用 Hugging Face 推理端点部署 LLM
开源的 LLM,如 Falcon、(Open-)LLaMA、X-Gen、StarCoder 或 RedPajama,近几个月来取得了长足的进展,能够在某些用例中与闭源模型如 ChatGPT 或 GPT4 竞争。然而,有效且优化地部署这些模型仍然是一个挑战。
在这篇博客文章中,我们将向你展示如何将开源 LLM 部署到 Hugging Face Inference Endpoints,这是我们的托管 SaaS 解决方案,可以轻松部署模型。此外,我们还将教你如何流式传输响应并测试我们端点的性能。那么,让我们开始吧!
在我们开始之前,让我们回顾一下关于推理端点的知识。
什么是 Hugging Face 推理端点
Hugging Face 推理端点 提供了一种简单、安全的方式来部署用于生产的机器学习模型。推理端点使开发人员和数据科学家都能够创建 AI 应用程序而无需管理基础设施: 简化部署过程为几次点击,包括使用自动扩展处理大量请求,通过缩减到零来降低基础设施成本,并提供高级安全性。
以下是 LLM 部署的一些最重要的特性:
- 简单部署: 只需几次点击即可将模型部署为生产就绪的 API,无需处理基础设施或 MLOps。
- 成本效益: 利用自动缩减到零的能力,通过在端点未使用时缩减基础设施来降低成本,同时根据端点的正常运行时间付费,确保成本效益。
- 企业安全性: 在仅通过直接 VPC 连接可访问的安全离线端点中部署模型,由 SOC2 类型 2 认证支持,并提供 BAA 和 GDPR 数据处理协议,以增强数据安全性和合规性。
- LLM 优化: 针对 LLM 进行了优化,通过自定义 transformers 代码和 Flash Attention 来实现高吞吐量和低延迟。
- 全面的任务支持: 开箱即用地支持 Transformers、Sentence-Transformers 和 Diffusers 任务和模型,并且易于定制以启用高级任务,如说话人分离或任何机器学习任务和库。
你可以在 https://ui.endpoints.huggingface.co/ 开始使用推理端点。
1. 怎样部署 Falcon 40B instruct
要开始使用,你需要使用具有文件付款方式的用户或组织帐户登录 (你可以在 这里 添加一个),然后访问推理端点 https://ui.endpoints.huggingface.co。
