隐马尔科夫模型(HMM)学习笔记二
这里接着学习笔记一中的问题2,说实话问题2中的Baum-Welch算法编程时矩阵转换有点烧脑,开始编写一直不对(编程还不熟练hh),后面在纸上仔细推了一遍,由特例慢慢改写才运行成功,所以代码里面好多处都有print。
笔记一中对于问题1(概率计算问题)采用了前向或后向算法,根据前向和后向算法可以得到一些后面要用到的概率与期望值。



一、问题2 学习问题 已知观测序列,估计模型参数,使得在该模型下观测序列概率最大
隐马尔可夫模型的学习,根据训练数据除包括观测序列O外是否包括了对应的状态序列 I 分为监督学习和非监督学习。如果包括了状态序列 I ,则可以直接采用极大似然估计来估计隐马尔可夫模型的初始状态概率Pi,状态转移概率A和观测概率B(一般统计频数)。但是一般没有对应的状态序列 I ,如果人工标注训练数据的话代价太高,所以大多时候采用非监督学习方法------Baum-Welch算法。
Baum-Welch算法
假设给定训练数据只包含S个长度为T的观测序列 而没有对应的状态序列,目标是学习隐马尔可夫模型
而没有对应的状态序列,目标是学习隐马尔可夫模型 的参数。我们将观测序列数据看作观测数据O,状态序列数据看作不可观测的隐数据I,那么隐马尔可夫模型事实上是一个含有隐变量的概率模型
的参数。我们将观测序列数据看作观测数据O,状态序列数据看作不可观测的隐数据I,那么隐马尔可夫模型事实上是一个含有隐变量的概率模型

它的参数学习可以由EM算法实现(EM算法可以参考博客,博主写得通俗易懂)。
1、确定完全数据的对数似然函数
所有观测数据写成 ,所有隐数据写成
,所有隐数据写成 ,完全数据是
,完全数据是 。完全数据的对数似然函数是
。完全数据的对数似然函数是 。
。
2、EM算法的E步:
求Q函数

其中, 是隐马尔可夫模型参数的当前估计值,
是隐马尔可夫模型参数的当前估计值, 是要极大化的隐马尔可夫模型参数。(Q函数的标准定义是:
是要极大化的隐马尔可夫模型参数。(Q函数的标准定义是: ,式子内部其实是条件概率,其中的
,式子内部其实是条件概率,其中的 对应
对应 ;其与
;其与 无关,所以省略掉了。)
无关,所以省略掉了。)

于是函数 可以写成:
可以写成:

式中求和都是对所有训练数据的序列总长度T进行的。这个式子是将代入后(取对数后变成加法,便于求解),将初始概率、转移概率、观测概率这三部分乘积的对数拆分为对数之和,所以有三项。
3、EM算法的M步:极大化Q函数求模型参数 ,由于要极大化的参数在Q函数表达式中单独地出现在3个项中,所以只需对各项分别极大化。
,由于要极大化的参数在Q函数表达式中单独地出现在3个项中,所以只需对各项分别极大化。
第1项可以写成:

注意到 满足约束条件利用拉格朗日乘子法,写出拉格朗日函数:
满足约束条件利用拉格朗日乘子法,写出拉格朗日函数:

对其求偏导数并令结果为0

得到

这个求导是很简单的,求和项中非i的项对πi求导都是0,logπ的导数是1/π,γ那边求导就剩下πi自己对自己求导,也就是γ。等式两边同时乘以πi就得到了上式。
对i求和得到γ:

代入中得到:

第2项可以写成:

类似第1项,应用具有约束条件 的拉格朗日乘子法可以求出
的拉格朗日乘子法可以求出

第3项为:

同样用拉格朗日乘子法,约束条件是 。注意,只有在对
。注意,只有在对 时
时 对
对 的偏导数才不为0,以
的偏导数才不为0,以 表示。求得
表示。求得

Baum-Welch模型参数估计公式
将这三个式子中的各概率分别简写如下:


则可将相应的公式写成:

这三个表达式就是Baum-Welch算法(Baum-Welch algorithm),它是EM算法在隐马尔可夫模型学习中的具体实现,由Baum和Welch提出。
算法 (Baum-Welch算法)
输入:观测数据
输出:隐马尔可夫模型参数。
(1)初始化。对 ,选取
,选取 ,得到模型
,得到模型 。
。
(2)递推。对


右端各值按观测和模型 计算。
计算。
(3)终止。得到模型参数 。
。
分析:先根据前向算法得出alpha,根据后向算法得到beta,之后再根据本文最开始的公式计算gamma和sigamma矩阵,这里注意gamma是N*N维的,而sigamma是T-1*N*N维的,最后执行Baum-Welch算法。代码里面有相应的注释,这里我也卡了好久,可以先自己到纸上推一下。
def Baum_Welch(pi, A, B, obs_seq, error=0.005):
switch = 0 # 判断是否停止迭代
if not switch:
N = A.shape[0] # 可能的状态个数
M = B.shape[1] # 可能的观测结果个数
T = len(obs_seq) # 观测序列长度
newB = np.zeros((N, M)) # 初始化观测概率
alpha = forward_compute(pi, A, B, obs_seq)[1] # 前向算法得到的alpha矩阵 N*T维
print('alpha:', alpha)
beta = backword_compute(pi, A, B, obs_seq)[1] # 后向算法得到的beta矩阵 N*T维
print('beta:', beta)
gamma = np.zeros((N, T)) # gamma_t_i 表示t时刻在状态q_i的概率 N*N维
sigamma = np.zeros((T-1, N, N)) # sigamma_t_i_j t时刻处于q_i,t+1时刻处于q_j的概率 (T-1)*N*N维 for t in range(T-1):
gamma[:, t] = (alpha[:, t]*beta[:, t]) / (alpha[:, t].dot(beta[:, t])) # 求出gamma矩阵
denom = np.dot(np.dot(alpha[:,t].T, A) * B[:,obs_seq[t+1]].T, beta[:,t+1]) # sigmma矩阵分母
for i in range(N):
molecule = alpha[i, t]* A[i,:] * B[:,obs_seq[t+1]]*beta[:,t+1] # 分子
sigamma[t,i,:] = molecule / denom # 求sigamma gamma[:, T-1] = (alpha[:, T-1]*beta[:, T-1]) / (alpha[:, T-1].dot(beta[:, T-1])) # 由于sigamma直到T-1,所以gamma最后要添加一列
print('gamma:', gamma)
print('sigamma:', sigamma)
# print('-----------')
# print(np.sum(sigamma, axis=0))
# print('*********')
# print(np.sum(gamma[:,:T-1], axis=1))
# print(np.sum(gamma[:,:T-1], axis=1).reshape(N, -1))
#更新
newA = np.sum(sigamma, axis=0)/(np.sum(gamma[:,:T-1], axis=1).reshape(N, -1))
# print(newA)
# print(obs_seq==0)
# print(np.sum(gamma, axis=1)
for m in range(M):
newB[:,m] = np.sum(gamma.T[obs_seq==m], axis=0)/(np.sum(gamma, axis=1))
# print(newB)
newpi = gamma[:, 0] # 检查是否满足要求
if np.max(abs(pi - newpi)) < error and np.max(abs(A - newA)) < error and np.max(abs(B - newB)) < error:
switch = 1
pi, A, B = newpi, newA, newB
return A, B, pi
之后带入相关数据进行测试。
A = np.array([[0.1, 0.3, 0.6],[0.3, 0.5, 0.2], [0.3, 0.5, 0.2]])
B = np.array([[0.5, 0.5],[0.5, 0.5], [0.5,0.5]])
pi = np.array([0.2, 0.4, 0.4]) observations_data = np.array([0, 1, 0, 0, 1]) newA, newB, newpi = Baum_Welch(pi, A, B, observations_data)
print("newA: ", newA)
print("newB: ", newB)
print("newpi: ", newpi)

