从baselines库的common/vec_env/vec_normalize.py模块看方差的近似计算方法
在baselines库的common/vec_env/vec_normalize.py中计算方差的调用方法为:
RunningMeanStd
同时该计算函数的解释也一并给出了:
https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Parallel_algorithm
也就是说这个函数是在对方差进行近似计算,找了下中文的这方面的资料:

上图来自:https://baijiahao.baidu.com/s?id=1715371851391883847&wfr=spider&for=pc
可以看到在wiki上给出了python的计算代码:


def shifted_data_variance(data):
if len(data) < 2:
return 0.0
K = data[0]
n = Ex = Ex2 = 0.0
for x in data:
n = n + 1
Ex += x - K
Ex2 += (x - K) * (x - K)
variance = (Ex2 - (Ex * Ex) / n) / (n - 1)
# use n instead of (n-1) if want to compute the exact variance of the given data
# use (n-1) if data are samples of a larger population
return variance
该代码的计算公式为:
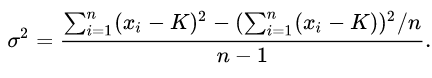
也就是说在样本数据较大的情况下可以使用该计算方法来近似计算样本方差。
给出自己的测试代码:
import numpy as np data = np.random.normal(10, 5, 100000000) print(data)
print(data.shape)
print(np.mean(data), np.var(data)) print('......')
def shifted_data_variance(data, K):
if len(data) < 2:
return 0.0
# K = data[0]
n = Ex = Ex2 = 0.0
for x in data:
n = n + 1
Ex += x - K
Ex2 += (x - K) * (x - K)
variance = (Ex2 - (Ex * Ex) / n) / (n - 1)
# use n instead of (n-1) if want to compute the exact variance of the given data
# use (n-1) if data are samples of a larger population
return variance print(shifted_data_variance(data, data[0]))
print(shifted_data_variance(data, 0))
print(shifted_data_variance(data, -10000))
运行结果:
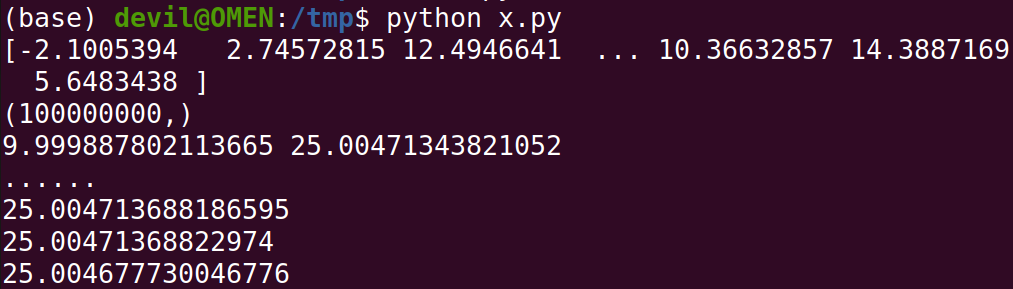
可以知道如果K值越接近真实的均值那么所得到的近似方差会更加逼近真实的样本方差。
那么如果样本数据较少的情况呢,上面的测试使用的是100000000个数据样本,如果是100个呢,给出测试:
代码:
import numpy as np data = np.random.normal(10, 5, 100) print(data)
print(data.shape)
print(np.mean(data), np.var(data)) print('......')
