火山引擎 DataTester:如何做 A/B 实验的假设检验
A/B 实验的核心统计学理论是(双样本)假设检验,是用来判断样本与样本、样本与总体的差异是由 抽样误差 引起还是 本质差别 造成的一种统计推断方法。
假设检验,顾名思义,是一种对自己做出的假设进行数据验证的过程。通俗地说,假设检验是一门 做出拒绝 的理论,检验结果有两种:拒绝原假设(reject H0),无法拒绝原假设(fail to reject H0)。实验者往往将主观不希望看到的结果(新策略没有效果)置于 原假设 (从英文命名就可以看出来感情色彩 - 它叫 null hypothesis),而将原假设的互斥事件,即对事实本身有利的结果(新策略有提升)置于 备则假设 (alternative hypothesis),如此构成的假设检验目的在于用现有的数据通过一系列理论演绎 拒绝原假设 ,达到证明备择假设是正确的,即某项改进有效的目的,所以这一套方法也被称作 null hypothesis significance testing (NHST) 。
由于我们永远只能抽取流量做 小样本 实验,所以每个假设检验都面临着 随机抽样误差 ,因此在做出推论的过程中,一切都围绕 概率 展开。这意味着没有任何一个基于假设检验的演绎过程可以对结果 100%确定。但所幸,统计理论可以告诉我们在每一步中犯错的机会。因此,事先知晓我们 可能犯什么错 ,以及 有多大机会犯错 就成了设计和解读假设检验的关键所在。
实验者在假设检验的过程中可能会做出 两类错误判断 - 不意外地 - 它们被命名为 第一类错误 (弃真)和 第二类错误 (取伪)。第一类错误(Type I Error):H0 为真,拒绝 H0。“本身没提升,但误判为有提升”第二类错误(Type II Error):H1 为真,接受 H0。“本身有提升,但没有察觉提升”
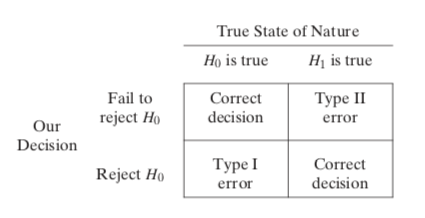
对比上图,第一类错误指的是原假设正确但是我们做出了拒绝原假设的结论,这个错误在现实中常常表现为“我作出了统计显著的结论但是我的改动实际上没用”;相应地,第二类错误指的是原假设错误但是我们没能拒绝原假设,这个错误在现实中常常表现为“我的改动有效,但实验没能检测出来”。
在 AB 实验的场景下,如果对某一个新 feature 是否有效进行假设检验,H0 为新 feature 没有效果,第一类错误指的是“新 feature 实际无效但检测出存在显著性效果”,第二类错误则指的是“新 feature 实际有效但未能检测出效果”。如果犯了第一类错误,会导致新 feature 的错误上线,可能会带来实际利益损失,如果犯了第二类错误,实际有效的 feature 将不会上线,带来的是潜在利益的损失。两相比较,应该更严格地控制第一类错误发生的概率。
定性知晓我们可能犯什么错以后,我们仍然需要定量地分析有多大机会犯错。在频率统计学中 ,显著性水平(α) 以及 (1 - 检验效力 power)(beta) 分别描述了实验者犯第一类错误和第二类错误的概率。这两个统计指标结合在一起比较完整地刻画一个假设检验的总体基本性能,也是进行一个假设检验所需统计指标的最小集。应该说,缺少任何一个,我们都没有足够的信息作出科学的推论,甚至可能错误影响产品的走向。
适用范围可以对 单个总体参数(H0:μ=c) 或者 两个总体参数(H0: μ1= μ2) 进行检验,假设的内容可以是双侧检验 如参数是否等于某个值(H0:μ=c),也可以为单侧检验如 参数是否大于或小于某个值(H0:μ><c)。在 AB 实验的背景下,我们通常进行的检验是 两总体双侧检验。
检验步骤
提出假设:H0: μ1= μ2v.s. H1: μ1!= μ2
构造统计量
计算统计量、检验阈值、置信区间及 p 值
得出结论:若 p<0.05 或统计量绝对值>阈值或置信区间包含 0,则拒绝原假设;若 p>0.05 或统计量绝对值<=阈值或置信区间不包含 0,则无法拒绝原假设。
Note:有些其他的计算公式会假定两组的总体方差相等,在方差的计算方式上有区别,这类公式不推荐,因为该假设在 AB 实验应用中并不常见。
p-valueP 值就是当原假设为真是所得到的样本观察结果或更极端结果出现的概率。如果 P 值很小,说明这种情况发生的概率很小,但如果出现了,根据小概率原理,我们就有理由拒绝原假设。P 值越小,说明实验发现的差异是因为抽样误差导致的概率越小,极大程度上还是由于本质上存在差异造成,我们拒绝原假设的理由越充分。
注: 两样本均值差的置信区间包含 0 等价于 P 值大于 0.05 ,此时接受原假设。思想上 与区间估计的原理中提到的“对称”有相通之处。两样本均值差的置信区间包含 0 等价于 均值差与 0 的距离小于 1.96 倍标准差 等价于 统计量的绝对值小于 1.96 等价于 P 值大于 0.05
DataTester 是火山引擎数智平台旗下产品,能基于先进的底层算法,提供科学分流能力和智能的统计引擎,支持多种复杂的 A/B 实验类型。DataTester 深度耦合推荐、广告、搜索、UI、产品功能等多种业务场景需求,为业务增长、转化、产品迭代、策略优化、运营提效等各个环节提供科学的决策依据,让业务真正做到数据驱动。
