Adam 算法
简介
Adam 是一种可以替代传统随机梯度下降(SGD)过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。Adam 最开始是由 OpenAI 的 Diederik Kingma 和多伦多大学的 Jimmy Ba 在提交到 2015 年 ICLR 论文(Adam: A Method for Stochastic Optimization)中提出的。 「Adam」,其并不是首字母缩写,也不是人名。它的名称来源于适应性矩估计(adaptive moment estimation)。在介绍这个算法时,原论文列举了将 Adam 优化算法应用在非凸优化问题中所获得的优势: 1.直截了当地实现
2.高效的计算
3.所需内存少
4.梯度对角缩放的不变性(第二部分将给予证明)
5.适合解决含大规模数据和参数的优化问题
6.适用于非稳态(non-stationary)目标
7.适用于解决包含很高噪声或稀疏梯度的问题
8.超参数可以很直观地解释,并且基本上只需极少量的调参
Adam 优化算法的基本机制
Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率
Adam 算法的提出者描述其为两种随机梯度下降扩展式的优点集合,即:
适应性梯度算法(AdaGrad)为每一个参数保留一个学习率以提升在稀疏梯度(即自然语言和计算机视觉问题)上的性能。
均方根传播(RMSProp)基于权重梯度最近量级的均值为每一个参数适应性地保留学习率。这意味着算法在非稳态和在线问题上有很有优秀的性能。
Adam 算法同时获得了 AdaGrad 和 RMSProp 算法的优点。Adam 不仅如 RMSProp 算法那样基于一阶矩均值计算适应性参数学习率,它同时还充分利用了梯度的二阶矩均值(即有偏方差/uncentered variance)。具体来说,算法计算了梯度的指数移动均值(exponential moving average),超参数 beta1 和 beta2 控制了这些移动均值的衰减率。移动均值的初始值和 beta1、beta2 值接近于 1(推荐值),因此矩估计的偏差接近于 0。该偏差通过首先计算带偏差的估计而后计算偏差修正后的估计而得到提升。
Adam算法

如上算法所述,在确定了参数α、β1、β2 和随机目标函数 f(θ) 之后,我们需要初始化参数向量、一阶矩向量、二阶矩向量和时间步。然后当参数θ没有收敛时,循环迭代地更新各个部分。即时间步 t 加 1、更新目标函数在该时间步上对参数θ所求的梯度、更新偏差的一阶矩估计和二阶原始矩估计,再计算偏差修正的一阶矩估计和偏差修正的二阶矩估计,然后再用以上计算出来的值更新模型的参数θ。
上图伪代码为展现了 Adam 算法的基本步骤。假定 f(θ) 为噪声目标函数:即关于参数θ可微的随机标量函数。我们对怎样减少该函数的期望值比较感兴趣,即对于不同参数θ,f 的期望值 E[f(θ)]。其中 f1(θ), ..., , fT (θ) 表示在随后时间步 1, ..., T 上的随机函数值。这里的随机性来源于随机子样本(小批量)上的评估和固有的函数噪声。而表示 ft(θ) 关于θ的梯度,即在实践步骤 t下ft对θ的偏导数向量。
该算法更新梯度的指数移动均值(mt)和平方梯度(vt),而参数 β1、β2 ∈ [0, 1) 控制了这些移动均值(moving average)指数衰减率。移动均值本身使用梯度的一阶矩(均值)和二阶原始矩(有偏方差)进行估计。然而因为这些移动均值初始化为 0 向量,所以矩估计值会偏差向 0,特别是在初始时间步中和衰减率非常小(即β接近于 1)的情况下是这样的。但好消息是,初始化偏差很容易抵消,因此我们可以得到偏差修正(bias-corrected)的估计 mt hat 和 vt hat。
注意算法的效率可以通过改变计算顺序而得到提升,例如将伪代码最后三行循环语句替代为以下两个:Adam 的更新规则
