postman导入请求到jmeter进行简单压测,开发同学一学就会
背景
这个事情也是最近做的,因为线上nginx被我换成了openresty,然后接入层服务也做了较大改动,虽然我们这个app(内部办公类)并发不算高,但好歹还是压测一下,上线时心里也稳一点。
于是用jmeter简单压测下看看,这里记录一下。
这次也就找了几个接口来压:登录接口、登录后获取用户信息接口、登录后写数据的一个接口。
因为这几个接口,在postman里面有,我就懒得手工录入到jmeter了(那种form表单,懒得一个一个弄),唯一需要解决的就是,能不能把postman里面的请求导出,然后导入到jmeter里面。
postman请求导入jmeter
postman导出
简单提一句,如果请求在postman里没有,也可以用抓包方式(charles、fiddler),在charles里将请求导出为curl格式,然后导入到postman里面。
postman导入jmeter的方式也比较简单,网上有人写了个开源库来做这个事情。
先导出:
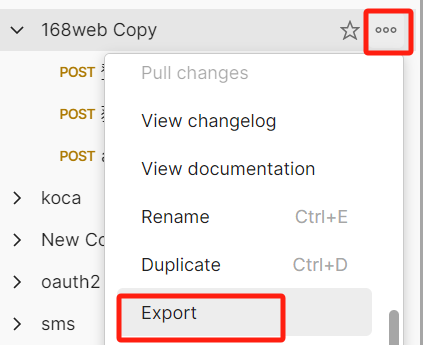
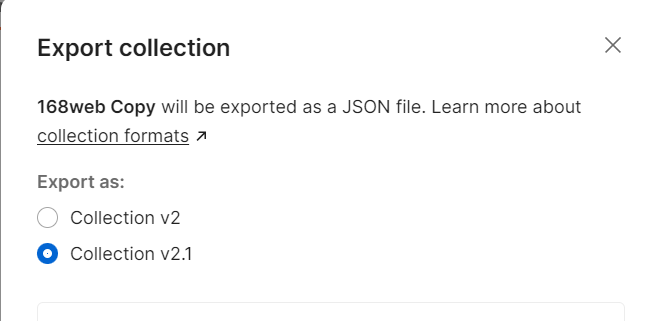
最终会得到一个json文件。
转换json文件为jmeter的jmx
