树模型--ID3算法
基于信息增益(Information Gain)的ID3算法
ID3算法的核心是在数据集上应用信息增益准则来进行特征选择,以此递归的构建决策树,以信息熵和信息增益为衡量标准,从而实现对数据的归纳分类。
ID3算法需要解决的问题是如何选择特征作为划分数据集的标准。在ID3算法中,选择信息增益最大的属性作为当前的特征对数据集分类
信息增益
信息增益需要涉及到熵,条件熵这2个概念,先通俗的理解一下:
- 熵:表示随机变量的不确定性。
- 条件熵:在一个条件下,随机变量的不确定性。
- 信息增益:熵 - 条件熵。表示在一个条件下,信息不确定性减少的程度。
比如:太阳明天从东方升起 ,这句话的信息熵等于0,因为这是确定的事件,信息无价值
对于信息增益,举个例子,通俗地讲,假设\(X\)(明天下雨)是一个随机变量,\(X\)的熵假设等于2, \(Y\)(明天阴天)也是随机变量,在阴天情况下下雨的信息熵我们如果也知道的话(此处需要知道其联合概率分布或是通过数据估计)即是条件熵。\(X\)的熵减去\(Y\)条件下\(X\)的熵,就是信息增益。
具体解释:原本明天下雨的信息熵是2,条件熵是0.01(因为如果知道明天是阴天,那么下雨的概率很大,信息量少),这样相减后为1.99就是信息增益。其含义就是在获得阴天这个信息后,下雨信息不确定性减少了1.99,不确定减少了很多,所以信息增益大。也就是说,阴天这个信息对明天下午这一推断来说非常重要。所以在特征选择的时候常常用信息增益,如果IG(信息增益大)的话那么这个特征对于分类来说很关键,决策树就是这样来找特征的。具体到数据集上,信息增益需要结合特征和对应的label来计算。
熵
信息增益与熵(entropy)有关,在概率论中,熵是随机变量不确定性的度量,熵越大,随机变量的不确定性就越大;假设\(X\)是取有限个值的离散随机变量,其概率分布为:
\]
则,熵的定义为:
\]
一般取自然对数\(e\)为底数,值得注意的是,熵实际上是随机变量\(X\)的分布的泛函数,它并不依赖\(X\)的实际取值,而仅仅依赖\(X\)的概率分布,所以它又可以被记作:
\]
其中, \(n\)表示\(X\)的\(n\)种不同的取值, 这个值一般是离散的. \(p_i\)表示为\(X\)取到值为\(i\)的概率.\(log\)一般是自然底数
例子:
条件熵
多个变量的熵叫联合熵, 比如两个变量\(X,Y\)的联合熵就表示为:
\]
类似于条件概率,熵同样也存在着条件熵, 条件熵描述了知道某个变量以后, 剩下的变量的不确定性, 其表达式如下:
\]
信息增益
\(H(X)\)度量了\(X\)的不确定性, \(H(X|Y)\)度量了知道\(Y\)后,\(X\)的不确定性, 那么\(H(X)-H(X|Y)\)度量的可以理解为:知道\(Y\)的基础上, \(X\)不确定性减少的程度,我们记为\(I(X,Y)\),如图:

更多理解
假定当前样本集合\(D\)中,第\(k\)类样本所占比例为\(p_k(k=1,2,3...,|y|)\), 则\(D\)的信息熵定义为:
\]
假定离散属性\(a\)有\(V\)个可能的取值\({a^1,a^2...a^v}\), 若使用\(a\)来对样本集进行划分,则会产生\(V\)个分支结点, 也就是说, ID3构建的决策树, 是多叉树, 那么它的信息增益就是
\]
比如: 一个二分类数据集, 包含17个样本, 其中正例为8,反例为9,那么, 数据集\(D\)的信息熵为:
\]
对于变量\(a\),他有三个取值, 那么它可以将数据集划分为三个子集: \(D^1,D^2,D^3\), 其样本里分别为6,6,5, 这三个自数据集中, 正负样本分别为(3,3) (4,2),(1,4), 这三个分支结点的信息熵为为:
\]
\]
\]
那么变量\(a\)的信息增益为:
\]
ID3 步骤
ID3使用信息增益来决策当前树结点该使用那个变量来构建决策树, 显然,信息增益越大的, 就越能更有效的区分特征(变量)与预测标签之间的关系.