然后,点击“新建端点”。选择仓库、云和区域,调整实例和安全设置,并在我们的情况下部署 tiiuae/falcon-40b-instruct 。

推理端点会根据模型大小建议实例类型,该类型应足够大以运行模型。这里是 4x NVIDIA T4 GPU。为了获得 LLM 的最佳性能,请将实例更改为 GPU [xlarge] · 1x Nvidia A100 。
注意: 如果无法选择实例类型,则需要 联系我们 并请求实例配额。
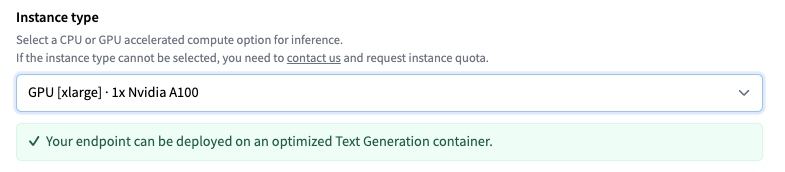
然后,你可以点击“创建端点”来部署模型。10 分钟后,端点应该在线并可用于处理请求。
2. 测试 LLM 端点
端点概览提供了对推理小部件的访问,可以用来手动发送请求。这使你可以使用不同的输入快速测试你的端点并与团队成员共享。这些小部件不支持参数 - 在这种情况下,这会导致“较短的”生成。
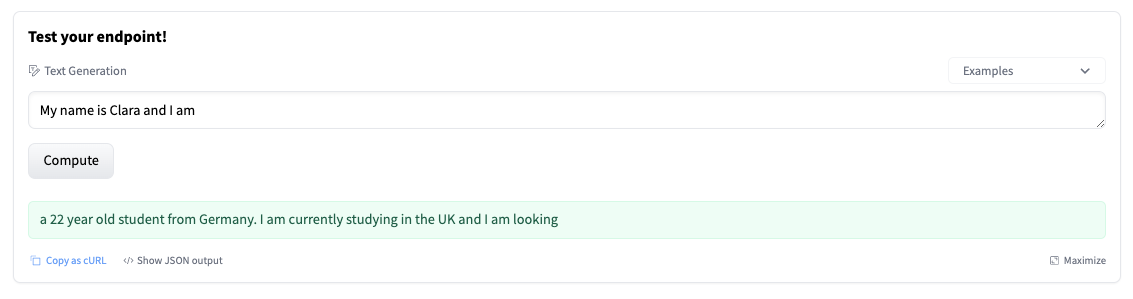
该小部件还会生成一个你可以使用的 cURL 命令。只需添加你的 hf_xxx 并进行测试。
curl https://j4xhm53fxl9ussm8.us-east-1.aws.endpoints.huggingface.cloud \
-X POST \
-d '{"inputs":"Once upon a time,"}' \
-H "Authorization: Bearer <hf_token>" \
-H "Content-Type: application/json"
你可以使用不同的参数来控制生成,将它们定义在有效负载的 parameters 属性中。截至目前,支持以下参数:
temperature: 控制模型中的随机性。较低的值会使模型更确定性,较高的值会使模型更随机。默认值为 1.0。max_new_tokens: 要生成的最大 token 数。默认值为 20,最大值为 512。repetition_penalty: 控制重复的可能性。默认值为null。seed: 用于随机生成的种子。默认值为null。stop: 停止生成的 token 列表。当生成其中一个 token 时,生成将停止。top_k: 保留概率最高的词汇表 token 数以进行 top-k 过滤。