redis--小白博客
概述
redis是一种nosql数据库,他的数据是保存在内存中,同时redis可以定时把内存数据同步到磁盘,即可以将数据持久化,并且他比memcached支持更多的数据结构(string,list列表[队列和栈],set[集合],sorted set[有序集合],hash(hash表))。相关参考文档:http://redisdoc.com/index.html
redis使用场景:(数据不太重要,实时更新)
- 登录会话存储:存储在
redis中,与memcached相比,数据不会丢失。 - 排行版/计数器:比如一些秀场类的项目,经常会有一些前多少名的主播排名。还有一些文章阅读量的技术,或者新浪微博的点赞数等。
- 作为消息队列:比如
celery就是使用redis作为中间人。 - 当前在线人数:还是之前的秀场例子,会显示当前系统有多少在线人数。
- 一些常用的数据缓存:比如我们的
BBS论坛,板块不会经常变化的,但是每次访问首页都要从mysql中获取,可以在redis中缓存起来,不用每次请求数据库。 - 把前200篇文章缓存或者评论缓存:一般用户浏览网站,只会浏览前面一部分文章或者评论,那么可以把前面200篇文章和对应的评论缓存起来。用户访问超过的,就访问数据库,并且以后文章超过200篇,则把之前的文章删除。
- 好友关系:微博的好友关系使用
redis实现。 - 发布和订阅功能:可以用来做聊天软件。
redis和memcached的比较:
| memcached | redis | |
|---|---|---|
| 类型 | 纯内存数据库 | 内存磁盘同步数据库 |
| 数据类型 | 在定义value时就要固定数据类型 | 不需要 |
| 虚拟内存 | 不支持 | 支持 |
| 过期策略 | 支持 | 支持 |
| 存储数据安全 | 不支持 | 可以将数据同步到dump.db中 |
| 灾难恢复 | 不支持 | 可以将磁盘中的数据恢复到内存中 |
| 分布式 | 支持 | 主从同步 |
| 订阅与发布 | 不支持 | 支持 |
redis日常操作
1.安装:centos7

wget http://download.redis.io/releases/redis-5.0.0.tar.gz
tar -zxvf redis-5.0.0.tar.gz
yum install gcc
yum install gcc-c++
make
cp src/redis-server /usr/bin/
cp src/redis-cli /usr/bin/
2.启动redis数据库服务
service redis start
3.停止redis数据库服务
service redis stop
4.连接上redis-server:
redis-cli -p 6379 -h 127.0.0.1
5.添加:
set key value
如:
set username balabala
将字符串值value关联到key。如果key已经持有其他值,set命令就覆写旧值,无视其类型。并且默认的过期时间是永久,即永远不会过期。
6.删除:
del key
如:
del username
7.设置过期时间
expire key timeout(单位为秒)
也可以在设置值的时候,一同指定过期时间: set key value EX timeout
或:
setex key timeout value
8.查看过期时间
ttl key
如:
ttl username
9.查看当前redis所有的key
keys *
10.列表操作
在列表左边添加元素:
lpush key value
将值value插入到列表key的表头。如果key不存在,一个空列表会被创建并执行lpush操作。当key存在但不是列表类型时,将返回一个错误。 在列表右边添加元素:
rpush key value
将值value插入到列表key的表尾。如果key不存在,一个空列表会被创建并执行RPUSH操作。当key存在但不是列表类型时,返回一个错误。
查看列表中的元素:
lrange key start stop
返回列表key中指定区间内的元素,区间以偏移量start和stop指定,如果要左边的第一个到最后的一个lrange key 0 -1。 移除列表中的元素: 移除并返回列表key的头元素:
lpop key 移除并返回列表的尾元素:
rpop key
指定返回第几个元素:
lindex key index
将返回key这个列表中,索引为index的这个元素。 获取列表中的元素个数:
llen key
如:
llen languages 删除指定的元素:
lrem key count value
如:
lrem languages 0 php
根据参数 count 的值,移除列表中与参数 value 相等的元素。count的值可以是以下几种: count > 0:从表头开始向表尾搜索,移除与value相等的元素,数量为count。
count < 0:从表尾开始向表头搜索,移除与 value相等的元素,数量为count的绝对值。
count = 0:移除表中所有与value 相等的值。
11.set集合的操作:
添加元素:
sadd set value1 value2....
