如何使用参数化查询提高Cypher查询的性能
摘要:在DBMS中,参数化查询被视为一种有效预防SQL注入攻击的手段。
本文分享自华为云社区《使用参数化查询提高Cypher查询的性能:以华为云图引擎GES为例》,作者: 蜉蝣与海。
在DBMS中,参数化查询被视为一种有效预防SQL注入攻击的手段。华为云图引擎GES提供对gremlin和cypher查询语言的参数化查询支持,使用参数化查询不仅可以防止前端用户随意输入恶意指令影响语句执行,还可以有效利用查询编译缓存,提高查询性能。
参数化查询(Parameterized Query),Wiki中的解释是:客户端在向数据服务端发送和请求查询语句时,在需要填入数值或者用户输入的字符串数据的地方,使用一个变量名来替代,并在请求体中解释每个变量名所指代的内容。在这种情况下,由于变量名指代的内容不会参与SQL语言的查询编译,即使用户输入数据中包含一些破坏性的指令,也不会被数据库运行。
举例说明,使用Cypher-JDBC-Driver访问华为云图引擎,可以进行对应的参数设置:
public static void main(String[] args) throws ClassNotFoundException {
Class.forName("com.huawei.ges.jdbc.Driver");
String url = "jdbc:ges:http://{{graph_ip}}:{{graph_port}}/ges/v1.0/{{project_id}}/graphs/{{graph_name}}/action?action_id=execute-cypher-query";
url = url.replace("{{graph_ip}}", ip).replace("{{graph_port}}",port + "").replace("{{project_id}}", projectId).replace("{{graph_name}}", graphName);
Properties prop = new Properties();
prop.setProperty("X-Auth-Token", token);
prop.setProperty("limit","40");
try(Connection conn = DriverManager.getConnection(url,prop)){
String query = "match (n:movie) where n.genres=? return n.title";
try(PreparedStatement stmt = conn.prepareStatement(query)){
stmt.setString(1, "Comedy");
try(ResultSet rs = stmt.executeQuery()){
while(rs.next()) {
System.out.println(rs.getString("n.title"));
}
}
}
} catch (SQLException e) {
// do something for e.
}
}
其中查询语句中的问号即是JDBC风格的参数化查询变量,后面代码中通过setString方法为其设置一个值“Comedy”。
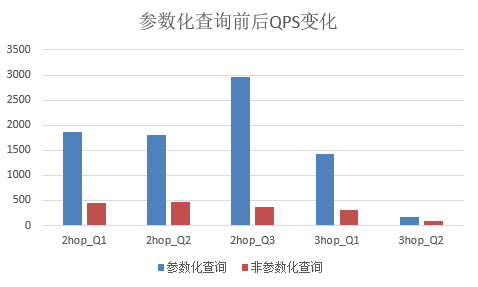
同时,参数化查询可以使得不同的用户输入使用同一条参数化查询语句执行,可以高效利用数据库查询缓存,节省了查询编译时间,从而提升了查询性能。例如,下图是使用Freebase数据集构造的若干2跳3跳查询,在华为云图引擎GES中运行, 参数化查询前后QPS的变化。可以看到使用参数化查询,qps获得了2-8倍的提升。
为什么参数化查询可以提高查询qps?首先要简单介绍下数据服务在收到查询语句后都做了什么。在数据管理领域,数据服务接收到查询语句,往往会进行下列步骤: 词法&语法解析,查询计划生成,查询计划执行,如图。
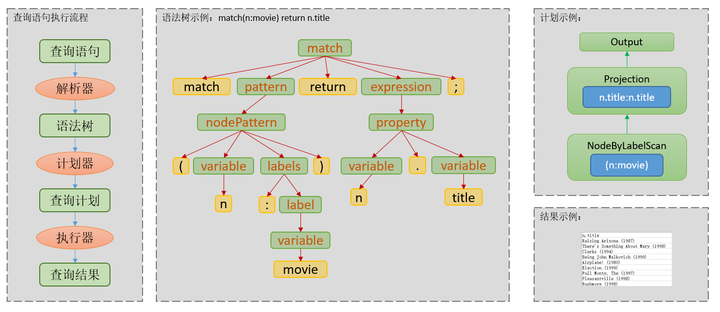