默认值为null,禁用 top-k 过滤。top_p: 保留核心采样的参数最高概率词汇表 token 的累积概率,默认为nulldo_sample: 是否使用采样; 否则使用贪婪解码。默认值为false。best_of: 生成 best_of 序列并返回一个最高 token 的 logprobs,默认为null。details: 是否返回有关生成的详细信息。默认值为false。return_full_text: 是否返回完整文本或仅返回生成部分。默认值为false。truncate: 是否将输入截断到模型的最大长度。默认值为true。typical_p: token 的典型概率。默认值为null。watermark: 用于生成的水印。默认值为false。
3. 用 javascript 和 python 进行流响应传输
使用 LLM 请求和生成文本可能是一个耗时且迭代的过程。改善用户体验的一个好方法是在生成 token 时将它们流式传输给用户。下面是两个使用 Python 和 JavaScript 流式传输 token 的示例。对于 Python,我们将使用 Text Generation Inference 的客户端,对于 JavaScript,我们将使用 HuggingFace.js 库。
使用 Python 流式传输请求
首先,你需要安装 huggingface_hub 库:
pip install -U huggingface_hub
我们可以创建一个 InferenceClient ,提供我们的端点 URL 和凭据以及我们想要使用的超参数。
from huggingface_hub import InferenceClient
# HF Inference Endpoints parameter
endpoint_url = "https://YOUR_ENDPOINT.endpoints.huggingface.cloud"
hf_token = "hf_YOUR_TOKEN"
# Streaming Client
client = InferenceClient(endpoint_url, token=hf_token)
# generation parameter
gen_kwargs = dict(
max_new_tokens=512,
top_k=30,
top_p=0.9,