Adam 算法更新规则的一个重要特征就是它会很谨慎地选择步长的大小。假定ε=0,则在时间步 t 和参数空间上的有效下降步长为有效下降步长有两个上确界:即在
情况下,有效步长的上确界满足
和其他情况下满足 |∆t| ≤ α。第一种情况只有在极其稀疏的情况下才会发生:即梯度除了当前时间步不为零外其他都为零。而在不那么稀疏的情况下,有效步长将会变得更小。当
时,我们有
,因此可以得出上确界 |∆t| < α。在更通用的场景中,因为 |E[g]/ p E[g^2]| ≤ 1,我们有
。每一个时间步的有效步长在参数空间中的量级近似受限于步长因子α,即
。这个可以理解为在当前参数值下确定一个置信域,因此其要优于没有提供足够信息的当前梯度估计。这正可以令其相对简单地提前知道α正确的范围。 对于许多机器学习模型来说,我们知道好的最优状态是在参数空间内的集合域上有极高的概率。这并不罕见,例如我们可以在参数上有一个先验分布。因为α确定了参数空间内有效步长的量级(即上确界),我们常常可以推断出α的正确量级,而最优解也可以从θ0 开始通过一定量的迭代而达到。我们可以将
称之为信噪比(signal-to-noise ratio/SNR)。如果 SNR 值较小,那么有效步长∆t 将接近于 0,目标函数也将收敛到极值。这是非常令人满意的属性,因为越小的 SNR 就意味着算法对方向
是否符合真实梯度方向存在着越大的不确定性。例如,SNR 值在最优解附近趋向于 0,因此也会在参数空间有更小的有效步长:即一种自动退火(automatic annealing)的形式。有效步长∆t 对于梯度缩放来说仍然是不变量,我们如果用因子 c 重缩放(rescaling)梯度 g,即相当于用因子 c 重缩放
和用因子 c^2 缩放
,而在计算信噪比时缩放因子会得到抵消
.
 表示 ft(θ) 关于θ的梯度,即在实践步骤 t下ft对θ的偏导数向量。
表示 ft(θ) 关于θ的梯度,即在实践步骤 t下ft对θ的偏导数向量。

 有效下降步长有两个上确界:即在
有效下降步长有两个上确界:即在 情况下,有效步长的上确界满足
情况下,有效步长的上确界满足 和其他情况下满足 |∆t| ≤ α。第一种情况只有在极其稀疏的情况下才会发生:即梯度除了当前时间步不为零外其他都为零。而在不那么稀疏的情况下,有效步长将会变得更小。当
和其他情况下满足 |∆t| ≤ α。第一种情况只有在极其稀疏的情况下才会发生:即梯度除了当前时间步不为零外其他都为零。而在不那么稀疏的情况下,有效步长将会变得更小。当 时,我们有
时,我们有
 ,因此可以得出上确界 |∆t| < α。在更通用的场景中,因为 |E[g]/ p E[g^2]| ≤ 1,我们有
,因此可以得出上确界 |∆t| < α。在更通用的场景中,因为 |E[g]/ p E[g^2]| ≤ 1,我们有 。这个可以理解为在当前参数值下确定一个置信域,因此其要优于没有提供足够信息的当前梯度估计。这正可以令其相对简单地提前知道α正确的范围。
对于许多机器学习模型来说,我们知道好的最优状态是在参数空间内的集合域上有极高的概率。这并不罕见,例如我们可以在参数上有一个先验分布。因为α确定了参数空间内有效步长的量级(即上确界),我们常常可以推断出α的正确量级,而最优解也可以从θ0 开始通过一定量的迭代而达到。我们可以将
。这个可以理解为在当前参数值下确定一个置信域,因此其要优于没有提供足够信息的当前梯度估计。这正可以令其相对简单地提前知道α正确的范围。
对于许多机器学习模型来说,我们知道好的最优状态是在参数空间内的集合域上有极高的概率。这并不罕见,例如我们可以在参数上有一个先验分布。因为α确定了参数空间内有效步长的量级(即上确界),我们常常可以推断出α的正确量级,而最优解也可以从θ0 开始通过一定量的迭代而达到。我们可以将 称之为信噪比(signal-to-noise ratio/SNR)。如果 SNR 值较小,那么有效步长∆t 将接近于 0,目标函数也将收敛到极值。这是非常令人满意的属性,因为越小的 SNR 就意味着算法对方向
