java.io.BufferedInputStream 源码分析
BufferedInputStream是一个带缓冲区的输入流,在读取字节数据时可以从底层流中一次性读取多个字节到缓冲区,而不必每次读取操作都调用底层流,从而提高系统性能。
先介绍几个关键属性
//默认缓冲区的小大
private static int defaultBufferSize = 8192;
//内部缓冲区
protected volatile byte buf[];
//缓冲区中可用的字节数量
protected int count;
//缓冲区中当前读取位置
protected int pos;
//重复读取时标记的位置
protected int markpos = -1;
//这个值是设置当用户调用了mark(int readlimit)以后,后续可以读取readlimit这个多个字节reset方法有效。
protected int marklimit;
pos指向缓冲区中下一个可以read的位置,count是记录缓冲区中可用的字节总数,当pos >= count就需要重新读取底层流来填充缓冲区了。

当你调用mark方法时,内部会保存一个markPos标志,它的值为目前读取字节流的pos位置,倘若你调用reset方法,这时候会把pos重置为markPos的值,这样你就可以重读已经读过的字节。
举个例子来说,比如有个字节流为【ABCDEFG】 那么pos指向B的位置,当比调用mark方法时markPos也指向B的位置,然后你接着调用read方法读取 B,C,D,现在pos指向E 当你调用reset方法后
会将pos设置为markPos的位置,这样你在读的时候又从B开始读了,这样就实现了重复读的效果。
mark方法中还有个参数markLimit,它是设置当你调用mark方法后 接着可以读取多少个字节 reset方法仍然保持有效。
举个例子来说,比如你传入的markLimit的值为20, 那么当你调用mark后,后面我读取了22个字节(超过了20),那么这时在调用reset方法就失效了,缓冲区不会再为我保存之前mark标记的那段数据了。
核心方法:当我们调用read()方法时,它在内部做了一些事情。
public synchronized int read() throws IOException {
if (pos >= count) { // 检查是否有可读缓冲数据
fill(); // 没有缓冲数据可读,则从物理数据源读取数据并填充缓冲区
if (pos >= count) // 若物理数据源也没有多于可读数据,则返回-1,标示EOF
return -1;
}
// 从缓冲区读取buffer[pos]并返回(由于这里读取的是一个字节,而返回的是整型,所以需要把高位置0)
return getBufIfOpen()[pos++] & 0xff;
}
private byte[] getBufIfOpen() throws IOException {
byte[] buffer = buf; // buf为内部缓冲区
if (buffer == null)
