获取搜索结果的真实URL、描述、标题
1、场景
爬虫练手代码
2、代码
Python2:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
def getfromBaidu(word):
list=[]
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
}
baiduurl = 'http://www.baidu.com'
url = 'http://www.baidu.com.cn/s?wd=' + word + '&cl=3'
html = requests.get(url=url,headers=headers)
path = etree.HTML(html.content)
#用k来控制爬取的页码范围
for k in range(1, 20):
# 取出内容
path = etree.HTML(requests.get(url, headers).content)
flag = 11
if k == 1:
flag = 10
for i in range(1, flag):
# 获取标题
sentence = ""
for j in path.xpath('//*[@id="%d"]/h3/a//text()'%((k-1)*10+i)):
sentence+=j
print sentence # 打印标题
# 获取真实URL
try:
url_href = path.xpath('//*[@id="%d"]/h3/a/@href'%((k-1)*10+i))
url_href = ''.join(url_href)
baidu_url = requests.get(url=url_href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] # 得到网页原始地址
print real_url # 打印URL
except:
print "error",sentence,url_href
# 获取描述
res_abstract = path.xpath('//*[@id="%d"]/div[@class="c-abstract"]'%((k-1)*10+i))
if res_abstract:
abstract = res_abstract[0].xpath('string(.)')
else:
res_abstract = path.xpath('//*[@id="%d"]/div/div[2]/div[@class="c-abstract"]' % ((k - 1) * 10 + i))
if res_abstract:
abstract = res_abstract[0].xpath('string(.)')
print abstract # 打印描述
url = baiduurl+path.xpath('//*[@id="page"]/a[%d]/@href'%flag)[0]
return
#主程序测试函数
if __name__ == '__main__':
print getfromBaidu('上网')
3、效果
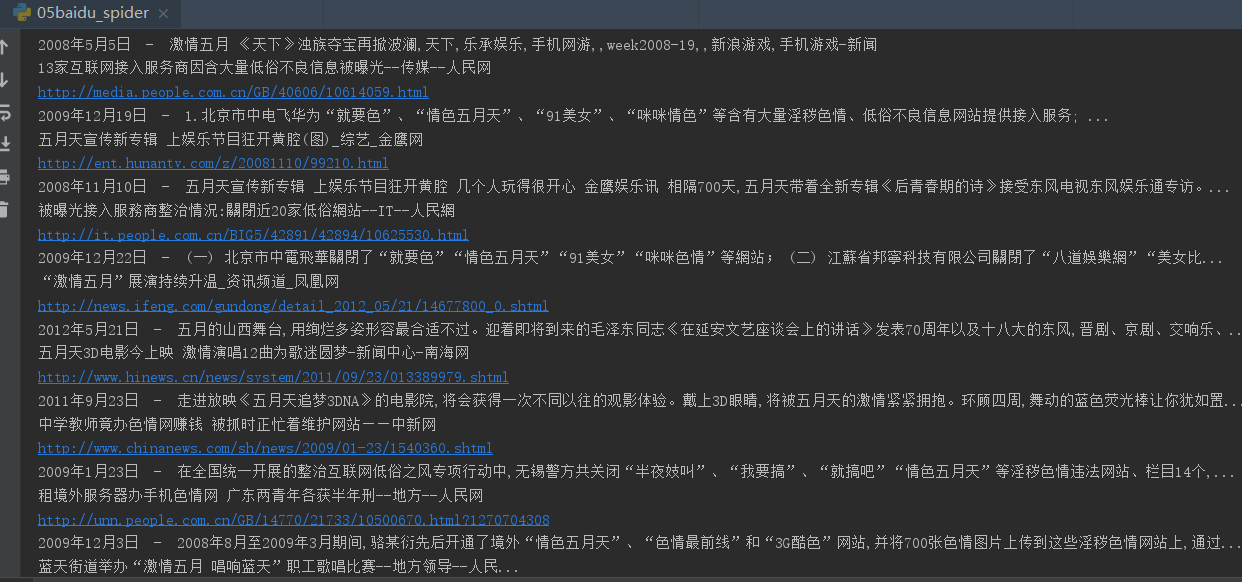
获取搜索结果的真实URL、描述、标题的更多相关文章
- 获取百度搜索结果的真实url以及摘要和时间
利用requests库和bs4实现,demo如下: #coding:utf- import requests from bs4 import BeautifulSoup import bs4 impo ...