称之为信噪比(signal-to-noise ratio/SNR)。如果 SNR 值较小,那么有效步长∆t 将接近于 0,目标函数也将收敛到极值。这是非常令人满意的属性,因为越小的 SNR 就意味着算法对方向 是否符合真实梯度方向存在着越大的不确定性。例如,SNR 值在最优解附近趋向于 0,因此也会在参数空间有更小的有效步长:即一种自动退火(automatic annealing)的形式。有效步长∆t 对于梯度缩放来说仍然是不变量,我们如果用因子 c 重缩放(rescaling)梯度 g,即相当于用因子 c 重缩放
是否符合真实梯度方向存在着越大的不确定性。例如,SNR 值在最优解附近趋向于 0,因此也会在参数空间有更小的有效步长:即一种自动退火(automatic annealing)的形式。有效步长∆t 对于梯度缩放来说仍然是不变量,我们如果用因子 c 重缩放(rescaling)梯度 g,即相当于用因子 c 重缩放 和用因子 c^2 缩放
和用因子 c^2 缩放 ,而在计算信噪比时缩放因子会得到抵消
,而在计算信噪比时缩放因子会得到抵消 .
.
初始化偏差修正
正如本论文第二部分算法所述,Adam 利用了初始化偏差修正项。本部分将由二阶矩估计推导出这一偏差修正项,一阶矩估计的推导完全是相似的。首先我们可以求得随机目标函数 f 的梯度,然后我们希望能使用平方梯度(squared gradient)的指数移动均值和衰减率β2 来估计它的二阶原始矩(有偏方差)。令 g1, ..., gT 为时间步序列上的梯度,其中每个梯度都服从一个潜在的梯度分布 gt ∼ p(gt)。现在我们初始化指数移动均值 v0=0(零向量),而指数移动均值在时间步 t 的更新可表示为: 其中 gt^2 表示 Hadamard 积 gt⊙gt,即对应元素之间的乘积。同样我们可以将其改写为在前面所有时间步上只包含梯度和衰减率的函数,即消去 v:
其中 gt^2 表示 Hadamard 积 gt⊙gt,即对应元素之间的乘积。同样我们可以将其改写为在前面所有时间步上只包含梯度和衰减率的函数,即消去 v:

我们希望知道时间步 t 上指数移动均值的期望值 E[vt] 如何与真实的二阶矩
 相关联,所以我们可以对这两个量之间的偏差进行修正。下面我们同时对表达式(1)的左边和右边去期望,即如下所示:
相关联,所以我们可以对这两个量之间的偏差进行修正。下面我们同时对表达式(1)的左边和右边去期望,即如下所示:

如果真实二阶矩 E[gi2] 是静态的(stationary),那么ζ=0。否则ζ可以保留一个很小的值,这是因为我们应该选择指数衰减率 β1 以令指数移动均值分配很小的权重给梯度。所以初始化均值为零向量就造成了只留下了 (1 − βt^2 ) 项。我们因此在算法 1 中除以了ζ项以修正初始化偏差。
在稀疏矩阵中,为了获得一个可靠的二阶矩估计,我们需要选择一个很小的 β2 而在许多梯度上取均值。然而正好是这种小β2 值的情况导致了初始化偏差修正的缺乏,因此也就令初始化步长过大。
总结

常规操作
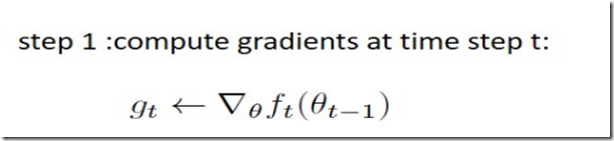







参考文献:
https://www.jianshu.com/p/3e363f5e1a79
http://blog.csdn.net/BVL10101111/article/details/72616516
http://blog.csdn.net/zj360202/article/details/70262874
Adam 算法的更多相关文章
- Adam算法
结合了Momentum 和RMSprop算法的优点
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- 优化算法:AdaGrad | RMSProp | AdaDelta | Adam
0 - 引入 简单的梯度下降等优化算法存在一个问题:目标函数自变量的每一个元素在相同时间步都使用同一个学习率来迭代,如果存在如下图的情况(不同自变量的梯度值有较大差别时候),存在如下问题: 选择较小的 ...
