PostgreSQL>窗口函数的用法
PostgreSQL之窗口函数的用法
转载请注明出处:https://www.cnblogs.com/funnyzpc/p/9311281.html
PostgreSQL的高级特性本准备三篇的(递归、窗口函数、JSON),结果中间一直一直加班 和遗忘 拖到现在才写到中篇,欸,加班真不是一件好事情。
谈谈我对加班的看法吧=> 如果加班能控制在一个小时内,这样会比较好(当然如果不加班的话更好),偶尔适当的加班能提高工作进度,对创业公司来说尤为重要;但,糟糕的地方也不少,加班时间长了容易造成思维缓慢,这对脑子本来就不快的人来说伤害尤其的大(我就是个例子),也容易造成颈椎病、高血压、过劳。。。等等可怕的疾病,尤其还是做IT的一定要注意到这个问题,以上这些话可能有童鞋不会在意,那我就在这里说说我见过的真实的例子,我上一家公司的CTO有比较严重的脊椎病,(他说)坐的时间久了背部尤其的难受,上一家公司总监也经常加班,可能再加上本身体质的原因,心脏现在已经装上了起搏器,同样是上一家公司,我的一同事,也就比我大三岁左右,头发已经有相当部分白了哎,每见到这样的事儿都很难受,人一辈子,如果没有足够的时间去关注生活,关注健康,我们生活内容还剩下什么?
这次我就简单的讲讲PostgreSQL的高级特性>窗口函数
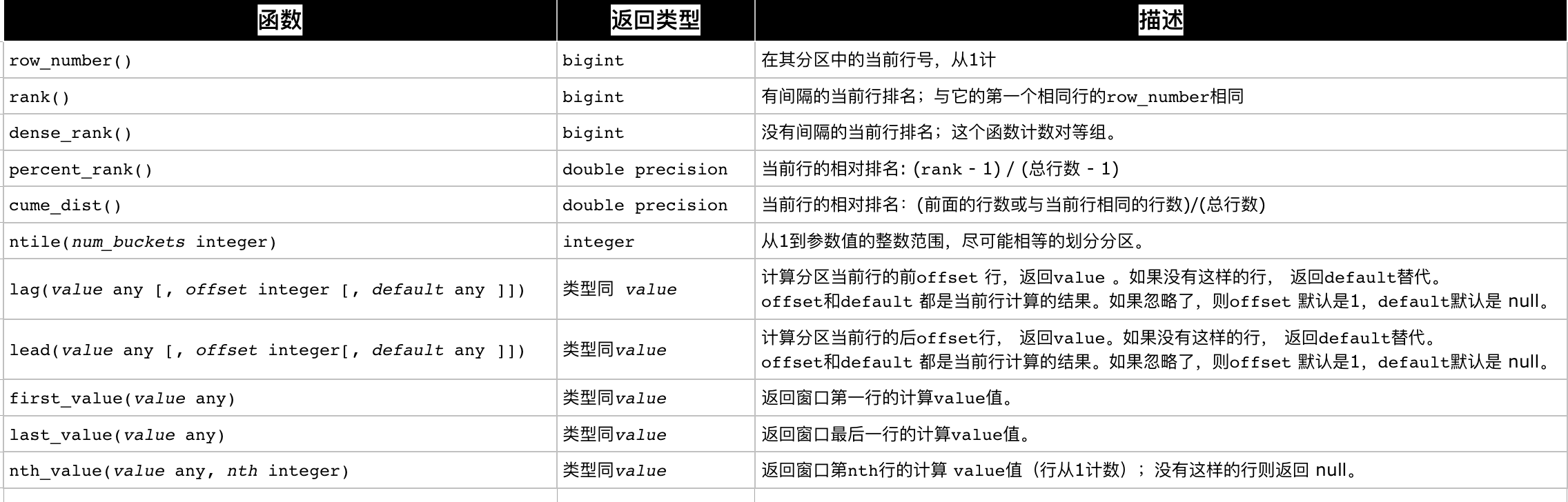
我先用表格列出PostgreSQL里面的窗口函数,(源文档在这里>http://www.postgres.cn/docs/9.3/functions-window.html,推荐去postgre的中文社区看看)
讲第一个问题之前我先扔出一个需求>如何给查询出来的数据添加一列序号,用最简单的方式实现?
