kettle从入门到精通 第三十二课 mysql 数据连接集群/分区配置
1、这里的集群实际上是数据分区或者分片的概念,如中国全国的学生,应该不会都存在一张表里面,有可能每个省市一个表进行存储。
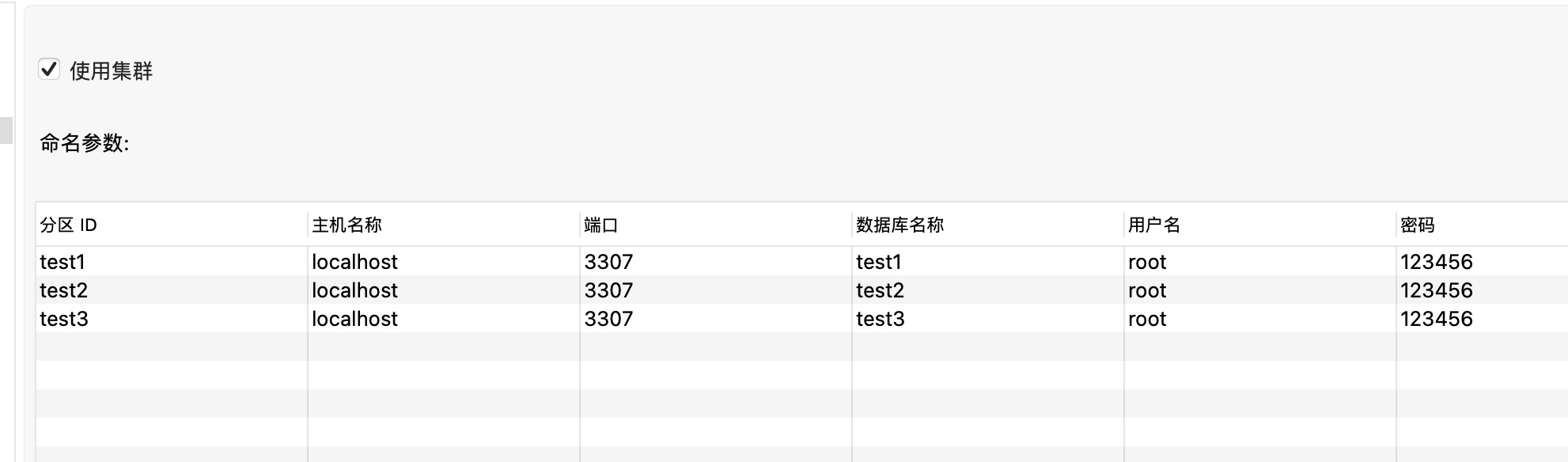
2、集群(分区),如下图所示

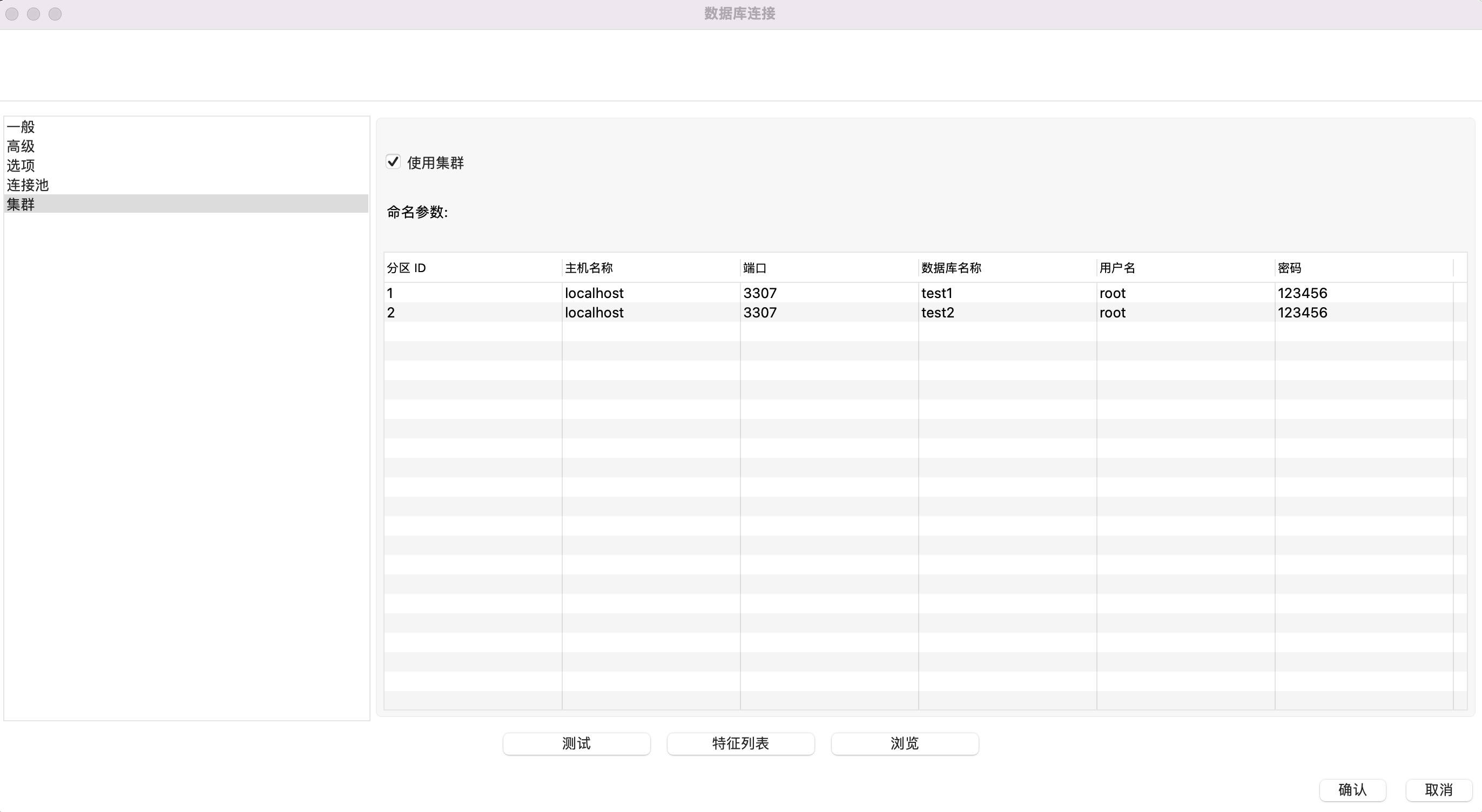
设置在“集群”标签,勾选“使用集群”,然后定义两个分区。这里的分区实际指的是数据库实例,需要指定自定义的分区ID,数据库实例的主机名(IP)、端口、数据库名、用户名和密码。
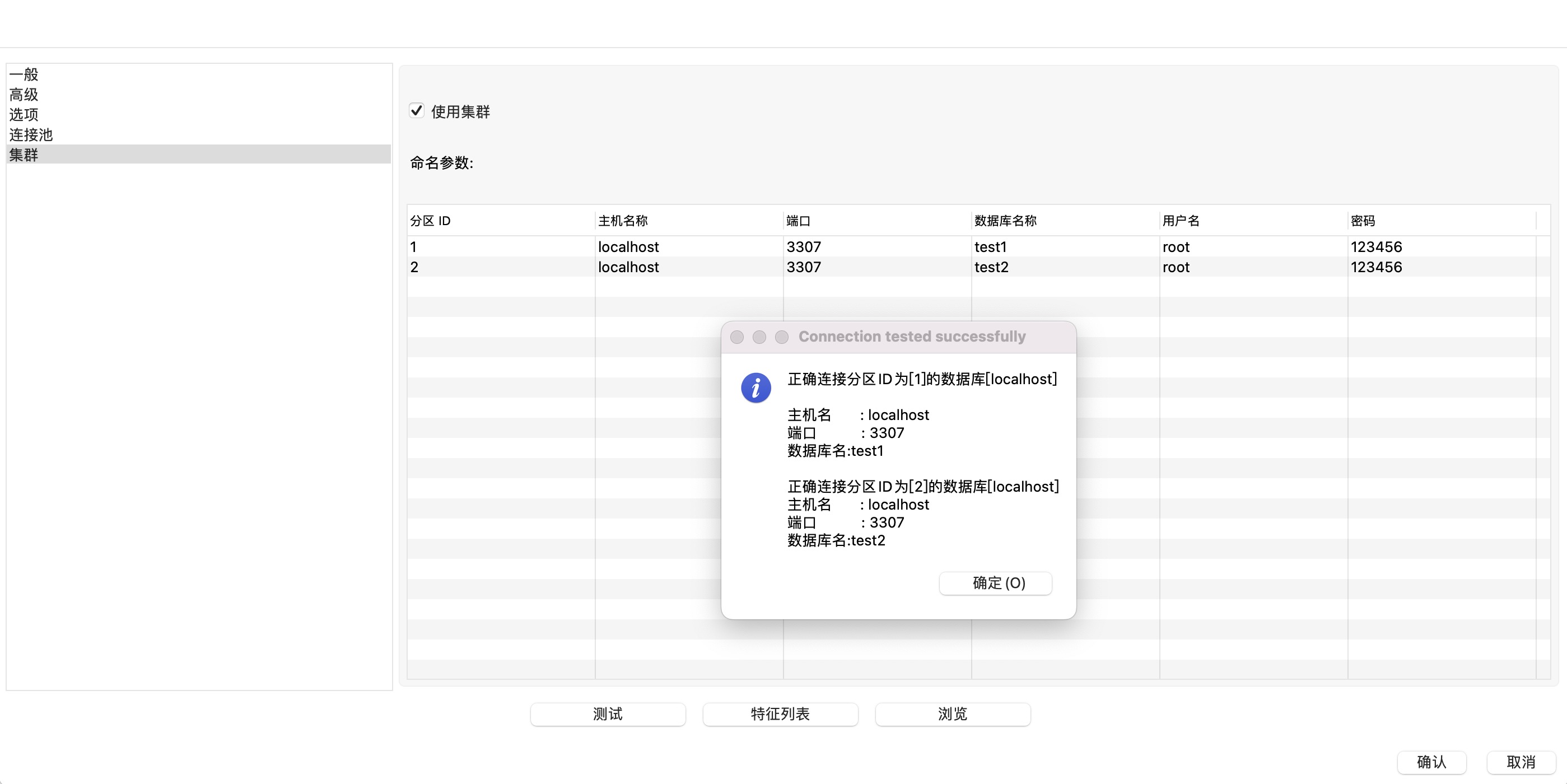
点击测试按钮可以测试数据库是否正常连接,如下图所示
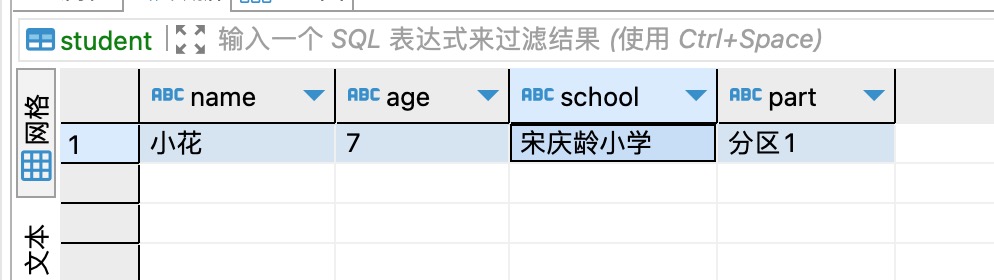
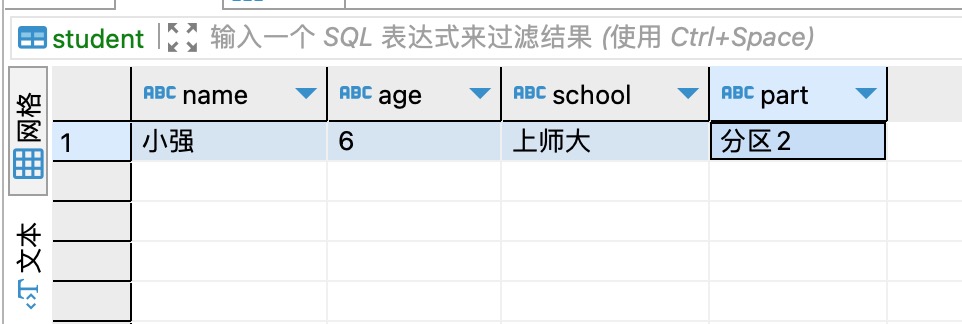
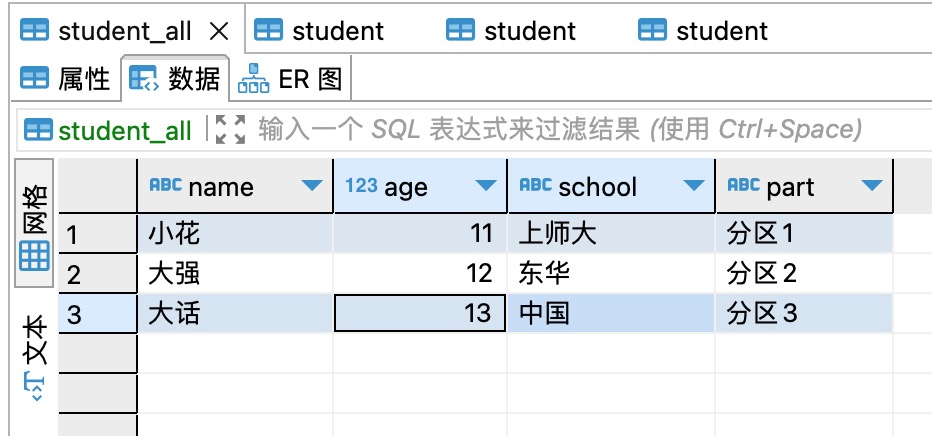
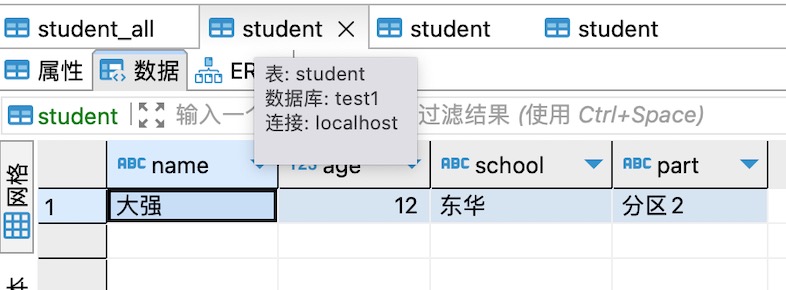
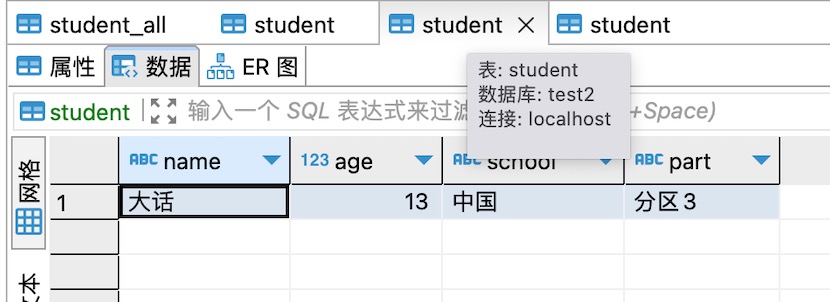
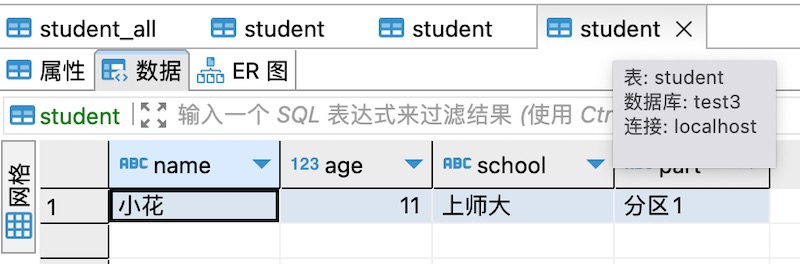