DataTester 经过抖音、今日头条等字节业务多年验证,截至 2022 年 8 月,已在字节跳动内部累计完成 150 万次 A/B 实验。此外也已经服务了美的、得到、凯叔讲故事等在内多家标杆客户,将成熟的“数据驱动增长”经验赋能给各行业。
点击跳转 火山引擎DataTester官网 了解更多
火山引擎 DataTester:如何做 A/B 实验的假设检验的更多相关文章
- 火山引擎 DataTester:让企业“无代码”也能用起来的 A/B 实验平台
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 当数字化变革方兴未艾,无代码正受到前所未有的关注.Salesforce 的数据显示,52%的 IT 部门表示,公司 ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- 火山引擎 A/B 测试产品——DataTester 私有化架构分享
作为一款面向 ToB 市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向 ToB 客户私有化的实际落地中,火 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 火山引擎MARS-APM Plus x 飞书 |降低线上OOM,提高App性能稳定性
通过使用火山引擎MARS-APM Plus的memory graph功能,飞书研发团队有效分析定位问题线上case多达30例,线上OOM率降低到了0.8‰,降幅达到60%.大幅提升了用户体验,为飞书的 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- JuiceFS 在火山引擎边缘计算的应用实践
火山引擎边缘云是以云计算基础技术和边缘异构算力结合网络为基础,构建在边缘大规模基础设施之上的云计算服务,形成以边缘位置的计算.网络.存储.安全.智能为核心能力的新一代分布式云计算解决方案. 01- 边 ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
随机推荐
- VRRP相关简述
VRRP 诞生原因 单网关,出问题时,旗下所有主机无法通信. 多网关,容易产生网关冲突. 而,VRRP能够在不改变组网的情况下,将多台路由器虚拟成一个虚拟路由器,通过配置虚拟路由器的IP地址为默认网关 ...
- React生命周期函数(迭代合并:react 16.3)
本文分两部分,上面的是react16.3,下部分是老版本 react 16.3生命周期更新解析 ------ 老react版本生命周期 1.组件生命周期的执行次数 只执行一次: constructor ...
- 谈谈SSO单点登录的设计实现
谈谈SSO单点登录的设计实现 本篇将会讲讲单点登录的具体实现. 实现思路 其实单点登录在我们生活中很常见,比如学校的网站,有很多个系统,迎新系统,教务系统,网课系统.我们往往只需要登录一次就能在各个系 ...
- 快速入门:构建您的第一个 .NET Aspire 应用程序
前言 云原生应用程序通常需要连接到各种服务,例如数据库.存储和缓存解决方案.消息传递提供商或其他 Web 服务..NET Aspire 旨在简化这些类型服务之间的连接和配置.在本快速入门中,您将了解如 ...
- 车的可用捕获量(3.26leetcode每日打卡)
在一个 8 x 8 的棋盘上,有一个白色车(rook).也可能有空方块,白色的象(bishop)和黑色的卒(pawn).它们分别以字符 "R",".",&quo ...
- 🔥🔥Java开发者的Python快速进修指南:面向对象--高级篇
首先,让我来介绍一下今天的主题.今天我们将讨论封装.反射以及单例模式.除此之外,我们不再深入其他内容.关于封装功能,Python与Java大致相同,但写法略有不同,因为Python没有修饰符.而对于反 ...
- mysql--基础管理
1.docker环境登录mysql PS C:\WINDOWS\system32> docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS P ...
- 25 个超棒的 Python 脚本合集
Python是一种功能强大且灵活的编程语言,拥有广泛的应用领域.下面是一个详细介绍25个超棒的Python脚本合集: 1. 网络爬虫:使用Python可以轻松编写网络爬虫,从网页中提取数据并保存为结构 ...
- jmeter编写java脚本
jmeter开发java脚本主要的依赖包有三个如下图 步骤1 :打开idea,创建一个project,导入上图依赖包 步骤2:创建一个类,继承AbstractJavaSamplerClient类,并实 ...
- ClickHouse(16)ClickHouse日志引擎Log详细解析
日志引擎系列 这些引擎是为了需要写入许多小数据量(少于一百万行)的表的场景而开发的. 这系列的引擎有: StripeLog Log TinyLog 共同属性 引擎: 数据存储在磁盘上. 写入时将数据追 ...