Oracle>使用rownum快速生成
MySql>使用变量定义:(@i:=@i+1) as row
SqlServer>通过定义存储过程的方式
PostgreSQL>通过函数generate_series(start_value,end_value)
额,以上方式我大概都用过,对于Oracle的方式虽然语句简单,但是涉及到排序的时候可就乱了,mysql的方式也还算可以,但是这样并没有通用性,子查询的时候会相当麻烦,同时个人觉得这更像是存储过程和sql的结合体,也破坏了Sql本该有的形式,PostgreSQL的方式虽然不错,但是总要指定起始和终止值,这个在生成测试数据的时候还好用,具体业务开发用起来可就麻烦多了;这里,当然有更好的实现方式>窗口函数,这个属性在主流的数据库系统中都有实现(以前用oracle的时候竟然没发现这么好用的东西,好遗憾)。
这里我先放出表结构语句:
DROP TABLE IF EXISTS "public"."products";
CREATE TABLE "public"."products" (
"id" varchar(10) COLLATE "default",
"name" text COLLATE "default",
"price" numeric,
"uid" varchar(14) COLLATE "default",
"type" varchar(100) COLLATE "default"
)
WITH (OIDS=FALSE); BEGIN;
INSERT INTO "public"."products" VALUES ('', 'iPhone X', '', null, '电器');
INSERT INTO "public"."products" VALUES ('', '电视', '', '', '电器');
INSERT INTO "public"."products" VALUES ('', '辣条', '5.6', '', '零食');
INSERT INTO "public"."products" VALUES ('', '薯条', '7.5', '', '零食');
INSERT INTO "public"."products" VALUES ('', '方便面', '3.5', '', '零食');
INSERT INTO "public"."products" VALUES ('', '铅笔', '', '', '文具');
INSERT INTO "public"."products" VALUES ('', '作业本', '', null, '文具');
INSERT INTO "public"."products" VALUES ('', '鞋子', '', '', '衣物');
INSERT INTO "public"."products" VALUES ('', '外套', '110.9', '', '衣物');
INSERT INTO "public"."products" VALUES ('', '围巾', '', '', '衣物');
INSERT INTO "public"."products" VALUES ('', '香皂', '17.5', '', '日用品');
INSERT INTO "public"."products" VALUES ('', '水杯', '', '', '日用品');