3、有两个数据库test1和test2,两个数据库里面都有一个相同的表,名为student,每个表里有一条数据,如下图所示,后面会用到。
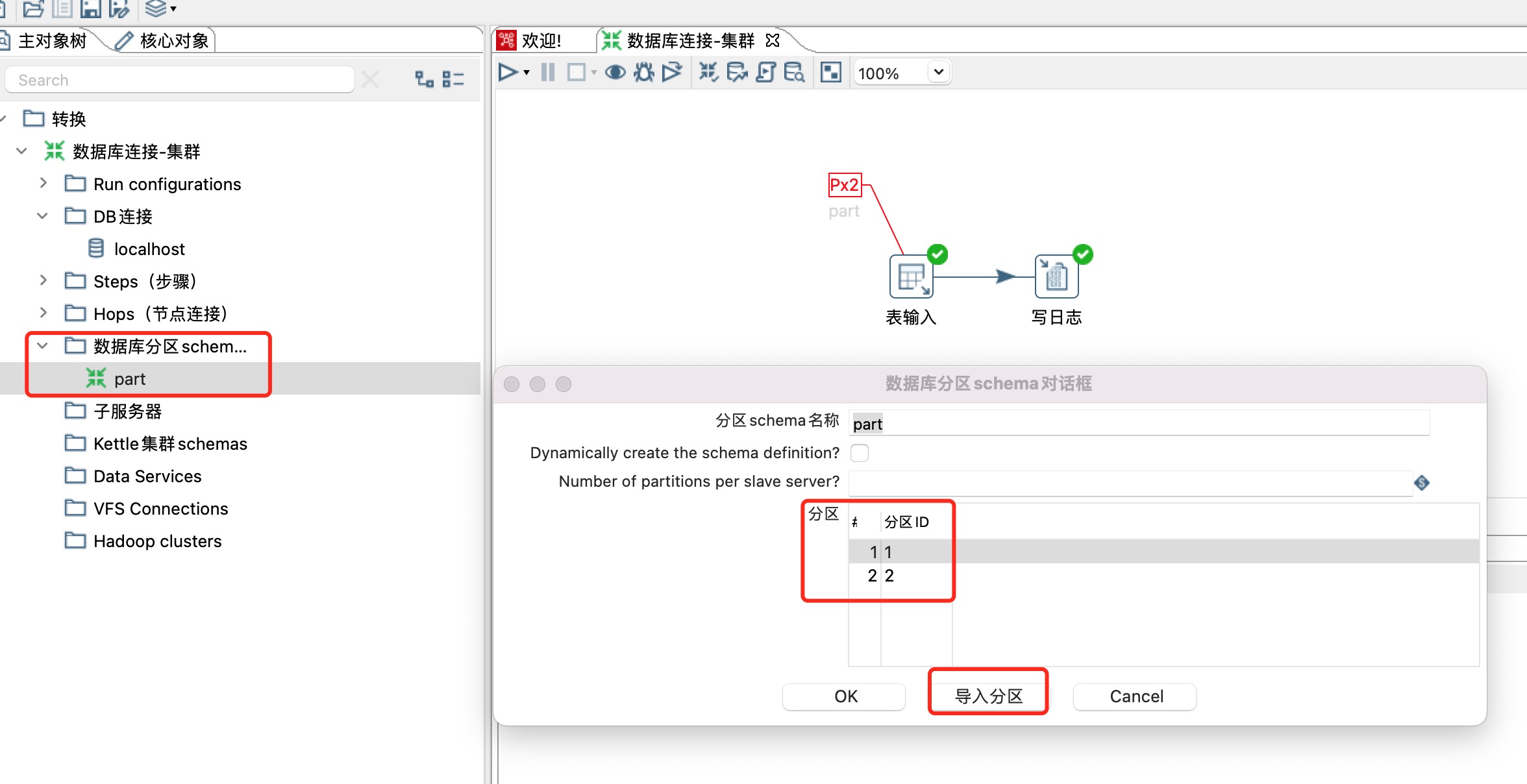
4、创建数据库分区schemas,在“主对象树”的“数据库分区schemas”上点右键“新建”,在弹出窗口中输入“分区schema名称”,然后点击“导入分区”按钮,如下图所示。
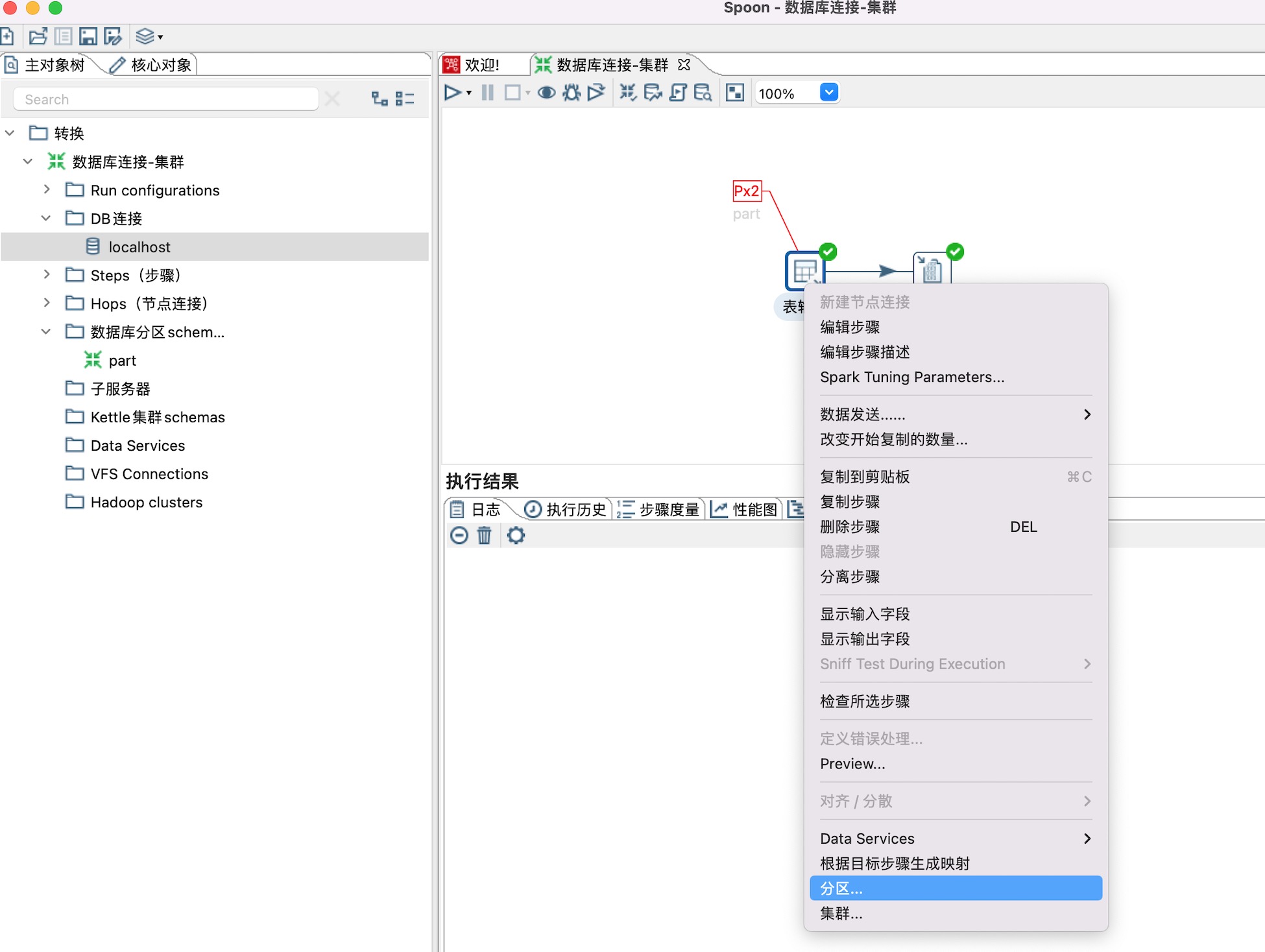
5、为表输入步骤设置分区,右键表输入步骤,设置分区即可,如下图所示
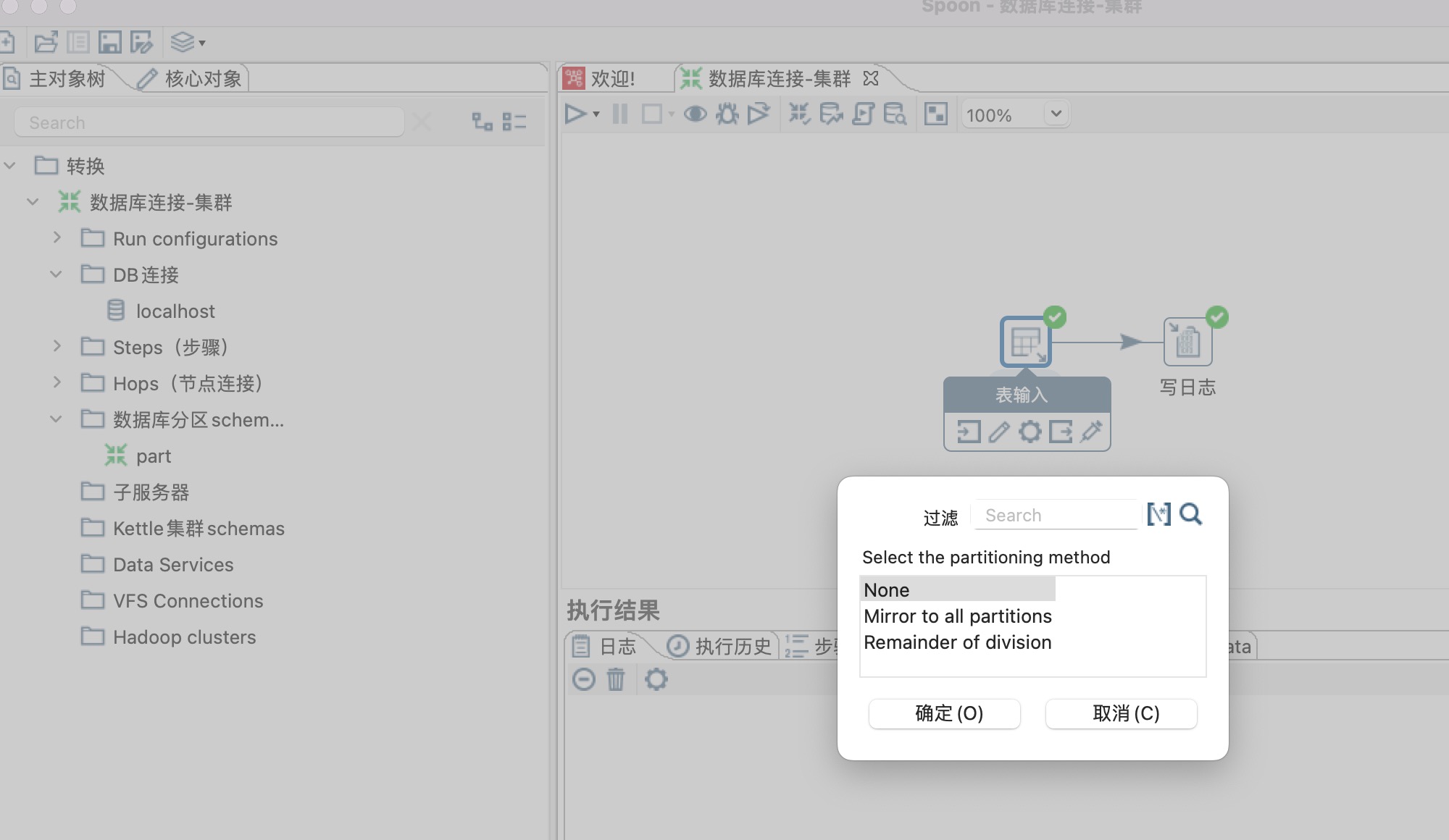
a. None:选择None表示不进行数据分区,即所有数据都将被发送到默认的目标分区中。这意味着不对数据进行分区,将全部数据集中存储在一个分区中。
b. Mirror to all partitions:选择Mirror to all partitions表示将数据镜像复制到所有分区中。无论输入数据来自哪个分区,都会被同时复制到所有可用的分区中,使得每个分区都含有完整的数据集。
c. Remainder of division:选择Remainder of division表示根据某个字段的取余结果将数据分发到不同的分区中。通常情况下,我们会选择一个字段进行取余操作,然后将取余的结果作为分区的标识,这样可以将数据均匀地分布到不同的分区中。