这里简单说一下查询计划生成。现在大多数查询计划的生成策略,要么是基于代价的查询计划生成,要么是基于规则的查询计划生成,或者二者组合使用。而不管是哪种查询计划生成,都是偏向计算密集型的任务,比较耗费服务器的计算资源,同一时间系统只能并行处理有限数目的查询计划生成任务。在计划生成器内部,大多数数据库都会内置查询缓存,即在一定的时间范围内,同一条查询语句输入计划器,计划器优先从查询缓存中检查有无可用计划,如果缓存中生成的计划时间太长或者无可用计划,才会真正执行计划生成的过程。
因此使用参数化查询时,由于使用不同参数的查询语句语句体相同,在查询编译阶段更容易被认为是同一条查询语句, 从而实现“多次查询,一次编译”的效果,也就提高了查询编译效率。
附录:
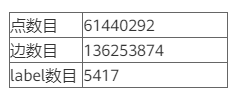
Freebase数据集属性图格式规模:
查询语句:
2hop_Q1: match (n1)-[r]->(m1)-->(p1) where id(n1)=$vertex return id(p1) limit 100
2hop_Q2: match (n1)-[r]->(m1)-->(p1) where id(n1)=$vertex return p1.name limit 100
2hop_Q3: match(n)-[r]->(m)-->(p) where id(n)=$vertex and m.games > 10 and p.name contains 'NBA' return p
3hop_Q1: match (n1)-[r1]-(m1)-[r2]-(p1)--(p2) where id(n1)=$vertex and m1.game > 0 return id(p2) limit 100
3hop_Q2: match (n1)-[r1]-(m1) match (m1)-[r2]-(p1) match (p1)--(p2) where id(n1)=$vertex and m1.games > 0 return id(p2)
相关参考:
[1]参数化查询_百度百科:https://baike.baidu.com/item/%E5%8F%82%E6%95%B0%E5%8C%96%E6%9F%A5%E8%AF%A2/4841802?fr=aladdin
[2]GES cypher API: https://support.huaweicloud.com/api-ges/ges_03_0212.html
[3]Github - opencypher:https://github.com/opencypher/openCypher
如何使用参数化查询提高Cypher查询的性能的更多相关文章
- 并行查询提高sql查询速度
新项目在使用Oracle开发中遇到测试库千万级数据导致数据慢,除去加索引和存储过程可以明显提速外,使用并行也可以提速 select /*+parallel(a,8)*/ a.* from a 加上/* ...
- 提高SQL查询效率(SQL优化)
要提高SQL查询效率where语句条件的先后次序应如何写 http://blog.csdn.net/sforiz/article/details/5345359 我们要做到不但会写SQL,还要做到 ...
- 提高SQL查询效率的常用方法
提高SQL查询效率的常用方法 (1)选择最有效率的表名顺序(只在基于规则的优化器中有效): Oracle的解析器按照从右到左的顺序处理FROM子句中的表名,FROM子句中写在最后的表(基础表 driv ...
- 防SQL注入:生成参数化的通用分页查询语句
原文:防SQL注入:生成参数化的通用分页查询语句 前些时间看了玉开兄的“如此高效通用的分页存储过程是带有sql注入漏洞的”这篇文章,才突然想起某个项目也是使用了累似的通用分页存储过程.使用这种通用的存 ...
- 提高MySQL查询速度
参考百度知道 关于mysql处理百万级以上的数据时如何提高其查询速度的方法 最近一段时间由于工作需要,开始关注针对Mysql数据库的select查询语句的相关优化方法. 由于在参与的实际项目中发现当m ...
- Neo4j使用Cypher查询图形数据
Neo4j使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大,由于Neo4j在图形数据库家族中处于绝对领先的地位,拥有众多的用户基数,使得Cypher成为图形查询语言 ...
