Spark部署
Spark的部署让人有点儿困惑,有些需要注意的事项,本来我已经装成功了YARN模式的,但是发现了一些问题,出现错误看日志信息,完全看不懂那个错误信息,所以才打算翻译Standalone的部署的文章。第一部分,我先说一下YARN模式的部署方法。第二部分才是Standalone的方式。
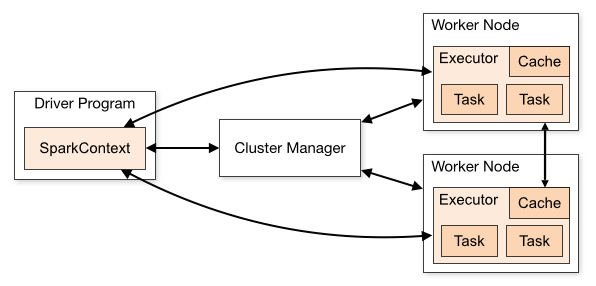
我们首先看一下Spark的结构图,和hadoop的差不多。
1、YARN模式
采用yarn模式的话,其实就是把spark作为一个客户端提交作业给YARN,实际运行程序的是YARN,就不需要部署多个节点,部署一个节点就可以了。
把从官网下载的压缩包在linux下解压之后,进入它的根目录,没有安装git的,先执行yum install git安装git
1)运行这个命令: SPARK_HADOOP_VERSION=2.2.0 SPARK_YARN=true ./sbt/sbt assembly
就等着吧,它会下载很多jar包啥的,这个过程可能会卡死,卡死的就退出之后,重新执行上面的命令。
2)编辑conf目录下的spark-env.sh(原来的是.template结尾的,删掉.template),添加上HADOOP_CONF_DIR参数
HADOOP_CONF_DIR=/etc/hadoop/conf
3)运行一下demo看看,能出结果 Pi is roughly 3.13794
SPARK_JAR=./assembly/target/scala-/spark-assembly_2.9.3-0.8.1-incubating-hadoop2.2.0.jar \
./spark-class org.apache.spark.deploy.yarn.Client \
--jar examples/target/scala-/spark-examples-assembly--incubating.jar \
--class org.apache.spark.examples.SparkPi \
--args yarn-standalone \
--num-workers \
--master-memory 1g \
--worker-memory 1g \
--worker-cores
2、Standalone模式
下面我们就讲一下怎么部署Standalone,参考页面是http://spark.incubator.apache.org/docs/latest/spark-standalone.html。
这里我们要一个干净的环境,刚解压出来的,运行之前的命令的时候不能再用了,会报错的。
1)打开make-distribution.sh,修改SPARK_HADOOP_VERSION=2.2.0,然后执行./make-distribution.sh, 然后会生成一个dist目录,这个目录就是我们要部署的内容。官方推荐是先把master跑起来,再部署别的节点,大家看看bin目录下面的脚本,和hadoop的差不多的,按照官方文档的推荐的安装方式有点儿麻烦。下面我们先说简单的方法,再说官方的方式。
我们打开dist目录下conf目录的,如果没有slaves文件,添加一个,按照hadoop的那种配置方式,把slave的主机名写进去,然后把dist目录部署到各台机器上,回到master上面,进入第三题、目录的sbin目录下,有个start-all.sh,执行它就可以了。
下面是官方文档推荐的方式,先启动master,执行。
./bin/start-master.sh
2)部署dist的目录到各个节点,然后通过这个命令来连接master节点
./spark-class org.apache.spark.deploy.worker.Worker spark://IP:PORT
3)然后在主节点查看一下http://localhost:8080 ,查看一下子节点是否在这里,如果在,就说明连接成功了。
4) 部署成功之后,想要在上面部署程序的话,在执行./spark-shell的时候,要加上MASTER这个参数。
MASTER=spark://IP:PORT ./spark-shell
3、High Availability
Spark采用Standalone模式的话,Spark本身是一个master/slaves的模式,这样就会存在单点问题,Spark采用的是zookeeper作为它的active-standby切换的工具,设置也很简单。一个完整的切换需要1-2分钟的时间,这个时候新提交的作业会受到影响,之前提交到作业不会受到影响。
在spark-env.sh添加以下设置:
//设置下面三项JVM参数,具体的设置方式在下面//spark.deploy.recoveryMode=ZOOKEEPER//spark.deploy.zookeeper.url=192.168.1.100:2181,192.168.1.101:2181// /spark是默认的,可以不写//spark.deploy.zookeeper.dir=/spark export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop.Master:2181,hadoop.SlaveT1:2181,hadoop.SlaveT2:2181"
这里就有一个问题了,集群里面有多个master,我们连接的时候,连接谁?用过hbase的都知道是先连接的zookeeper,但是Spark采用的是另外的一种方式,如果我们有多个master的话,实例化SparkContext的话,使用spark://host1:port1,host2:port2这样的地址,这样它会同时注册两个,一个失效了,还有另外一个。
如果不愿意配置高可用的话,只是想失败的时候,再恢复一下,重新启动的话,那就使用FILESYSTEM的使用,指定一个目录,把当前的各个节点的状态写入到文件系统。
spark.deploy.recoveryMode=FILESYSTEMspark.deploy.recoveryDirectory=/usr/lib/spark/dataDir
当 stop-master.sh来杀掉master之后,状态没有及时更新,再次启动的时候,会增加一分钟的启动时间来等待原来的连接超时。
recoveryDirectory最好是能够使用一个nfs,这样一个master失败之后,就可以启动另外一个master了。
Spark部署的更多相关文章
- Spark部署三种方式介绍:YARN模式、Standalone模式、HA模式
参考自:Spark部署三种方式介绍:YARN模式.Standalone模式.HA模式http://www.aboutyun.com/forum.php?mod=viewthread&tid=7 ...