- Adam优化算法
Question? Adam 算法是什么,它为优化深度学习模型带来了哪些优势? Adam 算法的原理机制是怎么样的,它与相关的 AdaGrad 和 RMSProp 方法有什么区别. Adam 算法应该 ...
- 机器学习中几种优化算法的比较(SGD、Momentum、RMSProp、Adam)
有关各种优化算法的详细算法流程和公式可以参考[这篇blog],讲解比较清晰,这里说一下自己对他们之间关系的理解. BGD 与 SGD 首先,最简单的 BGD 以整个训练集的梯度和作为更新方向,缺点是速 ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- 优化深度神经网络(二)优化算法 SGD Momentum RMSprop Adam
Coursera吴恩达<优化深度神经网络>课程笔记(2)-- 优化算法 深度机器学习中的batch的大小 深度机器学习中的batch的大小对学习效果有何影响? 1. Mini-batch ...
- zz:一个框架看懂优化算法之异同 SGD/AdaGrad/Adam
首先定义:待优化参数: ,目标函数: ,初始学习率 . 而后,开始进行迭代优化.在每个epoch : 计算目标函数关于当前参数的梯度: 根据历史梯度计算一阶动量和二阶动量:, 计算当前时刻的下降 ...
- 深度学习剖根问底: Adam优化算法的由来
在调整模型更新权重和偏差参数的方式时,你是否考虑过哪种优化算法能使模型产生更好且更快的效果?应该用梯度下降,随机梯度下降,还是Adam方法? 这篇文章介绍了不同优化算法之间的主要区别,以及如何选择最佳 ...
随机推荐
- Java的位运算
左移位操作 左移位运算的符号为[<<],左移位运算符左面的操作元称作被移位数,右面的操作数称作移位量. 左移位运算是双目运算符,操作元必须是整型类型的数据,其移动过程是:[a <&l ...
- NGINX 缓存使用指南
NGINX 缓存使用指南 [proxy_cache] Nginx 一个web缓存坐落于客户端和“原始服务器(origin server)”中间,它保留了所有可见内容的拷贝.如果一个客户端请求的内容在缓 ...
- golang一些知识点
2.冒泡排序(二维数组使用): func main() { i := 1 MYLABEL: for { i++ if i > 3 { break MYLABEL } } fmt.Println( ...
- ionic准备之angular基础——dom操作相关(6)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 通过特定获取获取电脑外网IP地址
void get_WanIp() { }; ]; ]; ; }; GetTempPathA(MAX_PATH,szFilePath); strcat(szFilePath,"IPinTheW ...
- ListView知识点汇总(9.2)
1 最为基础的listview: http://www.cnblogs.com/allin/archive/2010/05/11/1732200.html http://blog.csdn.net/h ...
- Memcahed服务异常监控脚本
#!/bin/sh # filename: mon_mc.sh export MemcahedIp=$1export MemcahedPort=$2export NcCmd="nc $Mem ...
- Ubuntu 16.04 安装opencv的各种方法(含opencv contrib扩展包安装方法)
Ubuntu 16.04 安装opencv的各种方法(含opencv contrib扩展包安装方法) https://blog.csdn.net/ksws0292756/article/details ...
- 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数P。并将P对1000000007取模的结果输出。 即输出P%1000000007
include "stdafx.h" #include<iostream> #include<vector> #include <algorithm& ...
- 编写一个基于HBase的MR程序,结果遇到一个错:ERROR security.UserGroupInformation - PriviledgedActionException as ,求帮助
环境说明:Ubuntu12.04,使用CDH4.5,伪分布式环境 Hadoop配置如下: core-site.xml: <configuration><property> ...