Oracle "脑残" CBO 优化案例
今天晚上下班回来才有空看群,群友发了一条很简单的慢SQL问怎么优化。
非常简单,我自己模拟的数据。
表结构:
-- auto-generated definition
CREATE TABLE HHHHHH
(
ID NUMBER NOT NULL
PRIMARY KEY,
NAME VARCHAR2(20),
PARAGRAPH_ID NUMBER
)
/ CREATE INDEX IDX_1_2_PARAGRAPH_HIST_RULE
ON HHHHHH (PARAGRAPH_ID)
/ CREATE INDEX IDX_1_2_NAME_HIST_RULE
ON HHHHHH (NAME)
/
数据量:
SQL> select count(1) from HHHHHH; COUNT(1)
----------
200002 Elapsed: 00:00:00.00
慢SQL:
SELECT a.* FROM hhhhhh a
WHERE a.name IN (
SELECT name from hhhhhh b
GROUP BY b.name HAVING count(DISTINCT b.paragraph_id) = 1
); Plan hash value: 1063187735 ------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 5 (20)| 00:00:01 |
|* 1 | FILTER | | | | | |
| 2 | TABLE ACCESS FULL | HHHHHH | 1 | 38 | 2 (0)| 00:00:01 |
|* 3 | FILTER | | | | | |
| 4 | HASH GROUP BY | | 1 | 25 | 3 (34)| 00:00:01 |
| 5 | VIEW | VM_NWVW_1 | 1 | 25 | 3 (34)| 00:00:01 |
| 6 | SORT GROUP BY | | 1 | 25 | 3 (34)| 00:00:01 |
| 7 | TABLE ACCESS FULL| HHHHHH | 1 | 25 | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------ Predicate Information (identified by operation id):
--------------------------------------------------- " 1 - filter( EXISTS (SELECT 0 FROM (SELECT ""B"".""PARAGRAPH_ID"" "
" ""$vm_col_1"",""B"".""NAME"" ""$vm_col_2"" FROM ""HHHHHH"" ""B"" GROUP BY "
" ""B"".""NAME"",""B"".""PARAGRAPH_ID"") ""VM_NWVW_1"" GROUP BY ""$vm_col_2"" HAVING "
" ""$vm_col_2""=:B1 AND COUNT(""$vm_col_1"")=1))"
" 3 - filter(""$vm_col_2""=:B1 AND COUNT(""$vm_col_1"")=1)"
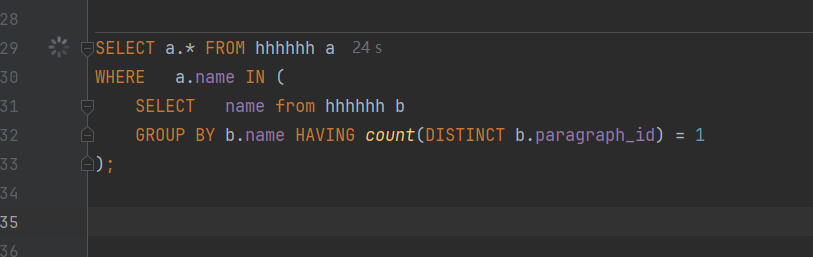
跑了24秒没出结果我就干掉了,正常来说Oracle 这种遥遥领先的数据库,不能100毫秒以内出结果都有问题。
简单看了下上面的计划 Predicate Information 谓词信息,里面信息很复杂,懒得解释(其实我也不懂为啥CBO为啥这样乱分组过滤),并没啥卵用,感觉很SB。
一句话就是CBO等价改写了 EXISTS 还有 :B1这种变量,每次都是传个值到:B1 然后进行filter , 重点是每次。反正各位读者以后在计划中看到这种 :B1 变量都是每次每次,就是一次一次的传值,比较完一个数据继续传。
这种按照 PG 的说法就是复杂的子连接无法提升, GROUP BY b.name HAVING count(DISTINCT b.paragraph_id) = 1 惹得锅。
复杂的子连接无法提升参考 <<PostgreSQL技术内幕:查询优化深度探索 >>这本书 3.2篇章。
加个HINT:
SELECT a.* FROM hhhhhh a
WHERE a.name IN (
SELECT /*+ unnest */ name from hhhhhh b
GROUP BY b.name HAVING count(DISTINCT b.paragraph_id) = 1
5 ); ID NAME PARAGRAPH_ID
---------- -------------------- ------------
200002 aaaaa 10000001 Elapsed: 00:00:00.05 Plan hash value: 3353221841 -------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 50 | 5 (20)| 00:00:01 |
|* 1 | HASH JOIN SEMI | | 1 | 50 | 5 (20)| 00:00:01 |
| 2 | TABLE ACCESS FULL | HHHHHH | 1 | 38 | 2 (0)| 00:00:01 |
| 3 | VIEW | VW_NSO_1 | 1 | 12 | 3 (34)| 00:00:01 |
