从baselines库的common/vec_env/vec_normalize.py模块看方差的近似计算方法
在baselines库的common/vec_env/vec_normalize.py中计算方差的调用方法为:
RunningMeanStd
同时该计算函数的解释也一并给出了:
https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Parallel_algorithm
也就是说这个函数是在对方差进行近似计算,找了下中文的这方面的资料:

上图来自:https://baijiahao.baidu.com/s?id=1715371851391883847&wfr=spider&for=pc
可以看到在wiki上给出了python的计算代码:


def shifted_data_variance(data):
if len(data) < 2:
return 0.0
K = data[0]
n = Ex = Ex2 = 0.0
for x in data:
n = n + 1
Ex += x - K
Ex2 += (x - K) * (x - K)
variance = (Ex2 - (Ex * Ex) / n) / (n - 1)
# use n instead of (n-1) if want to compute the exact variance of the given data
# use (n-1) if data are samples of a larger population
return variance
该代码的计算公式为:
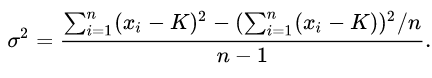
也就是说在样本数据较大的情况下可以使用该计算方法来近似计算样本方差。
给出自己的测试代码:
import numpy as np data = np.random.normal(10, 5, 100000000) print(data)
print(data.shape)
print(np.mean(data), np.var(data)) print('......')
def shifted_data_variance(data, K):
if len(data) < 2:
return 0.0
# K = data[0]
n = Ex = Ex2 = 0.0
for x in data:
n = n + 1
Ex += x - K
Ex2 += (x - K) * (x - K)
variance = (Ex2 - (Ex * Ex) / n) / (n - 1)
# use n instead of (n-1) if want to compute the exact variance of the given data
# use (n-1) if data are samples of a larger population
return variance print(shifted_data_variance(data, data[0]))
print(shifted_data_variance(data, 0))
print(shifted_data_variance(data, -10000))
运行结果:
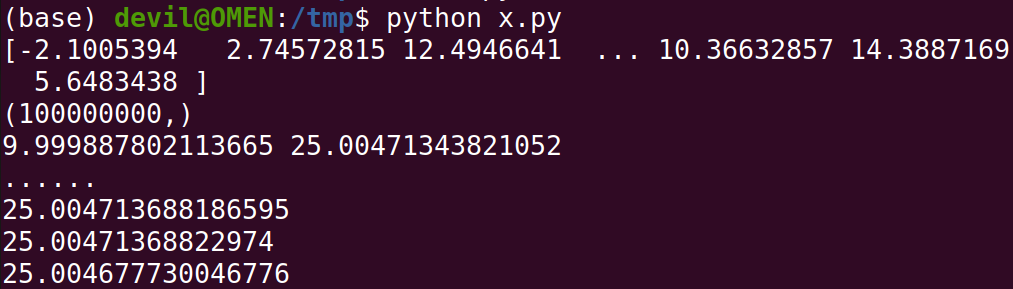
可以知道如果K值越接近真实的均值那么所得到的近似方差会更加逼近真实的样本方差。
那么如果样本数据较少的情况呢,上面的测试使用的是100000000个数据样本,如果是100个呢,给出测试:
代码:
import numpy as np data = np.random.normal(10, 5, 100) print(data)
print(data.shape)
print(np.mean(data), np.var(data)) print('......')