temperature=0.2,
repetition_penalty=1.02,
stop_sequences=["\nUser:", "<|endoftext|>", "</s>"],
)
# prompt
prompt = "What can you do in Nuremberg, Germany? Give me 3 Tips"
stream = client.text_generation(prompt, stream=True, details=True, **gen_kwargs)
# yield each generated token
for r in stream:
# skip special tokens
if r.token.special:
continue
# stop if we encounter a stop sequence
if r.token.text in gen_kwargs["stop_sequences"]:
break
# yield the generated token
print(r.token.text, end = "")
# yield r.token.text
将 print 命令替换为 yield 或你想要将 token 流式传输到的函数。

使用 Javascript 流式传输请求
首先你需要安装 @huggingface/inference 库
npm install @huggingface/inference
我们可以创建一个 HfInferenceEndpoint ,提供我们的端点 URL 和凭据以及我们想要使用的超参数。
import { HfInferenceEndpoint } from '@huggingface/inference'
const hf = new HfInferenceEndpoint('https://YOUR_ENDPOINT.endpoints.huggingface.cloud', 'hf_YOUR_TOKEN')
//generation parameter
const gen_kwargs = {
max_new_tokens: 512,
top_k: 30,
top_p: 0.9,
temperature: 0.2,
repetition_penalty: 1.02,