- Neo4j 第三篇:Cypher查询入门
本文转载自:https://www.cnblogs.com/ljhdo/p/5516793.html Neo4j使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大,由 ...
- 提高SQL查询效率的30种方法
转载:提高SQL查询效率的30种方法 内容摘录如下: 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中 ...
- 使用Oracle的instr函数与索引配合提高模糊查询的效率
使用Oracle的instr函数与索引配合提高模糊查询的效率 一般来说,在Oracle数据库中,我们对tb表的name字段进行模糊查询会采用下面两种方式:1.select * from tb wher ...
- Redis进阶实践之十八 使用管道模式提高Redis查询的速度
原文:Redis进阶实践之十八 使用管道模式提高Redis查询的速度 一.引言 学习redis 也有一段时间了,该接触的也差不多了.后来有一天,以为同事问我,如何向redis中 ...
随机推荐
- gcd|最大公约数|欧几里得算法|欧几里得算法证明 一文说明白
gcd 最大公因数,也称最大公约数.最大公因子,指两个或多个整数共有约数中最大的一个.a,b的最大公约数记为 $ gcd(a,b) $ ,同样的,a,b,c的最大公约数记为 $ gcd(a,b,c) ...
- 模拟退火算法(SA)
求某个目标函数的最值 爬山法 首先我们通过爬山法来引出模拟退火算法 我们先看一个例子:求函数的最值 我们用爬山法解决这个问题的步骤 1.在解空间中随机生成一个初始解(图中小黄点就是我们生成的初始解) ...
- 使用ResponseSelector实现校园招聘FAQ机器人
本文主要介绍使用ResponseSelector实现校园招聘FAQ机器人,回答面试流程和面试结果查询的FAQ问题.FAQ机器人功能分为业务无关的功能和业务相关的功能2类. 一.data/nlu.y ...
- GCD Inside: GCD 数据结构
1 OS_object OS_object由下面宏OS_OBJECT_DEC_BASE扩展而来: // 1. os/object.h OS_OBJECT_DECL_BASE(object, NSObj ...
- MySQL安装、卸载与初始化
一.MySQL简介 1.MySQL是什么 MySQL 是一款安全.跨平台.高效的,并与 PHP.Java等主流编程语言紧密结合的关系型数据库管理系统.MySQL 的象征符号是一只名为 Sakila 的 ...
- python,opencv-python人脸识别,并且发邮件对镜头前未知人员进行报警
我们在任意一个硬盘的根目录下创建一个Code-project文件夹 在该文件夹下分别创建C-project和Python-project文件夹 在Python-project文件夹下创建face re ...
- MySQL的索引为什么使用B+树而不使用跳表?
目录 MySQL的索引为什么使用B+树而不使用跳表? 1.B+树的结构 2.跳表的结构 3.B+树和跳表的区别 1.B+树新增数据会怎么样 跳表新增数据 4.Mysql的索引为什么使用B+树而不使用跳 ...
- 【外包杯】【报错】(表面解决实际未解决)微信小程序报错:[渲染层错误] TypeError: Cannot read property ‘$$‘ of undefined
半解不解吧,反正实现了就行 渲染层出错,滑动图片组件无法显示,(swiper是轮播图插件,因此错误应该出现在swiper渲染中) 可以这样移动,但是没有图片 我觉得是路径的问题 兄弟们,目前没有解决接 ...
- 在Winform应用中增加通用的业务编码规则生成
在我们很多应用系统中,往往都需要根据实际情况生成一些编码规则,如订单号.入库单号.出库单号.退货单号等等,我们有时候根据规则自行增加一个函数来生成处理,不过我们仔细观察后,发现它们的编码规则有很大的共 ...
- 10 个免费的 AI 图片生成工具分享
原文: https://openaigptguide.com/ai-picture-generator/ 在人工智能(AI)图像生成技术的推动下,各类AI图片生成网站如雨后春笋般涌现,为我们的日常生活 ...