def shifted_data_variance(data, K):
if len(data) < 2:
return 0.0
# K = data[0]
n = Ex = Ex2 = 0.0
for x in data:
n = n + 1
Ex += x - K
Ex2 += (x - K) * (x - K)
variance = (Ex2 - (Ex * Ex) / n) / (n - 1)
# use n instead of (n-1) if want to compute the exact variance of the given data
# use (n-1) if data are samples of a larger population
return variance print(shifted_data_variance(data, data[0]))
print(shifted_data_variance(data, 0))
print(shifted_data_variance(data, -10000))
运行结果:
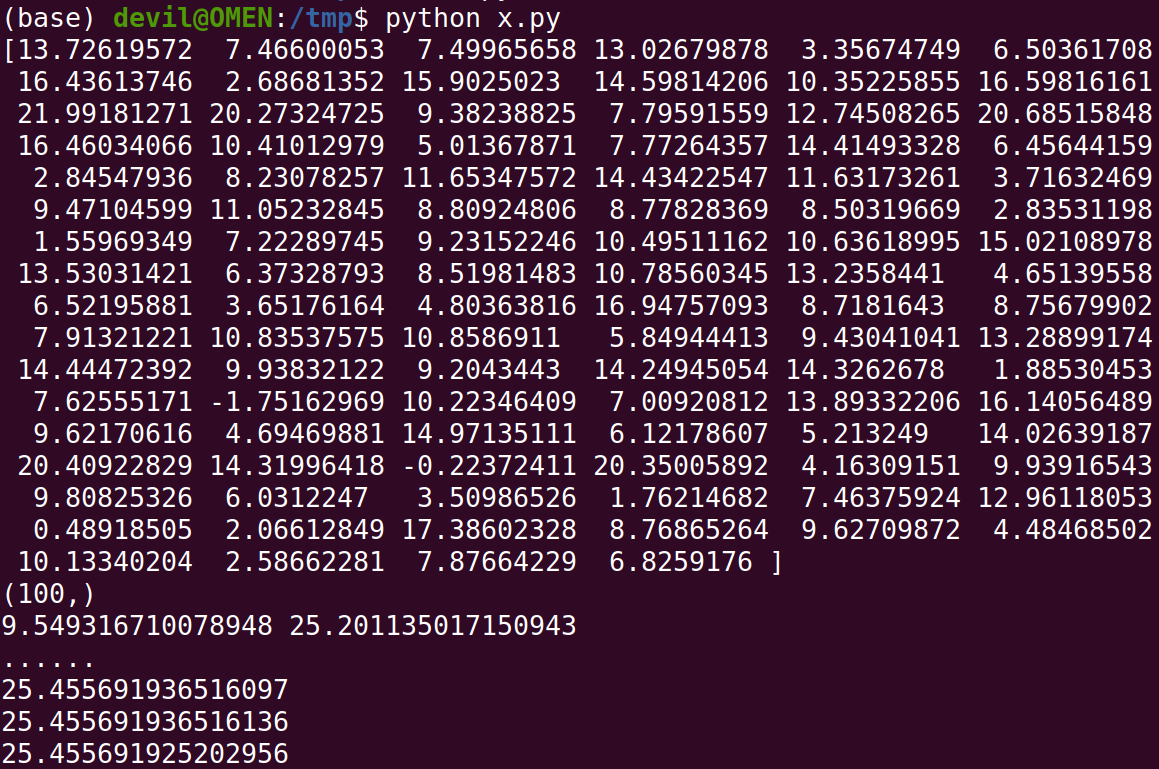
可以看到和数据样本较大规模的情况一样,该方法依然可以得到非常好的近似方差,同时K值越接近真实均值近似方差就越接近真实方差,不过这里可以看到这里的差别也是在小数点后九位,因此这个差距可以看做没有。
总结:
这个计算方差的最大好处就是可以在不计算样本均值的情况下就直接计算样本方差,该种计算方法非常适合样本数据量在不断增加的情况,不过这里的样本数据量增加也是在服从同一分布的条件下的。
比如我们需要不断的从一个数据分布中获得样本并获得分布的方差,如果不适用这种近似计算方差的方法每当我们得到一个新的样本都需要重新计算样本的方差,这样就会成几何倍数的增加计算量,毕竟标准的方差计算是需要遍历所有样本数据的。
给出标准的方差计算公式:
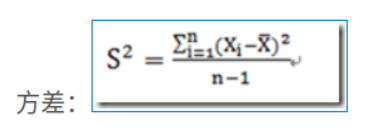
图片源自:https://www.cnblogs.com/devilmaycry812839668/p/16072130.html
不得不说算法设计可以有效提升计算性能。
================================================
不过根据wiki的说明可以知道,上述的方法在计算过程中设计到大量的求和sum计算,而求和计算由于会由于浮点数计算时的精度取舍从而影响最终的结果精度:
This algorithm is numerically stable if n is small.[1][4] However, the results of both of these simple algorithms ("naïve" and "two-pass") can depend inordinately on the ordering of the data and can give poor results for very large data sets due to repeated roundoff error in the accumulation of the sums. Techniques such as compensated summation can be used to combat this error to a degree.
================================================
在baselines库中使用的求方差的方法为:

也就是baselines中的函数:
class RunningMeanStd(object):
# https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Parallel_algorithm
def __init__(self, epsilon=1e-4, shape=()):
self.mean = np.zeros(shape, 'float64')
self.var = np.ones(shape, 'float64')
self.count = epsilon def update(self, x):
batch_mean = np.mean(x, axis=0)
batch_var = np.var(x, axis=0)
batch_count = x.shape[0]
self.update_from_moments(batch_mean, batch_var, batch_count) def update_from_moments(self, batch_mean, batch_var, batch_count):
self.mean, self.var, self.count = update_mean_var_count_from_moments(
self.mean, self.var, self.count, batch_mean, batch_var, batch_count) def update_mean_var_count_from_moments(mean, var, count, batch_mean, batch_var, batch_count):
delta = batch_mean - mean
tot_count = count + batch_count new_mean = mean + delta * batch_count / tot_count
m_a = var * count
m_b = batch_var * batch_count
M2 = m_a + m_b + np.square(delta) * count * batch_count / tot_count
new_var = M2 / tot_count
new_count = tot_count return new_mean, new_var, new_count
使用自己的测试代码:
import numpy as np data = np.random.normal(10, 5, 1000000) print(data)
print(data.shape)
print(np.mean(data), np.var(data)) print('......')
