SparkStreaming数据源Flume实际案例分享
一、什么是Flume?
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
flume的特点:
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
flume的可靠性
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
flume的可恢复性:
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
flume的一些核心概念:
Agent 使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。
- Client 生产数据,运行在一个独立的线程。
- Source 从Client收集数据,传递给Channel。
- Sink 从Channel收集数据,运行在一个独立线程。
- Channel 连接 sources 和 sinks ,这个有点像一个队列。
- Events 可以是日志记录、 avro 对象等。
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:
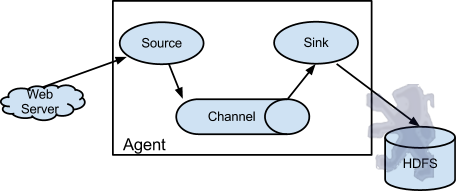
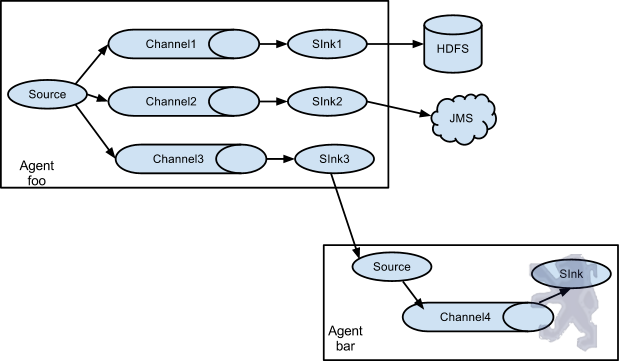
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是NB之处。如下图所示:
二、Flume+Kafka+Spark Streaming应用场景:
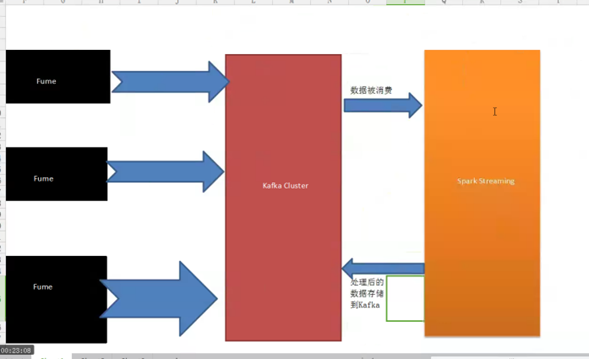
1、Flume集群采集外部系统的业务信息,将采集后的信息发生到Kafka集群,最终提供Spark Streaming流框架计算处理,流处理完成后再将最终结果发送给Kafka存储,架构如下图:
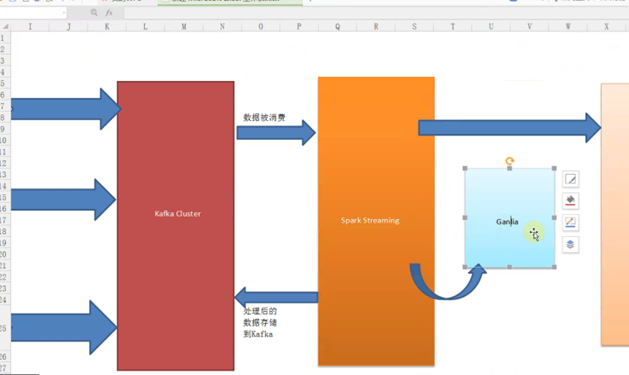
2、Flume集群采集外部系统的业务信息,将采集后的信息发生到Kafka集群,最终提供Spark Streaming流框架计算处理,流处理完成后再将最终结果发送给Kafka存储,同时将最终结果通过Ganglia监控工具进行图形化展示,架构如下图:
3、我们要做:Spark streaming 交互式的360度的可视化,Spark streaming 交互式3D可视化UI;Flume集群采集外部系统的业务信息,将采集后的信息发生到Kafka集群,最终提供Spark Streaming流框架计算处理,流处理完成后再将最终结果发送给Kafka存储,将最终结果同时存储在数据库(Mysql)、内存中间件(Redis、MemSQL)中,同时将最终结果通过Ganglia监控工具进行图形化展示,架构如下图:
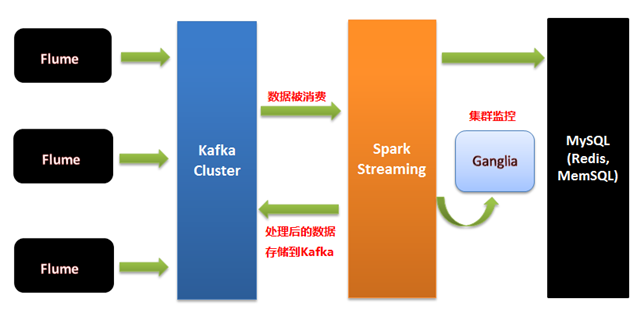
三、Kafka数据写入Spark Streaming有二种方式:
一种是Receivers,这个方法使用了Receivers来接收数据,Receivers的实现使用到Kafka高层次的消费者API,对于所有的Receivers,接收到的数据将会保存在Spark 分布式的executors中,然后由Spark Streaming启动的Job来处理这些数据;然而,在默认的配置下,这种方法在失败的情况下会丢失数据,为了保证零数据丢失,你可以在Spark Streaming中使用WAL日志功能,这使得我们可以将接收到的数据保存到WAL中(WAL日志可以存储在HDFS上),所以在失败的时候,我们可以从WAL中恢复,而不至于丢失数据。
另一种是DirectAPI,产生数据和处理数据的时候是在两台机器上?其实是在同一台数据上,由于在一台机器上有Driver和Executor,所以这台机器要足够强悍。
Flume集群将采集的数据放到Kafka集群中,Spark Streaming会实时在线的从Kafka集群中通过DirectAPI拿数据,可以通过Kafka中的topic+partition查询最新的偏移量(offset)来读取每个batch的数据,即使读取失败也可再根据偏移量来读取失败的数据,保证应用运行的稳定性和数据可靠性。
温馨提示:
1、Flume集群数据写入Kafka集群时可能会导致数据存放不均衡,即有些Kafka节点数据量很大、有些不大,后续会对分发数据进行自定义算法来解决数据存放不均衡问题。
2、个人强烈推荐在生产环境下用DirectAPI,但是我们的发行版,会对DirectAPI进行优化,降低其延迟。
总结:
实际生产环境下,搜集分布式的日志以Kafka为核心。
姜伟
备注:86课
更多私密内容,请关注微信公众号:DT_Spark
SparkStreaming数据源Flume实际案例分享的更多相关文章
- Flume1.5.0入门:安装、部署、及flume的案例
转自:http://www.aboutyun.com/thread-8917-1-1.html 问题导读1.什么是flume2.flume的官方网站在哪里?3.flume有哪些术语?4.如何配置flu ...