stop_sequences: ['\nUser:', '<|endoftext|>', '</s>'],
}
// prompt
const prompt = 'What can you do in Nuremberg, Germany? Give me 3 Tips'
const stream = hf.textGenerationStream({ inputs: prompt, parameters: gen_kwargs })
for await (const r of stream) {
// # skip special tokens
if (r.token.special) {
continue
}
// stop if we encounter a stop sequence
if (gen_kwargs['stop_sequences'].includes(r.token.text)) {
break
}
// yield the generated token
process.stdout.write(r.token.text)
}
将 process.stdout 调用替换为 yield 或你想要将 token 流式传输到的函数。
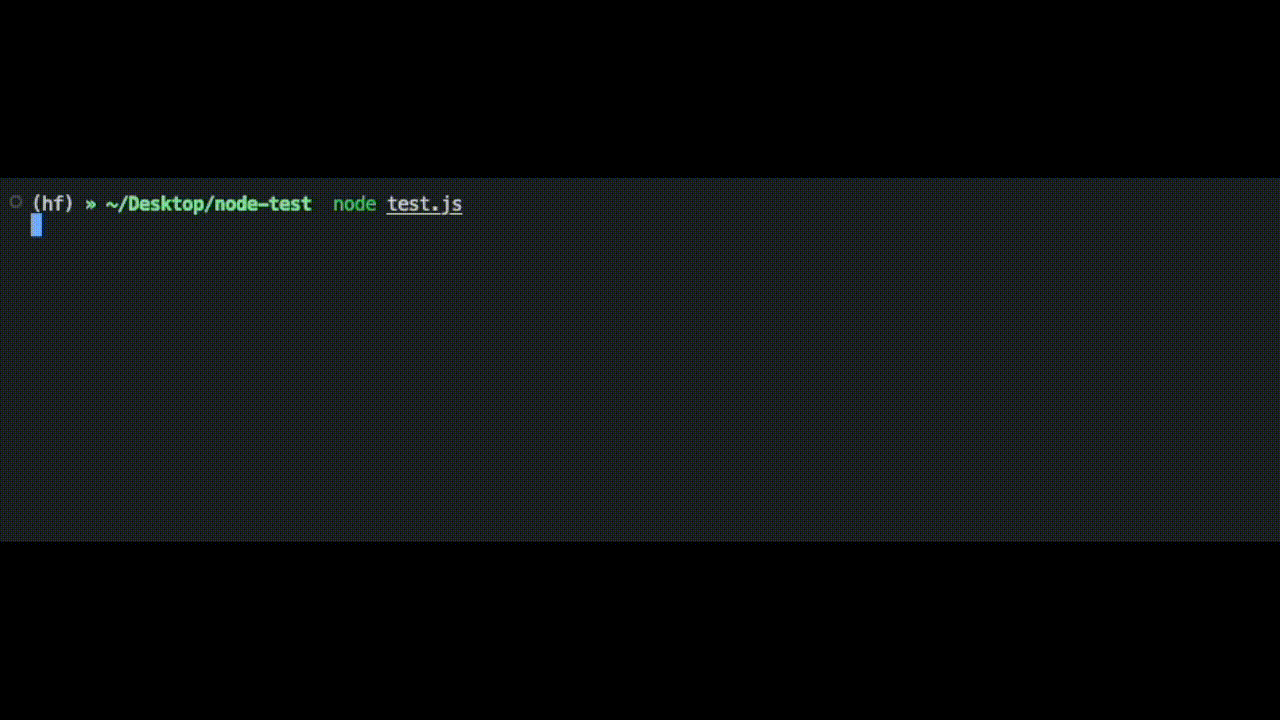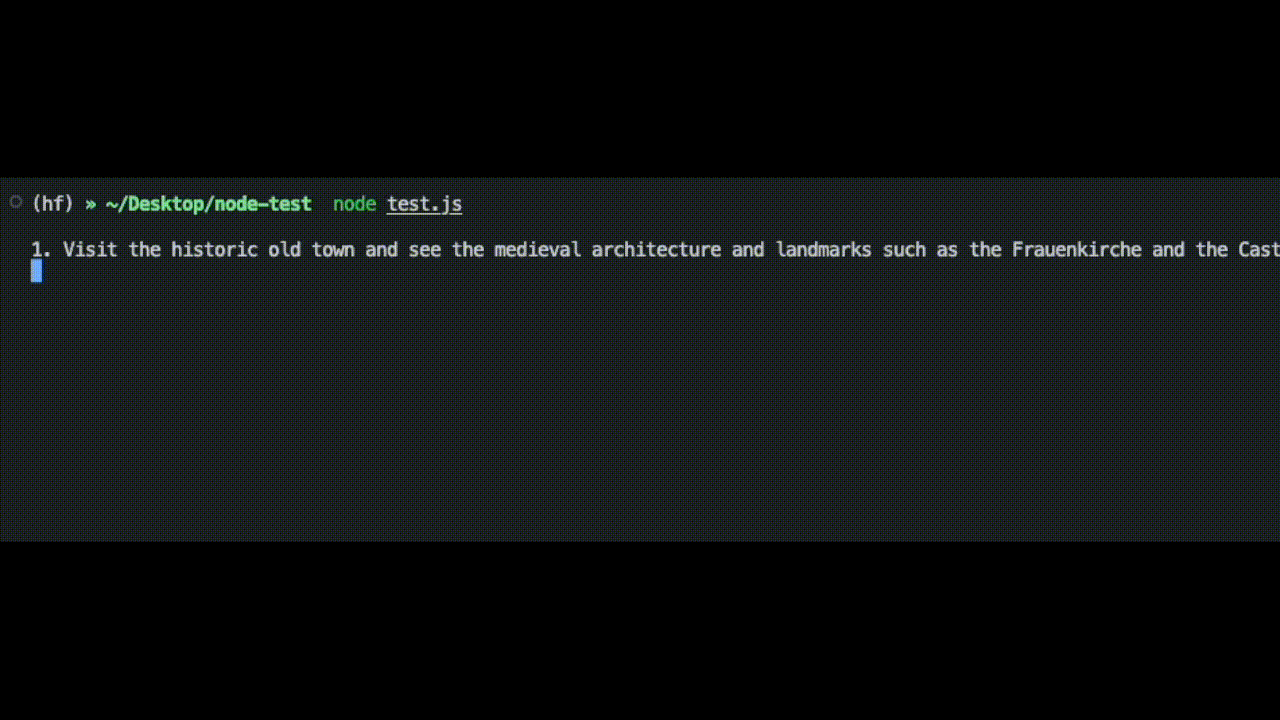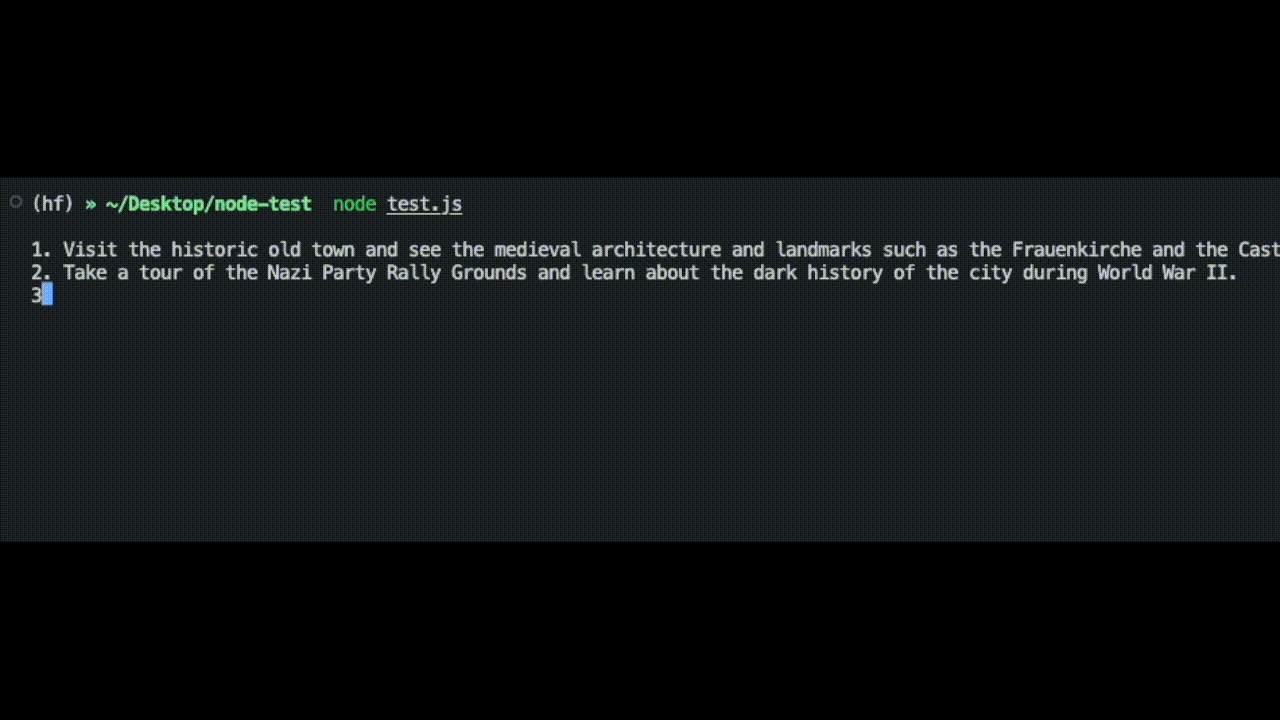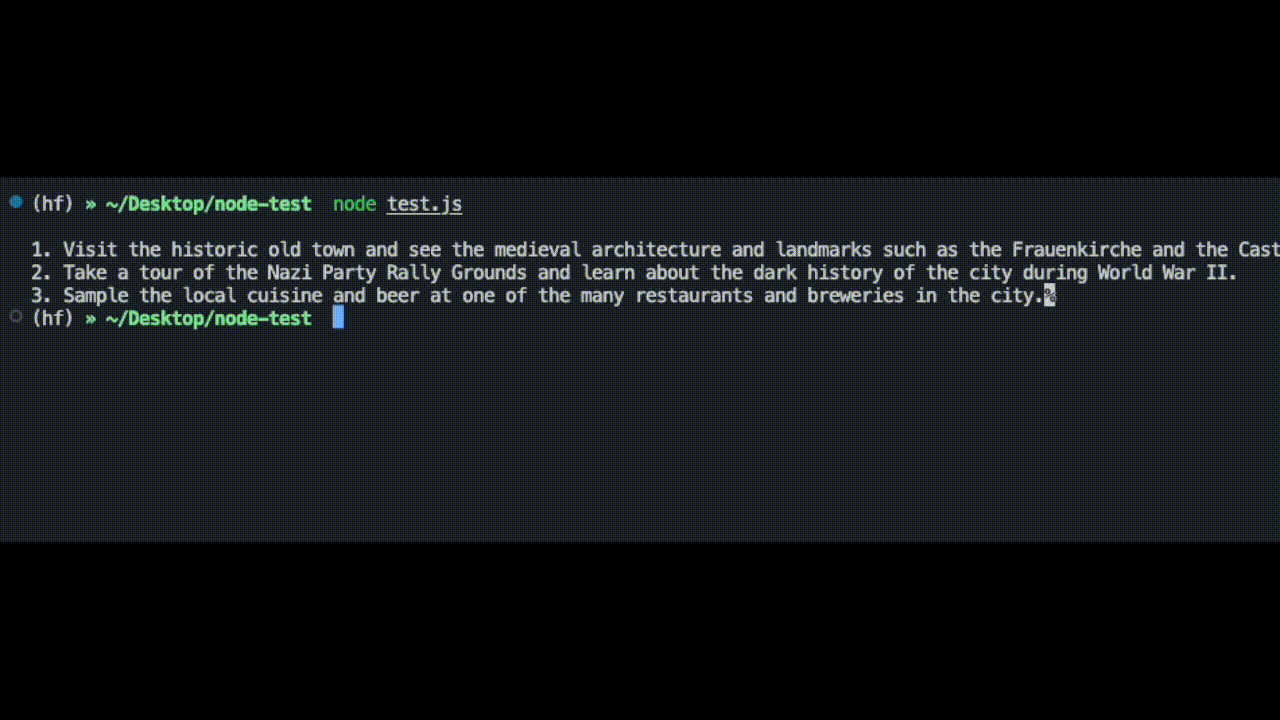
结论
在这篇博客文章中,我们向你展示了如何使用 Hugging Face 推理端点部署开源 LLM,如何使用高级参数控制文本生成,以及如何将响应流式传输到 Python 或 JavaScript 客户端以提高用户体验。通过使用 Hugging Face 推理端点,你可以只需几次点击即可将模型部署为生产就绪的 API,通过自动缩减到零来降低成本,并在 SOC2 类型 2 认证的支持下将模型部署到安全的离线端点。
感谢你的阅读!如果你有任何问题,请随时在 Twitter 或 LinkedIn 上联系我。
英文原文: https://hf.co/blog/inference-endpoints-llm
作者: Philipp Schmid