INSERT INTO "public"."products" VALUES ('', '洗发露', '', '', '日用品');
INSERT INTO "public"."products" VALUES ('', '毛巾', '', '', '日用品');
INSERT INTO "public"."products" VALUES ('', '手表', '1237.55', '', '电器');
INSERT INTO "public"."products" VALUES ('', '绘图笔', '', null, '文具');
INSERT INTO "public"."products" VALUES ('', '汽水', '3.5', null, '零食');
COMMIT;
这我先用第一个函数row_number() ,一句即可实现>
select type,name,price,row_number() over(order by price asc) as idx from products ;
结果>
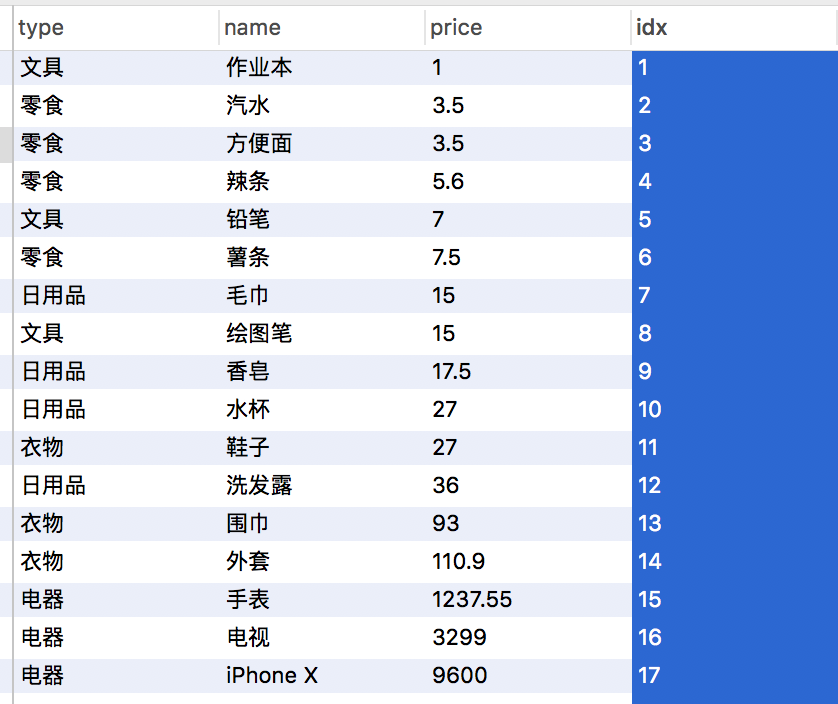
用窗口函数的好处不仅仅可实现序号列,还可以在over()内按指定的列排序,上图是按照price列升序。
这里,对于以上提到的一个问题,根据上面的数据 我再做个扩充>如果需要在类别(type)内按照价格(price) 升序排列(就是在类别内做排序),该怎么做呢?
当然也很简单,只需要在窗口(over())中声明分隔方式 Partition .
分类排序序号,row_number() 实现>
select type,name,price,row_number() over(PARTITION by type order by price asc) as idx from products ;
查询结果>
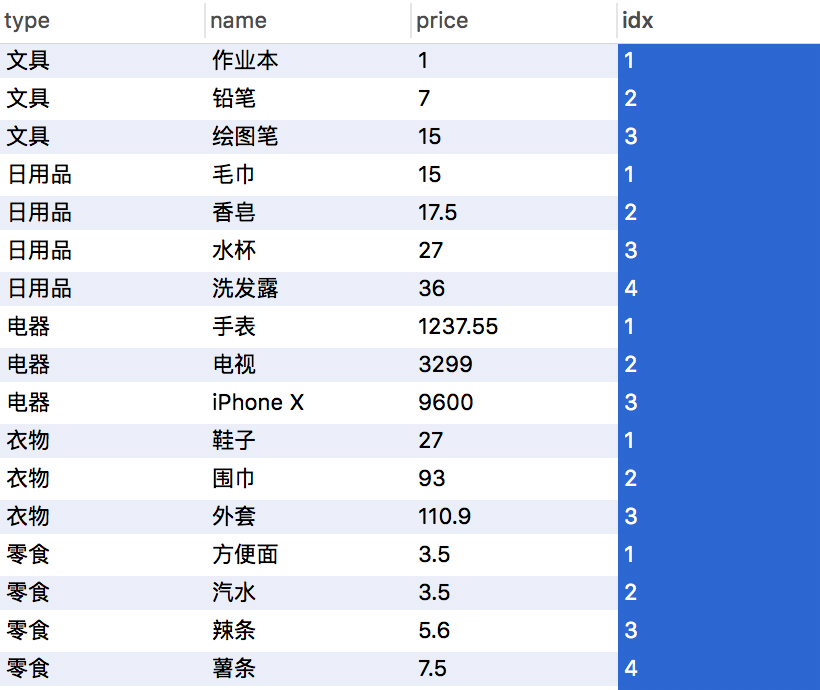
上面的问题这里需求完美实现,额,这里其实还可以做个扩充,你可以注意到零食类别内的 方便面和汽水价格是一样的,如何将零食和汽水并列第一呢?答案是:用窗口函数>rank()
分类排序序号并列, rank() 实现>
SELECT type,name,price,rank() over(partition by type order by price asc) from products;
SQL输出>
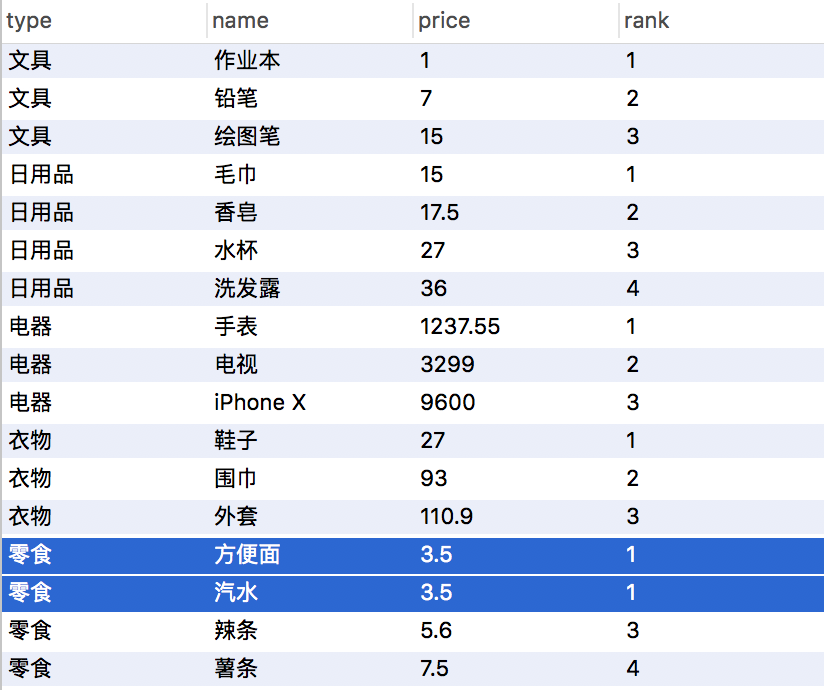
需求又完美的实现了,但,注意到没,零食类别中的第三个 辣条 排到第三了,如果这里需要在类别里面能保持序号不重不少(将辣条排名至第二),如何实现呢?答案>使用窗口函数 dense_rank()
分类排序序号并列顺序,dense_rank() 实现>
SELECT type,name,price,dense_rank() over(partition by type order by price asc) from products;
SQL输出>
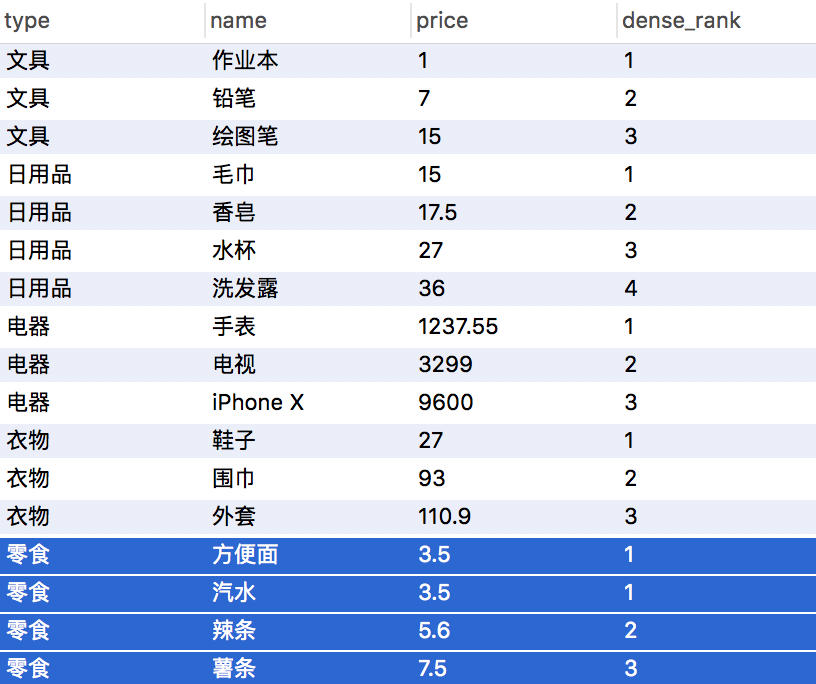
OK,以上的几个窗口函数已经能实现大多数业务需求了,如果有兴趣可以看看一些特殊业务可能用到的功能,比如说如何限制序号在0到1之间排序呢?
