { return Arrays.asList(s.split(" "));
} });
flatMapResult.foreach(new VoidFunction<String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(String t) throws Exception {
System.out.println(t);
}
}); jsc.stop();
}
}
函数解释:
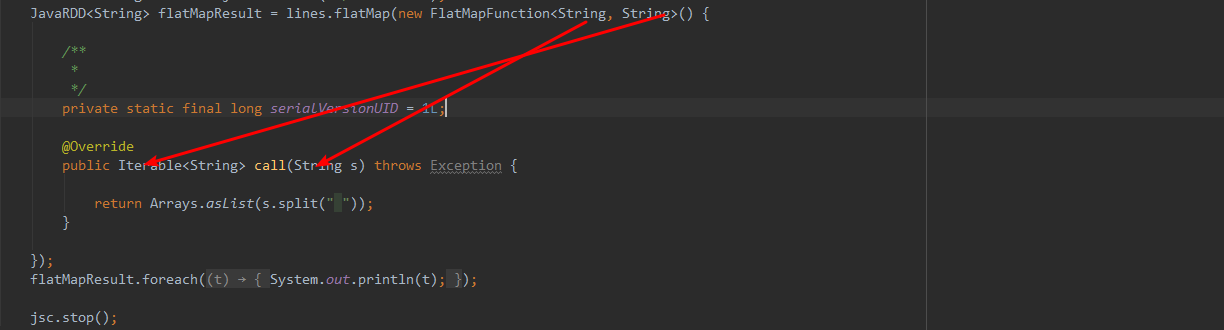
进来一个String,出去一个集合。
函数结果:

4、sample(随机抽样)
随机抽样算子,根据传进去的小数按比例进行又放回或者无放回的抽样。(True,fraction,long)
True 抽样放回
Fraction 一个比例 float 大致 数据越大 越准确
第三个参数:随机种子,抽到的样本一样 方便测试
package com.spark.spark.transformations; import java.util.ArrayList;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFlatMapFunction;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class Operator_sample {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("sample"); JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("./words.txt");
JavaPairRDD<String, Integer> flatMapToPair = lines.flatMapToPair(new PairFlatMapFunction<String, String, Integer>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Iterable<Tuple2<String, Integer>> call(String t)
throws Exception {
List<Tuple2<String,Integer>> tupleList = new ArrayList<Tuple2<String,Integer>>();
tupleList.add(new Tuple2<String,Integer>(t,1));
return tupleList;
}
});
JavaPairRDD<String, Integer> sampleResult = flatMapToPair.sample(true,0.3,4);//样本有7个所以大致抽样为1-2个
sampleResult.foreach(new VoidFunction<Tuple2<String,Integer>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t);
}
}); jsc.stop();
}
}
函数结果:

5.reduceByKey
将相同的Key根据相应的逻辑进行处理。
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class Operator_reduceByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("reduceByKey");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("./words.txt");
JavaRDD<String> flatMap = lines.flatMap(new FlatMapFunction<String, String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
}
});
JavaPairRDD<String, Integer> mapToPair = flatMap.mapToPair(new PairFunction<String, String, Integer>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String t) throws Exception {
return new Tuple2<String,Integer>(t,1);
} }); JavaPairRDD<String, Integer> reduceByKey = mapToPair.reduceByKey(new Function2<Integer,Integer,Integer>(){ /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
} },10);
reduceByKey.foreach(new VoidFunction<Tuple2<String,Integer>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t);
}
}); jsc.stop();
}
}
函数解释:
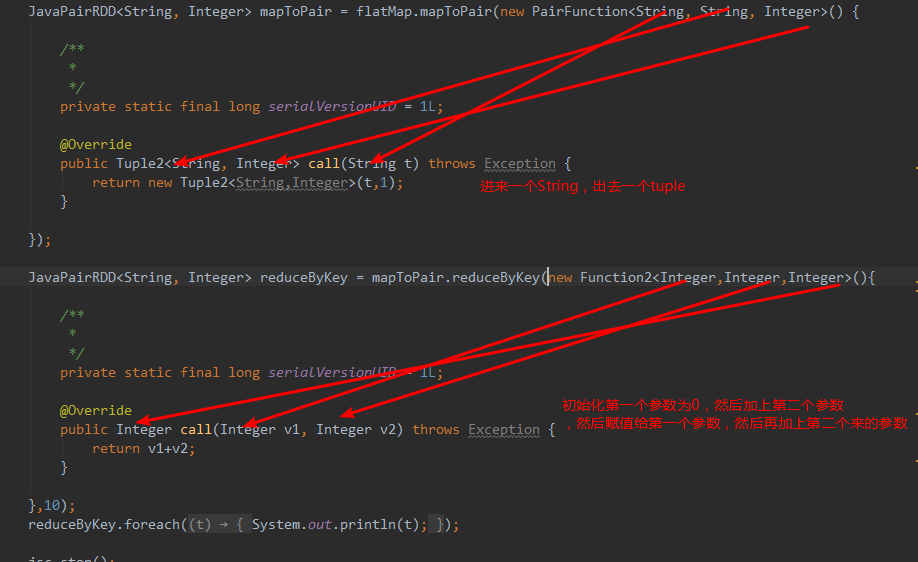
函数结果:

6、sortByKey/sortBy
作用在K,V格式的RDD上,对key进行升序或者降序排序。
Sortby在java中没有
package com.spark.spark.transformations; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class Operator_sortByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("sortByKey");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile("./words.txt");
JavaRDD<String> flatMap = lines.flatMap(new FlatMapFunction<String, String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
}
});
JavaPairRDD<String, Integer> mapToPair = flatMap.mapToPair(new PairFunction<String, String, Integer>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
}); JavaPairRDD<String, Integer> reduceByKey = mapToPair.reduceByKey(new Function2<Integer, Integer, Integer>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
});
reduceByKey.mapToPair(new PairFunction<Tuple2<String,Integer>, Integer, String>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> t)
throws Exception {
return new Tuple2<Integer, String>(t._2, t._1);
}
}).sortByKey(false).mapToPair(new PairFunction<Tuple2<Integer,String>, String, Integer>() {//先把key.value对调,然后排完序后再对调回来 false是降序,True是升序 /**
*
*/
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> t)
throws Exception {
return new Tuple2<String,Integer>(t._2,t._1);
}
}).foreach(new VoidFunction<Tuple2<String,Integer>>() { /**
*
*/
private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t);
}
});
}
}
代码解释:先对调,排完序,在对调过来
代码结果:

【Spark篇】---Spark中Transformations转换算子的更多相关文章
- Spark—RDD编程常用转换算子代码实例
Spark-RDD编程常用转换算子代码实例 Spark rdd 常用 Transformation 实例: 1.def map[U: ClassTag](f: T => U): RDD[U] ...
- Spark中RDD转换成DataFrame的两种方式(分别用Java和Scala实现)
一:准备数据源 在项目下新建一个student.txt文件,里面的内容为: ,zhangsan, ,lisi, ,wanger, ,fangliu, 二:实现 Java版: 1.首先新建一个s ...
- HBase读写的几种方式(二)spark篇
1. HBase读写的方式概况 主要分为: 纯Java API读写HBase的方式: Spark读写HBase的方式: Flink读写HBase的方式: HBase通过Phoenix读写的方式: 第一 ...
- Spark调研笔记第6篇 - Spark编程实战FAQ
本文主要记录我使用Spark以来遇到的一些典型问题及其解决的方法,希望对遇到相同问题的同学们有所帮助. 1. Spark环境或配置相关 Q: Sparkclient配置文件spark-defaults ...
- 【转帖】HBase读写的几种方式(二)spark篇
HBase读写的几种方式(二)spark篇 https://www.cnblogs.com/swordfall/p/10517177.html 分类: HBase undefined 1. HBase ...
- spark教程(四)-SparkContext 和 RDD 算子
SparkContext SparkContext 是在 spark 库中定义的一个类,作为 spark 库的入口点: 它表示连接到 spark,在进行 spark 操作之前必须先创建一个 Spark ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- 【转载】Spark学习——spark中的几个概念的理解及参数配置
首先是一张Spark的部署图: 节点类型有: 1. master 节点: 常驻master进程,负责管理全部worker节点.2. worker 节点: 常驻worker进程,负责管理executor ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
随机推荐
- Mac smartsvn破解及license文件
第一步:去官网下载自己系统smartsvn版本文件 下载地址:http://www.smartsvn.com/download 第二步:破解 (1) 将文件解压到系统路径:/opt/smartsvn ...
- 修改 salt-minion 的 ID 后报错解决方法
当在搭建 Saltstack 集中化管理平台配置完毕时,启动服务时,不知道是否你也越到过如下报错的现象呢? 报错问题如下: [root@saltstack_web1group_1 ~]# vim /e ...
- POJ 3268 (dijkstra变形)
题目链接 :http://poj.org/problem?id=3268 Description One cow from each of N farms (1 ≤ N ≤ 1000) conveni ...
- php的运行机制
php的解析过程是 apache -> httpd -> php5_module -> sapi -> php cgi (外部应用程序)只是用来解析php代码的 sapi中的其 ...
- 彻底解决eclipse中tomcat启动速度缓慢的问题
问题: Tomcat启动提示At least one JAR was scanned for TLDs yet contained no TLDs tomcat启动速度总是很慢,检查后发现tomcat ...
- supervisor 配置程序挂起自启动
使用 supervisor 服务,将程序监控起来,如果程序挂掉了,可以实现自启动 编写 c++ 程序 test.c #include <stdio.h> #include <stri ...
- [ubuntu]apt-get update突然出现arm package找不到
https://blog.csdn.net/l741299292/article/details/69671789
- JQuery实现旋转轮播图
css部分 <style> *{ margin:; padding:; } .container{ width:100%; height:353px; margin-top: 20px; ...
- input标签实现小数点后两位保留小数
短短一行代码就可以实现 <input type="number" min="0" max="100" step="0.01& ...
- 动态sql语句,非存储过程,如何判断某条数据是否存在,如果不存在就添加一条
已知一个表 table 里面有两个字段 A1 和 A2 如何用动态语句 判断 A1 = A , A2=B 的数据是否存在,如果不存在,就添加一条数据, A1 = A , A2 = B INSERT ...