17 模块subprocess、re
1. subprocess模块
1.1 概念
subprocess模块启动一个新进程,并连接到它们的输入/输出/错误管道,从而获取返回值
简单理解:可以远程连接电脑(socket模块)
1.2 Popen方法
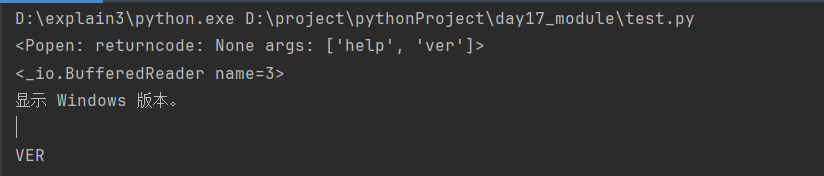
import subprocess res = subprocess.Popen(['help', 'ver'], # windows中执行的命令要放在列表里面,命令单词之间用逗号隔开
shell=True, # Windows和Linux都填写True
stdout=subprocess.PIPE, # 存储正确结果的返回值
stderr=subprocess.PIPE) # 存储错误结果的返回值
print(res) # <Popen: returncode: None args: ['help']>
print(res.stdout) # <_io.BufferedReader name=3>
print(res.stdout.read().decode('gbk')) # Linux默认编码格式是utf-8,国内Windows默认编码格式是gbk
subprocess模块首先推荐的是run方法,更高级的方法使用Popen接口
1.3 run方法
# run参数的含义
# *popenargs:解包,将命令单词用逗号隔开放列表里 ['cd', '目录']
# timeout:超时时间,执行某个命令,在指定时间内没有执行成功就返回错误信息
# check:如果该参数设置为True,并且进程退出状态码不是0,则弹出CalledProcessError 异常。
# stdout:存储正确结果的管道
# stderr:存储错误结果的管道
# shell:Windows和Linux都填True
# encoding:如果指定了该参数,则 stdin、stdout 和 stderr 可以接收字符串数据,并以该编码方式编码,否则只接收 bytes 类型的数据。
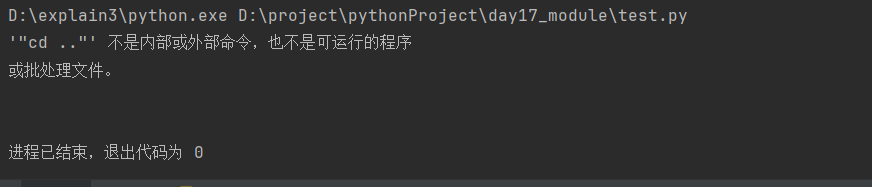
import subprocess res = subprocess.run(
["cd .."], # 格式一定为列表形式
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
encoding='gbk'
# 如果这里是True就不需要执行上面的stdout和stderr,错误的情况下正常打印错误信息
# 如果这里是False程序就会直接报错
# capture_output=True )
print(res.stderr)
1.4 call方法
import os
import subprocess root_dir = os.path.dirname(os.path.dirname(__file__))
print(root_dir)
subprocess.call('help') # 可以执行简单的命令,不能执行下方复杂的命令
subprocess.call(['dir', 'D:\project\pythonProject'])
subprocess.call(['dir', 'D:\\project\\pythonProject'])
2. 正则表达式re模块
2.1 概念
正则表达式的主要作用是用于检索、替换那些符合某个特定模式的文本。它通过使用特定的字符和字符组合来形成一个“规则字符串”,这个“规则字符串”用来表达对字符串的过滤逻辑,从而实现对文本的模式匹配和操作。
2.2 引入
# 校验手机号是否符合规范
def check_pn(pn):
if not pn.isdigit():
return '必须是数字'
if len(pn) != 11:
return '必须11位'
if pn[0:2] not in ['13', '14', '15', '16', '17', '18', '19']:
return '号段错误'
return f'号码:{pn}格式正确' while True:
num = input('请输入手机号:')
print(check_pn(num))
正则表达式进行格式匹配
import re def check_pn(pn):
# ^1是否以1开头,接下来的1位是否位3~9,结尾是否为数字,结尾位数是否为9位
pattern = '^1[3456789]\d{9}$'
if not re.match(pattern, pn):
return '格式不正确'
return f'手机号:{pn}格式正确' while True:
num = input('请输入手机号:')
print(check_pn(num))
2.3 字符组
概念:在同一个位置可能出现的各种字符组成了一个字符组
语法:[ ]
字符分为很多类,比如数字、字母、标点等等。
假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。
|
正则 |
待匹配字符 |
匹配结果 |
说明 |
|