使用了开源库,也是java写的:
https://github.com/Loadium/postman2jmx
我用的时候,因为我postman里面有个请求有点问题,导致报了空指针,然后自己debug了下,解决了,所以大家可以拉我的仓库也行:
https://github.com/cctvckl/postman2jmx
我也顺便给原仓库提了个pr。
使用方式:
$ git clone https://github.com/Loadium/postman2jmx.git
$ cd postman2jmx
$ mvn package
$ cd target/Postman2Jmx
$ java -jar Postman2Jmx.jar my_postman_collection.json my_jmx_file.jmx
正常的话,最终就会得到一个my_jmx_file.jmx文件,导入jmeter即可。
jmeter配置
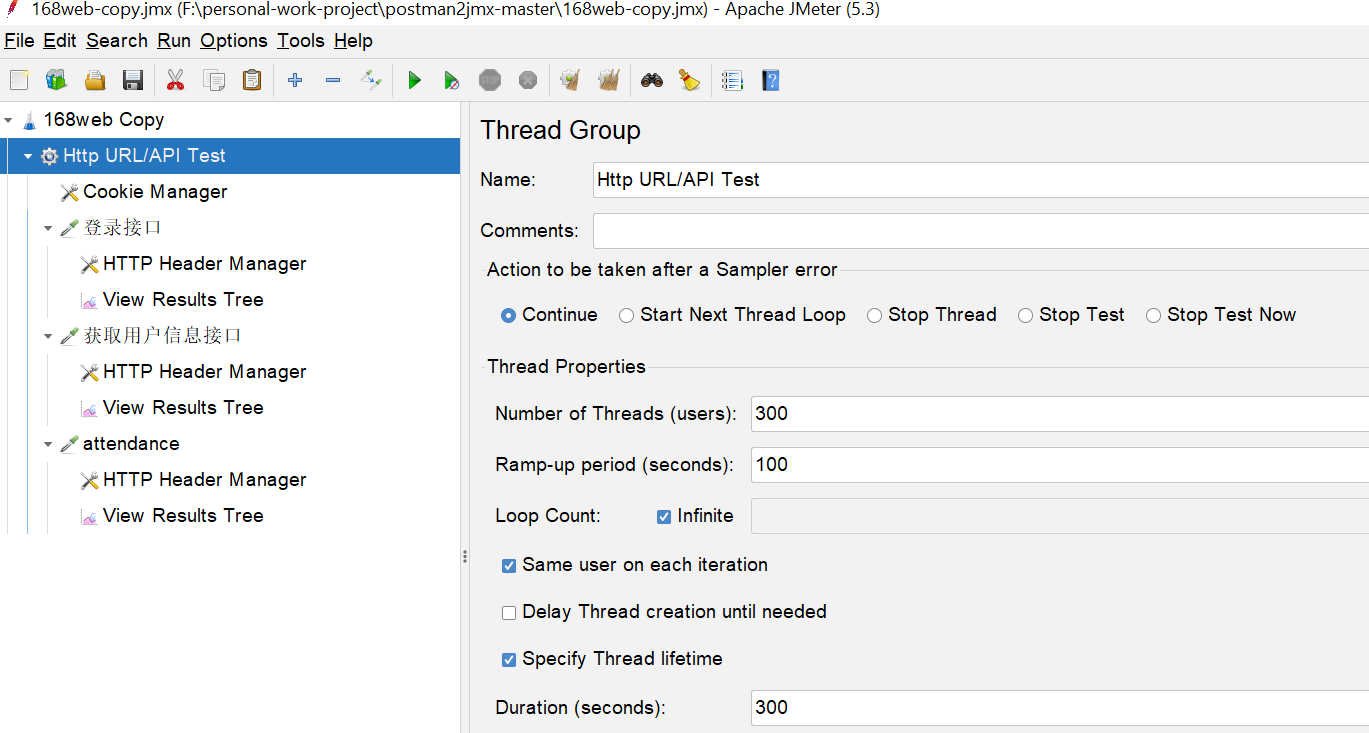
导入效果
打开这个jmx后,个人做了一点点修改,加了个查看结果数,改了下线程组配置,大概如下:
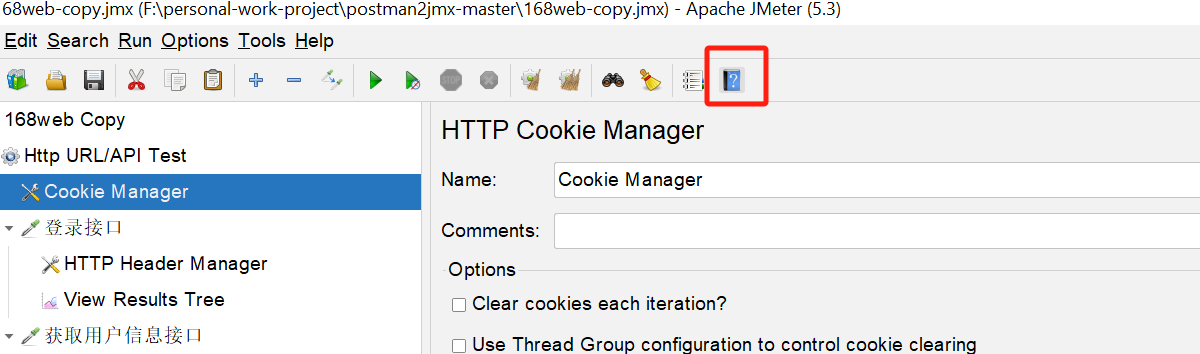