Kettle标准的分区方法。通过分区编号除以分区数目,产生的余数被用来决定记录行将发往哪个分区。例如在一个记录行里,如果有 “3” 标识的用户身份,而且有2个分区定义,这样这个记录行属于分区1
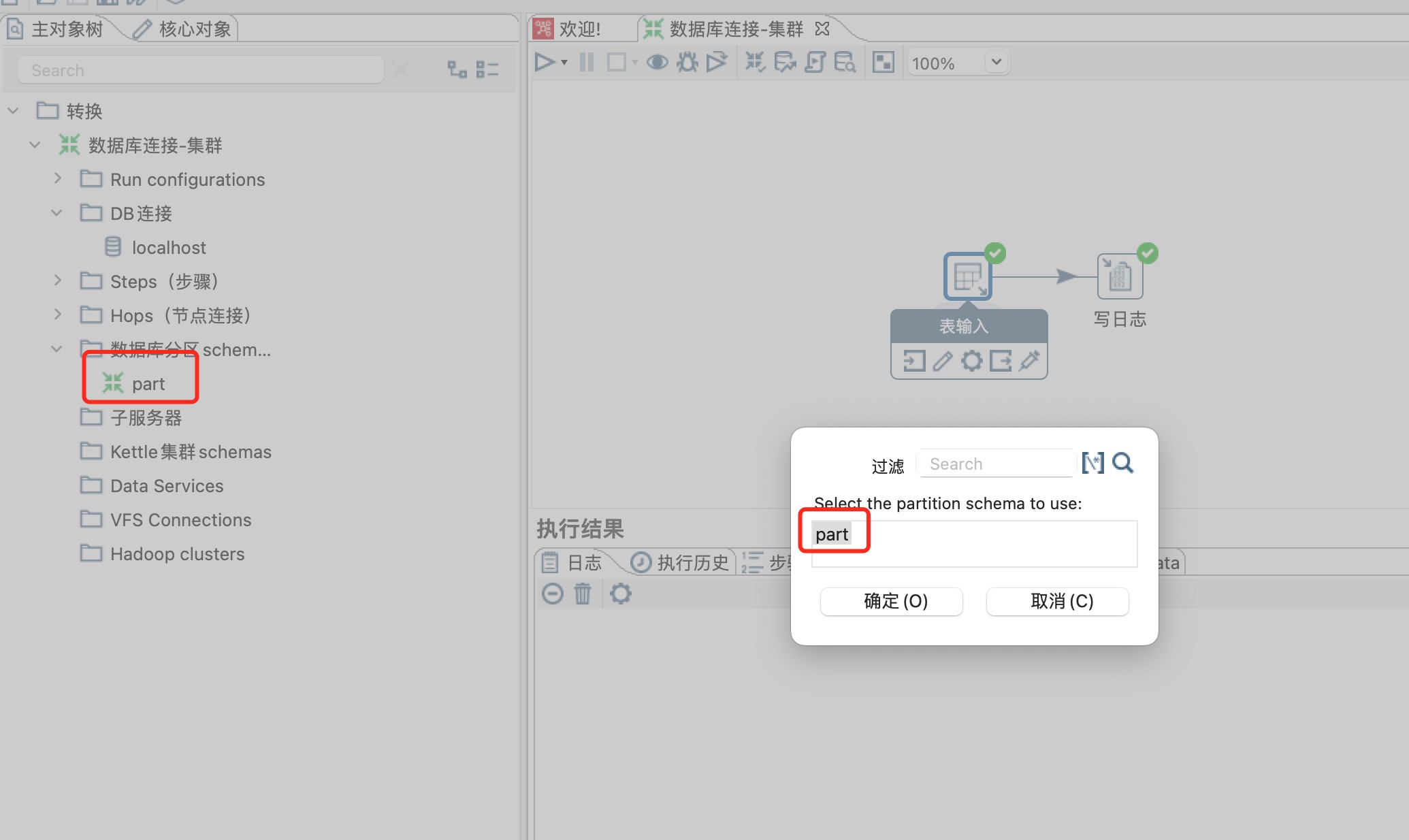
选择设置好的part分区即可,这里的part名字可以根据需要自行定义。
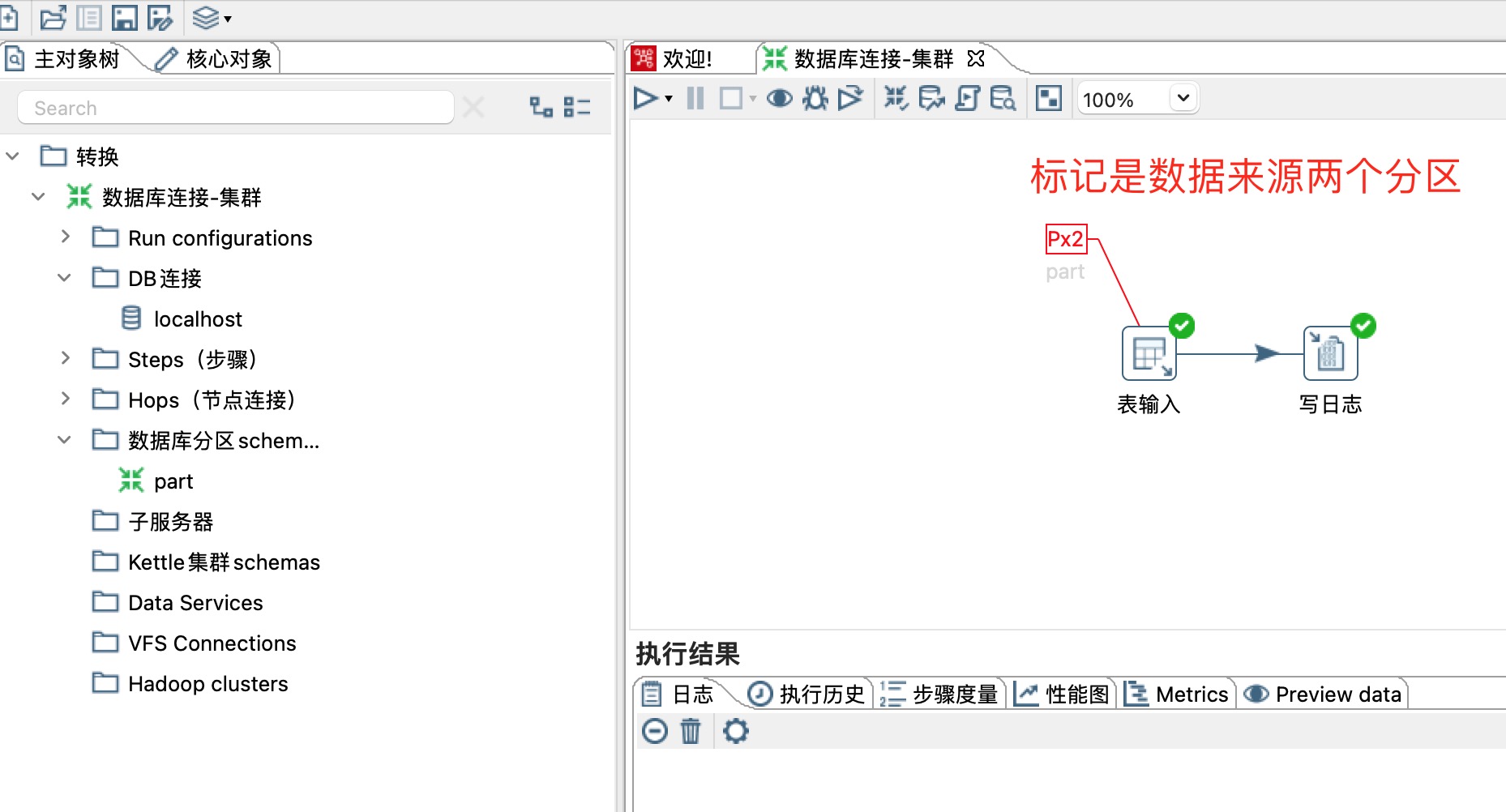
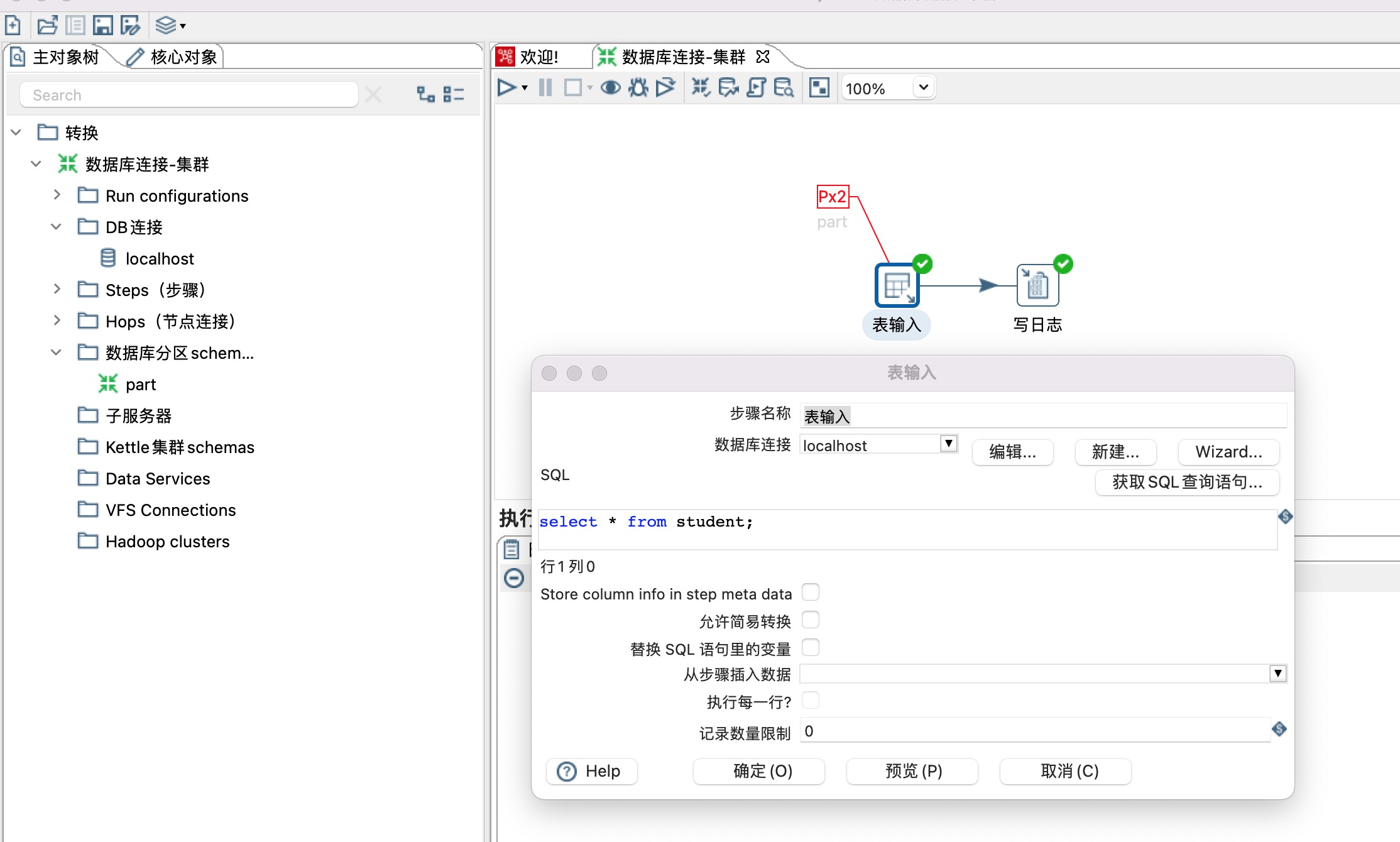
6、设置表输入步骤,如下图所示
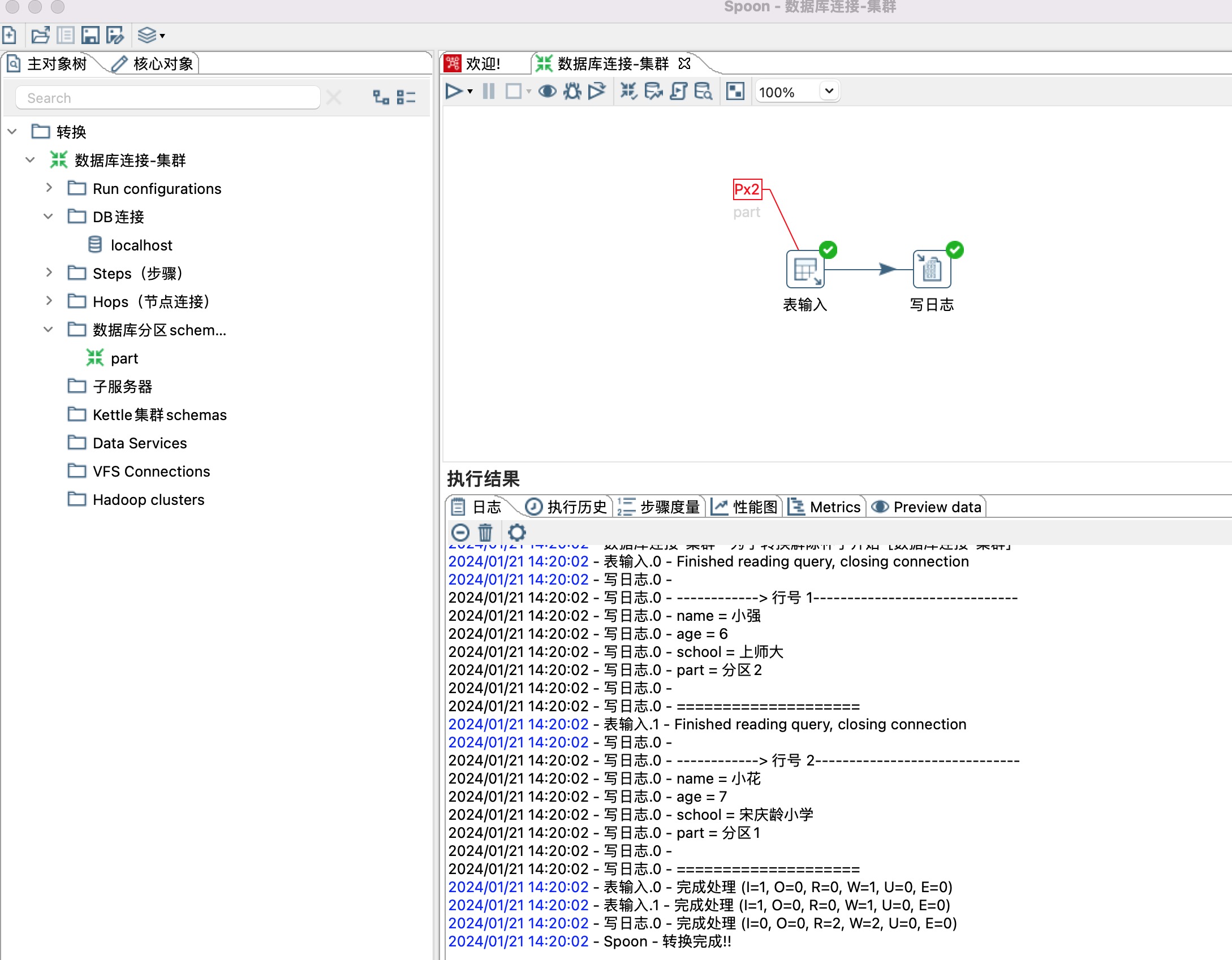
7、分区方式为Mirror to all partitions的情况下,表输入读取两个分区的数据,如下图所示
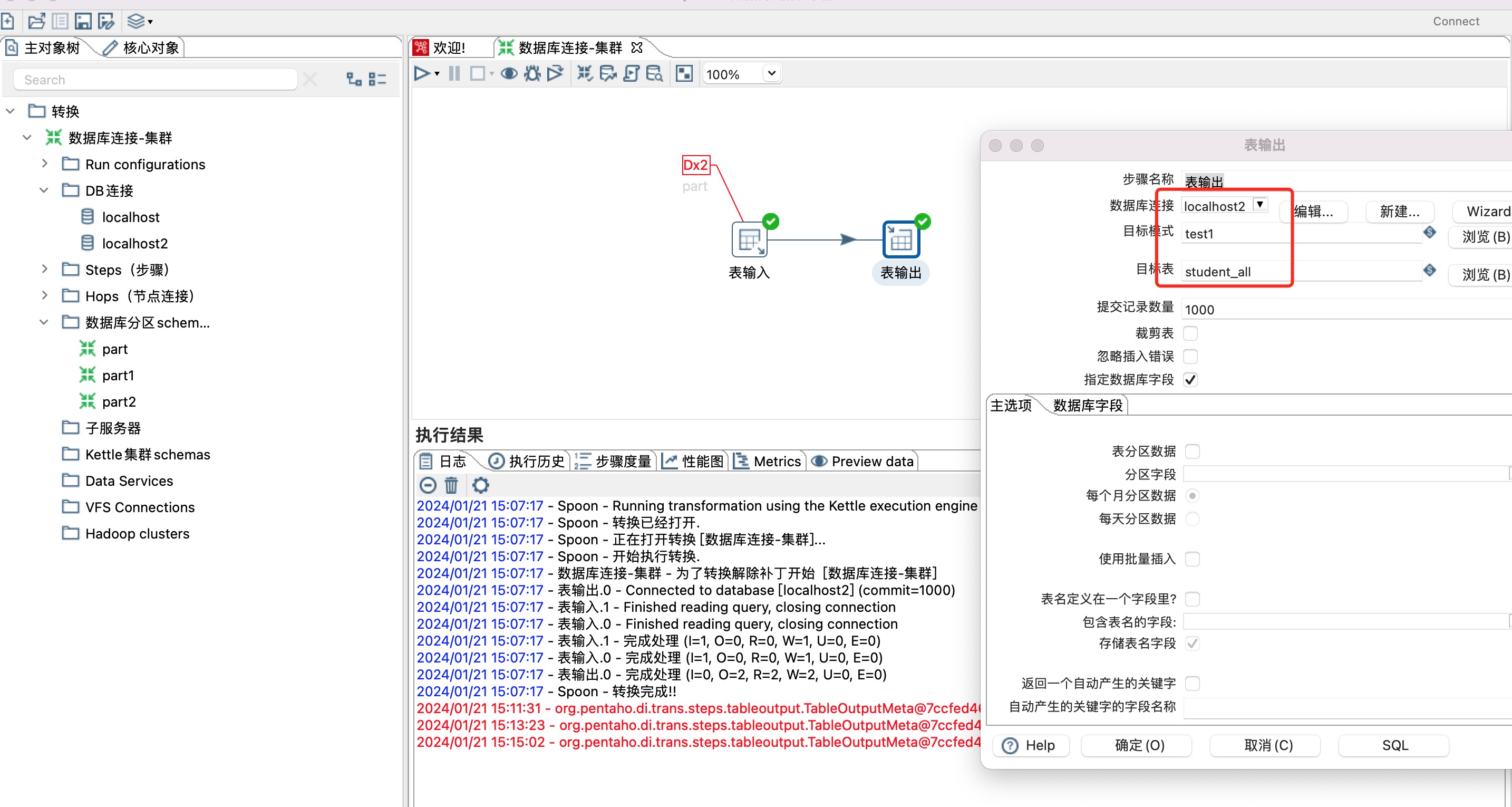
8、两个分区数据转移到一张表里面,如下图所示
另外表输入和输出步骤不熟悉的话,可以查看我之前的文章,里面有详细介绍。
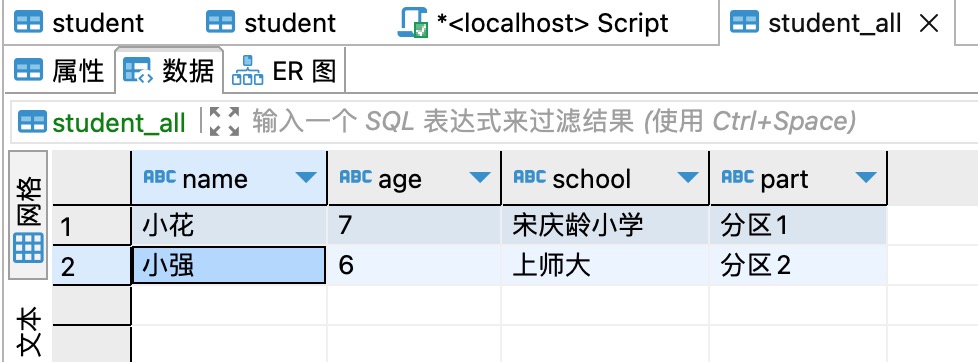
9、一个全量表student_all 中的数据,同步到三个分区的三个student表,如下图所示