[0123456789] |
8 |
True |
在一个字符组里枚举合法的所有字符,字符组里的任意一个字符和"待匹配字符"相同都视为可以匹配 |
|
[0123456789] |
a |
False |
由于字符组中没有"a"字符,所以不能匹配 |
|
[0-9] |
7 |
True |
也可以用-表示范围,[0-9]就和[0123456789]是一个意思 |
|
[a-z] |
s |
True |
同样的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
|
[A-Z] |
B |
True |
[A-Z]就表示所有的大写字母 |
|
[0-9a-fA-F] |
e |
True |
可以匹配数字,大小写形式的a~f,用来验证十六进制字符 |
# findall方法:在指定文本中查找符合正则表达式的内容
import re a = '789'
pattern1 = '[1]' # pattern1 = ['1']这样写会报错
# 去a中查找符合pattern1的内容,有则返回,没有则返回空
print(re.findall(pattern1, a)) # [] b = '123'
pattern2 = '[1]'
print(re.findall(pattern2, b)) # ['1'] c = '666'
pattern3 = '[0-9]' # 匹配0~9的数字
pattern4 = '[0123456789]'
print(re.findall(pattern3, c)) # ['6', '6', '6']
print(re.findall(pattern4, c)) # ['6', '6', '6'] d = '123abcABC'
pattern5 = '[a-z]' # 匹配所有小写字母
print(re.findall(pattern5, d)) # ['a', 'b', 'c'] e = '123abcABC'
pattern6 = '[A-Z]' # 匹配所有大写字母
print(re.findall(pattern6, e)) # ['A', 'B', 'C'] f = '123abcABC'
pattern7 = '[0-9a-zA-Z]' # 匹配大小写字母、数字
print(re.findall(pattern7, f)) # ['1', '2', '3', 'a', 'b', 'c', 'A', 'B', 'C']
2.4 字符组案例
# [ ]匹配字符组中的任意一个字符
# [^ ]匹配除了字符组外的任意一个字符
# ^[ ]匹配以字符组中的任意一个字符开头 import re a = '球王和球玉和球土和球欧冠和球'
pattern1 = '球[王和球玉和球土和球欧冠和球]'
print(re.findall(pattern1, a)) # ['球王', '球玉', '球土', '球欧'] b = '球王和球玉和球土和球欧冠和球'
pattern2 = '球[王和玉和土和欧冠和]*' # *匹配0次或无数次
print(re.findall(pattern2, b)) # ['球王和', '球玉和', '球土和', '球欧冠和', '球'] c = '球王和球玉和球土和球欧冠和球'
pattern3 = '球[^和]'
print(re.findall(pattern3, c)) # ['球王', '球玉', '球土', '球欧'] d = '11aa22bb33'
pattern4 = '\d+' # 匹配数字1次或多次
print(re.findall(pattern4, d)) # ['11', '22', '33']
2.5 元字符
元字符 匹配内容
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线
\s 匹配任意的空白符
\d 匹配数字
\n 匹配换行符
\t 匹配制表符 是1个tab键,相当于4个空格
\b 匹配单词的结尾
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
import re a = '12 \n ab'
pattern1 = '.' # 匹配换行符外的所有字符
print(re.findall(pattern1, a))
# ['1', '2', ' ', ' ', 'a', 'b'] 空格也能匹配 b = '12_ \n ab_%&*'
pattern2 = '\w' # 匹配字母、数字、下划线
print(re.findall(pattern2, b)) # ['1', '2', '_', 'a', 'b', '_'] c = '12_ \n ab_%&*'
pattern3 = '\s' # 匹配任意的空白符
print(re.findall(pattern3, c)) # [' ', '\n', ' '] d = '12_ \n ab_%&*'
pattern4 = '\d' # 匹配数字
print(re.findall(pattern4, d)) # ['1', '2'] e = '12_ \n\n \nab_%&*'