我这边项目还是依赖cookie 机制的,所以我这边就用了cookie manager,它会自动把返回中的set-cookie,存储到该线程的cookie区域,后续的请求也会自动携带:
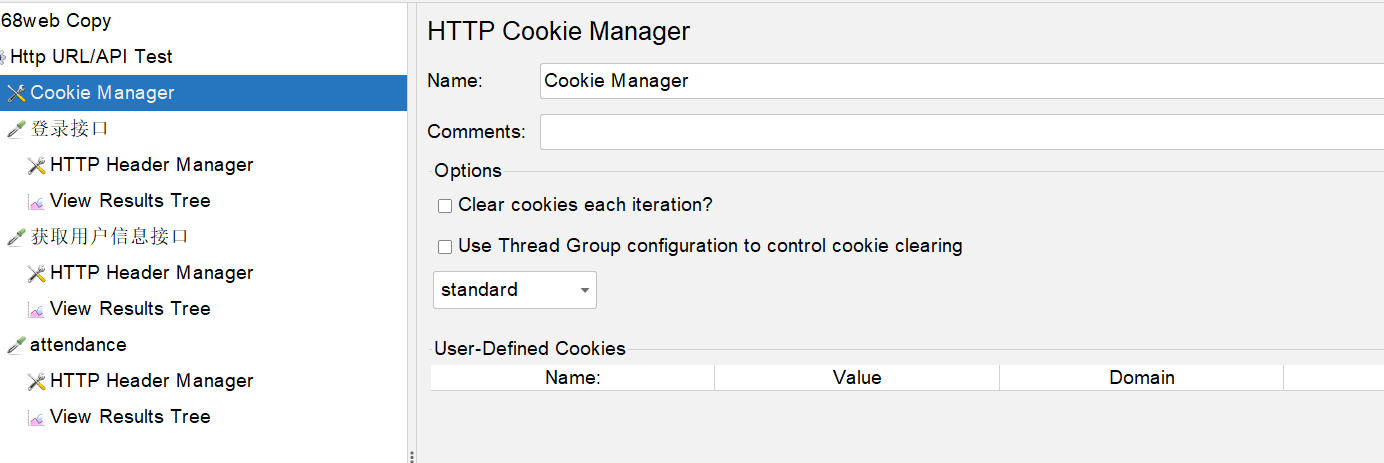
如果不了解,可以在该页面点击Help,就能看到帮助文档。
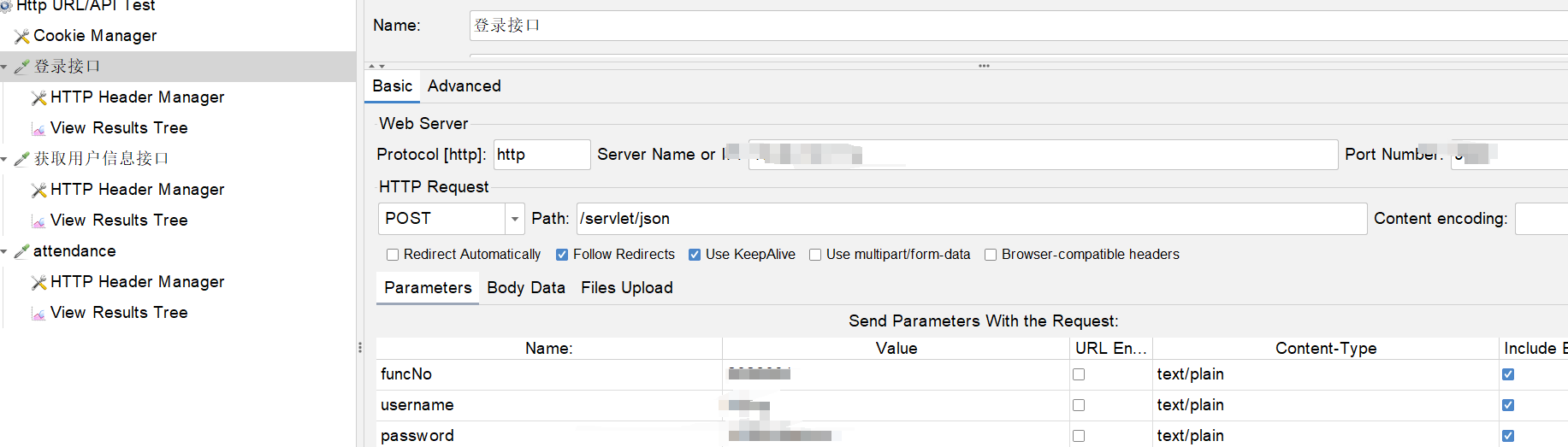
导入的效果还是挺好的:
线程组中并发线程数的设置
一般来说,压测的话,我们会关注某个接口的qps或tps,此时一般要增加一个listener,如聚合报告,来查看最终接口的吞吐(tps):
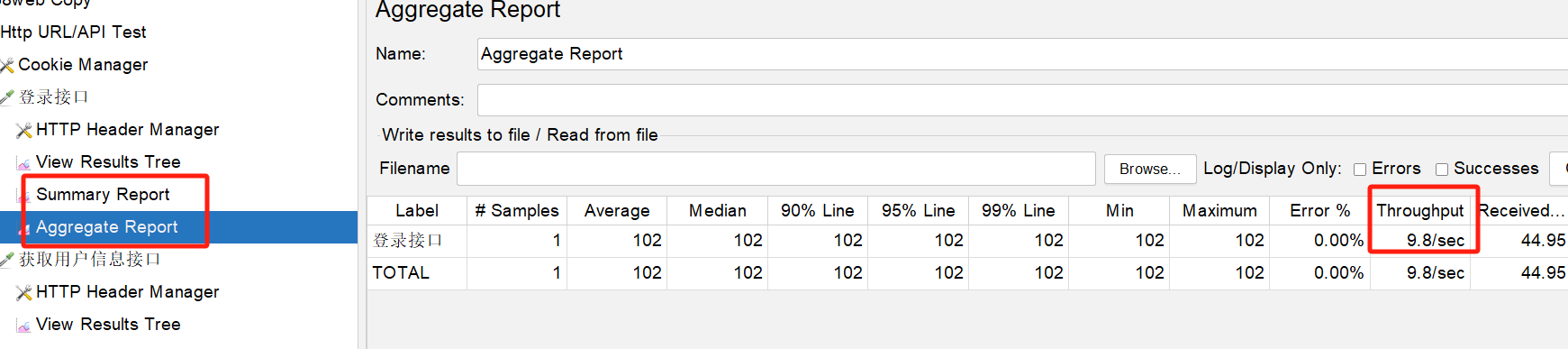
我们一般用jmeter做压测的目的,是我需要压测出,在目前架构、环境下,该接口的极限是多少,能达到多少笔/s,此时,就是靠不断地加压(比如提高并发用户数),在压力越来越大的情况下,系统一开始可能Throughput的值是一路增加的,但慢慢地,会到达一个拐点,到了这个点,你再加压,Throughout也不会继续增加了,此时,就拿到了极限tps。
当然,我们也可能加压到一定程度,发现接口的tps达标了,就不管了,不会继续加压,去寻找那个压力不断提升下的tps拐点。