限制序号在0~1之间(0作为第一个序),窗口函数 percernt_rank() >
SELECT type,name,price,percent_rank() over(partition by type order by price asc) from products;
SQL语句输出>
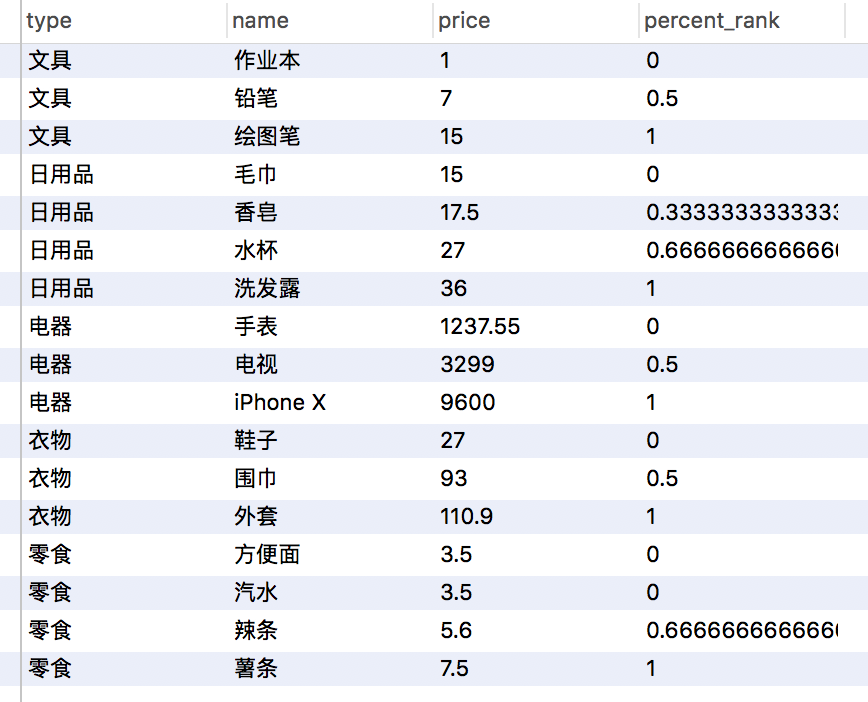
注意:上面的percernt_rank()函数默认是从0开始排序的,如果需要使用相对0~1之间的排名,需要这样:
限制序号在0~1之间相对排名,窗口函数 cume_dist() 实现>
SELECT type,name,price,cume_dist() over(partition by type order by price asc) from products;
SQL语句输出>
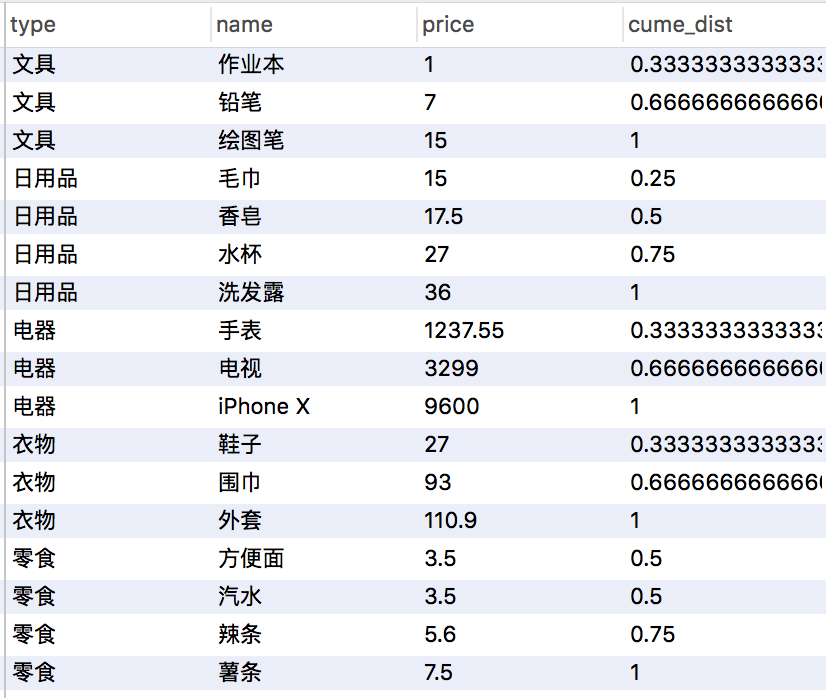
注意:上面的序号是相对于0开始排序的。
对于排序序号还可以限制最大序号,这样做:
限制最大序号为指定数字序号 ntile(val1) 实现 >
SELECT type,name,price,ntile(2) over(partition by type order by price asc) from products;
SQL语句输出 >
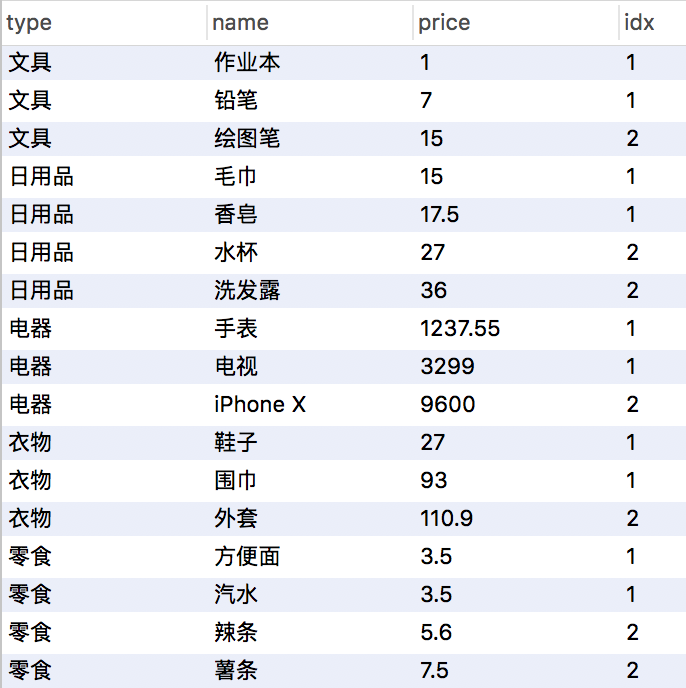
窗口函数还可以实现在子分类排序的情况下取偏移值,这样实现>
获取到排序数据的每一项的偏移值(向下偏移) , lag(val1,val2,val3) 函数实现>
SELECT id,type,name,price,lag(id,1,'') over(partition by type order by price asc) as topid from products;