pattern5 = '\n' # 匹配换行符
print(re.findall(pattern5, e)) # ['\n', '\n', '\n'] f = '12_ \n\t ab_%&*\t'
pattern6 = '\t' # 匹配制表符(制表符是一个tab键,相当于4个空格)
print(re.findall(pattern6, f)) # ['\t', '\t'] g = 'hello hi how'
pattern7 = "'[how]'\b" # ???匹配单词的结尾
print(re.findall(pattern7, g)) # [] h = '123abc'
pattern8 = '^[0-9]' # 匹配字符串的开始
print(re.findall(pattern8, h)) # ['1']
pattern9 = '^[a-z]'
print(re.findall(pattern9, h)) # [] i = '12_ \n ab_%&@'
pattern10 = '[0-9]$' # 匹配字符串的结尾
print(re.findall(pattern10, i)) # []
pattern11 = '@$'
print(re.findall(pattern11, i)) # ['@'] j = '12_ \n ab_%&*'
pattern12 = '\W' # 匹配非数字、字母、下划线
print(re.findall(pattern12, j)) # [' ', '\n', ' ', '%', '&', '*'] k = '12_ \n ab_%&*'
pattern13 = '\D' # 匹配非数字
print(re.findall(pattern13, k)) # ['_', ' ', '\n', ' ', 'a', 'b', '_', '%', '&', '*'] l = '12_ \n\t ab_%&*\t'
pattern14 = '\S' # 匹配非空白符
print(re.findall(pattern14, l)) # ['1', '2', '_', 'a', 'b', '_', '%', '&', '*'] m = '12_ \n\t ab_%&*\t'
pattern15 = '[0-9]|[a-z]' # a|b,匹配字符a或字符b
print(re.findall(pattern15, m)) # ['1', '2', 'a', 'b'] n = '123456789 \n abcd'
pattern16 = '12([0-9])4' # () 匹配括号内的表达式,也表示一个组
print(re.findall(pattern16, n)) # ['3'] o = '123456789 \n abcd'
pattern17 = '23[0-9][0-9]678' # [...]匹配字符组中的字符
print(re.findall(pattern17, o)) # ['2345678']
pattern18 = '23([0-9][0-9])678'
print(re.findall(pattern18, o)) # ['45'] p = '123456789 \n abcd'
pattern19 = '[^0-9]' # 匹配除了字符组中字符的所有字符
print(re.findall(pattern19, p)) # [' ', '\n', ' ', 'a', 'b', 'c', 'd']
2.6 位置元字符案例
import re # . 表示任意一个字符
a = '球王球玉球土球欧冠'
pattern1 = '球.'
print(re.findall(pattern1, a)) # ['球王', '球玉', '球土', '球欧'] # ^ 以某个字符开头
b = '球王球玉球土球欧冠'
pattern2 = '^球.'
print(re.findall(pattern2, b)) # ['球王'] # $ 以某个字符结尾
c = '球王球玉球土球欧冠'
pattern3 = '球.$'
print(re.findall(pattern3, c)) # []
pattern4 = '球..$'
print(re.findall(pattern4, c)) # ['球欧冠'] # ^以某个字符开头 \w匹配字母、数字、下划线 {5}重复5次
d = 'city_haaland'
pattern5 = "^\w{5}"
print(re.findall(pattern5, d)) # ['city_'] # \w匹配字母、数字、下划线 {5}重复5次 $以某个字符结尾
e = 'leo_messi'
pattern6 = "\w{5}$"
print(re.findall(pattern6, e)) # ['messi'] # ^以某个字符开头 \w匹配字母、数字、下划线 {5}重复5次 $以某个字符结尾
f = 'leo_messi'
pattern7 = "^\w{5}$"
print(re.findall(pattern7, f)) # [] # 字符串长度必须是5位,以字母、数字、下划线开头,并且以字母、数字、下划线结尾