输入\(m\)个样本,每个样本有\(n\)个离散的特征,令特征集合为\(A\),输出决策树\(T\)
- 判断样本是否为同一类别, 如果是, 则返回树T
- 判断特征是否为空, 是, 则返回树T
- 计算A中, 各个特征的信息增益,选择最大的信息增益特征,记为\(i\)
- 按特征\(i\)的不同取值, 将对应的样本分成不同类别,每个类别产生一个子结点,对应的特征值为\(i_j\)
- 重复上述步骤直到结束
显然,ID3是一个多叉树,且其只能解决分类问题
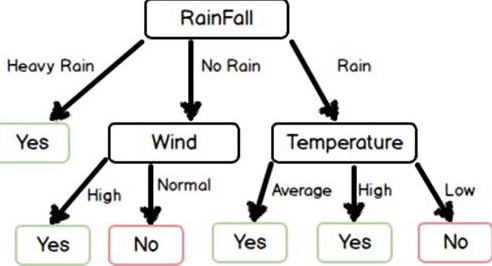
ID3算法的缺点
- 无法处理连续的特征,遇到连续的特征的话,就得做连续数据离散化了,可以考虑分桶等策略
- 采用信息增益更大的特征优先建立决策树, 但相同的数据集下, 取值较多的特征值比取值较少的特征值信息增益更大,即信息增益偏向取值较多的特征。
- 没有考虑缺失值,当然大部分算法都不支持含有missing value的数据集,尽管理论上算法可以支持,比如gbdt,但大部分gbdt的实现都不支持missing value,目前常用的算法,只有xgb,lgb支持
- 过拟合问题,id3没有考虑过拟合的对抗策略,相当于是在
ID3算法的优点
- 可解释性较强
树模型--ID3算法的更多相关文章
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 决策树笔记:使用ID3算法
决策树笔记:使用ID3算法 决策树笔记:使用ID3算法 机器学习 先说一个偶然的想法:同样的一堆节点构成的二叉树,平衡树和非平衡树的区别,可以认为是"是否按照重要度逐渐降低"的顺序 ...
- ID3算法 决策树的生成(1)
# coding:utf-8 import matplotlib.pyplot as plt import numpy as np import pylab def createDataSet(): ...
- 鹅厂优文 | 决策树及ID3算法学习
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~. 作者:袁明凯|腾讯IEG测试开发工程师 决策树的基础概念 决策树是一种用树形结构来辅助行为研究.决策分析以及机器学习的方式,是机器学习中的 ...
- SAS-决策树模型
决策树是日常建模中使用最普遍的模型之一,在SAS中,除了可以通过EM模块建立决策树模型外,还可以通过SAS代码实现.决策树模型在SAS系统中对应的过程为Proc split或Proc hpsplit, ...
- 决策树ID3算法--python实现
参考: 统计学习方法>第五章决策树] http://pan.baidu.com/s/1hrTscza 决策树的python实现 有完整程序 决策树(ID3.C4.5.CART ...
- ID3算法(MATLAB)
ID3算法是一种贪心算法,用来构造决策树.ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续 ...
- 机器学习-决策树之ID3算法
概述 决策树(Decision Tree)是一种非参数的有监督学习方法,它是一种树形结构,所以叫决策树.它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回 ...
- 数据挖掘之决策树ID3算法(C#实现)
决策树是一种非常经典的分类器,它的作用原理有点类似于我们玩的猜谜游戏.比如猜一个动物: 问:这个动物是陆生动物吗? 答:是的. 问:这个动物有鳃吗? 答:没有. 这样的两个问题顺序就有些颠倒,因为一般 ...
随机推荐
- HashMap很美好,但线程不安全怎么办?ConcurrentHashMap告诉你答案!
写在开头 在<耗时2天,写完HashMap>这篇文章中,我们提到关于HashMap线程不安全的问题,主要存在如下3点风险: 风险1: put的时候导致元素丢失:如两个线程同时put,且ke ...
- 8、mysql的内存管理及优化
内存优化原则 1) 将尽量多的内存分配给MySQL做缓存,但要给操作系统和其他程序预留足够内存. 2) MyISAM 存储引擎的数据文件读取依赖于操作系统自身的IO缓存,因此,如果有MyISAM表,就 ...
- JS3-高级事件
获取事件和处理事件的第二种方式:事件监听 如何获取和处理鼠标与键盘的基本事件? 事件监听方式 eventTarget.addEventListener(type,listener[,useCaptur ...
- OPPO 后端面试凉经(附详细参考答案)
这篇文章的问题来源于一个读者之前分享的 OPPO 后端凉经,我对比较典型的一些问题进行了分类并给出了详细的参考答案.希望能对正在参加面试的朋友们能够有点帮助! Java String 为什么是不可变的 ...
- iptables五表五链及对应实例
iptables是Linux系统上用于配置网络包过滤规则的工具,它使用表(tables)和链(chains)来组织规则.以下是iptables中的五表五链及其对应的实例说明: 五表 filter表:默 ...
- CentOS 7.9 环境下搭建k8s集群(一主两从)
目录 一.硬件准备(虚拟主机) 二.环境准备 1.所有机器关闭防火墙 2.所有机器关闭selinux 3.所有机器关闭swap 4.所有机器上添加主机名与ip的对应关系 5.在所有主机上将桥接的ipv ...
- c语言之被遗漏的角落---#pragma pack
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 记录--vue3优雅的使用element-plus的dialog
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 如何优雅的基于 element-plus,封装一个梦中情 dialog 优点 摆脱繁琐的 visible 的命名,以及反复的重复 dom. ...
- 记录-Symbol学习笔记
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 Symbol是JavaScript中的原始数据类型之一,它表示一个唯一的.不可变的值,通常用作对象属性的键值.由于Symbol值是唯一的, ...
- Elasticsearch内核解析 - 数据模型篇【转载】
原文链接 Elasticsearch是一个实时的分布式搜索和分析引擎,它可以帮助我们用很快的速度去处理大规模数据,可以用于全文检索.结构化检索.推荐.分析以及统计聚合等多种场景. Elasticsea ...