- 2、Flume1.7.0入门:安装、部署、及flume的案例
一.什么是Flume? flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用. flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的 ...
- Flume实战案例运维篇
Flume实战案例运维篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Flume概述 1>.什么是Flume Flume是一个分布式.可靠.高可用的海量日志聚合系统,支 ...
- 【案例分享】使用ActiveReports报表工具,在.NET MVC模式下动态创建报表
提起报表,大家会觉得即熟悉又陌生,好像常常在工作中使用,又似乎无法准确描述报表.今天我们来一起了解一下什么是报表,报表的结构.构成元素,以及为什么需要报表. 什么是报表 简单的说:报表就是通过表格.图 ...
- 【案例分享】在 React 框架中使用 SpreadJS 纯前端表格控件
[案例分享]在 React 框架中使用 SpreadJS 纯前端表格控件 本期葡萄城公开课,将由国电联合动力技术有限公司,资深前端开发工程师——李林慧女士,与大家在线分享“在 React 框架中使用 ...
- 大数据学习day35----flume01-------1 agent(关于agent的一些问题),2 event,3 有关agent和event的一些问题,4 transaction(事务控制机制),5 flume安装 6.Flume入门案例
具体见文档,以下只是简单笔记(内容不全) 1.agent Flume中最核心的角色是agent,flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道.对于每一个Age ...
- ArcGIS Add-in插件开发从0到1及实际案例分享
同学做毕设,要求我帮着写个ArcGIS插件,实现功能为:遍历所有图斑,提取相邻图斑的公共边长及其他属性(包括相邻图斑的ID),链接到属性表中.搞定后在这里做个记录.本文分两大部分: ArcGIS插件开 ...
- Office 2010 KMS激活原理和案例分享
Office 2010 KMS激活原理和案例分享 为了减低部署盗版(可能包含恶意软件.病毒和其他安全风险)的可能性,Office 2010面向企业客户推出了新的批量激活方式:KMS和MAK.这 ...
- Office 2010 KMS激活原理和案例分享 - Your Office Solution Here - Site Home - TechNet Blogs
[作者:葛伟华.张玉工程师 , Office/Project支持团队, 微软亚太区全球技术支持中心 ] 为了减低部署盗版(可能包含恶意软件.病毒和其他安全风险)的可能性,Office 2010面向企 ...
随机推荐
- gulp实时刷新页面
需要安装nodejs 全局安装gulp cnpm install -g gulp 局部安装 cnpm install -save-dev gulp 添加配置文件,新建gulpfile.js var g ...
- spring in action 学习笔记十:用@PropertySource避免注入外部属性的值硬代码化
@PropertySource的写法为:@PropertySource("classpath:某个.properties文件的类路径") 首先来看一下这个案例的目录结构,重点看带红 ...
- DiskGenius
DiskGenius是一款集磁盘分区管理与数据恢复功能于一身的工具软件.它即是一款功能强大.灵活易用的分区软件,同时也是一款技术高超.功能全面的数据恢复软件.它不仅具备与分区管理有关的几乎全部功能,支 ...
- 关闭vscode打开新文件自动关闭预览文件功能
经常碰到这个问题,我打开文件就是有用的,每次给我自动关闭了我还得去打开. 当然这个问题可以双击文件,接触那个文件的预览状态就可以解决了.不过还有一个更懒的方法,直接修改vscode配置就好了. // ...
- clips 前端 js 动画 抛物线加入购物车
抛物线加入购物车的特效动画(支持ie7以上,移动端表现良好) 1.引用一个极小的jquery插件库 2.启动 设置 起点 终点 和完成后回调函数 1.插件地址 git-hub上的官方主页 ...
- linux -特殊符号
在shell中常用的特殊符号罗列如下: # ; ;; . , / \\ 'string'| ! $ ${} $? $$ $* \"string\"* ** ...
- java1.7集合源码阅读:ArrayList
ArrayList是jdk1.2开始新增的List实现,首先看看类定义: public class ArrayList<E> extends AbstractList<E> i ...
- 第五步:Lucene创建索引
package cn.lucene; import java.io.IOException; import java.nio.file.Paths; import java.util.Date; im ...
- asp.net 网站模板怎么用,就是16aspx上面下下来的模板,里面有个sln文件,其他全是文件夹的东西
.net写的程序模板一般都被写死了.那样只有通过程序改了.
- RANSAC中迭代次数的计算
假设 $w=\frac{内点个数 }{所有点的个数}$. 则 $p_{0}=w^n$表示采样的$n$个点全为内点的概率(可重复) 则至少有一个为外点的概率$p_{1}=1-p_{0}$ 则重复$K$次 ...