- 基于Docker搭建大数据集群(四)Spark部署
主要内容 spark部署 前提 zookeeper正常使用 JAVA_HOME环境变量 HADOOP_HOME环境变量 安装包 微云下载 | tar包目录下 Spark2.4.4 一.环境准备 上传到 ...
- 大数据系列之并行计算引擎Spark部署及应用
相关博文: 大数据系列之并行计算引擎Spark介绍 之前介绍过关于Spark的程序运行模式有三种: 1.Local模式: 2.standalone(独立模式) 3.Yarn/mesos模式 本文将介绍 ...
- Spark部署及应用
在飞速发展的云计算大数据时代,Spark是继Hadoop之后,成为替代Hadoop的下一代云计算大数据核心技术,目前Spark已经构建了自己的整个大数据处理生态系统,如流处理.图技术.机器学习.NoS ...
- 再谈spark部署搭建和企业级项目接轨的入门经验(博主推荐)
进入我这篇博客的博友们,相信你们具备有一定的spark学习基础和实践了. 先给大家来梳理下.spark的运行模式和常用的standalone.yarn部署.这里不多赘述,自行点击去扩展. 1.Spar ...
- Spark 部署即提交模式意义解析
Spark 的官方从 Cluster Mode Overview 中,官方向我们介绍了 cluster 模式的部署方式. Spark 作为独立进程在集群上运行,他们通过 SparkContext 进行 ...
- 入门大数据---Spark部署模式与作业提交
一.作业提交 1.1 spark-submit Spark 所有模式均使用 spark-submit 命令提交作业,其格式如下: ./bin/spark-submit \ --class <ma ...
- spark 部署问题
spark的web UI 端口设置:spark-env.sh 中设置SPARK_MASTER_WEBUI_PORT 为自己想设置的端口号. 其他worker 的web UI 端口默认:8081 mas ...
- [Spark] - Spark部署安装
环境:centos6.0 虚拟机 搭建单机版本的spark 前提条件:搭建好hadoop环境 1. 下载scala进行安装 只需要设置环境变量SCALA_HOME和PATH即可 export SCAL ...
随机推荐
- [转]IC行业的牛人
转载的: 说来惭愧,我所了解的牛人也只是大学教授,工业界的高手了解的还太少,虽然我对教育界的牛人了解的也不多,但这里也要牢骚几句,论坛上的人好像只是认识Gray,Razavi,Allen,Lee, ...
- C#基础课程之三循环语句
for循环: ; i < ; i++) { Console.WriteLine("执行"+i+"次"); } while循环: while (true) ...
- 在windows 上统计git 代码量
1 需要系统安装 git + gawk git 安装自行百度 gawk 到官网下载 http://gnuwin32.sourceforge.net/packages/gawk.htm 1.2 下载好后 ...
- FIR仿真module_04
作者:桂. 时间:2018-02-06 12:10:14 链接:http://www.cnblogs.com/xingshansi/p/8421001.html 前言 本文主要记录基本的FIR实现, ...
- 基于Docker的负载均衡和服务发现
应用的容器化和微服务化带来的问题 在缺省网络模型中,容器每次重启后,IP会发生变动,在一个大的分布式系统保证IP地址不变是比较复杂的事情 IP频繁发生变动,动态应用部署无法预知容器的IP地址,clie ...
- 配置并使用Android支持的库
原文链接:http://android.eoe.cn/topic/android_sdk Android Support Library(支持库)提供了包含一个API库的JAR文件,当你的应用运行在A ...
- MQ有啥用
Q:最近看了一些MSMQ的资料,感觉很是奇怪,在IIS中装上此服务后,感觉这东西就像一个小数据库一样,暂时保存一些发送过来的数据,然后另一端再去收取?A:是的. Q:这样有什么用呢?直接在数据库中建立 ...
- # file Python-3.4.7.tar.xz Python-3.4.7.tar.xz: XZ compressed data
# file Python-3.4.7.tar.xz Python-3.4.7.tar.xz: XZ compressed data # xz -d Python-3.4.7.tar.xz # ls ...
- Python:sitecustomize 和 usercustomize
Python提供了两个hook用于定制Python:sitecustomize 和 usercustomize,首先需要查看site包目录, 然后就可以在此目录下创建usercustomize.py文 ...
- 【DIOCP-DEMO说明】所有演示DEMO的简要说明
samples目录下面为自带的DEMO 发现有很多朋友不知道如何开始DIOCP,下面是DEMO的简单说明,希望对大家有用 C#\Simple 用C#写的一个简单的回传测试,服务端开启ECHO服务器 ...