ELK系列五:Logstash输出到Elasticsearch和redis
1、Logstash与Redis的读写
1.1 Logstash 写入Redis
看完Logstash的输入,想必大家都清楚了Logstash的基本用法,那就是写配置文件。
output{
{
redis {
host => ["127.0.0.1:6379"] #这个是标明redis服务的地址
port => 6379
codec => plain
db => 0 #redis中的数据库,select的对象
key => #redis中的键值
data_type => list #一般就是list和channel
password => 123456
timeout => 5
workers => 1
}
}
}
其他配置选项
reconnect_interval => 1 #重连时间间隔
batch => true #通过发送一条rpush命令,存储一批的数据,默认为false,也就是1条rpush命令,存储1条数据。配置为true会根据一下两条规则缓存,满足其中之一时push。
batch_events => 50 #默认50条
batch_timeout => 5 #默认5s
# 拥塞保护(仅用于data_type为list)
congestion_interval => 1#每多长时间进行一次拥塞检查,默认1s,如果设为0,则表示对每rpush一个,都进行检测。
congestion_threshold => 0 #默认是0:表示禁用拥塞检测,当list中的数据量达到congestion_threshold,会阻塞直到有其他消费者消费list中的数据


1.2 补充,从redis中获取数据到Logstash
input {
redis {
codec => plain
host => "127.0.0.1"
port => 6379
data_type => list
key => "input"
db => 1
}
}
output{
redis{
codec => plain
host => ["127.0.0.1:6379"]
data_type => list
key => logstash
}
}

2、Logstash 写入Elasticsearch
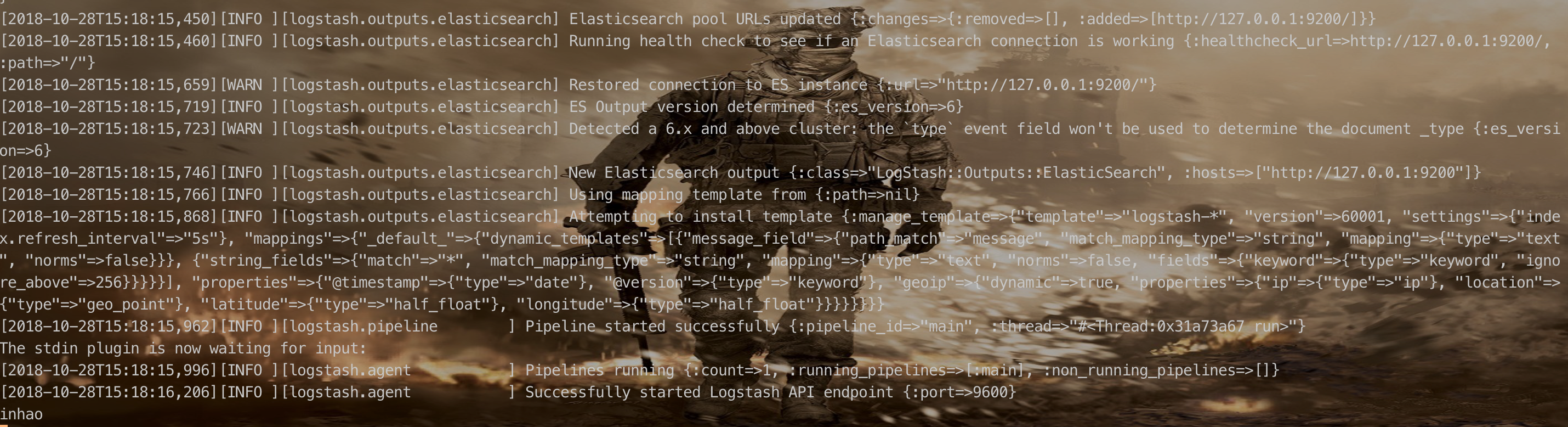
output{
elasticsearch {
hosts => ["http://127.0.0.1:9200"]
index => "ids-1"
document_type => warnning
}
}
其他配置项
output {
elasticsearch {
hosts => ["127.0.0.1:9200"] #elasticsearch的索引
action => index #有几个动作,index,create,create、update
cacert => /xxx #验证证书合法性
codec => plain
doc_as_upsert => false
document_id => 1 #id号
document_type => xxx #文档类型
flush_size => 500 #满500刷磁盘
idle_flush_time => 1 #满1s刷自盘
index => logstash-%{+YYYY.MM.dd} #索引名字
keystore => /xxx
keystore_password => xxx
manage_template => true
max_retries => 3 #失败重连次数
password => xxx
path => /
proxy => xxx
retry_max_interval => 2
sniffing => false
sniffing_delay => 5
ssl => false
ssl_certificate_verification => true
template => /xxx
template_name => logstash
template_overwrite => false
timeout => 5 #超时
user => xxx
workers => 1
}
}
ELK系列五:Logstash输出到Elasticsearch和redis的更多相关文章
- logstash输出到elasticsearch多索引
目标:将json格式的两类日志输出到elasticsearch两类索引 1. 安装logstash. 2. 编写logstash处理配置文件,创建一个test.conf文件,内容如下: input { ...