throw new IOException("Stream closed");
return buffer;
}
其中pos为缓冲区buffer下一个可读的数组下标,count是比缓冲区中最后一个有效字节的索引大 1 的索引。
我们可以一直从缓冲区里读取数据,直到pos变为count(此时只能从物理数据源读取数据),下面我们就分析下,当缓冲区里没有数据可读时,BufferedInputStream是如何处理的:
private void fill() throws IOException {
byte[] buffer = getBufIfOpen();
if (markpos < 0) //对应情况1 这也是最简单的一种情况
pos = 0;
//pos < buffer.length 对应情况2当中的A
else if (pos >= buffer.length) //如果进入条件 那么对应情况2当中到B
if (markpos > 0) { //对应情况B1
int sz = pos - markpos;
System.arraycopy(buffer, markpos, buffer, 0, sz);
pos = sz;
markpos = 0;
} else if (buffer.length >= marklimit) { //对应情况B3
markpos = -1;
pos = 0;
} else { //对应情况B4
int nsz = pos * 2;
if (nsz > marklimit)
nsz = marklimit;
byte nbuf[] = new byte[nsz];
System.arraycopy(buffer, 0, nbuf, 0, pos);
buffer = nbuf;
}
count = pos;
int n = getInIfOpen().read(buffer, pos, buffer.length - pos);
if (n > 0)
count = n + pos;
}
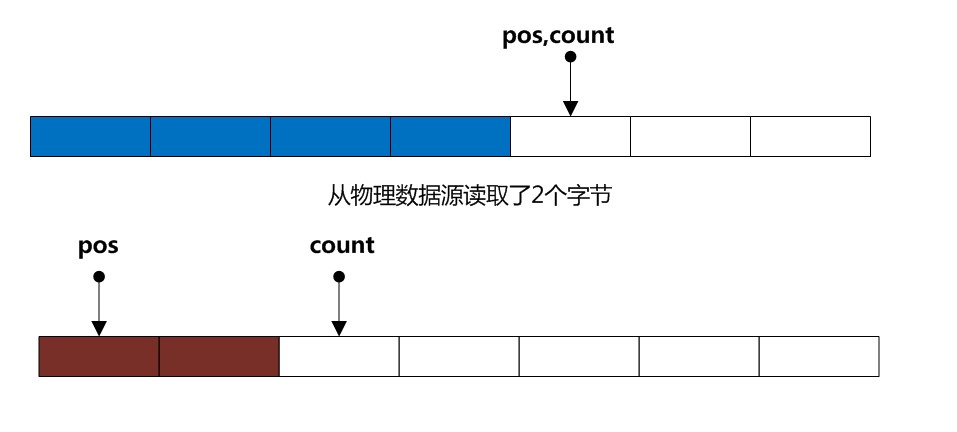
情况1、若用户没有开启re-read功能(即未调用mark方法) 当pos==count时, 我们只需要将pos重新置为0,然后从物理源读取数据(假设读到了n个字节),最后把count设置成 n + pos 即可 (其实就是n,因为pos之前被设置成了0), 当下次你在调用read方法时,就直接从缓冲读取,非常快速(如下图)

情况2、若用户开启了re-read功能,(即调用mark方法),那么情况就变得复杂了,这意味着我们需要保存从markPos到pos这段数据,以供用户调用reset时重复读取该段数据,现在我们分情况讨论。
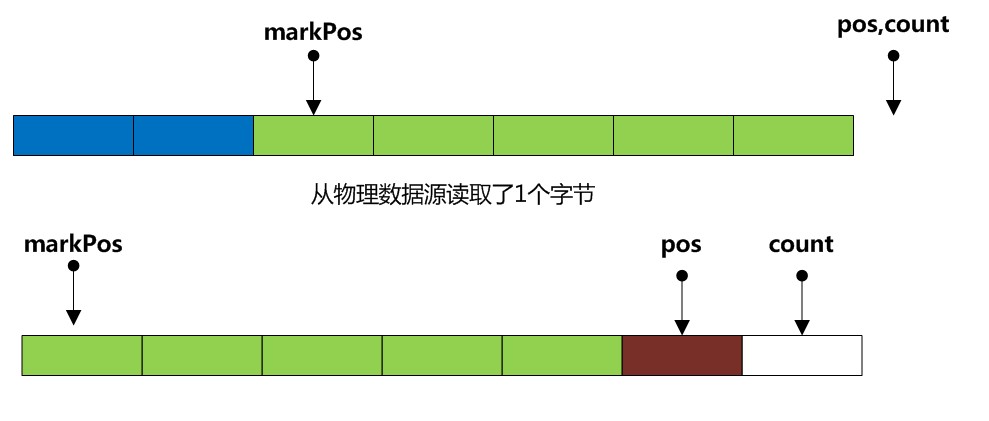
A:pos < buffer.length 这意味着缓冲区还有多余空间,所以我们可以继续从物理数据源读取数据放入到缓冲区中(如下图)
B: pos >= buffer.length 这意味着缓冲区已经没有更多空间,所以需要清空缓冲区,同时还必须保留原来 markPos到pos那段数据,以供用户调用reset时重复读取该段数据,