SQL语句输出 >
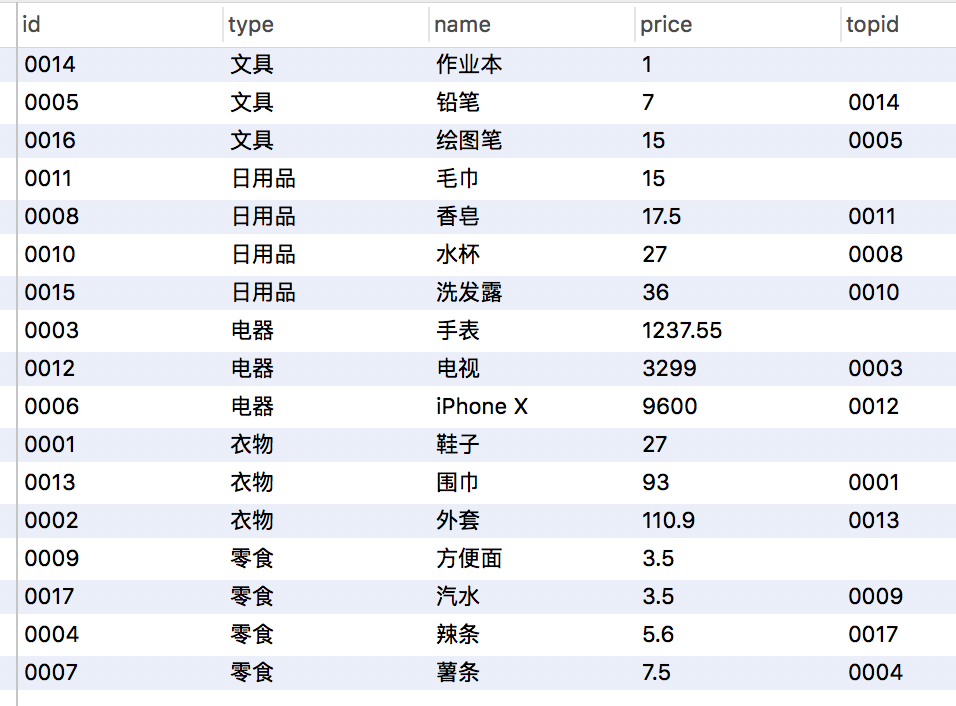
注意:函数lag(val1,val2,val3) 中的三个参数分别为->(输出的上一条记录的字段,偏移值,无偏移值的默认值);以上这里的偏移值为1,偏移字段为id,无偏移默认值为空('')
若获取数据项偏移值(向上偏移) , lead(val1,val2,val3)>
SELECT id,type,name,price,lead(id,1,'') over(partition by type order by price asc) as downid from products;
SQL 语句输出 >
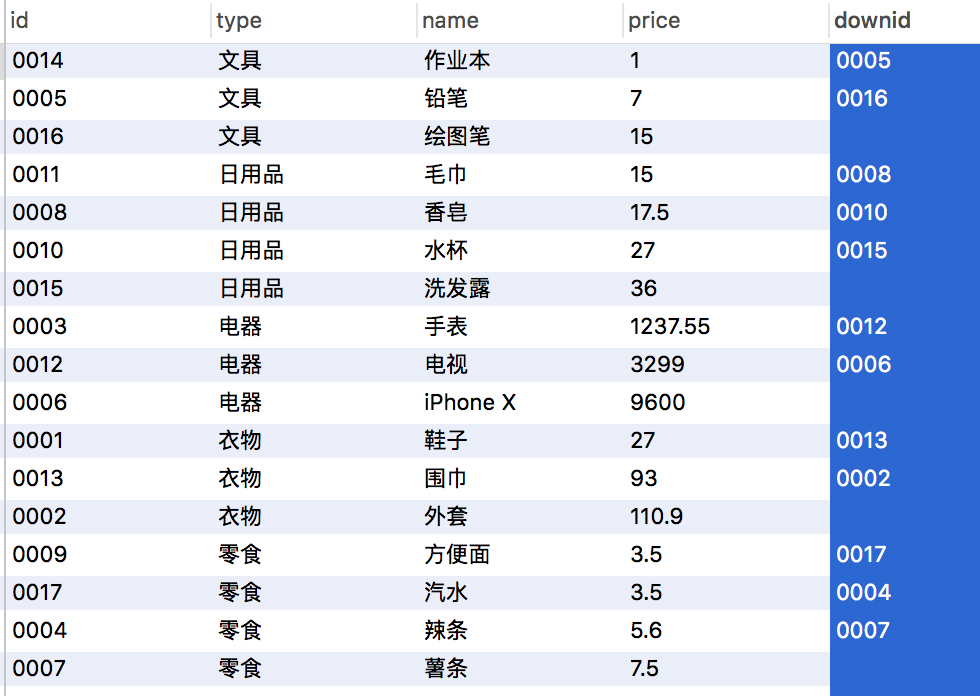
当然,窗口函数还可以实现每个子类排序中的第一项的某个字段的值,可以这样实现:
获取分类子项排序中的第一条记录的某个字段的值, first_value(val1) 实现>
SELECT id,type,name,price,first_value(name) over(partition by type order by price asc) from products;
SQL语句输出>
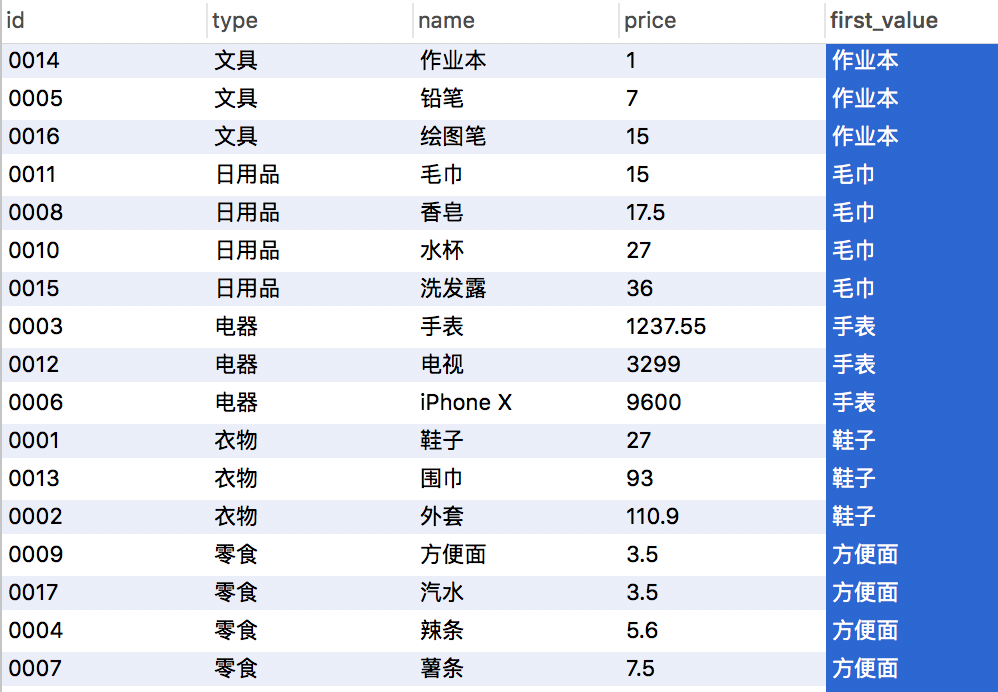
注意:以上函数取的是排序子类记录中的第一条记录的name字段。
当然也可以向下取分类排序中的最后一条记录的某个字段, last_value(val1)实现>
SELECT id,type,name,price,last_value(name) over(partition by type order by price range between unbounded preceding and unbounded following) from products; -- order by type asc ;-- ,price asc;
