机器学习-无监督机器学习-kmeans衍生的算法-18
1. k-Medoids
之前的kmeans算法 对于异常点数据特别敏感,更新中心点的时候,是对于该簇的所有样本点求平均,这种方式对于异常样本特别敏感,

kmedoids算法克服这个问题,实现方式所有属于该簇的样本点每一个维度 取中位数 这样得到新的中心点 就对于异常点没那么敏感了
总结:更新中心点的方法 由求平均改成求中位数
2. 二分KMEANS
为克服K-Means算法收敛于局部最小值问题,提出了二分K-Means算法
- 使用以前的KMEANS算法 k=2, 得到两个簇,两个中心点,
- 选取其中的一个簇,再使用k=2的KMEANS算法,相比上一步,只不过输入的样本换一下而已,选取其中的一个簇,根据一定的指标来选,例如:样本数量大的,需进行再分,或者 SSE总误差更大的
- 重复步骤,直到分类的总数等于目标分类数
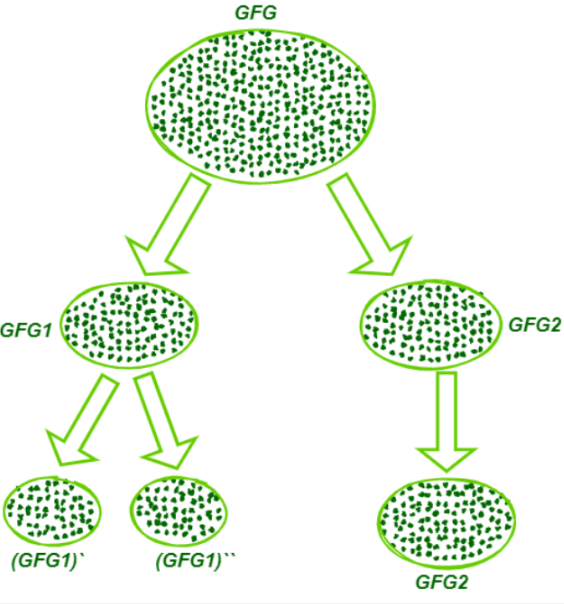
总结:每次分两个簇,选择其中一个簇再分成两个,直到分类的总数=k
3. KMeans++
KMeans++ 与KMeans的不同就是在初始中心点的选取上不同,初始中心点的选取会直接影响算法的收敛,容易只得到局部最优,所以初始中心点的选取就要尽量的相离的分散,如何实现
- 随机选取一个中心点
- 计算其他点到 已知中心点 中最近邻的的距离 根据这个距离 来选择他是否能做为下一个中心点,被选择的概率和计算出来的距离成正比
- 重复2 直到k个中心被选中
实现方式伪代码:
- 已知的中心点 c1, c2, c3
- 对于剩余的样本点 x4,x5,--- ,xn,
拿x4来说: min(d(c1, x4), d(x2, x4), d(c3,x4)) 得到x4 距离已知中心点的最近邻距离 记为 dist4, 依次得到 dist5, ---, distn
将这距离进行归一化操作, 记sum=sum(dist4, dist5, ---, distn)
(dist4, dist5, ---, distn)/sum 记为 (p4, p5, p6, ,,, pn)
将这些距离画在数轴上

np.random.rand() 0-1之间随机的取一个数,看下它落在数轴上的那个位置,则那个样本点就被选中,这也就是为什么距离远远的点越容易被选中。
4. elkan KMeans
由于计算每个样本到 类中心 的距离比较耗时
对于x样本 是属于b中心点还是c中心点 只需要作出判断 不需要全部计算出
利用两边之和大于第三边
假设x是一个点,b和c是中心点


bx 肯定是小于bc x点肯定是分类到b
elkan K-Means比起传统的K-Means迭代速
度有很大的提高。但是如果我们的样本的特征是稀疏的,有缺失值的话,这个方法就不使用了,此时某些距离无法计算,则不能使用该算法
5. min batch KMeans算法
KMeans算法 对所有的样本点 通过计算距离最近 将其划分到对应类 这样会特别耗时
能否只抽取部分的样本 计算距离最近 将其划分到对应类 输出新的中心点
这就叫做mini batch KMeans
与批量梯度下降法 计算梯度类似,计算梯度的时候也只使用部分样本 只要能大致的指明梯度的方向就行 不需要完全精确计算出梯度
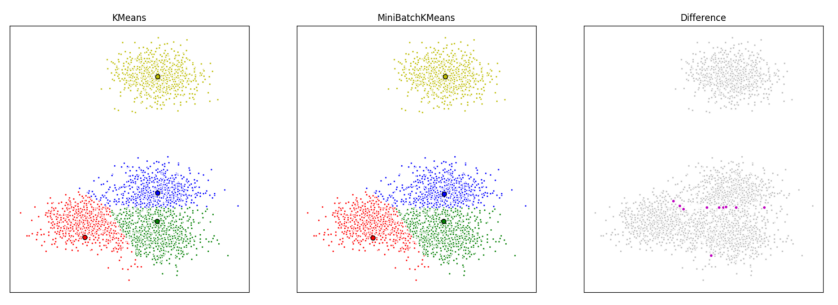
6.小结:
原理比较简单,实现也是很容易,收敛速度快(在大规模数据集上收敛较慢,可尝试使用Mini
Batch K-Means算法)。
1 原理比较简单,实现也是很容易,收敛速度快(在大规模数据集上收敛较慢,可尝试使用MiniBatch K-Means算法)
2 聚类效果较优。
3 算法的可解释度比较强。
4 主要需要调参的参数仅仅是簇数k。
缺点:

机器学习-无监督机器学习-kmeans衍生的算法-18的更多相关文章
- 1(1).有监督 VS 无监督
对比一 : 有标签 vs 无标签 有监督机器学习又被称为“有老师的学习”,所谓的老师就是标签.有监督的过程为先通过已知的训练样本(如已知输入和对应的输出)来训练,从而得到一个最优模型,再将这个模型应用 ...
- 学习笔记CB008:词义消歧、有监督、无监督、语义角色标注、信息检索、TF-IDF、隐含语义索引模型
词义消歧,句子.篇章语义理解基础,必须解决.语言都有大量多种含义词汇.词义消歧,可通过机器学习方法解决.词义消歧有监督机器学习分类算法,判断词义所属分类.词义消歧无监督机器学习聚类算法,把词义聚成多类 ...
- 深度学习——无监督,自动编码器——尽管自动编码器与 PCA 很相似,but自动编码器既能表征线性变换,也能表征非线性变换;而 PCA 只能执行线性变换
自动编码器是一种有三层的神经网络:输入层.隐藏层(编码层)和解码层.该网络的目的是重构其输入,使其隐藏层学习到该输入的良好表征. 自动编码器神经网络是一种无监督机器学习算法,其应用了反向传播,可将目标 ...
- darktrace 亮点是使用的无监督学习(贝叶斯网络、聚类、递归贝叶斯估计)发现未知威胁——使用无人监督 机器学习反而允许系统发现罕见的和以前看不见的威胁,这些威胁本身并不依赖 不完善的训练数据集。 学习正常数据,发现异常!
先说说他们的产品:企业免疫系统(基于异常发现来识别威胁) 可以看到是面向企业内部安全的! 优点整个网络拓扑的三维可视化企业威胁级别的实时全局概述智能地聚类异常泛频谱观测 - 高阶网络拓扑;特定群集,子 ...
- <机器学习>无监督学习算法总结
本文仅对常见的无监督学习算法进行了简单讲述,其他的如自动编码器,受限玻尔兹曼机用于无监督学习,神经网络用于无监督学习等未包括.同时虽然整体上分为了聚类和降维两大类,但实际上这两类并非完全正交,很多地方 ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- 机器学习实战 - 读书笔记(11) - 使用Apriori算法进行关联分析
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第11章 - 使用Apriori算法进行关联分析. 基本概念 关联分析(associat ...
- R语言︱机器学习模型评估方案(以随机森林算法为例)
笔者寄语:本文中大多内容来自<数据挖掘之道>,本文为读书笔记.在刚刚接触机器学习的时候,觉得在监督学习之后,做一个混淆矩阵就已经足够,但是完整的机器学习解决方案并不会如此草率.需要完整的评 ...
- Python机器学习笔记:奇异值分解(SVD)算法
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 奇异值分解(Singu ...
随机推荐
- 如何根据月份查询每月Xxx的总数
我以我的项目根据月份查询每月新增会员的总数为例 Controller @GetMapping("/getMemberReport.do") public R getMemberRe ...
- Lucas定理 、斯特灵公式
斯特灵公式是一条用来取n阶乘的近似值的数学公式. 公式为: 用该公式我们可以用来估算n阶乘的值:估算n阶乘的在任意进制下的位数. 如何计算在R进制下的位数:我们可以结合对数来计算,比如十进制就是lg( ...
- ElasticSearch索引库的增删改查
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/6.8/indices.html 创建索引.设置分片 https://www. ...
- 使用vLLM和ChatGLM3-6b批量推理
当数据量大的时候,比如百万级别,使用 ChatGLM3-6b 推理的速度是很慢的.发现使用 vLLM 和 ChatGLM3-6b 批量推理极大的提高了推理效率.本文主要通过一个简单的例子进行实践. 1 ...
- C++ Qt开发:Charts折线图绑定事件
Qt 是一个跨平台C++图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍QCharts ...
- k8s初始化pod-pod标签
目录 initContainers(初始化容器) 静态pod pod的调度策略(将pod指派给特定节点) initContainers(初始化容器) k8s在1.3版本的时候引入了一个初始化容器(in ...
- 如何构建一个 NodeJS 影院微服务并使用 Docker 部署
如何构建一个 NodeJS 影院微服务并使用 Docker 部署 前言 如何构建一个 NodeJS 影院微服务并使用 Docker 部署.在这个系列中,将构建一个 NodeJS 微服务,并使用 Doc ...
- JavaImprove--Lesson05--Arrays,对象排序,Lambda表达式,方法引用简化Lambda表达式
一.Arrays 用来操作数组的一个工具类 在Java中,没有内置的"Arrays工具类",但有一个名为java.util.Arrays的类,它包含了一些用于操作数组的静态方法.这 ...
- Windows环境下为Android编译OpenCV4.3
Windows环境下为Android编译OpenCV4.3 踩了三四天的坑,今天终于顺利跑通了,原来是toolchain的问题,外网的教程大多都是用opencv source里的toolchain,会 ...
- 万万没想到,我在夜市地摊解决了MySQL临时表空间难题~~
都说"大隐隐于市,高手在深宫".突如其来的"摆地摊"风潮,让原本冷清的街道热闹非凡,也让众人发现了那些神龙见首不见尾的大神们. 这不,小毛在下班的途中就遇到了大 ...