但是,我之前一直有个问题,就是不知道jmeter里的并发线程数怎么设置,经过查阅,发现在性能测试领域,业内一般把这个值叫做 VU(virtual user)。
这个值,性能测试人员在做测试计划的时候,就会先去根据系统的使用人员规模、系统的高峰时间有多长,来进行估算,总的来说,还是有点复杂。我这边也是看了一本书,全栈性能测试修炼宝典,里面第7章讲了具体怎么算。
我这边也网上简单查了下,比如:
https://www.cnblogs.com/gltou/p/15168252.html
通用公式
对绝大多数场景,我们用:
并发量=(用户总量/统计时间)*影响因子(一般为3)来进行估算。
#用户总量和统计时间使用2/8原则计算,即80%的用户集中在20%的时间
#影响因子,一般为3,根据实际情况来
#通用公式使用了二八原则,计算的并发量即是峰值并发量。
例子
以乘坐地铁为例子,每天乘坐人数为5万人次,每天早高峰是7到9点,晚高峰是6到7点,根据2/8原则,80%的乘客会在高峰期间乘坐地铁,则每秒到达地铁检票口的人数为50000*80%/(3小时*60*60s)=3.7,约4人/S,考虑到安检,入口关闭等因素,实际堆积在检票口的人数肯定比这个要大,假定每个人需要3秒才能进站,那实际并发应为4人/s*3s=12,当然影响因子可以根据实际情况增大!
它这个地铁的例子中,算出来并发用户就应该设置为12.