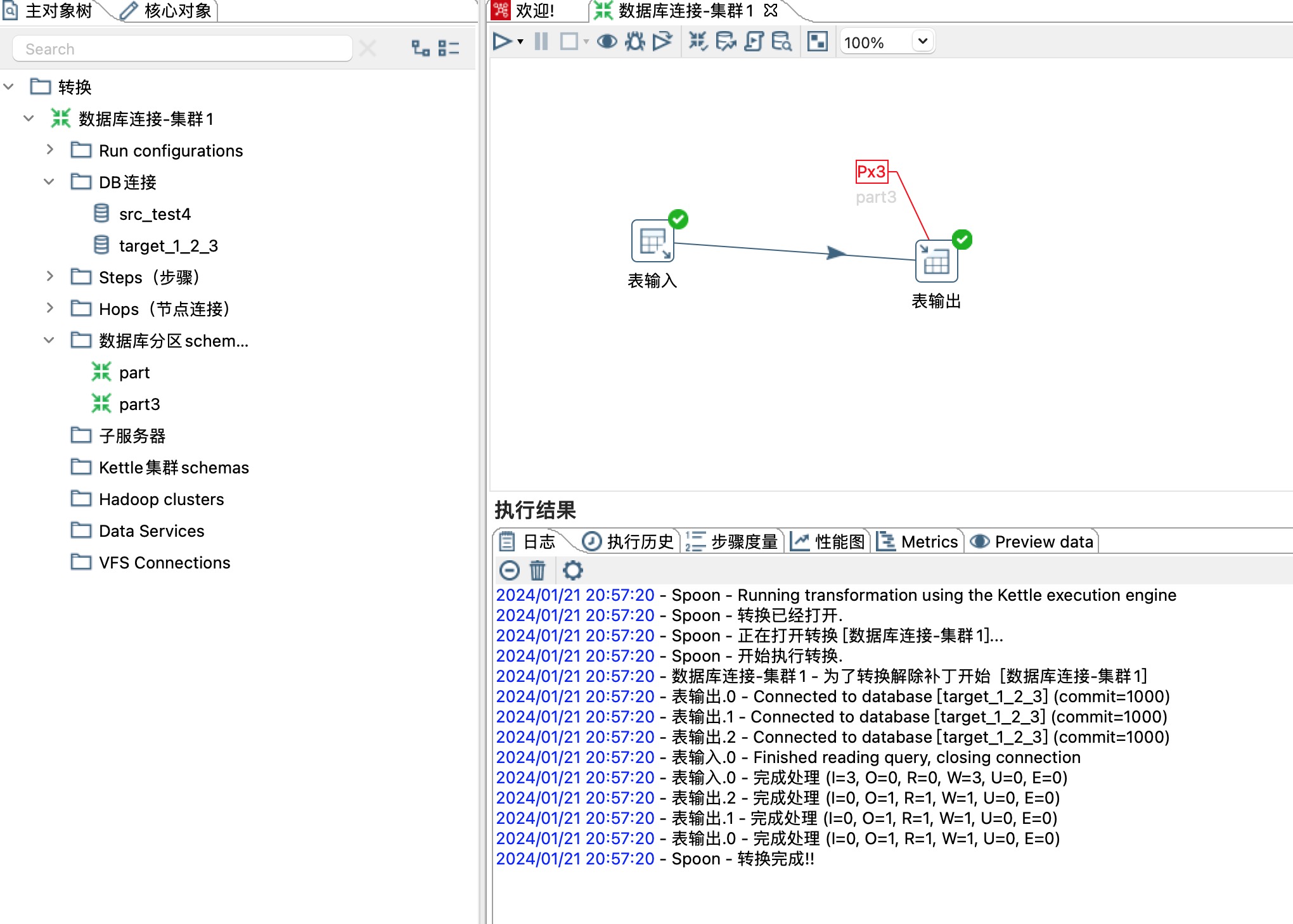
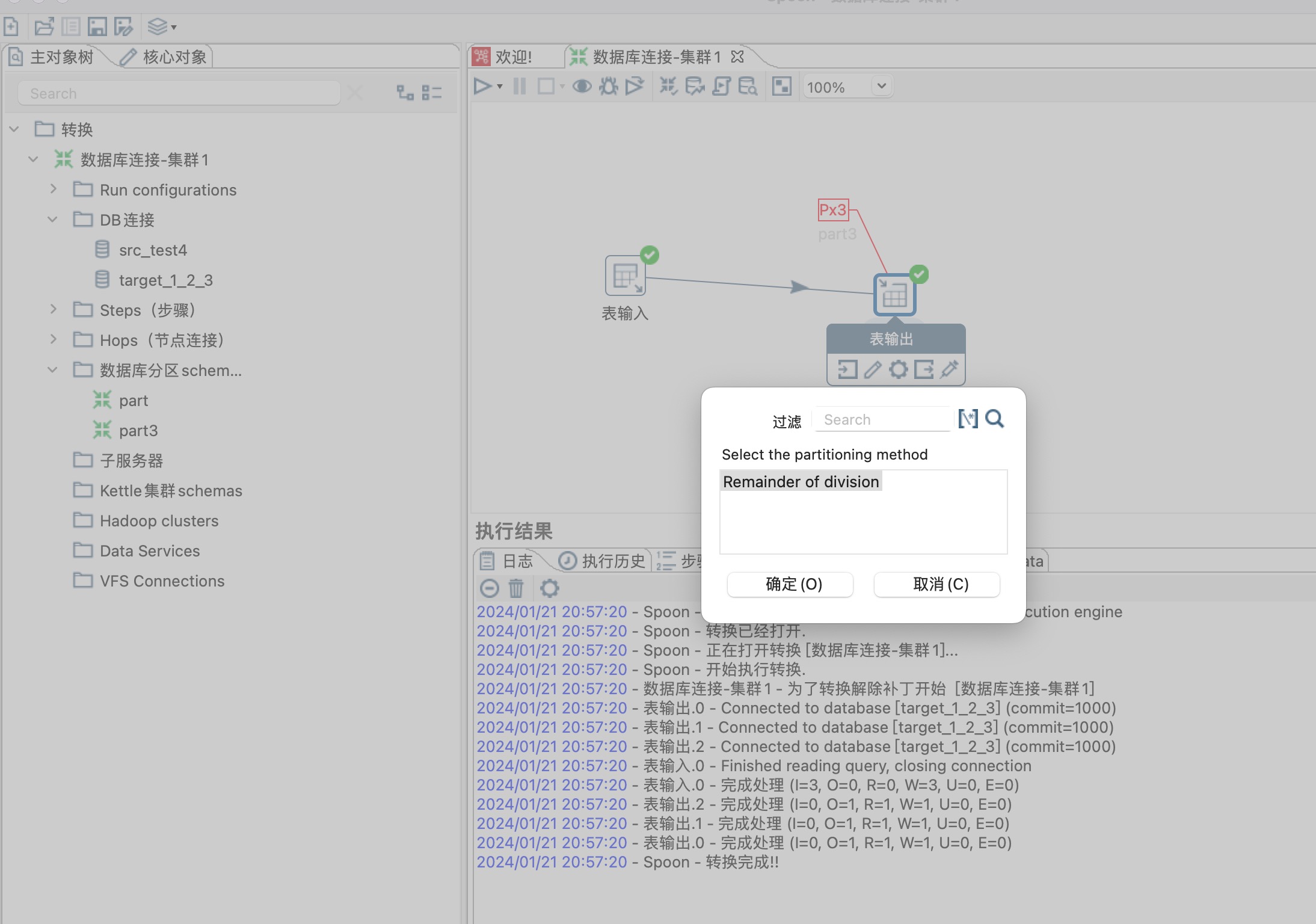
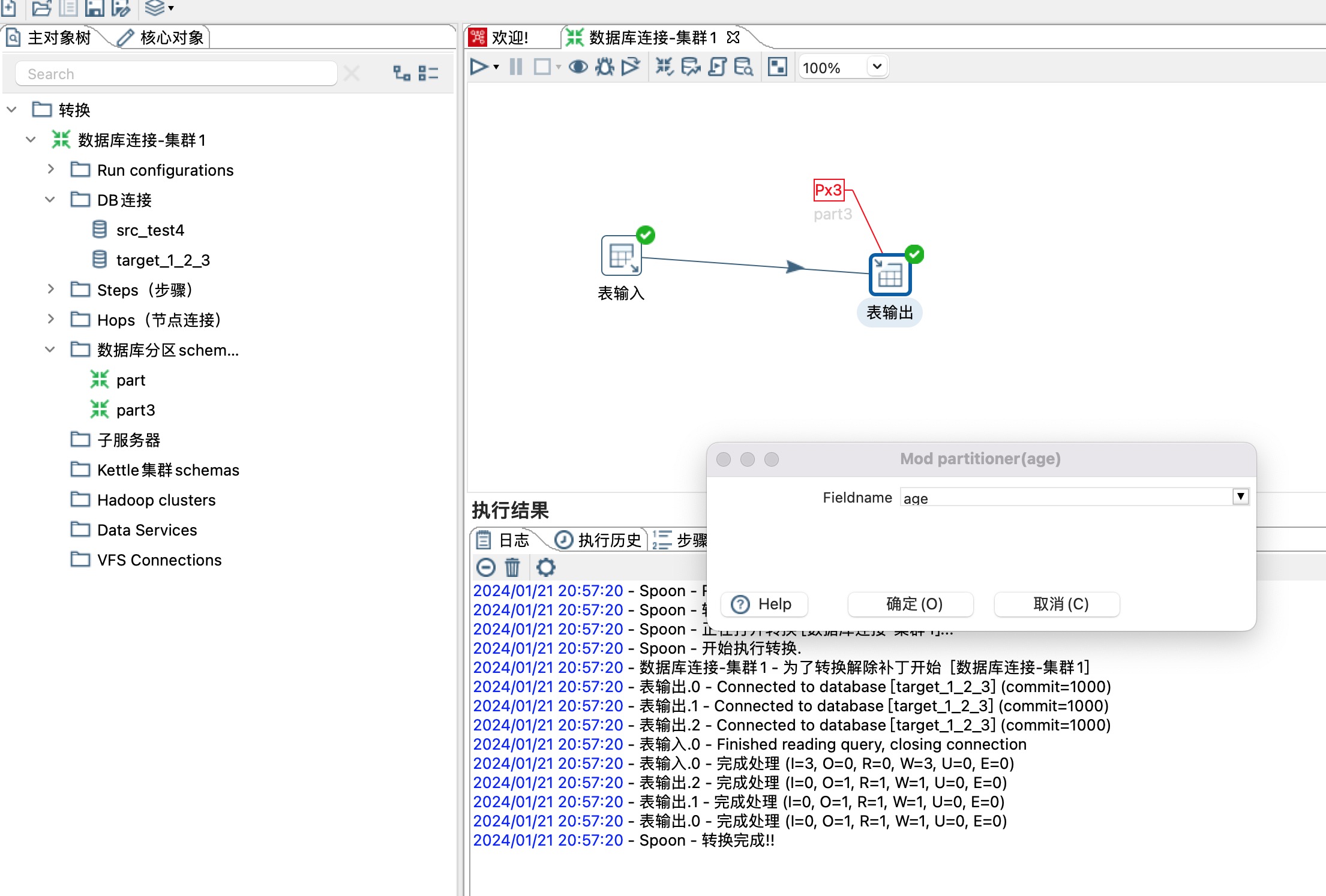
这里分区策略选择Remainder of division,同时选择一个分区路由字段,这里选择age字段,age/分区总数3剩余的商就是数据同步到哪个分区,分区编号从0开始,如下图所示

kettle从入门到精通 第三十二课 mysql 数据连接集群/分区配置的更多相关文章
- NeHe OpenGL教程 第三十二课:拾取游戏
转自[翻译]NeHe OpenGL 教程 前言 声明,此 NeHe OpenGL教程系列文章由51博客yarin翻译(2010-08-19),本博客为转载并稍加整理与修改.对NeHe的OpenGL管线 ...
- 第三十二课:JSDeferred的性能提速
大家如果看了前面两课,就知道Deferred的静态方法next(next_default)是用setTimeout实现的(有浏览器最小时钟间隔).但是实现这种异步操作,可以有很多种方法.JSDefer ...
- 潭州课堂25班:Ph201805201 django 项目 第三十八课 后台 文章发布,FastDFS安装 配置(课堂笔记)