如:
sadd team xiaotuo datuo
查看元素:
smembeers set
如:
smembers team
移除元素:
srem set member...
如:
srem team xiaotuo datuo
查看集合中的元素个数:
scard set
如:
scard team1
获取多个集合的交集:
sinter set1 set2
如:
sinter team1 team2
获取多个集合的并集:
sunion set1 set2
如:
sunion team1 team2
获取多个集合的差集:
sdiff set1 set2
如:
sdiff team1 team2
12.hash,哈希操作:
添加一个新值:
hset key field value
如:
hset website baidu baidu.com
将哈希表key中的域field的值设为value。
如果key不存在,一个新的哈希表被创建并进行 HSET操作。如果域 field已经存在于哈希表中,旧值将被覆盖。 获取哈希中的field对应的值:
hget key field
如:
hget website baidu 删除field中的某个field:
hdel key field
如:
hdel website baidu 获取某个哈希中所有的field和value:
hgetall key
如:
hgetall website 获取某个哈希中所有的field:
hkeys key
如:
hkeys website 获取某个哈希中所有的值:
hvals key
如:
hvals website 判断哈希中是否存在某个field:
hexists key field
如:
hexists website baidu 获取哈希中总共的键值对:
hlen field
如:
hlen website
12.事务操作:Redis事务可以一次执行多个命令,事务具有以下特征:
- 隔离操作:事务中的所有命令都会序列化、按顺序地执行,不会被其他命令打扰。
- 原子操作:事务中的命令要么全部被执行,要么全部都不执行。
开启一个事务:
multi
以后执行的所有命令,都在这个事务中执行的。
- 执行事务:
exec
会将在multi和exec中的操作一并提交。
- 取消事务:
discard
会将multi后的所有命令取消。
- 监视一个或者多个
key:
watch key...
监视一个(或多个)key,如果在事务执行之前这个(或这些) key被其他命令所改动,那么事务将被打断。
- 取消所有
key的监视:
unwatch
13.发布/订阅操作:
- 给某个频道发布消息:
publish channel message
- 订阅某个频道的消息:
subscribe channel
14.持久化
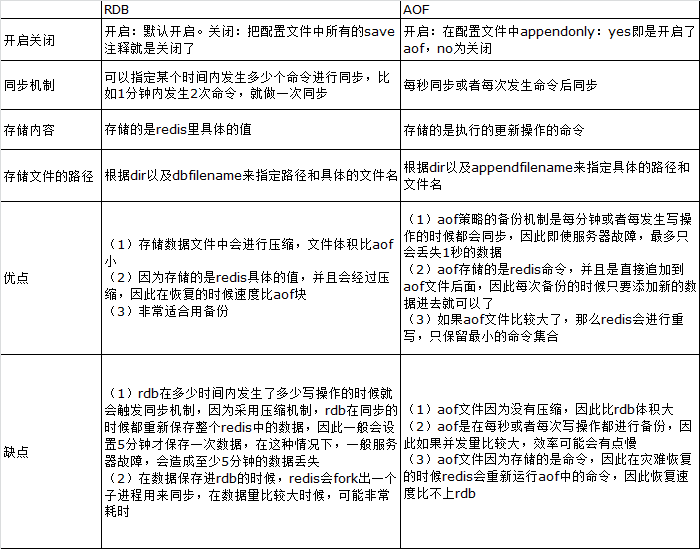
redis提供了两种数据备份方式,一种是RDB,另外一种是AOF,以下将详细介绍这两种备份策略:
Python 操作redis
安装
python-redis:pip install redis
新建一个文件比如
redis_test.py,然后初始化一个redis实例变量,并且在ubuntu虚拟机中开启redis。比如虚拟机的ip地址为192.168.174.130。示例代码如下:# 从redis包中导入Redis类
from redis import Redis
# 初始化redis实例变量
xtredis = Redis(host='192.168.174.130',port=6379)对字符串的操作:操作
redis的方法名称,跟之前使用redis-cli一样,现就一些常用的来做个简单介绍,示例代码如下(承接以上的代码):# 添加一个值进去,并且设置过期时间为60秒,如果不设置,则永远不会过期
xtredis.set('username','xiaotuo',ex=60)
# 获取一个值
xtredis.get('username')
# 删除一个值
xtredis.delete('username')对列表的操作:同字符串操作,所有方法的名称跟使用
redis-cli操作是一样的:# 给languages这个列表往左边添加一个python
xtredis.lpush('languages','python')
# 给languages这个列表往左边添加一个php
xtredis.lpush('languages','php')