到这一步又分为几种情况
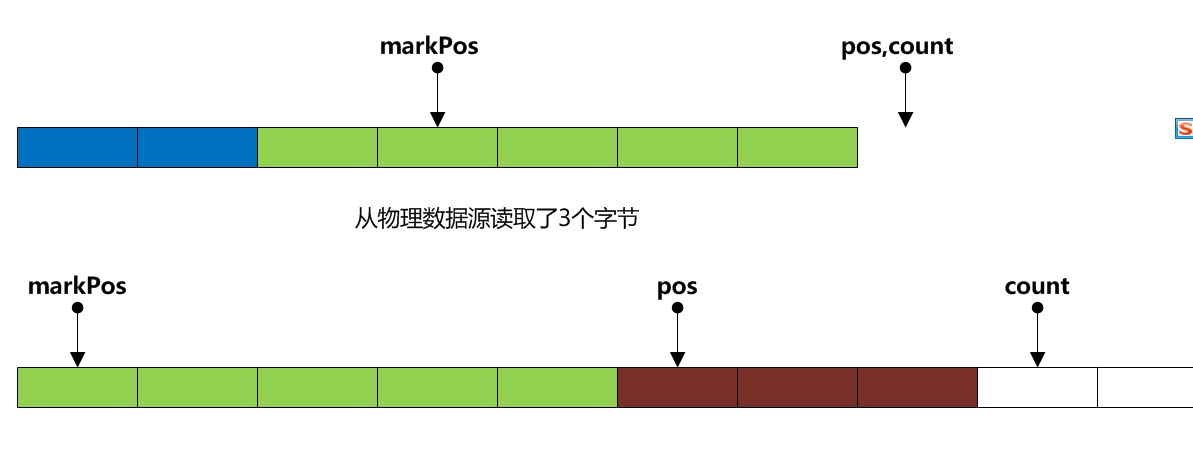
B1:markpos > 0 那么 (pos - makrPos)一定小于缓冲区大小,这样意味着我们保留原来markPos到pos那段数据的同时 缓冲区还有空余空间
所以需要这样做
// 计算需要保留多少字节的数据
int sz = pos - markPos;
// 然后拷贝到缓冲头部
System.arraycopy(buffer, markpos, buffer, 0, sz);
// 重置pos以及markPos
pos=sz;
markPos=0;
B2: markpos == 0 那么 (pos - makrPos)已经等于缓冲区大小,这样意味着我们保留原来markPos到pos那段数据的同时 缓冲区已经没有空余空间,所以这时候我们是无法通过挪动位置来使缓冲区有多余空间的,所以我们只可以清空或扩展缓冲区 那么又分为俩种情况(B3:B4)。
B3: buffer.length >= marklimit时 ,此时意味着markPos已经失效,用户不可以在进行re-read,所以此时我们就可以简单释放整个缓冲区了:pos=0, markPos=-1;
B4: 意味着markPos还有效,所以我们只能通过扩展缓冲区的方式来使缓冲区有多余空间。
再解释一下mark(int readlimit)这个方法的用法,这个readlimit的意思是在调用mark方法以后,缓冲区最对还可以读取多少个字节标记才失效。
是取readlimit和BufferedInputStream类的缓冲区大小两者中的最大值,而并非完全由readlimit确定,这个在JAVA文档中是没有提到的。
JAVA中mark()和reset()用法的通俗理解mark就像书签一样,在这个BufferedInputStream对应的buffer里作个标记,以后再调用reset时就可以再回到这个mark过的地方。mark方法有个参数,通过这个整型参数,你告诉系统,希望在读出这么多个字符之前,这个mark保持有效。读过这么多字符之后,系统可以使mark不再有效,而你不能觉得奇怪或怪罪它。这跟buffer有关,如果你需要很长的距离,那么系统就必须分配很大的buffer来保持你的mark。
java.io.BufferedInputStream 源码分析的更多相关文章
- java.io.ByteArrayOutputStream 源码分析
ByteArrayOutputStream 内部包含了一个缓冲区,缓冲区会随着数据的不断写入而自动增长,俗称内存流. 首先看一下俩个属性,buf是内部缓冲区,count是记录写入了多少个字节. pro ...
- java.io.ByteArrayInputStream 源码分析
ByteArrayInputStream 包含一个内部缓冲区,该缓冲区包含从流中读取的字节. 成员变量 //由该流的创建者提供的 byte 数组. protected byte buf[]; //要从 ...