|* 4 | FILTER | | | | | |
| 5 | HASH GROUP BY | | 1 | 25 | 3 (34)| 00:00:01 |
| 6 | VIEW | VM_NWVW_2 | 1 | 25 | 3 (34)| 00:00:01 |
| 7 | HASH GROUP BY | | 1 | 25 | 3 (34)| 00:00:01 |
| 8 | TABLE ACCESS FULL| HHHHHH | 1 | 25 | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- " 1 - access(""A"".""NAME""=""NAME"")"
" 4 - filter(COUNT(""$vm_col_1"")=1)"
使用HINT将子链接强行提升(展开)以后,秒出。
但是使用HINT容易将执行计划固定住,非必要情况下不推荐。
等价改写该SQL 方式1:
SELECT A.*
FROM HHHHHH A
INNER JOIN (SELECT COUNT(1) BB, NAME
FROM HHHHHH B
5 GROUP BY NAME) B ON A.NAME = B.NAME AND B.BB = 1; ID NAME PARAGRAPH_ID
---------- -------------------- ------------
200002 aaaaa 10000001 Elapsed: 00:00:00.03 Plan hash value: 3909860973 --------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 50 | 5 (20)| 00:00:01 |
|* 1 | HASH JOIN | | 1 | 50 | 5 (20)| 00:00:01 |
| 2 | TABLE ACCESS FULL | HHHHHH | 1 | 38 | 2 (0)| 00:00:01 |
| 3 | VIEW | | 1 | 12 | 3 (34)| 00:00:01 |
|* 4 | FILTER | | | | | |
| 5 | HASH GROUP BY | | 1 | 12 | 3 (34)| 00:00:01 |
| 6 | TABLE ACCESS FULL| HHHHHH | 1 | 12 | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- " 1 - access(""A"".""NAME""=""B"".""NAME"")"
4 - filter(COUNT(*)=1)
改写成 join 以后也是秒出。
等价改写该SQL 方式2:
SELECT X.ID,
X.NAME,
X.PARAGRAPH_ID
FROM (SELECT A.*, COUNT(DISTINCT PARAGRAPH_ID) OVER (PARTITION BY NAME) CNT FROM HHHHHH A) X
5 WHERE X.CNT = 1; ID NAME PARAGRAPH_ID
---------- -------------------- ------------
200002 aaaaa 10000001 Elapsed: 00:00:00.07 Plan hash value: 2750561680 ------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 51 | 3 (34)| 00:00:01 |
|* 1 | VIEW | | 1 | 51 | 3 (34)| 00:00:01 |
| 2 | WINDOW SORT | | 1 | 38 | 3 (34)| 00:00:01 |
| 3 | TABLE ACCESS FULL| HHHHHH | 1 | 38 | 2 (0)| 00:00:01 |
------------------------------------------------------------------------------ Predicate Information (identified by operation id):
--------------------------------------------------- " 1 - filter(""X"".""CNT""=1)"
改写成开窗函数以后也是秒出。
<<PostgreSQL技术内幕:查询优化深度探索 >> 这本书是真的不错,偷偷刷了好几次,每次看完都有新的理解。
Oracle "脑残" CBO 优化案例的更多相关文章
- 【Oracle】CBO优化详解
SQL优化是数据优化的重要方面,本文将分析Oracle自身的CBO优化,即基于成本的优化方法.Oracle为了自动的优化sql语句需要各种统计数据作为优化基础.外面会通过sql的追踪来分析sql的执行 ...
- Oracle中CBO优化器简介
Oracle中CBO优化器简介 Oracle数据库中的优化器是SQL分析和执行的优化工具.它负责制定SQL的执行计划,也就是它负责保证SQL的执行计划的效率最高,比如优化器决定Oracle以什么样的方 ...
- 脑残式网络编程入门(三):HTTP协议必知必会的一些知识
本文原作者:“竹千代”,原文由“玉刚说”写作平台提供写作赞助,原文版权归“玉刚说”微信公众号所有,即时通讯网收录时有改动. 1.前言 无论是即时通讯应用还是传统的信息系统,Http协议都是我们最常打交 ...