g = 'messi'
pattern8 = "^\w{5}$"
print(re.findall(pattern8, g)) # ['messi']
2.7 量词
量词 用法说明
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
量词默认是贪婪匹配,尽可能多拿
import re a = '01111123'
pattern1 = '0([0-9]*)23' # *重复0次或更多次
print(re.findall(pattern1, a)) # ['11111'] b = 'aabbbcccc'
pattern2 = 'aa([a-z]+)cccc' # +重复一次或更多次
print(re.findall(pattern2, b)) # ['bbb'] c = '01111123'
pattern3 = '0([0-9]?)23' # ?重复0次或一次
print(re.findall(pattern3, c)) # []
pattern4 = '011111([0-9]?)3'
print(re.findall(pattern4, c)) # ['2'] d = '01111123'
pattern5 = '0([0-9]{5})23' # {n}重复n次
print(re.findall(pattern5, d)) # ['11111'] e = '01111123'
pattern6 = '0([0-9]{3,})23' # {n,}重复n次或更多次 这里最少是3次,包括3
print(re.findall(pattern6, e)) # ['11111'] f = '01111123'
pattern7 = '0([0-9]{2,9})23' # {n,m}重复n到m次 这里最少是2次,包括2,最多是9次
print(re.findall(pattern7, f))
2.8 量词案例
import re a = '球王和球玉和球土和球欧冠和球'
pattern1 = '球.?' # ?匹配0次或1次
print(re.findall(pattern1, a)) # ['球王', '球玉', '球土', '球欧', '球'] b = '球王和球玉和球土和球欧冠和球'
pattern2 = '球.*' # *匹配0次或无数次
print(re.findall(pattern2, b)) # ['球王和球玉和球土和球欧冠和球'] c = '球王和球玉和球土和球欧冠和球'
pattern3 = '球.+' # +匹配1次或无数次
print(re.findall(pattern3, c)) # ['球王和球玉和球土和球欧冠和球'] d = '球王和球玉和球土和球欧冠和球'
pattern4 = '球.{1}' # {1}匹配指定次数1次
print(re.findall(pattern4, d)) # ['球王', '球玉', '球土', '球欧'] e = '球王和球玉和球土和球欧冠和球'
pattern5 = '球.{1,}' # {1,}匹配1次或更多次
print(re.findall(pattern5, e)) # ['球王和球玉和球土和球欧冠和球'] f = '球王和球玉和球土和球欧冠和球'
pattern6 = '球.{1,3}' # {1,3}匹配1到3次,尽可能多拿
print(re.findall(pattern6, f)) # ['球王和球', '球土和球']
2.9 分组匹配方法
( ) 提升优先级
| 两个条件任一
[^ ] 排除指定外的规则
2.10 转义字符
在python中斜杠 \ 具有特殊的含义,能够和某些字母构成特定的用法 如:\n 换行符
import re # \n换行符
a = '\n'
pattern1 = '\n'
print(re.findall(pattern1, a)) # ['\n']
取消转义的两种方式:
import re # 方式1:前面斜杠\ 加 后面斜杠\,取消后面斜杠的特殊含义
b = '\n'
pattern2 = '\\n'
print(re.findall(pattern2, b)) # ['\n'] # 方式2:在整个字符串的开头 + r 取消字符串的转义
# f'{}'格式化输出 r'\'取消斜杠的转义
c = '\n'
pattern3 = r'\n'
print(re.findall(pattern3, c)) # ['\n']
2.11 贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配
取消贪婪匹配:在满足条件时,按照最少的匹配 量词 + ?
几个常用的非贪婪匹配:
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
import re a = '球王和球玉和球土和球欧冠和球'
pattern1 = '球.*'
print(re.findall(pattern1, a)) # ['球王和球玉和球土和球欧冠和球'] # 取消贪婪匹配
b = '球王和球玉和球土和球欧冠和球'
pattern2 = '球.*?'