然后,另一个文章里的例子,这种是根据PV来计算:
根据PV计算
并发量=(日PV/统计时间)*影响因子(一般为3)
#日PV和统计时间使用2/8原则计算,即80%的用户集中在20%的时间
#影响因子,一般为3,根据实际情况来
#PV公式使用了二八原则,计算的并发量即是峰值并发量。
例子
比如一个网站,每天的PV大概1000w,根据2/8原则,我们可以认为这1000w,pv的80%是在一天的9个小时内完成的(人的精力有限),那么TPS为:1000w*80%/(9*60*60)=246.92个/s,取经验因子3,则并发量应为:246.92*3=740
所以,最终算出来,其实并发用户数也不是很高,一般的系统,感觉jmeter里的并发线程数控制在500内就够了,再不行的话,1000内都足够了。如果超出1000了,看看是不是考虑用多个jmeter实例进行分布式压测,因为一般像大公司那种比较大的业务,压测都是分布式压测,压测机集群都好几十台起步。
当然,如果非要拼命在单个jmeter实例(也就是一个java进程)提升线程数,可以看看下面这篇文章:
https://www.blazemeter.com/blog/jmeter-maximum-concurrent-users
看看是如何靠增加堆大小之类,来提升到10000个线程的,不过我反正是不建议,毕竟机器一般也才几核、几十核为主,开那么多线程会导致频繁的线程切换。
线程组中其他属性的设置
以下图为例:
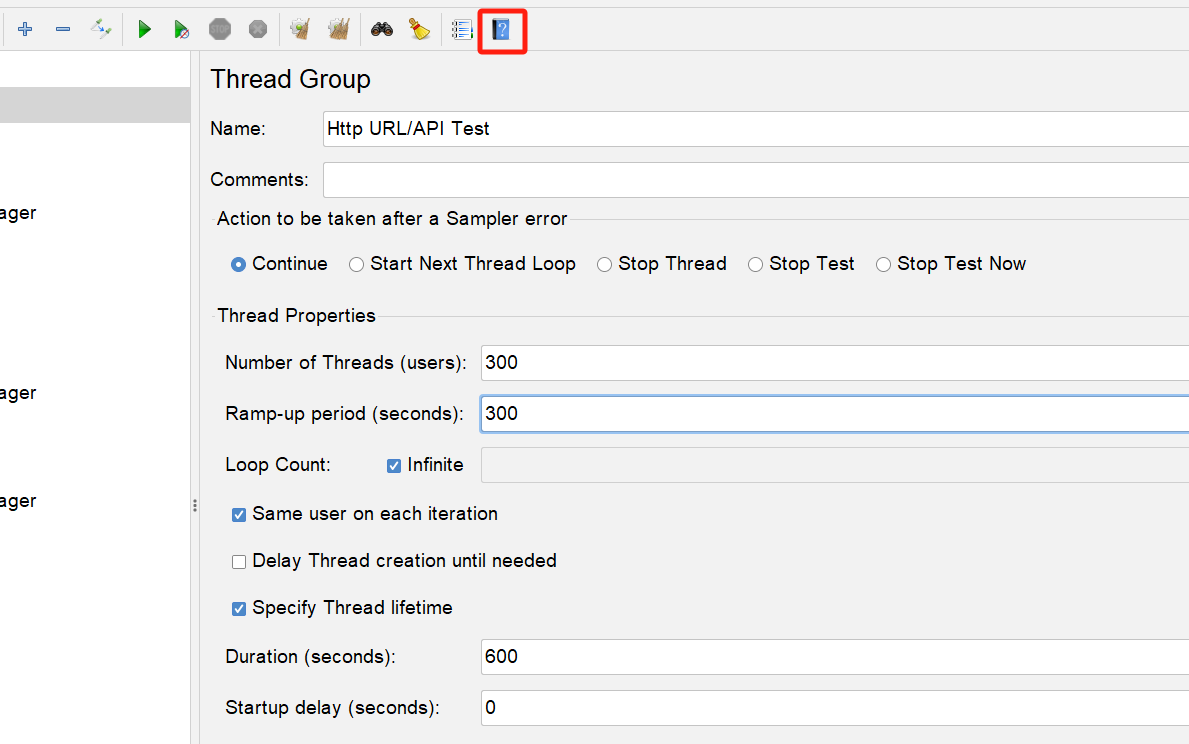
300个线程,但是Ramp-up period 是300s,意思是在300s内将我那300个线程启动起来,也就是1s增加1个;如果你设为1的话,300个线程就会在1s内启动,我感觉对电脑冲击比较大,还是平缓一点好。
Loop count我这里是设置为无限,那,难道整个脚本就一直跑吗,当然不是,可以看到,我上图设置了Duration为600s,也就是说,脚本总共跑10分钟。
可以预测的是:
在前300s,会逐步从1个线程增加到300个线程;在后面300s,就是300个线程同时去跑脚本,这时候的压力是稳定的300 virtual user或者说300线程产生的并发。
jmeter运行
严格压测时,我们一般不在GUI里面去运行,而是采用cli方式。
比如,在windows下用cli方式压测:
F:\apache-jmeter-5.2.1\bin>jmeter -n -t Test.jmx -l result.jtl -j test.log
或者在linux下压测:
./jmeter -n -t Test.jmx -l result.jtl
长时间压测
nohup ./jmeter -n -t Test.jmx -l result.jtl 2>&1 &
压测时,会产生这样的输出:
summary = 3801 in 00:00:40 = 94.5/s Avg: 417 Min: 13 Max: 3817 Err: 0 (0.00%)
表示现在是压测开始后的第40s,3801是总共发出去的请求,94.5/s是这期间的tps,后面就是平均数、最小、最大、错误数
过一阵后,会连着出现这样的:
summary + 2590 in 00:00:35 = 74.3/s Avg: 1076 Min: 97 Max: 9799 Err: 0 (0.00%) Active: 151 Started: 151 Finished: 0
summary = 6391 in 00:01:15 = 85.1/s Avg: 684 Min: 13 Max: 9799 Err: 0 (0.00%)
为+的那一行,表示的是增量,从上一行结束后,过去了35s,这35s期间产生了2590个请求,这期间的tps是74.3
为=的那一行,就是从脚本开始到目前为止,总的指标,如6391这个请求数,就是40s时候的请求数3801 + 增量的2590.
顺便给大家看下,我这次上线前,为了测试下稳定性,压了18个小时:
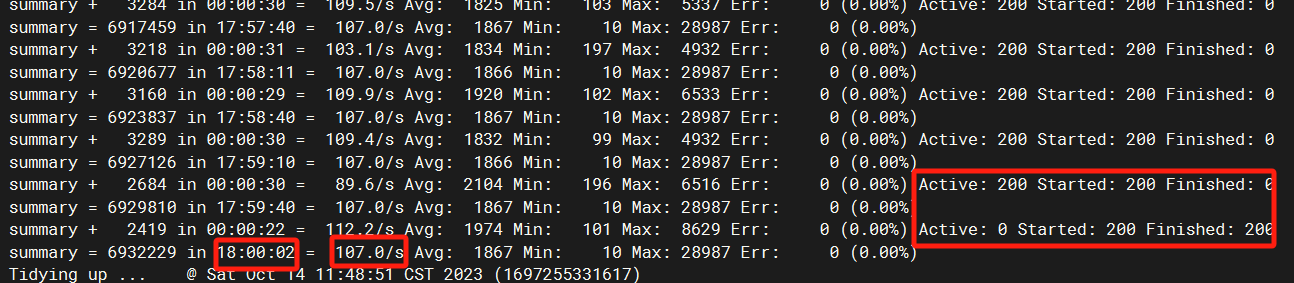
另外,后面的Active那些就是活跃线程数,我是用200并发压了18小时,第二天去,发现系统还是挺稳定。
postman导入请求到jmeter进行简单压测,开发同学一学就会的更多相关文章
- jmeter简单压测、下载文件
一.jmeter做简单压测(单机) 1.添加需要压测的HTTP请求 2.添加聚合报告 3.设置压测场景 4.查看聚合报告 二.多机同时进行压测 1.在需要连接的电脑上打开jmeter bin目录下的 ...
- jmeter之登录接口的一次简单压测与分析
前言:登录接口的一次简单压测与分析 1.接口文档 2.配置元件 3.结果分析 1.接口文档 a.拿到接口文档 接口地址:http://localhost:8080/jpress/admin/login ...
- 1. 堪比JMeter的.Net压测工具 - Crank 入门篇
目录 堪比JMeter的.Net压测工具 - Crank 入门篇 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml 堪比JMeter的.Net压测工具 - Crank 进阶篇 ...
- 3. 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识bombardier
目录 堪比JMeter的.Net压测工具 - Crank 入门篇 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml 堪比JMeter的.Net压测工具 - Crank 进阶篇 ...