, .安装FastDFS # 从docker hub中拉取fastdfs镜像docker pull youkou1/fastdfs # 查看镜像是否拉取成功docker images # 安装trac ...
- python第三十二课——队列
队列:满足特点 --> 先进先出,类似于我们生活中的买票.安检 [注意] 对于队列而言:python中有为其封装特定的函数,在collections模块中的deque函数就可以获取一个队列对象; ...
- 潭州课堂25班:Ph201805201 django 项目 第三十二课 后台站点管理(课堂笔记)
一.后台站点模版抽取 1.获取静态站点模版 可以使用git clone到本地 git clone https://github.com/almasaeed2010/AdminLTE.git 也可以在g ...
- 第三十二课 linux内核链表剖析
__builtin_prefetch是gcc扩展的,用来提高访问效率,需要硬件的支持. 在标准C语言中是不允许static inline联合使用的. 删除依赖的头文件,将相应的结构拷贝到LinuxLi ...
- python第三十二课——栈
栈:满足特点 --> 先进后出,类似于我们生活中的子弹夹 [注意] 对于栈结构而言:python中没有为其封装特定的函数,我们可以使用list(列表)来模拟栈的特点 使用list对象来模拟栈结构 ...
- JAVA学习第三十二课(经常使用对象API)- 基本数据类型对象包装类
将基本数据类型(8种:int..)封装成对象的优点就是能够在对象中封装很多其它的功能和方法来操控该数据 常见的操作就是:用于基本数据类型与字符串之间的转换 基本数据类型对象包装类一般用于基本类型和字符 ...
- 三十二、MySQL 导出数据
MySQL 导出数据 MySQL中你可以使用SELECT...INTO OUTFILE语句来简单的导出数据到文本文件上. 使用 SELECT ... INTO OUTFILE 语句导出数据 以下实例中 ...
- Python学习第二十二课——Mysql 表记录的一些基本操作 (增删改)
记录基本操作: 增:(insert into) 基本语法: insert into 表名(字段) values(对应字段的值): 例子1: insert into employee(id,name,a ...
随机推荐
- 【Oracle】使用PL/SQL快速查询出1-9数字
[Oracle]使用PL/SQL快速查询出1-9数字 简单来说,直接Recursive WITH Clauses 在Oracle 里面就直接使用WITH result(参数)即可 WITH resul ...
- 力扣191(java)-位1的个数(简单)