二、问题3 预测问题 已知模型和观测序列,求给定序列最大概率下的状态
预测算法有两种:近似算法和维特比算法。
1.近似算法
基本思想:在每个时刻t选择在该时刻最有可能出现的状态 i*t ,从而得到一个状态序列 I* = (i*1, i*2, ..., i*T)。
对于给定隐马尔可夫模型和观测序列O,在 t 时刻处于状态 qi 的概率gamma(i) 为:
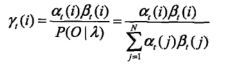
在每一时刻 t 最有可能的状态 i*t 为:

从而得到状态序列 I* = (i*1, i*2, ..., i*T)。
这个代码很简单,直接对gamma按行求最大值就行。
'''
gamma: [[0.2 0.26 0.248 0.2504 0.44992]
[0.4 0.46 0.448 0.2992 0.24992]
[0.4 0.28 0.304 0.4504 0.30016]]
'''
def envolution_state(gamma):
states = []
for i in range(gamma.shape[1]):
max_index = np.where(gamma==np.max(gamma[:,i]))[0][0]
states.append(max_index)
return states print('*********test*********')
gamma = np.array([[0.2 ,0.26,0.248,0.2504,0.44992], [0.4,0.46,0.448,0.2992,0.24992], [0.4,0.28,0.304,0.4504,0.30016]])
print('state:', envolution_state(gamma))
2、维特比算法
基本思想:利用动态规划求解隐马尔科夫模型预测问题,即用动态规划求解概率最大路径(最优路径),一条路径对应一个状态序列。
算法(维特比算法)
输入:模型 和观测
和观测 ;
;
输出:最优路径 。
。
⑴初始化

(2)递推。对

(3)终止

(4)最优路径回溯。对

求得最优路径。
def vetebi(pi, A, B, obs_seq):
N = A.shape[0] # 状态个数
T = len(obs_seq) # 观测序列长度 deta = np.zeros((N, T)) # 初始化deta矩阵
fia = np.zeros((N, T), dtype=int) # 初始化fia矩阵
path = np.zeros(T, dtype=int) # 初始化最优路径 deta[:, 0] = pi*B[:, obs_seq[0]] # 计算deta_1
for t in range(1, T):
matrix = (deta[:, t-1]*A.T)*B[:, obs_seq[t]].reshape(N, -1) # 计算乘法,deta按列取其中最大的
deta[:, t] = np.max(matrix, axis=1) # 给deta赋值
fia[:, t] = np.argmax(matrix, axis=1) # 给fia赋值,用于求最优路径
print(deta)
print(fia) # 最大概率
P_max = np.max(deta[:, T-1])
# print(P_max) # 求最优路径
path[T-1] = np.max(fia[:, T-1])
for t in range(T-2, -1, -1):
path[t] = fia[:, t+1][path[t+1]]
# print(path)
return path+1
利用书本上例题进行测试。
# test
A = np.array([[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]])
B = np.array([[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]])
pi = np.array([0.2, 0.4, 0.4])
obs_seq = np.array([0, 1, 0])
path = vetebi(pi, A, B, obs_seq)
print('the best path is :',path)