# 给languages这个列表往左边添加一个javascript
xtredis.lpush('languages','javascript') # 获取languages这个列表中的所有值
print xtredis.lrange('languages',0,-1)
> ['javascript','php','python']对集合的操作:
# 给集合team添加一个元素xiaotuo
xtredis.sadd('team','xiaotuo')
# 给集合team添加一个元素datuo
xtredis.sadd('team','datuo')
# 给集合team添加一个元素slice
xtredis.sadd('team','slice') # 获取集合中的所有元素
xtredis.smembers('team')
> ['datuo','xiaotuo','slice'] # 无序的对哈希(
hash)的操作:# 给website这个哈希中添加baidu
xtredis.hset('website','baidu','baidu.com')
# 给website这个哈希中添加google
xtredis.hset('website','google','google.com') # 获取website这个哈希中的所有值
print xtredis.hgetall('website')
> {"baidu":"baidu.com","google":"google.com"}事务(管道)操作:
redis支持事务操作,也即一些操作只有统一完成,才能算完成。否则都执行失败,用python操作redis也是非常简单,示例代码如下:# 定义一个管道实例
pip = xtredis.pipeline()
pip = xtredis.pipeline()
pip.set('username', 'xiaomei')
pip.set('school', 'qinghua')
pip.execute()- 事务(管道)操作:
redis支持事务操作,也即一些操作只有统一完成,才能算完成。否则都执行失败,用python操作redis也是非常简单,示例代码如下:
#订阅
from redis import Redis
ps = xtredis.pubsub()
ps.subscribe('email')
while True:
for item in ps.listen():
if item['type'] == 'message':
data = item.get('data')
print(data.decode('utf-8')) #发布
from redis import Redis
xtredis = Redis(host='192.168.254.41', port=6379)
xtredis.publish('email', 'xxx@qq.com')
以上便展示了python-redis的一些常用方法,如果想深入了解其他的方法,可以参考python-redis的源代码(查看源代码pycharm快捷键提示:把鼠标光标放在import Redis的Redis上,然后按ctrl+b即可进入)。
redis搭建主从
1.拷贝一份redis配置文件为slave-6380.conf
cp redis.conf slave.conf
2.编辑slave-6380.conf文件
vim slave-6380.conf bind 192.168.254.41
slaveof 192.168.254.41 6379
port 6380
redis集群
redis集群
redis集群我这里部在2个机器上 第一台:192.168.254.41 第二台:192.168.254.45 每一台机器创建3个redis配置文件 第一台机器配置:
mkdir conf
touch 7000.conf 7001.conf 7002.conf
vim 7000.conf#编辑文件并且把如下内容拷贝进去
(剩下的7001.conf和7002.conf也是如此,把一下7000改成7001和7002即可) port 7000 #绑定端口
bind 192.168.254.41 #绑定对外连接提供的ip
daemonize yes #开启守护进程
pidfile 7000.pid #进程文件名
cluster-enabled yes #是否是集群
cluster-config-file 7000_node.conf #集群配置文件