SQL 语句输出 >
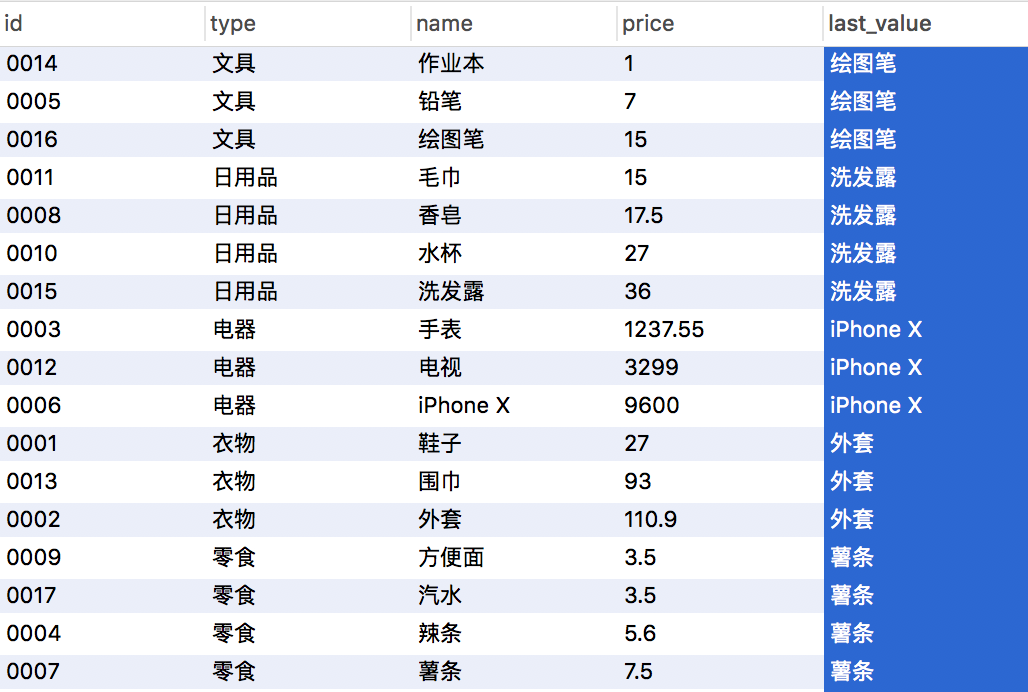
额,这里需要说明的是,当取分类在最后一条记录的时候 自然排序下不可以在over() 使用排序字段,不然取得的值为相对于当前记录的值,故这里按价格(price) 升序的时候指定 排序字段 -> range between unbounded preceding and unbounded following
窗口函数还能在分类排序下取得指定序号记录的某个字段,这样:
取得排序字段项目中指定序号记录的某个字段值, nth_value(val1,val2)>
SELECT id,type,name,price,nth_value(name,2) OVER(partition by type order by price range between unbounded preceding and unbounded following ) from products;
SQL语句输出 >
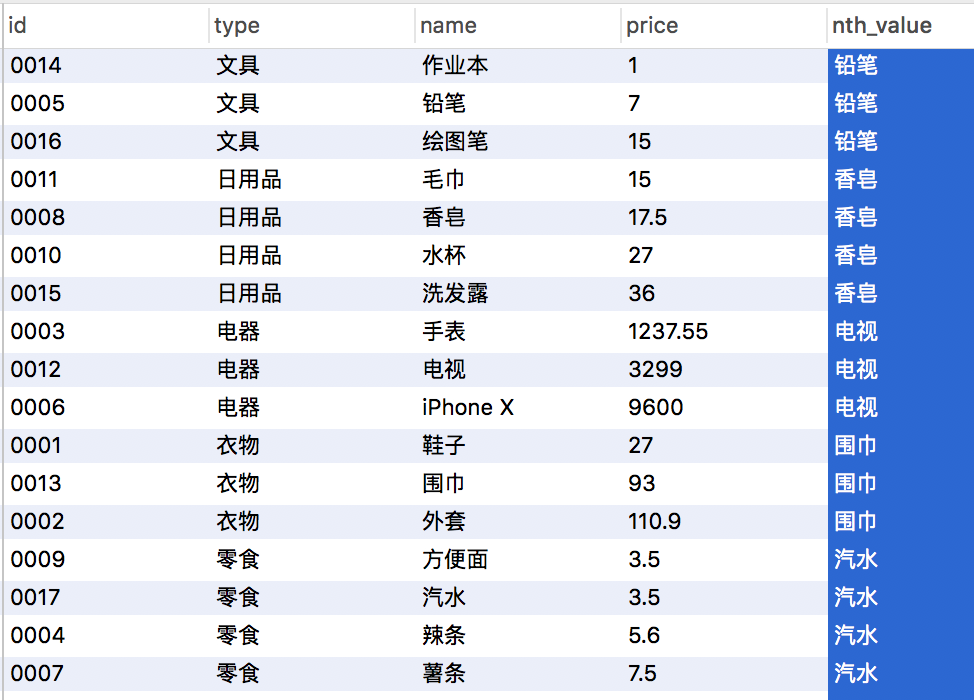
额,窗口函数在单独使用的时候能省略很多不必要的查询 ,比如子查询、聚合查询,当然窗口函数能做得更多(配合聚合函数使用的时候) ,额,这里我给出一个示例 >
SQL查询语句 ,窗口函数+聚合函数 实现 >
sum(price) over (partition by type) 类别金额合计,
(sum(price) over (order by type))/sum(price) over() 类别总额占所有品类商品百分比,
round(price/(sum(price) over (partition by type rows between unbounded preceding and unbounded following)),3) 子除类别百分比,