译者: innovation64
审校/排版: zhongdongy (阿东)
用 Hugging Face 推理端点部署 LLM的更多相关文章
- Hugging Face - 推理(Inference)解决方案
每天,开发人员和组织都在使用 Hugging Face 平台上托管的模型,将想法变成概念验证(proof-of-concept)的 demo,再将 demo 变成生产级的应用. Transformer ...
- 利用KubeEdge在A500部署边缘推理任务
利用KubeEdge在A500部署边缘推理任务 目 录 1 环境介绍... 1 2 云端环境部署... 2 2.1 在master节点安装Docker和k8S (ubuntu) 2 2.1.1 ...
- Optimum + ONNX Runtime: 更容易、更快地训练你的 Hugging Face 模型
介绍 基于语言.视觉和语音的 Transformer 模型越来越大,以支持终端用户复杂的多模态用例.增加模型大小直接影响训练这些模型所需的资源,并随着模型大小的增加而扩展它们.Hugging Face ...
- Hugging News #0414: Attention 在多模态情景中的应用、Unity API 以及 Gradio 主题构建器
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- Paddle Inference原生推理库
Paddle Inference原生推理库 深度学习一般分为训练和推理两个部分,训练是神经网络"学习"的过程,主要关注如何搜索和求解模型参数,发现训练数据中的规律,生成模型.有了训 ...
- Windows10下yolov8 tensorrt模型加速部署【实战】
Windows10下yolov8 tensorrt模型加速部署[实战] TensorRT-Alpha基于tensorrt+cuda c++实现模型end2end的gpu加速,支持win10.linux ...
- Win10下yolov8 tensorrt模型加速部署【实战】
Win10下yolov8 tensorrt模型加速部署[实战] TensorRT-Alpha基于tensorrt+cuda c++实现模型end2end的gpu加速,支持win10.linux,在20 ...