cluster-node-timeout 15000 #集群连接超时时间
appendonly yes #数据持久化类型
第二台机器配置
mkdir conf
touch 7003.conf 7004.conf 7005.conf
vim 7000.conf#编辑文件并且把如下内容拷贝进去
(剩下的7004.conf和7005.conf也是如此,把一下7000改成7004和7005即可) port 7000 #绑定端口
bind 192.168.254.45 #绑定对外连接提供的ip
daemonize yes #开启守护进程
pidfile 7000.pid #进程文件名
cluster-enabled yes #是否是集群
cluster-config-file 7000_node.conf #集群配置文件
cluster-node-timeout 15000 #集群连接超时时间
appendonly yes #数据持久化类型
在两台机器上分别执行这3个配置文件
#192.168.254.41
redis-server 7000.conf
redis-server 7001.conf
redis-server 7002.conf #192.168.254.45
redis-server 7003.conf
redis-server 7004.conf
redis-server 7005.conf
redis需要的Ruby版本最低是2.2.2,但是CentOS7 yum库中ruby的版本支持到 2.0.0,可gem 安装redis需要最低是2.2.2,采用rvm来更新ruby: 安装RVM
1.curl -L get.rvm.io | bash -s stable 2.find / -name rvm -print(此时可能出现问题) 3.如果报错执行(4,5步) 4.curl -sSL https://rvm.io/mpapis.asc | gpg2 --import - 5.curl -sSL https://rvm.io/pkuczynski.asc | gpg2 --import - 6.出现如下内容代表成功
/usr/local/rvm
/usr/local/rvm/src/rvm
/usr/local/rvm/src/rvm/bin/rvm
/usr/local/rvm/src/rvm/lib/rvm
/usr/local/rvm/src/rvm/scripts/rvm
/usr/local/rvm/bin/rvm
/usr/local/rvm/lib/rvm
/usr/local/rvm/scripts/rvm
7.使刚安装的rvm立即生效
source /usr/local/rvm/scripts/rvm8.安装一个ruby版本
rvm install 2.4.1 9.使用一个ruby版本
rvm use 2.4.1 10.设置默认ruby版本 rvm use 2.4.1 --default 11.gem install redis
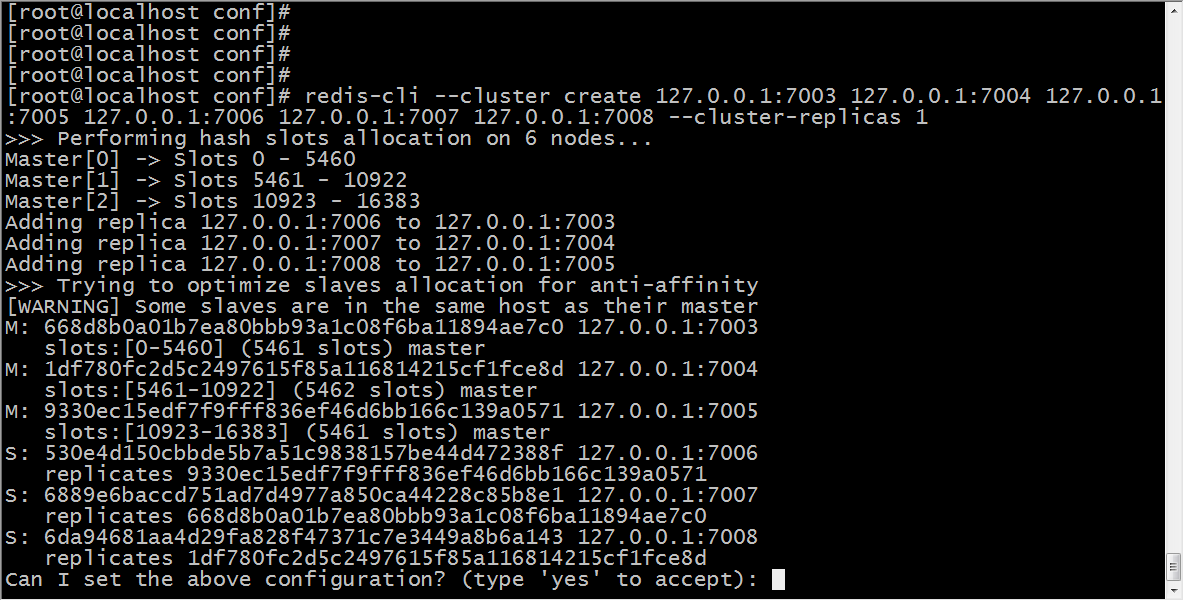
12.redis-cli --cluster create 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 127.0.0.1:7007 127.0.0.1:7008 --cluster-replicas 1
转载自:疯子7314
https://www.cnblogs.com/fengzi7314/
redis--小白博客的更多相关文章
- Mariadb第一章:介绍及安装--小白博客
mariadb(第一章) 数据库介绍 1.什么是数据库? 简单的说,数据库就是一个存放数据的仓库,这个仓库是按照一定的数据结构(数据结构是指数据的组织形式或数据之间的联系)来组织,存储的,我们可以 ...
- python之socket模块详解--小白博客
主要是创建一个服务端,在创建服务端的时候,主要步骤如下:创建socket对象socket——>绑定IP地址和端口bind——>监听listen——>得到请求accept——>接 ...
- MariaDB第四章:视图,事务,索引,外键--小白博客
视图 对于复杂的查询,在多个地方被使用,如果需求发生了改变,需要更改sql语句,则需要在多个地方进行修改,维护起来非常麻烦 假如因为某种需求,需要将user拆房表usera和表userb,该两张表的结 ...