- java.io.BufferedOutputStream 源码分析
BufferedOutputStream 是一个带缓冲区的输出流,通过设置这种输出流,应用程序就可以字节写入到缓冲区中,当缓冲区满了以后再调用底层系统,而不必针对每次字节写入调用底层系统,从而提高系 ...
- 细说并发5:Java 阻塞队列源码分析(下)
上一篇 细说并发4:Java 阻塞队列源码分析(上) 我们了解了 ArrayBlockingQueue, LinkedBlockingQueue 和 PriorityBlockingQueue,这篇文 ...
- Java split方法源码分析
Java split方法源码分析 public String[] split(CharSequence input [, int limit]) { int index = 0; // 指针 bool ...
- 【JAVA】ThreadLocal源码分析
ThreadLocal内部是用一张哈希表来存储: static class ThreadLocalMap { static class Entry extends WeakReference<T ...
- 【Java】HashMap源码分析——常用方法详解
上一篇介绍了HashMap的基本概念,这一篇着重介绍HasHMap中的一些常用方法:put()get()**resize()** 首先介绍resize()这个方法,在我看来这是HashMap中一个非常 ...
- 【Java】HashMap源码分析——基本概念
在JDK1.8后,对HashMap源码进行了更改,引入了红黑树.在这之前,HashMap实际上就是就是数组+链表的结构,由于HashMap是一张哈希表,其会产生哈希冲突,为了解决哈希冲突,HashMa ...
- Java中ArrayList源码分析
一.简介 ArrayList是一个数组队列,相当于动态数组.每个ArrayList实例都有自己的容量,该容量至少和所存储数据的个数一样大小,在每次添加数据时,它会使用ensureCapacity()保 ...
随机推荐
- Groovy 学习手册(1)
1. 需要安装的软件 Java / Groovy 对应 Java 和 Groovy,你需要安装以下软件: Java JDK,例如 JDK 8 IDE,例如 Eclipse,NetBeans 8 Gro ...
- VB通用数据库操作方法
1.VB通用数据操作方法. 2.通用数据库查询方法. 3.通用数据库操作方法. 'ERP查询数据库 Public Function YZQuery(sqls As String, msgstring ...
- Redis设置和更新Key的过期时间
EXPIRE key seconds 为给定 key 设置生存时间,当 key 过期时(生存时间为 0 ),它会被自动删除. 在 Redis 中,带有生存时间的 key 被称为『易失的』(volati ...
- python sort和sorted函数
sort 与 sorted 区别: sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作. list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 ...
- mysql 主从同步遇到的问题(1032)
event_scheduler对主从的影响: 1 对于已经存在的主从, 新建立events没有影响. 2 对于新建立的主从,如果有events ,那么需要在从库上把event_scheduler设置为 ...
- ES6模块的import和export用法
ES6之前已经出现了js模块加载的方案,最主要的是CommonJS和AMD规范.commonjs主要应用于服务器,实现同步加载,如nodejs.AMD规范应用于浏览器,如requirejs,为异步加载 ...
- Golang之字符串格式化
字符串格式化 // Go 之 字符串格式化 // // Copyright (c) 2015 - Batu // package main import ( "fmt" ) typ ...
- Enum,Int,String的互相转换 枚举转换
Enum为枚举提供基类,其基础类型可以是除 Char 外的任何整型.如果没有显式声明基础类型,则使用 Int32.编程语言通常提供语法来声明由一组已命名的常数和它们的值组成的枚举. 注意:枚举类型的基 ...
- ashx页面返回json字符串|jQuery 的ajax处理请求的纠结问题
纠结,整了半天的jquery的ajax请求数据. 遇到的问题: 1 ajax方法一直进入error方法里,进入到请求的.ashx页面.这个问题,我未找到是什么原因.反正我使用了一下的代码,就好了. $ ...
- filezilla修改默认21端口
一.filezilla修改端口21 1.修改ftp端口号,例如我们想把21修改成888 2.修改数据端口号为N-1,即888-1=887 3.防火墙中开启端口888和887 完成一个FTP的传输过程不 ...