def shifted_data_variance(data, K):
if len(data) < 2:
return 0.0
# K = data[0]
n = Ex = Ex2 = 0.0
for x in data:
n = n + 1
Ex += x - K
Ex2 += (x - K) * (x - K)
variance = (Ex2 - (Ex * Ex) / n) / (n - 1)
# use n instead of (n-1) if want to compute the exact variance of the given data
# use (n-1) if data are samples of a larger population
return variance print(shifted_data_variance(data, data[0]))
print(shifted_data_variance(data, 0))
print(shifted_data_variance(data, -10000))
运行结果:
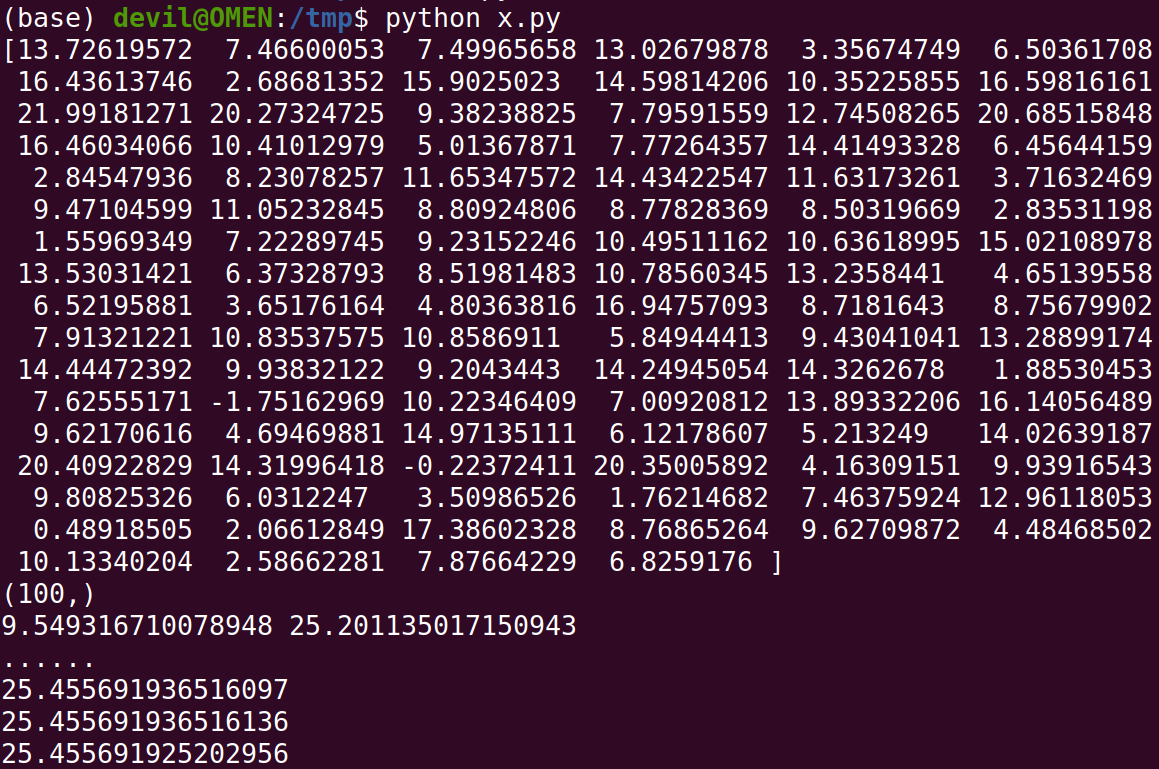
可以看到和数据样本较大规模的情况一样,该方法依然可以得到非常好的近似方差,同时K值越接近真实均值近似方差就越接近真实方差,不过这里可以看到这里的差别也是在小数点后九位,因此这个差距可以看做没有。
总结:
这个计算方差的最大好处就是可以在不计算样本均值的情况下就直接计算样本方差,该种计算方法非常适合样本数据量在不断增加的情况,不过这里的样本数据量增加也是在服从同一分布的条件下的。
比如我们需要不断的从一个数据分布中获得样本并获得分布的方差,如果不适用这种近似计算方差的方法每当我们得到一个新的样本都需要重新计算样本的方差,这样就会成几何倍数的增加计算量,毕竟标准的方差计算是需要遍历所有样本数据的。
给出标准的方差计算公式:
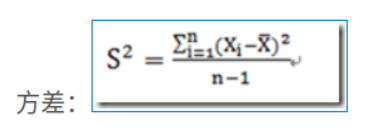
图片源自:https://www.cnblogs.com/devilmaycry812839668/p/16072130.html
不得不说算法设计可以有效提升计算性能。
================================================
不过根据wiki的说明可以知道,上述的方法在计算过程中设计到大量的求和sum计算,而求和计算由于会由于浮点数计算时的精度取舍从而影响最终的结果精度:
This algorithm is numerically stable if n is small.[1][4] However, the results of both of these simple algorithms ("naïve" and "two-pass") can depend inordinately on the ordering of the data and can give poor results for very large data sets due to repeated roundoff error in the accumulation of the sums. Techniques such as compensated summation can be used to combat this error to a degree.