def shifted_data_variance(data, K):
if len(data) < 2:
return 0.0
# K = data[0]
n = Ex = Ex2 = 0.0
for x in data:
n = n + 1
Ex += x - K
Ex2 += (x - K) * (x - K)
variance = (Ex2 - (Ex * Ex) / n) / (n - 1)
# use n instead of (n-1) if want to compute the exact variance of the given data
# use (n-1) if data are samples of a larger population
return variance print(shifted_data_variance(data, data[0]))
print(shifted_data_variance(data, 0))
print(shifted_data_variance(data, -10000)) print('......') class RunningMeanStd(object):
# https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Parallel_algorithm
def __init__(self, epsilon=1e-4, shape=()):
self.mean = np.zeros(shape, 'float64')
self.var = np.ones(shape, 'float64')
self.count = epsilon def update(self, x):
batch_mean = np.mean(x, axis=0)
batch_var = np.var(x, axis=0)
batch_count = x.shape[0]
self.update_from_moments(batch_mean, batch_var, batch_count) def update_from_moments(self, batch_mean, batch_var, batch_count):
self.mean, self.var, self.count = update_mean_var_count_from_moments(
self.mean, self.var, self.count, batch_mean, batch_var, batch_count) def update_mean_var_count_from_moments(mean, var, count, batch_mean, batch_var, batch_count):
delta = batch_mean - mean
tot_count = count + batch_count new_mean = mean + delta * batch_count / tot_count
m_a = var * count
m_b = batch_var * batch_count
M2 = m_a + m_b + np.square(delta) * count * batch_count / tot_count
new_var = M2 / tot_count
new_count = tot_count return new_mean, new_var, new_count rsd = RunningMeanStd(0)
for d in range(10000):
rsd.update(data[d*100:(d+1)*100])
print(rsd.mean, rsd.var, rsd.count)
运行结果:
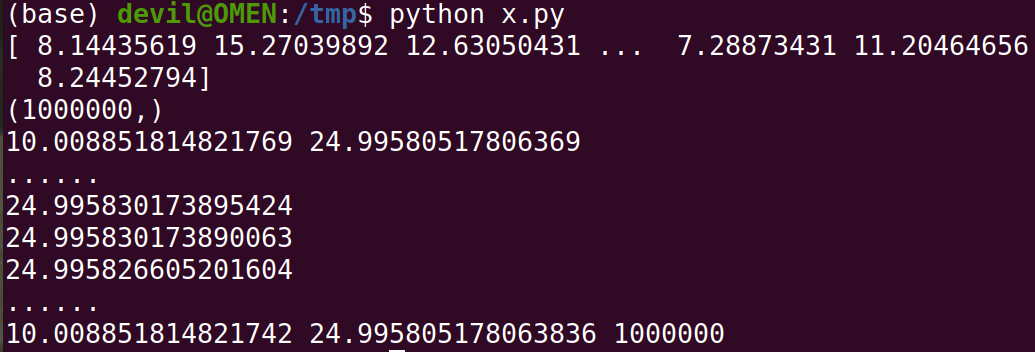
从运行结果中可以看到这种的求方差方法也可以得到很好的效果。
上面的这个baselines库中的求解方差的方法主要是适用于增量数据以集合的形式出现,在机器学习中可以看做是不断有的额batch的数据来到。
比如说我们收到的数据是一个集合增量,通过融合已有集合数据的方差、均值以及新到集合的方差、均值就可以得到合集的方差。
=======================================================
本文中的求解增量数据的方差的的方法来源:
https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance#Parallel_algorithm
由于这里的增强数据方差求解方法比较难以证明,因此这里也是直接拿过来进行使用。
========================
从baselines库的common/vec_env/vec_normalize.py模块看方差的近似计算方法的更多相关文章
- Python 库打包分发、setup.py 编写、混合 C 扩展打包的简易指南(转载)
转载自:http://blog.konghy.cn/2018/04/29/setup-dot-py/ Python 有非常丰富的第三方库可以使用,很多开发者会向 pypi 上提交自己的 Python ...
- 【Python】【Web.py】详细解读Python的web.py框架下的application.py模块
详细解读Python的web.py框架下的application.py模块 这篇文章主要介绍了Python的web.py框架下的application.py模块,作者深入分析了web.py的源码, ...
- 第三百零六节,Django框架,models.py模块,数据库操作——创建表、数据类型、索引、admin后台,补充Django目录说明以及全局配置文件配置
Django框架,models.py模块,数据库操作——创建表.数据类型.索引.admin后台,补充Django目录说明以及全局配置文件配置 数据库配置 django默认支持sqlite,mysql, ...