print(re.findall(pattern2, b)) # ['球', '球', '球', '球', '球']
2.12 模式修正符
模式修正符,也叫正则修饰符,是给正则模式增强或增加功能的。
值 说明
re.I 是匹配对大小写不敏感
re.L 做本地化识别匹配
re.M 多行匹配,影响到^和$
re.S 使.匹配包括换行符在内的所有字符
re.U 根据Unicode字符集解析字符,影响\w、\W、\b、\B
re.X 通过给予我们功能灵活的格式以便更好的理解正则表达式
import re a = 'abcABC'
pattern1 = '[a-z]'
print(re.findall(pattern1, a)) # ['a', 'b', 'c'] # 使用模式修正符后不区分大小写
b = 'abcABC'
pattern2 = '[a-z]'
print(re.findall(pattern2, b, re.I)) # ['a', 'b', 'c', 'A', 'B', 'C']
2.13 re模块常用方法
(1)查找结果 findall
返回所有满足匹配条件的结果,放在列表里
import re a = 'leo messi'
pattern = 'e'
print(re.findall(pattern, a)) # ['e', 'e']
(2)查找结果 search
只能返回一个满足条件的包含匹配信息的对象,该对象可以调用group()方法得到匹配的字符串
如果没有匹配到,则返回None,该结果不能调用group()
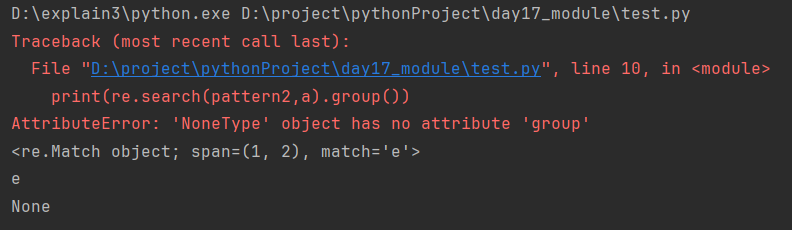
import re a = 'leo messi'
pattern1 = 'e'
print(re.search(pattern1, a)) # <re.Match object; span=(1, 2), match='e'>
print(re.search(pattern1, a).group()) # e pattern2 = 'r'
print(re.search(pattern2,a)) # None
print(re.search(pattern2,a).group())
(3)查找结果match
用法同search,但是只在字符串开始处进行匹配
import re a = 'leo messi'
pattern1 = 'e'
print(re.match(pattern1, a)) # None
pattern2 = 'leo'
print(re.match(pattern2, a)) # <re.Match object; span=(0, 3), match='leo'>
print(re.match(pattern2, a).group()) # leo
(4)切割 split
import re a = 'abcd'
pattern = '[ab]' # 先按'a'分割得到''和'bcd',再按'b'分割得到'','','cd'
print(re.split(pattern, a)) # ['', '', 'cd']
(5)替换指定个数 sub
语法:sub(pattern,替换的字符,原始数据,替换次数)
次数不写则全替换
import re data = 'aaabbbccc'
pattern = 'a'
print(re.sub(pattern, 'A', data, 2)) # AAabbbccc
print(re.sub(pattern, 'A', data)) # AAAbbbccc
(6)替换全部 subn
返回值是一个元组:(替换后的结果,替换次数)
import re data = 'aaabbbccc'
pattern = 'a'
print(re.subn(pattern, 'A', data)) # ('AAAbbbccc', 3)
(7)编译正则表达式 compile
import re
obj = re.compile('[a-z]{3}') # 将正则表达式编译为一个正则表达式对象,规则是要匹配3位小写字母
res = obj.search('abcdefg123456789') # 正则表达式对象调用search,参数为待匹配的字符串
print(res.group()) # abc
(8)查询结果finditer
finditer方法返回的是存放匹配结果的可迭代对象
import re
res = re.finditer('[A-Z]', '123abcJQK')
print(res) # <callable_iterator object at 0x0000012624B897E0>
print(next(res)) # <re.Match object; span=(6, 7), match='J'>
print(next(res).group()) # Q
print(next(res).group()) # K
print(next(res).group()) 继续取值就会报错
2.14 查询优先级
(1)findall的优先级查询
import re a = 'www.hoogle.com'
pattern1 = 'www.(hoogle|uwitter).com'
print(re.findall(pattern1, a)) # ['hoogle'] b = 'www.hoogle.com'
pattern2 = 'www.(?:hoogle|uwitter).com'
print(re.findall(pattern2, b)) # ['www.hoogle.com']
(2)split的优先级查询
import re
res1 = re.split('\d+', 'messi01ronaldo02kylian03')
print(res1) # ['messi', 'ronaldo', 'kylian', '']
res2 = re.split('(\d+)', 'messi01ronaldo02kylian03')
print(res2) # ['messi', '01', 'ronaldo', '02', 'kylian', '03', '']
在匹配部分加上()之后所切出的结果是不同的
没有()的没有保留所匹配的项,有()的保留了匹配的项
17 模块subprocess、re的更多相关文章
- Python第十一天 异常处理 glob模块和shlex模块 打开外部程序和subprocess模块 subprocess类 Pipe管道 operator模块 sorted函数 os模块 hashlib模块 platform模块 csv模块
Python第十一天 异常处理 glob模块和shlex模块 打开外部程序和subprocess模块 subprocess类 Pipe管道 operator模块 sorted函 ...