隐马尔科夫模型(HMM)学习笔记二的更多相关文章
- 隐马尔科夫模型HMM学习最佳范例
谷歌路过这个专门介绍HMM及其相关算法的主页:http://rrurl.cn/vAgKhh 里面图文并茂动感十足,写得通俗易懂,可以说是介绍HMM很好的范例了.一个名为52nlp的博主(google ...
- 用hmmlearn学习隐马尔科夫模型HMM
在之前的HMM系列中,我们对隐马尔科夫模型HMM的原理以及三个问题的求解方法做了总结.本文我们就从实践的角度用Python的hmmlearn库来学习HMM的使用.关于hmmlearn的更多资料在官方文 ...
- 隐马尔科夫模型(HMM)的概念
定义隐马尔科夫模型可以用一个三元组(π,A,B)来定义:π 表示初始状态概率的向量A =(aij)(隐藏状态的)转移矩阵 P(Xit|Xj(t-1)) t-1时刻是j而t时刻是i的概率B =(bij) ...
- 隐马尔科夫模型HMM(一)HMM模型
隐马尔科夫模型HMM(一)HMM模型基础 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比 ...
- 隐马尔科夫模型HMM
崔晓源 翻译 我们通常都习惯寻找一个事物在一段时间里的变化规律.在很多领域我们都希望找到这个规律,比如计算机中的指令顺序,句子中的词顺序和语音中的词顺序等等.一个最适用的例子就是天气的预测. 首先,本 ...
- 隐马尔科夫模型 HMM(Hidden Markov Model)
本科阶段学了三四遍的HMM,机器学习课,自然语言处理课,中文信息处理课:如今学研究生的自然语言处理,又碰见了这个老熟人: 虽多次碰到,但总觉得一知半解,对其了解不够全面,借着这次的机会,我想要直接搞定 ...
- 猪猪的机器学习笔记(十七)隐马尔科夫模型HMM
隐马尔科夫模型HMM 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十七次课在线笔记.隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来 ...
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态序列
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数 隐马尔科夫模型HMM(四)维特比算法解码隐藏状态 ...
随机推荐
- 虚拟机VMware怎么完全卸载干净,如何彻底卸载VMware虚拟机
亲测好使. 1.禁用VM虚拟机服务 首先,需要停止虚拟机VMware相关服务.按下快捷键WIN+R,打开windows运行对话框,输入[services.msc],点击确定.如下图. 在服务管理中,找 ...
- Unity3D笔记 GUI 一
要实现的功能: 1.个性化Windows界面 2.减少个性化的背景图片尺寸 3.个性化样式ExitButton和TabButton 4.实现三个选项卡窗口 一.个性化Windows界面 1.1.创建一 ...
- webp图片优化
根据对目前国内浏览器占比与 WebP 的兼容性分析,大约有 50% 以上的国内用户可以直接体验到 WebP,如果你的网站以图片为主,或者你的产品基于 Chromium 内核,建议体验尝试.假如你打算在 ...
- 使用disavled属性锁定input内容不可以修改后,打印获取不到对应的值
当我们需要锁定input内容不让修改时,可以使用disabled="disabled"和readonly="readonly", 官方的解释是:disabled ...
- Centos6.5安装mysql 5.7
1.在官网下载安装包:https://dev.mysql.com/downloads/mysql/5.7.html#downloads mysql-5.7.10-linux-glibc2.5-x86_ ...
- 转利用python实现电影推荐
“协同过滤”是推荐系统中的常用技术,按照分析维度的不同可实现“基于用户”和“基于产品”的推荐. 以下是利用python实现电影推荐的具体方法,其中数据集源于<集体编程智慧>一书,后续的编程 ...
- win10中强制vs2015使用管理员启动
文章转自: win10中强制vs2015使用管理员启动 首先,和网上流传的版本一样,需要做这下面这两步: 1. 打开VS快捷方式的属性对话框. 2.勾选“用管理员身份运行” 现在,你双击V ...
- Java 8新增的Lambda表达式
一. 表达式入门 Lambda表达式支持将代码块作为方法参数,lambda表达式允许使用更简洁的代码来创建只有一个抽象方法的接口(这种接口被称为函数式接口)的实例,相当于一个匿名的方法. 1.1 La ...
- 从UE(用户体验)到道家誓学再到李小龙
公司大Boss经常会给我做技术培训,感觉他什么都知道,也挺喜欢听他的课. 本文记录可能比较天马行空,我的语文比较差,很难把自己想表达的说出来,为此我就是记录一样关键字,可能这样还会更好些 背景是讲用户 ...
- 11.21 CSS学习-上午
font-family:设置文本的字体序列,应当多设置几个,作为后备机制,如果浏览器不支持第一种字体,它将尝试下一种字体.字体序列的名字超过一个字需要使用引号,多个字体序列用逗号分隔指明:{font- ...