- Oracle 课程五之优化器和执行计划
课程目标 完成本课程的学习后,您应该能够: •优化器的作用 •优化器的类型 •优化器的优化步骤 •扫描的基本类型 •表连接的执行计划 •其他运算方式的执行计划 •如何看执行计划顺序 •如何获取执行计划 ...
- mysql优化案例
MySQL优化案例 Mysql5.1大表分区效率测试 Mysql5.1大表分区效率测试MySQL | add at 2009-03-27 12:29:31 by PConline | view:60, ...
- 脑残式网络编程入门(六):什么是公网IP和内网IP?NAT转换又是什么鬼?
本文引用了“帅地”发表于公众号苦逼的码农的技术分享. 1.引言 搞网络通信应用开发的程序员,可能会经常听到外网IP(即互联网IP地址)和内网IP(即局域网IP地址),但他们的区别是什么?又有什么关系呢 ...
- 脑残式网络编程入门(五):每天都在用的Ping命令,它到底是什么?
本文引用了公众号纯洁的微笑作者奎哥的技术文章,感谢原作者的分享. 1.前言 老于网络编程熟手来说,在测试和部署网络通信应用(比如IM聊天.实时音视频等)时,如果发现网络连接超时,第一时间想到的就是 ...
- 脑残式网络编程入门(四):快速理解HTTP/2的服务器推送(Server Push)
本文原作者阮一峰,作者博客:ruanyifeng.com. 1.前言 新一代HTTP/2 协议的主要目的是为了提高网页性能(有关HTTP/2的介绍,请见<从HTTP/0.9到HTTP/2:一文读 ...
- 脑残式网络编程入门(二):我们在读写Socket时,究竟在读写什么?
1.引言 本文接上篇<脑残式网络编程入门(一):跟着动画来学TCP三次握手和四次挥手>,继续脑残式的网络编程知识学习 ^_^. 套接字socket是大多数程序员都非常熟悉的概念,它是计算机 ...
- 脑残式网络编程入门(一):跟着动画来学TCP三次握手和四次挥手
.引言 网络编程中TCP协议的三次握手和四次挥手的问题,在面试中是最为常见的知识点之一.很多读者都知道“三次”和“四次”,但是如果问深入一点,他们往往都无法作出准确回答. 本篇文章尝试使用动画图片的方 ...
随机推荐
- (2)Python解释器的安装
鉴于有同学在安装Python解释器出现了问题,这里再安装一下 step1,下载安装包,链接https://www.python.org/downloads/ 这里我安装的是3.6.4版本 我选择的是6 ...
- drf(视图组件)
一. 前言 Django REST framwork 提供的视图的主要作用 1. 控制序列化器的执行(检验.保存.转换数据) 2. 控制数据库查询的执行 二. 两个视图基类 两个视图基类: APIVi ...
- View事件机制源码分析
目录介绍 01.Android中事件分发顺序 02.Activity的事件分发机制 2.1 源码分析 2.2 点击事件调用顺序 2.3 得出结论 03.ViewGroup事件的分发机制 3.1 看一下 ...
- 说说如何在Vue项目中应用TypeScript?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 一.前言 与link类似 在VUE项目中应用typescript,我们需要引入一个库vue-property-decorator, 其是基 ...
- 记录--css水滴登录界面
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 今天我们来分享一款非常有趣的登录界面,它使用HTML和CSS制作,具有动态的水波纹效果,让用户在登录时感受到了一股清凉之感. 基本h ...
- 面试官:说说Spring中IoC实现原理?
IoC(Inversion of Control)即控制(权)反转,它是一种编程思想,它的核心理念是将对象的创建和管理权力从对象本身转移到外部的容器或框架. IoC 的主要目的是降低代码之间的耦合度, ...
- LiteOS-A内核中的procfs文件系统分析
一. procfs介绍 procfs是类UNIX操作系统中进程文件系统(process file system)的缩写,主要用于通过内核访问进程信息和系统信息,以及可以修改内核参数改变系统行为.需要注 ...
- (数据科学学习手札159)使用ruff对Python代码进行自动美化
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,在日常编写Python代码的过 ...
- HUAWEI AppGallery Connect全新升级,支持HarmonyOS生态全生命周期服务!
原文:https://mp.weixin.qq.com/s/7aNIplUBdm_D1yyiMrQdAw,点击链接查看更多技术内容. HUAWEI AppGallery Connect全新升 ...
- @EnableDiscoveryClient 注解如何实现服务注册与发现
@EnableDiscoveryClient 是如何实现服务注册的?我们首先需要了解 Spring-Cloud-Commons 这个模块,Spring-Cloud-Commons 是 Spring-C ...