- ELK系列(5) - Logstash怎么分割字符串并添加新的字段到Elasticsearch
问题 有时候我们想要在Logstash里对收集到的日志等信息进行分割,并且将分割后的字符作为新的字符来index到Elasticsearch里.假定需求如下: Logstash收集到的日志字段mess ...
- logstash输出至elasticsearch
续上一篇 上一篇描述了通过logback配置用logstash收集springmvc项目日志,本文是描述如何进一步通过elasticsearch对所收集数据进行的分析. output { elasti ...
- ElasticSearch——Logstash输出到Elasticsearch配置
位置 在Logstash的.conf配置文件中的output中配置ElasticSearch 示例: output { elasticsearch{ action => "index& ...
- logstash 输出到elasticsearch 自动建立index
由于es 单index 所能承受的数据量有限,之前情况是到400w数据300G左右的时候,整个数据的插入会变得特别慢(索引重建)甚至会导致集群之间的通信断开,于是我们采用每天一个index的方法来缓解 ...
- hive 学习系列五(hive 和elasticsearch 的交互,很详细哦,我又来吹liubi了)
hive 操作elasticsearch 一,从hive 表格向elasticsearch 导入数据 1,首先,创建elasticsearch 索引,索引如下 curl -XPUT '10.81.17 ...
- Logstash之Logstash inputs(file和redis插件)、Logstash outputs(elasticsearch 和redis插件)和Filter plugins
前期博客 Logstash安装和设置(图文详解)(多节点的ELK集群安装在一个节点就好) Filebeat啊,根据input来监控数据,根据output来使用数据!!! 请移步, Filebeat之 ...
- ELK系列(1) - Elasticsearch + Logstash + Kibana + Log4j2快速入门与搭建用例
前言 最近公司分了个ELK相关的任务给我,在一边学习一边工作之余,总结下这些天来的学习历程和踩坑记录. 首先介绍下使用ELK的项目背景:在项目的数据库里有个表用来存储消息队列的消费日志,这些日志用于开 ...
- ElasticSearch实战系列六: Logstash快速入门和实战
前言 本文主要介绍的是ELK日志系统中的Logstash快速入门和实战 ELK介绍 ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是 ...
随机推荐
- Windows 环境搭建Redis集群(win 64位)
转: http://blog.csdn.net/zsg88/article/details/73715947 参考:https://www.cnblogs.com/tommy-huang/p/6240 ...
- java中获取文件目录
1. web项目得到部署的目录路径(最后包含"/"或"\"): xxx(HttpServletRequest request) { String strDirP ...
- gtest运行小析
Gtest是google推出的C++测试框架,本篇文档,从整体上对Gtest的运行过程中的关键路径进行分析和梳理. 分析入口 新建一个最简单的测试工程,取名为source_analyse_proj,建 ...
- 关于High-Contrast的资料
SystemParameters.HighContrast Propertyhttp://msdn.microsoft.com/en-us/library/system.windows.systemp ...
- Android开发学习笔记-SharedPreferences的用法
SharedPreferences介绍: 做软件开发应该都知道,很多软件会有配置文件,里面存放这程序运行当中的各个属性值,由于其配置信息并不多,如果采用数据库来存放并不划算,因为数据库连接跟操作等 ...
- java程序员如何编写更好的单元测试的7个技巧
详解 cppunit进行单元测试 单元测试(模块测试)是开发者编写的一小段代码,用于检验被测代码的一个很小的.很明确的功能是否正确.通常而言,一个单元测试是用于判断某个特定条件(或者场景)下某个特定函 ...
- Apache性能优化总结
1.介绍 首先要了解Apache采用的MPM(Multi -Processing Modules,多道处理模块),MPM是Apache的核心,它的作用是管理网络连接.调度请求.Apache2.0中MP ...
- 大杂烩 -- Iterator 和 Iterable 区别和联系
基础大杂烩 -- 目录 用Iterator模式实现遍历集合 Iterator模式是用于遍历集合类的标准访问方法.它可以把访问逻辑从不同类型的集合类中抽象出来,从而避免向客户端暴露集合的内部结构. 例 ...
- 使用 requests 配置代理服务
(1) 如果我们一直用同一个IP去请求同一个网站上的网页,久了之后可能会被该网站服务器屏蔽,因此我们可以使用代理IP来发起请求,代理实际上指的就是代理服务器(2) 当我们使用代理IP发起请求时,服务器 ...
- Apache Kafka 1.0.0正式发布!
千呼万唤始出来,经过7年的发展与完善,Apache Kafka 1.0.0正式发布!在笔者看来,比起1.0.0引入的新功能,此版本最大的意义在于标识Kafka各种组件功能的稳定性.不过我们还是来看下1 ...