================================================
在baselines库中使用的求方差的方法为:

也就是baselines中的函数:
class RunningMeanStd(object):
# https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Parallel_algorithm
def __init__(self, epsilon=1e-4, shape=()):
self.mean = np.zeros(shape, 'float64')
self.var = np.ones(shape, 'float64')
self.count = epsilon def update(self, x):
batch_mean = np.mean(x, axis=0)
batch_var = np.var(x, axis=0)
batch_count = x.shape[0]
self.update_from_moments(batch_mean, batch_var, batch_count) def update_from_moments(self, batch_mean, batch_var, batch_count):
self.mean, self.var, self.count = update_mean_var_count_from_moments(
self.mean, self.var, self.count, batch_mean, batch_var, batch_count) def update_mean_var_count_from_moments(mean, var, count, batch_mean, batch_var, batch_count):
delta = batch_mean - mean
tot_count = count + batch_count new_mean = mean + delta * batch_count / tot_count
m_a = var * count
m_b = batch_var * batch_count
M2 = m_a + m_b + np.square(delta) * count * batch_count / tot_count
new_var = M2 / tot_count
new_count = tot_count return new_mean, new_var, new_count
使用自己的测试代码:
import numpy as np data = np.random.normal(10, 5, 1000000) print(data)
print(data.shape)
print(np.mean(data), np.var(data)) print('......')
def shifted_data_variance(data, K):
if len(data) < 2:
return 0.0
# K = data[0]
n = Ex = Ex2 = 0.0
for x in data:
n = n + 1
Ex += x - K
Ex2 += (x - K) * (x - K)
variance = (Ex2 - (Ex * Ex) / n) / (n - 1)
# use n instead of (n-1) if want to compute the exact variance of the given data
# use (n-1) if data are samples of a larger population
return variance print(shifted_data_variance(data, data[0]))
print(shifted_data_variance(data, 0))
print(shifted_data_variance(data, -10000)) print('......') class RunningMeanStd(object):
# https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Parallel_algorithm
def __init__(self, epsilon=1e-4, shape=()):
self.mean = np.zeros(shape, 'float64')
self.var = np.ones(shape, 'float64')
self.count = epsilon def update(self, x):
batch_mean = np.mean(x, axis=0)
batch_var = np.var(x, axis=0)
batch_count = x.shape[0]
self.update_from_moments(batch_mean, batch_var, batch_count) def update_from_moments(self, batch_mean, batch_var, batch_count):