- MariaDB第三章:数据库设计与备份--小白博客
数据库设计 1.第一范式(确保每列保持原子性) 第一范式是最基本的范式.如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式. 2.第二范式(确保表中的每列都和主键相关) 第 ...
- Ansible第二章:palybook介绍与使用--小白博客
playbook tasks variables templates handlers roles yaml介绍 yaml是一个可读性高的用来表达资料序列的格式,yaml参考了其他多种语言,包括:xm ...
- Ansible第一章:基础认识--小白博客
ansible Ansible:Ansible的核心程序Host Lnventory:记录了每一个由Ansible管理的主机信息,信息包括ssh端口,root帐号密码,ip地址等等.可以通过file来 ...
- python第九章:面向对象--小白博客
面向对象介绍 一.面向对象和面向过程 面向过程:核心过程二字,过程即解决问题的步骤,就是先干什么后干什么 基于该思想写程序就好比在这是一条流水线,是一种机械式的思维方式 优点:复杂的过程流程化 缺点 ...
- python之yagmail模块--小白博客
yagmail 实现发邮件 yagmail 可以简单的来实现自动发邮件功能. 安装 pip install yagmail 简单例子 import yagmail #链接邮箱服务器 yag = yag ...
- python之configparser模块详解--小白博客
configparse模块 一.ConfigParser简介 ConfigParser 是用来读取配置文件的包.配置文件的格式如下:中括号“[ ]”内包含的为section.section 下面为类似 ...
- python第八章:多任务--小白博客
多线程threading 多线程特点: #线程的并发是利用cpu上下文的切换(是并发,不是并行)#多线程执行的顺序是无序的#多线程共享全局变量#线程是继承在进程里的,没有进程就没有线程#GIL全局解释 ...
随机推荐
- 【Node.js】通过mongoose得到模型,不能新添字段的问题
问题描述 通过node.js为查询到的json对象添加新的字段,对象成功保存到数据库中,但新增字段却没保存. 前几天用vue+node.js+mongodb技术做一个购物车功能的网页,发现node.j ...
- 痞子衡嵌入式:ARM Cortex-M文件那些事(6)- 可执行文件(.out/.elf)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家讲的是嵌入式开发里的executable文件(elf). 第四.五节课里,痞子衡已经给大家介绍了2种output文件,本文继续给大家讲proje ...
- MySQL ProxySQL相关维护说明
背景: 前面的2篇文章MySQL ProxySQL读写分离使用初探和MySQL ProxySQL读写分离实践大致介绍了ProxySQL的使用说明,从文章的测试的例子中看到ProxySQL使用SQLIT ...
- 转换Word文档为PDF文件
1.使用 Office COM组件的Microsoft.Office.Interop.word.dll库 该方法需要在电脑上安装Office软件,并且需要Office支持转换为PDF格式,如果不支持, ...
- Kotlin 数组学习笔记
创建数组 初始值为空的String数组 val arrayEmpty = emptyArray<String>() 长度为5,初始值为空的Int数组 val arrayEmpty = em ...
- Java中float型最大值大于long型?
float型在内存中占用的是4个字节的空间,而long型占用的是8个字节的空间. 注:float类型的范围是:一3.403E38~3.403E38.而long类型的范围是:-2^63~2^63-1(大 ...
- python3.6 pip 出现locations that require TLS/SSL异常解决方案
在给CentOS服务器安装完Python3.6后,使用pip命令出现问题,提示说无法找到ssl模块. 上网查询后发现在安装Python3.6时没有安装openssl-devel依赖库,解决方案如下: ...
- C#设计模式之二十二备忘录模式(Memento Pattern)【行为型】
一.引言 今天我们开始讲“行为型”设计模式的第十个模式,该模式是[备忘录模式],英文名称是:Memento Pattern.按老规矩,先从名称上来看看这个模式,个人的最初理解就是对某个对象的状态进行保 ...
- Javascript继承3:将优点为我所有----组合式继承
//声明父类 function ParentClass(name){ //值类型公有属性 this.name = name //引用类型公有属性 this.books = ['Html'] } //父 ...
- java开发环境配置——JDK
虽然网上有很多类似的文章了,第一次搭的时候也是看的网上的文章,但为了做个记录,自己也写一下,记录一下. 首先是先安装JDK,JDK下载可以直接去官网下载,地址:http://www.oracle.co ...