- 四 Django框架,models.py模块,数据库操作——创建表、数据类型、索引、admin后台,补充Django目录说明以及全局配置文件配置
Django框架,models.py模块,数据库操作——创建表.数据类型.索引.admin后台,补充Django目录说明以及全局配置文件配置 数据库配置 django默认支持sqlite,mysql, ...
- Python标准库:datetime 时间和日期模块 —— 时间的获取和操作详解
datetime 时间和日期模块 datetime 模块提供了以简单和复杂的方式操作日期和时间的类.虽然支持日期和时间算法,但实现的重点是有效的成员提取以进行输出格式化和操作.该模块还支持可感知时区的 ...
- web.py模块使用
web.py模块 import time import web urls=("/",'hello') class hello(): def GET(self): return (t ...
- 第三百零九节,Django框架,models.py模块,数据库操作——F和Q()运算符:|或者、&并且——queryset对象序列化
第三百零九节,Django框架,models.py模块,数据库操作——F()和Q()运算符:|或者.&并且 F()可以将数据库里的数字类型的数据,转换为可以数字类型 首先要导入 from dj ...
- 第三百零八节,Django框架,models.py模块,数据库操作——链表结构,一对多、一对一、多对多
第三百零八节,Django框架,models.py模块,数据库操作——链表结构,一对多.一对一.多对多 链表操作 链表,就是一张表的外键字段,连接另外一张表的主键字段 一对多 models.Forei ...
- 第三百零七节,Django框架,models.py模块,数据库操作——表类容的增删改查
Django框架,models.py模块,数据库操作——表类容的增删改查 增加数据 create()方法,增加数据 save()方法,写入数据 第一种方式 表类名称(字段=值) 需要save()方法, ...
- 第三百零四节,Django框架,urls.py模块,views.py模块,路由映射与路由分发以及逻辑处理——url控制器
Django框架,urls.py模块,views.py模块,路由映射与路由分发以及逻辑处理——url控制器 这一节主讲url控制器 一.urls.py模块 这个模块是配置路由映射的模块,当用户访问一个 ...
随机推荐
- k8s配置文件管理
1.为什么要用configMap ConfigMap是一种用于存储应用所需配置信息的资源类型,用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件. 通过ConfigMap可以方便的 ...
- AnnotationTransactionAttributeSource is only available on Java 1.5 and higher和windows同时安装jdk7和jdk8
AnnotationTransactionAttributeSource is only available on Java 1.5 and higher和windows同时安装jdk7和jdk8 出 ...
- WIndow Server 2019 服务器 MinIO下载并IIS配置反向代理
1.官网下载并配置 下载MinIO Serve地址(不需要安装,放在目录就行) https://dl.min.io/server/minio/release/windows-amd64/minio.e ...
- 制作Jdk镜像
本文介绍用Dockerfile的方式构建Jdk镜像,请保证安装了Docker环境. 首先创建/opt/jdk目录,后续步骤都在该目录下进行操作. 准备好Jdk安装文件,放到/opt/jdk目录下. 编 ...
- R 语言入门学习笔记:软件安装踩坑记录——删除所有包以及彻底解决库包被安装到 C 盘用户目录下的问题,以及一些其他需要注意的点
目录 R 语言入门学习笔记:软件安装踩坑记录--删除所有包以及彻底解决库包被安装到 C 盘用户目录下的问题,以及一些其他需要注意的点 软件版本及环境 遇到的问题描述 问题的分析和探究 最终的解决方案 ...
- fastadmin的导出到excel功能
正常的excel导出没什么问题,最近一直头疼的是怎么导出数据中包含图片,并且图片还是数组?????by user 悦悦 https://www.cnblogs.com/nuanai 1.导出的exce ...
- ansible v2.9.9离线安装脚本
链接:https://pan.baidu.com/s/18uxyWWyJ39i1mJJ1hb8zww?pwd=QWSC 提取码:QWSC
- EasyExcel 无法读取图片?用poi写了一个工具类
在平时的开发中,经常要开发 Excel 的导入导出功能.一般使用 poi 或者 EasyExcel 开发,使用 poi 做 excel 比较复杂,大部分开发都会使用 EasyExcel 因为一行代码就 ...
- MSSQL慢查询查询与统计
查询MSSQL慢查询: SELECT TOP 20 TEXT AS 'SQL Statement',last_execution_time AS 'Last Execution Time' ,(tot ...
- Js 中的数组
在js 中,数组就是对象,除了可以使用字面量语法[...]来声明数组外,它和其它对象没有什么区别.当创建一个数组['a', 'b', 'c']时,内部的实现形式如下: { length: 3, ...