self.mean, self.var, self.count = update_mean_var_count_from_moments(
self.mean, self.var, self.count, batch_mean, batch_var, batch_count) def update_mean_var_count_from_moments(mean, var, count, batch_mean, batch_var, batch_count):
delta = batch_mean - mean
tot_count = count + batch_count new_mean = mean + delta * batch_count / tot_count
m_a = var * count
m_b = batch_var * batch_count
M2 = m_a + m_b + np.square(delta) * count * batch_count / tot_count
new_var = M2 / tot_count
new_count = tot_count return new_mean, new_var, new_count rsd = RunningMeanStd(0)
for d in range(10000):
rsd.update(data[d*100:(d+1)*100])
print(rsd.mean, rsd.var, rsd.count)
运行结果:
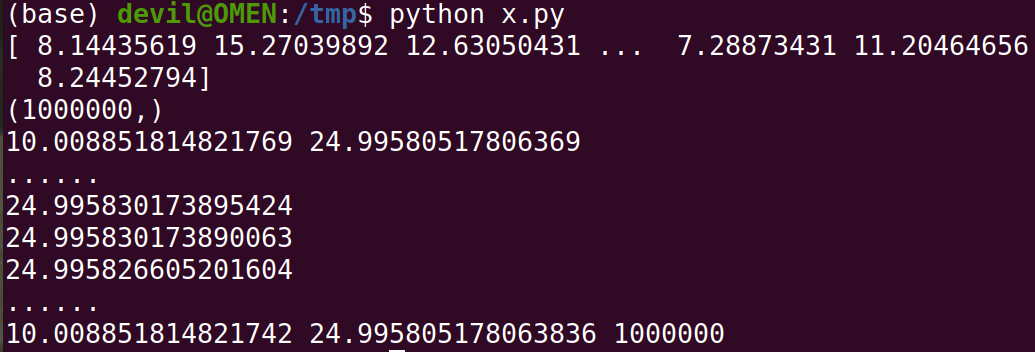
从运行结果中可以看到这种的求方差方法也可以得到很好的效果。
上面的这个baselines库中的求解方差的方法主要是适用于增量数据以集合的形式出现,在机器学习中可以看做是不断有的额batch的数据来到。
比如说我们收到的数据是一个集合增量,通过融合已有集合数据的方差、均值以及新到集合的方差、均值就可以得到合集的方差。
=======================================================
本文中的求解增量数据的方差的的方法来源:
https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Parallel_algorithm
由于这里的增强数据方差求解方法比较难以证明,因此这里也是直接拿过来进行使用。
========================
从baselines库的common/vec_env/vec_normalize.py模块看方差的近似计算方法的更多相关文章
- Python 库打包分发、setup.py 编写、混合 C 扩展打包的简易指南(转载)
转载自:http://blog.konghy.cn/2018/04/29/setup-dot-py/ Python 有非常丰富的第三方库可以使用,很多开发者会向 pypi 上提交自己的 Python ...
- 【Python】【Web.py】详细解读Python的web.py框架下的application.py模块
详细解读Python的web.py框架下的application.py模块 这篇文章主要介绍了Python的web.py框架下的application.py模块,作者深入分析了web.py的源码, ...
- 第三百零六节,Django框架,models.py模块,数据库操作——创建表、数据类型、索引、admin后台,补充Django目录说明以及全局配置文件配置
Django框架,models.py模块,数据库操作——创建表.数据类型.索引.admin后台,补充Django目录说明以及全局配置文件配置 数据库配置 django默认支持sqlite,mysql, ...
- 四 Django框架,models.py模块,数据库操作——创建表、数据类型、索引、admin后台,补充Django目录说明以及全局配置文件配置
Django框架,models.py模块,数据库操作——创建表.数据类型.索引.admin后台,补充Django目录说明以及全局配置文件配置 数据库配置 django默认支持sqlite,mysql, ...
- Python标准库:datetime 时间和日期模块 —— 时间的获取和操作详解
datetime 时间和日期模块 datetime 模块提供了以简单和复杂的方式操作日期和时间的类.虽然支持日期和时间算法,但实现的重点是有效的成员提取以进行输出格式化和操作.该模块还支持可感知时区的 ...
- web.py模块使用
web.py模块 import time import web urls=("/",'hello') class hello(): def GET(self): return (t ...
- 第三百零九节,Django框架,models.py模块,数据库操作——F和Q()运算符:|或者、&并且——queryset对象序列化
第三百零九节,Django框架,models.py模块,数据库操作——F()和Q()运算符:|或者.&并且 F()可以将数据库里的数字类型的数据,转换为可以数字类型 首先要导入 from dj ...