rank() over (partition by type order by price desc) 排名,
sum(price) over() 金额总计
from products ORDER BY type,price asc;
SQL 语句输出>
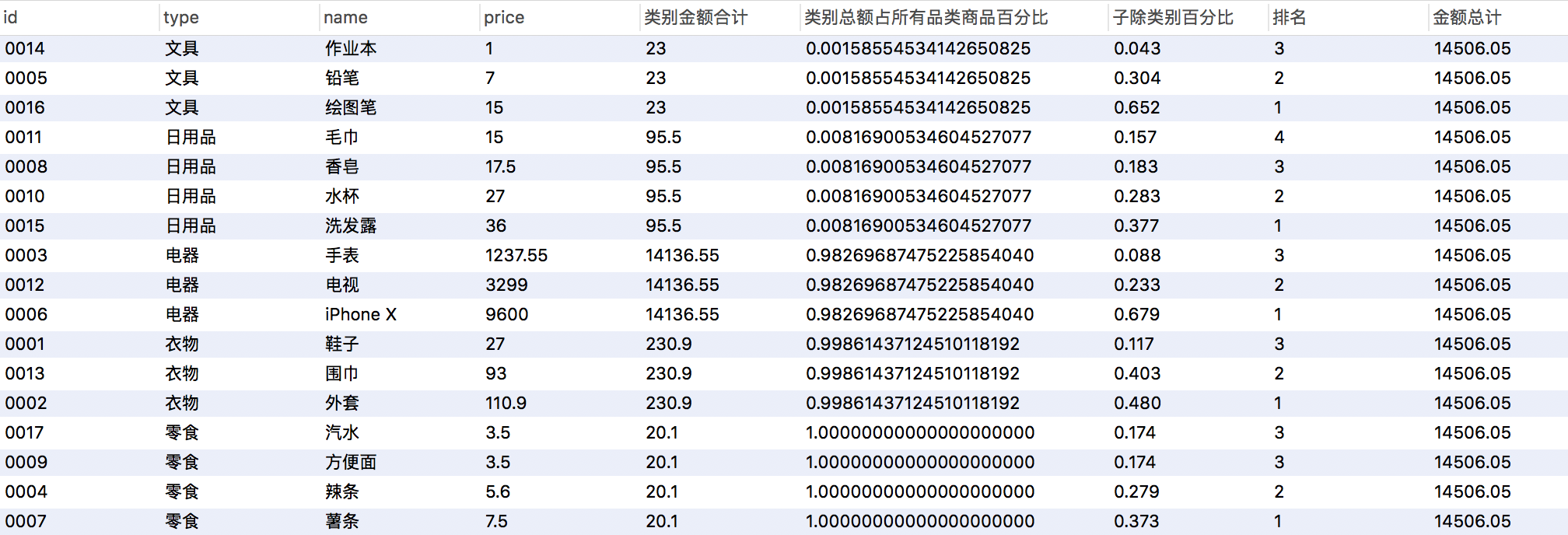
上面的语句看起来会有点儿晕,查询语句子项就像是在输出参数项里面直接写子查询的感觉,事实上为使语句有更好的可读性,窗口条件可以放在from后面 ,这样子>
select
id,type,name,price,
sum(price) over w1 类别金额合计,
(sum(price) over (order by type))/sum(price) over() 类别总额占所有品类商品百分比,
round(price/(sum(price) over w2),3) 子除类别百分比,
rank() over w3 排名,
sum(price) over() 金额总计
from
products
WINDOW
w1 as (partition by type),
w2 as (partition by type rows between unbounded preceding and unbounded following),
w3 as (partition by type order by price desc)
ORDER BY
type,price asc;
现在是 2018-07-22 21:59:31 ,各位晚安~
PostgreSQL>窗口函数的用法的更多相关文章
- PostgreSQL 窗口函数 ( Window Functions ) 如何使用?