- 零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程. 1.通用文本分类技术UTC介绍 本项目提供基于通用文本分类 UTC(Universal Text C ...
- 云中树莓派(5):利用 AWS IoT Greengrass 进行 IoT 边缘计算
云中树莓派(1):环境准备 云中树莓派(2):将传感器数据上传到AWS IoT 并利用Kibana进行展示 云中树莓派(3):通过 AWS IoT 控制树莓派上的Led 云中树莓派(4):利用声音传感 ...
- Amazon SageMaker和NVIDIA NGC加速AI和ML工作流
Amazon SageMaker和NVIDIA NGC加速AI和ML工作流 从自动驾驶汽车到药物发现,人工智能正成为主流,并迅速渗透到每个行业.但是,开发和部署AI应用程序是一项具有挑战性的工作.该过 ...
随机推荐
- [双目视差] 单双目MATLAB 相机标定(二)双目摄像机标定
文章目录 单双目MATLAB 相机标定(二)双目摄像机标定 一.环境准备 二.标定过程 单双目MATLAB 相机标定(二)双目摄像机标定 一.环境准备 MATLAB R2014a+windows7 6 ...
- 2023-05-03:给你一棵 二叉树 的根节点 root ,树中有 n 个节点 每个节点都可以被分配一个从 1 到 n 且互不相同的值 另给你一个长度为 m 的数组 queries 你必须在树上执行
2023-05-03:给你一棵 二叉树 的根节点 root ,树中有 n 个节点 每个节点都可以被分配一个从 1 到 n 且互不相同的值 另给你一个长度为 m 的数组 queries 你必须在树上执行 ...
- CF1037G A Game on Strings Sol
有趣题. 首先"分成若干个互不相干的子串"是子游戏的定义,可以用 SG 函数处理. 然而接下来试着打了半个多小时的表,没有找到任何规律. 但是发现 SG 函数的状态转移是很简单的. ...
- Unity开发Hololens2—交互发布配置
Unity开发Hololens2-交互发布配置 环境配置 unity2021.3.15f visual studio 2019 pro MRTK 2.8.3 OpenXR 1.8.0 Hololens ...
- 用Python语言进行时间序列ARIMA模型分析
应用时间序列 时间序列分析是一种重要的数据分析方法,应用广泛.以下列举了几个时间序列分析的应用场景: 1.经济预测:时间序列分析可以用来分析经济数据,预测未来经济趋势和走向.例如,利用历史股市数据和经 ...
- 2022-12-13:游戏玩法分析 I。写一条 SQL 查询语句获取每位玩家 第一次登陆平台的日期。 +-----------+-------------+ | player_id | first_l
2022-12-13:游戏玩法分析 I.写一条 SQL 查询语句获取每位玩家 第一次登陆平台的日期. ±----------±------------+ | player_id | first_log ...
- 2021-01-18:java中,HashMap的创建流程是什么?
福哥答案2021-01-18: jdk1.7创建流程:三种构造器.1.初始容量不能为负数,默认16.2.初始容量大于最大容量时,初始容量等于最大容量.3.负载因子必须大于0,默认0.75.4.根据初始 ...
- 2021-07-08:股票问题5。给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票)
2021-07-08:股票问题5.给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 .设计一个算法计算出最大利润.在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票) ...
- 2021-10-20:分数到小数。给定两个整数,分别表示分数的分子numerator和分母denominator,以字符串形式返回小数。如果小数部分为循环小数,则将循环的部分括在括号内。输入: num
2021-10-20:分数到小数.给定两个整数,分别表示分数的分子numerator和分母denominator,以字符串形式返回小数.如果小数部分为循环小数,则将循环的部分括在括号内.输入: num ...
- NodeJs 实践之他说
NodeJs 实践之他说 作为前端,我们知道 node 在构建方面是成功的,我们也听说过全栈,那么 node 是否能应用在企业级的后端?一起来看一下腾讯视频的 NodeJs 改造. Tip: 故事大概 ...