- 第三百零八节,Django框架,models.py模块,数据库操作——链表结构,一对多、一对一、多对多
第三百零八节,Django框架,models.py模块,数据库操作——链表结构,一对多.一对一.多对多 链表操作 链表,就是一张表的外键字段,连接另外一张表的主键字段 一对多 models.Forei ...
- 第三百零七节,Django框架,models.py模块,数据库操作——表类容的增删改查
Django框架,models.py模块,数据库操作——表类容的增删改查 增加数据 create()方法,增加数据 save()方法,写入数据 第一种方式 表类名称(字段=值) 需要save()方法, ...
- 第三百零四节,Django框架,urls.py模块,views.py模块,路由映射与路由分发以及逻辑处理——url控制器
Django框架,urls.py模块,views.py模块,路由映射与路由分发以及逻辑处理——url控制器 这一节主讲url控制器 一.urls.py模块 这个模块是配置路由映射的模块,当用户访问一个 ...
随机推荐
- (三)xpath爬取4K高清美女壁纸
功能:通过xpath爬取彼岸图网的高清美女壁纸 url = 'http://pic.netbian.com/4kmeinv/' 1. 通过url请求整张页面的数据 2.通过页面的标签定位图片所在的位置 ...
- 一个常见的 JavaScript 解构陷阱
在日常的 JavaScript 编码中,我们经常使用解构语法来提取对象中的属性.假设我们有一个名为 fetchResult 的对象,代表从接口返回的数据,其中包含一个字段名为 data. const ...
- 如何判断APP页面是原生还是H5
如何判断APP页面是原生还是H5 1.打开设置,搜索"开发者选项",点击"开发者选项" 华为手机进入开发者模式方法 1.打开华为手机的[设置],找到并点击进入[ ...
- K-means聚类是一种非常流行的聚类算法
K-means聚类是一种非常流行的聚类算法,它的目标是将n个样本划分到k个簇中,使得每个样本属于与其最近的均值(即簇中心)对应的簇,从而使得簇内的方差最小化.K-means聚类算法简单.易于实现,并且 ...
- BST-splay板子 - 维护一个分裂和合并的序列
splay 均摊复杂度 \(O(\log n)\) 证明: https://www.cnblogs.com/Mr-Spade/p/9715203.html 我这个 splay 有两个哨兵节点,分别是1 ...
- 推荐一款基于业务行为驱动开发(BDD)测试框架:Cucumber!
大家好,我是狂师. 今天给大家介绍一款行为驱动开发测试框架:Cucumber. 1.介绍 Cucumber是一个行为驱动开发(BDD)工具,它结合了文本描述和自动化测试脚本.它使用一种名为Gherki ...
- Linux修改dmesg 显示大小
背景 由于在调试的时候没有串口,而通过dmesg打印的内容发现其中有截断的现象. 因此为了方便调试.将有关的缓冲区加大. 原理 Linux内核中打印内核消息时用到了一个环形缓冲区. 这个缓冲区的大小由 ...
- ENVI无缝镶嵌、拼接栅格数据的方法
本文介绍基于ENVI软件,利用"Seamless Mosaic"工具实现栅格遥感影像无缝镶嵌的操作. 在遥感图像镶嵌拼接:ENVI的Pixel Based Mosaicki ...
- VulnHub_DC-1渗透流程
DC-1 DC-1 是一个专门建造的易受攻击的实验室,目的是在渗透测试领域获得经验. 它旨在为初学者提供挑战,但它的难易程度取决于您的技能和知识,以及您的学习能力. 要成功完成此挑战,您将需要 Lin ...
- yb课堂之自定义异常和配置 《五》
开发自定义异常和配置 自定义异常 继承RuntimeException 开发异常处理器ExceptionHandle YBException.java package net.ybclass.onli ...