一.为什么要有窗口函数 我们直接用例子来说明,这里有一张学生考试成绩表testScore: 现在有个需求,需要查询的时候多出一列subject_avg_score,为此科目所有人的平均成绩,好跟每个人 ...
- postgresql之distinct用法
1. 去重:关键字distinct去重功能 在其他数据库(oracle,mysql)是存在:当然postgresql也有这个功能 [postgres@sdserver40_210 ~]$ psql ...
- PostgreSQL窗口函数(转)
转自:http://time-track.cn/postgresql-window-function.html PostgreSQL提供了窗口函数的特性.窗口函数也是计算一些行集合(多个行组成的集合, ...
- PostgreSQL窗口函数
窗口函数允许在查询的SELECT列表和ORDER BY子句中使用. 如果有排序,要保证唯一,否则会有下面的错误: 修改方式是:保证唯一,修改方法如下:
- postgresql 窗口函数排序实例
经常遇到一种应用场景,将部分行的内容进行汇总.比较.排序. 比如数据表名称test.test2 select num,province from test.test2 得到结果: ;"黑龙江 ...
- PostgreSQL 中日期类型转换与变量使用及相关问题
PostgreSQL中日期类型与字符串类型的转换方法 示例如下: postgres=# select current_date; date ------------ 2015-08-31 (1 row ...
- 德哥PostgreSQL学习资料汇总(转)
文章来自:https://yq.aliyun.com/articles/59251?spm=5176.100239.bloglist.95.5S5P9S 德哥博客新地址:https://billtia ...
- psql -- PostgreSQL 交互终端
psql -- PostgreSQL 交互终端 用法:psql [option...] [dbname [username]] 描述:psql 是一个以终端为基础的 PostgreSQL 前端.它允 ...
- PostgreSQL的查询技巧: 零除, GENERATED STORED, COUNT DISTINCT, JOIN和数组LIKE
零除的处理 用NULLIF(col, 0)可以避免复杂的WHEN...CASE判断, 例如 ROUND(COUNT(view_50.amount_in)::NUMERIC / NULLIF(COUNT ...
随机推荐
- uCos-II中任务的同步与通信
任务的同步与通信 任务间的同步 在多任务合作工作过程中,操作系统要解决两个问题: 各任务间应该具有一种互斥关系,即对某些共享资源,如果一个任务正在使用,则其他任务只能等待,等到该任务释放资源后,等待任 ...
- ASP.NET Web API 2 OData v4教程
程序数据库格式标准化的开源数据协议 为了增强各种网页应用程序之间的数据兼容性,微软公司启动了一项旨在推广网页程序数据库格式标准化的开源数据协议(OData)计划,于此同时,他们还发 布了一款适用于OD ...
- 剑指Offer-翻转单词顺序列
题目描述 牛客最近来了一个新员工Fish,每天早晨总是会拿着一本英文杂志,写些句子在本子上.同事Cat对Fish写的内容颇感兴趣,有一天他向Fish借来翻看,但却读不懂它的意思.例如,"st ...
- C# - 学习总目录
C# - 基础 C# - 操作符 C# - 值类型和引用类型 C# - 表达式与语句 C# - 数组 C# - 引用类型 C# - 常用类 C# - 常用接口 C# - LINQ 语言集成查询 C# ...
- Unsafe 的简单使用
Unsafe 简介 Unsafe 是sun.misc包中的一个类,可以通过内存偏移量操作类变量/成员变量 Unsafe 用途 AQS(AbstractQueuedSynchronizer) 常用作实现 ...
- day13 闭包及装饰器
""" 今日内容: 1.函数的嵌套定义及必包 2.global 与 nonlocal 关键字 3.开放封闭原则及装饰器 """ " ...
- day04 流程控制
在python中流程控制主要有三种:顺序流程.分支流程.循环流程 1.顺序流程:在宏观上,python程序的运行就是自上而下的顺序流程: 2.分支流程:分支流程主要是 if...else....流程 ...
- VS2013创建ASP.NET应用程序描述
你的 ASP.NET 应用程序 恭喜! 你已创建了一个项目 此应用程序包含: 显示“主页”.“关于”和“联系方式”之间的基本导航的示例页 使用 Bootstrap 进行主题定位 身份验证,如果选择此项 ...
- SpringSecurity的配置分析
在分析SpringSecurity前,基于多年前使用SpringSecurity和近年来使用Shiro的经验, SpringSecurity这些年在发展和SpringBoot整合之后,也逃不出以下的一 ...
- pwnable.tw start&orw
emm,之前一直想做tw的pwnable苦于没有小飞机(,今天做了一下发现都是比较硬核的pwn题目,对于我这种刚入门?的菜鸡来说可能难度刚好(orz 1.start 比较简单的一个栈溢出,给出一个li ...