- 5. 堪比JMeter的.Net压测工具 - Crank 实战篇 - 接口以及场景压测
目录 堪比JMeter的.Net压测工具 - Crank 入门篇 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml 堪比JMeter的.Net压测工具 - Crank 进阶篇 ...
- 6. 堪比JMeter的.Net压测工具 - Crank 实战篇 - 收集诊断跟踪信息与如何分析瓶颈
目录 堪比JMeter的.Net压测工具 - Crank 入门篇 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml 堪比JMeter的.Net压测工具 - Crank 进阶篇 ...
- 7. 堪比JMeter的.Net压测工具 - Crank 总结篇 - crank带来了什么
目录 堪比JMeter的.Net压测工具 - Crank 入门篇 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml 堪比JMeter的.Net压测工具 - Crank 进阶篇 ...
- 2. 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml
目录 堪比JMeter的.Net压测工具 - Crank 入门篇 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml 堪比JMeter的.Net压测工具 - Crank 进阶篇 ...
- 4. 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识wrk、wrk2
目录 堪比JMeter的.Net压测工具 - Crank 入门篇 堪比JMeter的.Net压测工具 - Crank 进阶篇 - 认识yml 堪比JMeter的.Net压测工具 - Crank 进阶篇 ...
- jmeter的dubbo压测,依赖jar包要放到执行机的lib/ext下
对于jmeter的dubbo压测场景的master-slave结构: 即master的jmeter进行任务的下发和报告的生成,slave进行任务的执行 因为dubbo压测需要依赖很多三方jar包,那么 ...
随机推荐
- [渗透测试]—7.1 漏洞利用开发和Shellcode编写
在本章节中,我们将学习漏洞利用开发和Shellcode编写的基本概念和技巧.我们会尽量详细.通俗易懂地讲解,并提供尽可能多的实例. 7.1 漏洞利用开发 漏洞利用开发是渗透测试中的高级技能.当你发现一 ...
- 如何将mp4文件解复用并且解码为单独的.yuv图像序列以及.pcm音频采样数据?
一.初始化解复用器 在音视频的解复用的过程中,有一个非常重要的结构体AVFormatContext,即输入文件的上下文句柄结构,代表当前打开的输入文件或流.我们可以将输入文件的路径以及AVFormat ...
- 每日一题 力扣 1090 https://leetcode.cn/problems/largest-values-from-labels/
每日一题 力扣 1090 https://leetcode.cn/problems/largest-values-from-labels/ 先对这道题目进行排序,贪心一下,要求分数最高的放在前面,而标 ...
- Java版人脸跟踪三部曲之三:编码实战
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 作为<Java版人脸跟踪三部曲> ...
- pod setup 慢 的问题
由于更换了硬盘,重装了系统,需要重新配置环境,发现现在安装cocapods比之前坑更深了, 装环境时遇到pod setup才几kb的下载速度(即使用梯子也是巨慢),实在是没法用在网上尝试了各种方法,但 ...
- 如何在Avalonia11中设置自定义字体
如何在Avalonia11中设置自定义字体 由于avalonia默认的中文字体显示的效果不太理想,我们需要下载一些自定义的字体,来优化UI的显示效果.avalonia的官方文档地址. 对我在项目中运用 ...
- 如何配置Linux的yum源
一.配置本地yum源 1.挂载光盘 a.建目录 #mkdir /media/cdrom b.挂载光盘 #mount /media/sr0 /media/cdrom c.挂载本地iso文件 #mount ...
- [kvm]创建虚拟机
创建虚拟机示例 # 使用iso创建虚拟机 virt-install --virt-type kvm --os-type=linux --name temp_debian11 \ --memory 16 ...
- Day11:KMP、字典树、AC自动机、后缀数组、manacher
KMP算法 前言 KMP算法是一个著名的字符串匹配算法,效率很高,但是确实有点复杂. 简介 KMP 算法是 D.E.Knuth.J,H,Morris 和 V.R.Pratt 三位神人共同提出的,称之为 ...
- P3874 砍树 题解
前置 树形 dp,二分. 题意 本质上是一个树上背包,需要选不少于 \(k\) 个物品,每个物品有一个重量 \(w\) 和价值 \(v\),求性价比最大值. 分析 既然是性价比,显然是分数规划. 先介 ...