- songtaste网站歌曲真实URL获取
个人挺喜欢songtaste网站的歌曲的,下载方法也层出不穷,可是作为程序员如果不知其中原理的方法真是羞愧.首先简单点的方法当然有google插件这样的嗅探器了,不过这种工具的原理还不是很了解.今天先 ...
- Java 获取网络重定向文件的真实URL
其实Java 使用HttpURLConnection下载的的时候,会自动下载重定向后的文件,但是我们无法获知目标文件的真实文件名,文件类型,用下面的方法可以得到真实的URL,下面是一个YOUKU视频的 ...
- 多级反向代理下,Java获取请求客户端的真实IP地址多中方法整合
在JSP里,获取客户端的IP地址的方法是:request.getRemoteAddr(),这种方法在大部分情况下都是有效的.但是在通过了Apache,Squid等反向代理软件就不能获取到客户端的真实I ...
- spring中获取当前项目的真实路径
总结: 方法1: WebApplicationContext webApplicationContext = ContextLoader.getCurrentWebApplicationContext ...
- Java获取请求客户端的真实IP地址
整理网友的材料,最后有源码,亲测能解决所有java获取IP真实地址的问题 整理的这里: 1.链接1 2.链接2 JSP里,获取客户端的IP地址的方法是: request.getRemoteAddr() ...
- 使用CDN后配置nginx自定义日志获取访问用户的真实IP
问题描述: 新上线了一个项目,架构如下(简单画的理解就好): 问题是:负载前面加上CDN后负载这里无法获取客户的真实访问IP,只能过去到CDN的IP地址: 问题解决: 修改nginx日 ...
- 用Head方法获得百度搜索结果的真实地址
用Head方法获得百度搜索结果的真实地址 在百度中搜索"Java",第一条结果的链接为: https://www.baidu.com/link?url=HBOOMbhPKH4SfI ...
- 获取HTML中所有图片的 URL
/// <summary> /// 获取HTML中所有图片的 URL /// </summary> /// <param name="strHtml" ...
随机推荐
- 【Windows】+ win10 通过KMS激活
win10激活到期 通过KMS再次激活(亲测有效):http://www.xitongcheng.com/jiaocheng/win10_article_44435.html
- future builder
import 'package:flutter/material.dart';import 'dart:convert';import 'package:http/http.dart' as http ...
- TPYBoard开发板搭建,实现隐秘通信
一.准备工作 lTPYBoard v102(简称v102) 1块 lTPYBoard v202(简称v202) 1块 l杜邦线.MicroUSB数据线 若干 (成本100元以内,某宝上可以买到) 附上 ...
- Math的一些方法
Math.abs(数值) 把()内的值变为正数 Math.ceil(4.3) 向上取整 // 5 Math.floor(4.3) 向下取整 // 4 Math.round(4.3) 四舍五入取整 // ...
- redis--小白博客
概述 redis是一种nosql数据库,他的数据是保存在内存中,同时redis可以定时把内存数据同步到磁盘,即可以将数据持久化,并且他比memcached支持更多的数据结构(string,list列表 ...
- IPv6绝不仅仅是对IPv4地址长度的增加
众所周知,IPv6 IP地址长度是IPv4 IP地址长度的四倍,是解决IPv4公共网址资源枯竭的最佳技术.的确,IETF在制定IPv6标准时也是基于这一因素考虑的.当时正是90年代初,Web开始出现, ...
- NOIP2000提高组复赛C 单词接龙
题目链接:https://ac.nowcoder.com/acm/contest/248/C 题目大意: 略 分析: 注意点:1.前缀和后缀的公共部分应该选最短的.2.如果两个字符串前缀和后缀的公共部 ...
- python之路4-文件操作
对文件操作流程 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 f = open('lyrics','r',encoding='utf-8') read_line = f.r ...
- 修改Linux的编码集
使用SSH secure远程连接linux时,查看linux里的内容, 发现乱码.这是由于SSH secure客户端的编码是gbk ,而 linux的默认编码是utf-8 要解决乱码问题,必须将lin ...
- POJChallengeRound2 Guideposts 【单位根反演】【快速幂】
题目分析: 这题的目标是求$$ \sum_{i \in [0,n),k \mid i} \binom{n}{i}G^i $$ 这个形式很像单位根反演. 单位根反演一般用于求:$ \sum_{i \in ...