题目: 编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 '1' 的个数(也被称为汉明重量). 提示: 请注意,在某些语言(如 Java)中,没有无符号整数类型. ...
- 阿里云AHAS Chaos:应用及业务高可用提升工具平台之故障演练
简介: 阿里云AHAS Chaos:应用及业务高可用提升工具平台之故障演练 应用高可用服务AHAS及故障演练AHAS Chaos 应用高可用服务(Application High Availabili ...
- dotnet Roslyn 通过读取 suo 文件获取解决方案的启动项目
本文来告诉大家一个黑科技,通过 .suo 文件读取 VisualStudio 的启动项目.在 sln 项目里面,都会生成对应的 suo 文件,这个文件是 OLE 格式的文件,文件的格式没有公开,本文的 ...
- jumpserver-v3搭建配置与使用
一.jumpserver简介 官网:https://www.jumpserver.org/ 文档:https://docs.jumpserver.org/zh/v3/ 单机部署:https://doc ...
- 1.权限控制RBAC
官方参考地址:https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/rbac/#privilege-escalation-prev ...
- React项目中报错:Parsing error: The keyword 'import' is reservedeslint
记得更改完配置后,要重启编辑器(如:VSCode)!!! 记得更改完配置后,要重启编辑器(如:VSCode)!!! 记得更改完配置后,要重启编辑器(如:VSCode)!!! 这个错误通常发生在你尝试在 ...
- 基于Node.js+MySQL开发的开源微信小程序商城(微信小程序)部署环境
在网上搜到小程序设计的项目,下载前辈的代码到本地环境,接下来需要如何部署代码到本地,并能够看到完整的效果展示. 服务器端: https://github.com/tumobi/nideshop Nid ...
- iceoryx源码阅读(一)——全局概览
一.什么是iceoryx iceoryx是一套基于共享内存实现的进程间通信组件. 二.源码结构 iceoryx源码包括若干工程,整理如下表所示: 下图展示了主要项目之间的依赖(FROM:iceoryx ...
- jeecg-boot中分页接口用自定义sql和list实现
1.controller中 @ApiOperation(value="分析仪工作状态和报警-3列-分页", notes="分析仪工作状态和报警状态-分页") @ ...