- Python基础篇【第6篇】: Python模块subprocess
subprocess Python中可以执行shell命令的相关模块和函数有: os.system os.spawn* os.popen* --废弃 popen2.* ...
- python模块:调用系统命令模块subprocess等
http://blog.csdn.net/pipisorry/article/details/46972171 Python经常被称作"胶水语言",因为它能够轻易地操作其他程序,轻 ...
- os模块,os.path模块,subprocess模块,configparser模块,shutil模块
1.os模块 os表示操作系统该模块主要用来处理与操作系统相关的操作最常用的文件操作打开 读入 写入 删除 复制 重命名 os.getcwd() 获取当前执行文件所在的文件夹路径os.chdir(&q ...
- 【转】Python模块subprocess
subprocess 早期的Python版本中,我们主要是通过os.system().os.popen().read()等函数.commands模块来执行命令行指令的,从Python 2.4开始官方文 ...
- Python 调用系统命令的模块 Subprocess
Python 调用系统命令的模块 Subprocess 有些时候需要调用系统内部的一些命令,或者给某个应用命令传不定参数时可以使用该模块. 初识 Subprocess 模块 Subprocess 模块 ...
- configparser模块 subprocess 模块,xlrd 模块(表格处理)
今日内容: 1.configparser模块 2.subprocess模块 3.xlrd(读),xlwt(写) 表格处理 configparser模块 import configparser # co ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- python模块subprocess学习
当我们想要调用系统命令,可以使用os,commands还有subprocess模块整理如下: os模块: 1. os.system 输出命令结果到屏幕.返回命令执行状态. >>> o ...
- python hashlib模块 logging模块 subprocess模块
一 hashlib模块 import hashlib md5=hashlib.md5() #可以传参,加盐处理 print(md5) md5.update(b'alex') #update参数必须是b ...
随机推荐
- Linux服务器PBS任务队列作业提交脚本的使用方法
本文介绍在Linux服务器中,通过PBS(Portable Batch System)作业管理系统脚本的方式,提交任务到服务器队列,并执行任务的方法. 最近,需要在学校公用的超算中执行代码任务 ...
- Nuxt.js必读:轻松掌握运行时配置与 useRuntimeConfig
title: Nuxt.js必读:轻松掌握运行时配置与 useRuntimeConfig date: 2024/7/29 updated: 2024/7/29 author: cmdragon exc ...
- Jmeter调试取样器
调试取样器(Debug Sampler),生成一个包含JMeter变量或属性值的样本,并且这些值可以在组件[查看结果树]的响应窗格中看到 组件路径:线程组->右键添加->取样器->D ...
- Fiddler使用界面介绍-底部状态栏
底部状态栏 1.Capturing抓包状态 Capturing:Fiddler正在抓包 空白:Fiddler停止抓包 2.All Processes抓取进程类型 All Processes:抓取所有进 ...
- 【Java】线程池配置
先看JUC包自带的一个资源 线程池执行器: 初始化参数如下 ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor( corePo ...
- 【转载】sun的rpc ——rpcbind(nfs文件系统中的rpc)
原文地址: https://blog.csdn.net/wangpeng138375/article/details/8169071 ================================= ...
- 多网卡系统下如何使用tcp协议实现MPI的分布式多机运行(mpi的实现使用openmpi)
如题: 最近在看MPI方面的东西,主要是Python下的MPI4PY,学校有超算机房可以使用MPI,但是需要申请什么的比较麻烦,目的也本就是为了学习一下,所以就想着在自己的电脑上先配置一下. 现有硬件 ...
- 为baselines算法库安装mujoco环境支持——ubuntu 20.04安装MuJoCo2.1.1
下载开源版本的mujoco二进制文件: wget https://github.com/deepmind/mujoco/releases/download/2.1.1/mujoco-2.1.1-lin ...
- C#.Net筑基-解密委托与事件
委托与事件是C#中历史比较悠久的技术,从C#1.0开始就有了,核心作用就是将方法作为参数(变量)来传递和使用.其中委托是基础,需要熟练掌握,编程中常用的Lambda表达式.Action.Func都是委 ...
- Sentry 开源版与商业 SaaS 版的区别
您会在官方的文档中找到大量对 sentry 和 getsentry 的引用.两者都是 Django 应用程序,但 sentry 是开源的, getsentry 是闭源的.里面有什么? https:// ...