大数据实践解析(下):Spark的读写流程分析
导读:
众所周知,在大数据/数据库领域,数据的存储格式直接影响着系统的读写性能。spark是一种基于内存的快速、通用、可扩展的大数据计算引擎,适用于新时代的数据处理场景。在“大数据实践解析(上):聊一聊spark的文件组织方式”中,我们分析了spark的多种文件存储格式,以及分区和分桶的设计。接下来,本文通过简单的例子来分析在Spark中的读写流程,主要聚焦于Spark中的高效并行读写以及在写过程中如何保证事务性。
1、文件读
如何在Spark中做到高效的查询处理呢?这里主要有两个优化手段:
1)减少不必要的数据处理。数据处理涉及文件的IO以及计算,它们分别需要耗费大量的IO带宽和CPU计算。在实际的生产环境中,这两类资源都是有限的,同时这些操作十分耗时,很容易成为瓶颈,所以减少不必要的数据处理能有效提高查询的效率;
以下面的查询为例:
spark.read.parquet("/data/events")
.where("year = 2019")
.where("city = 'Amsterdam'")
.select("timestamp")
由于在events表中按照year字段做了分区,那么首先通过 year 字段我们就可以过滤掉所有year字段不为 2019 的分区:
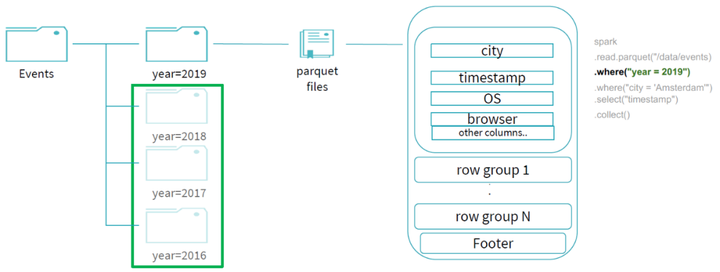
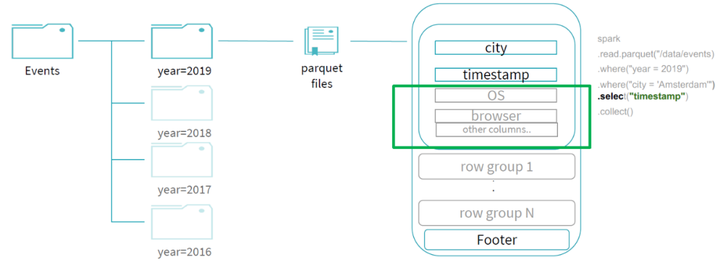
因为文件是parquet的文件格式,通过谓词下推可以帮助我们过滤掉 city 字段不是 "Amsterdam" 的 row groups;同时,由于我们的查询最终需要输出的投影字段只有 "timestamp" ,所以我们可以进行列裁剪优化,不用读取其他不需要的字段,所以最终整个查询所读的数据只有剩下的少部分,过滤掉了大部分的数据,提升了整体的查询效率:
2)并行处理,这里主流的思想分为两类:任务并行和数据并行。任务并行指充分利用多核处理器的优势,将大的任务分为一个个小的任务交给多个处理器执行并行处理;数据并行指现如今越来越丰富的SIMD指令,一次动作中处理多个数据,比如AVX-512可以一次处理16个32bit的整型数,这种也称为向量化执行。当然,随着其他新硬件的发展,并行也经常和GPU联系在一起。本文主要分析Spark读流程中的任务并行。
下面是Spark中一个读任务的过程,它主要分为三个步骤:
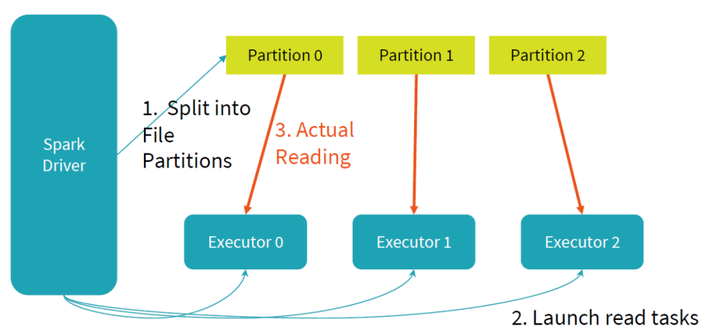
(1)将数据按照某个字段进行hash,将数据尽可能均匀地分为多个大小一致的Partition;
(2)发起多个任务,每个任务对应到图中的一个Executor;
(3)任务之间并行地进行各自负责的Partition数据读操作,提升读文件效率。
2、文件写
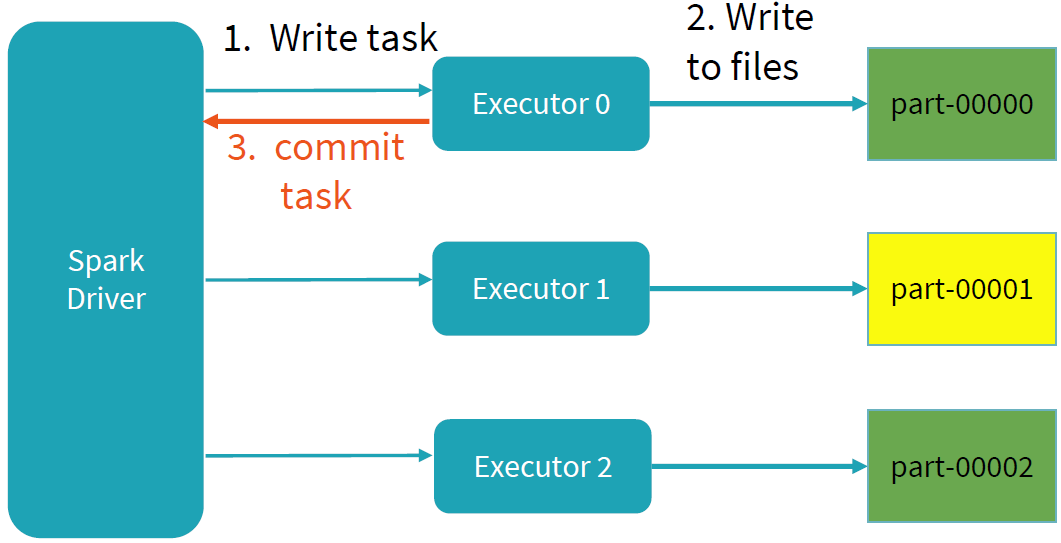
Spark写过程的目标主要是两个:并行和事务性。其中并行的思想和读流程一样,将任务分配给不同的Executor进行写操作,每个任务写各自负责的数据,互不干扰。
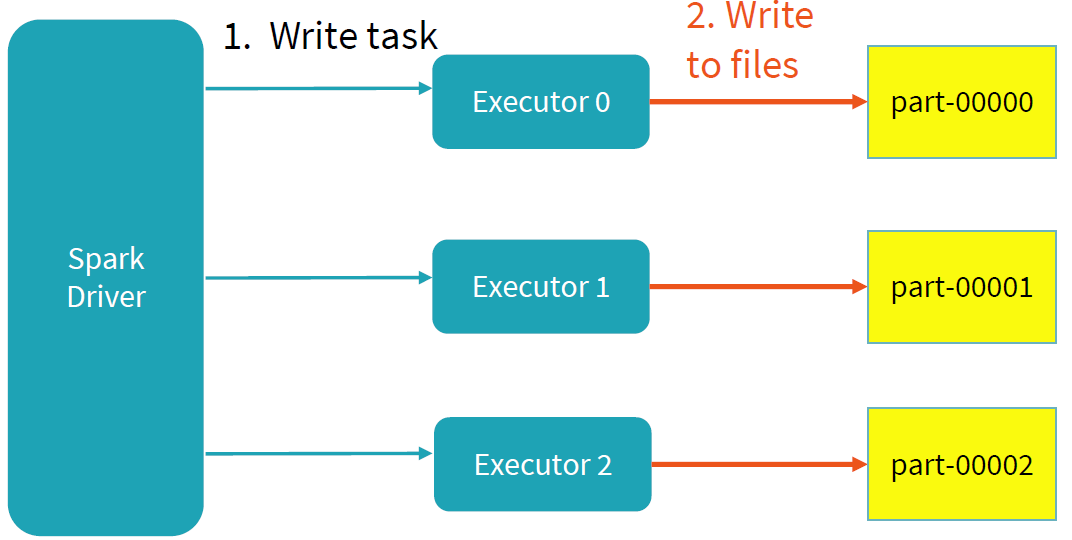
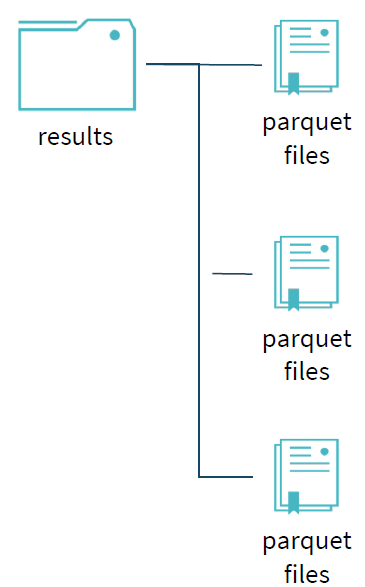
为了保证写过程的事务性,Spark在写过程中,任何未完成的写都是在临时文件夹中进行写文件操作。如下图所示:写过程中,results文件夹下只存在一个临时的文件夹_temporary;不同的job拥有各自job id的文件目录,相互隔离;同时在各目录未完成的写操作都是存在临时文件夹下,task的每次执行都视为一个taskAttempt,并会分配一个task attempt id,该目录下的文件是未commit之前的写文件。
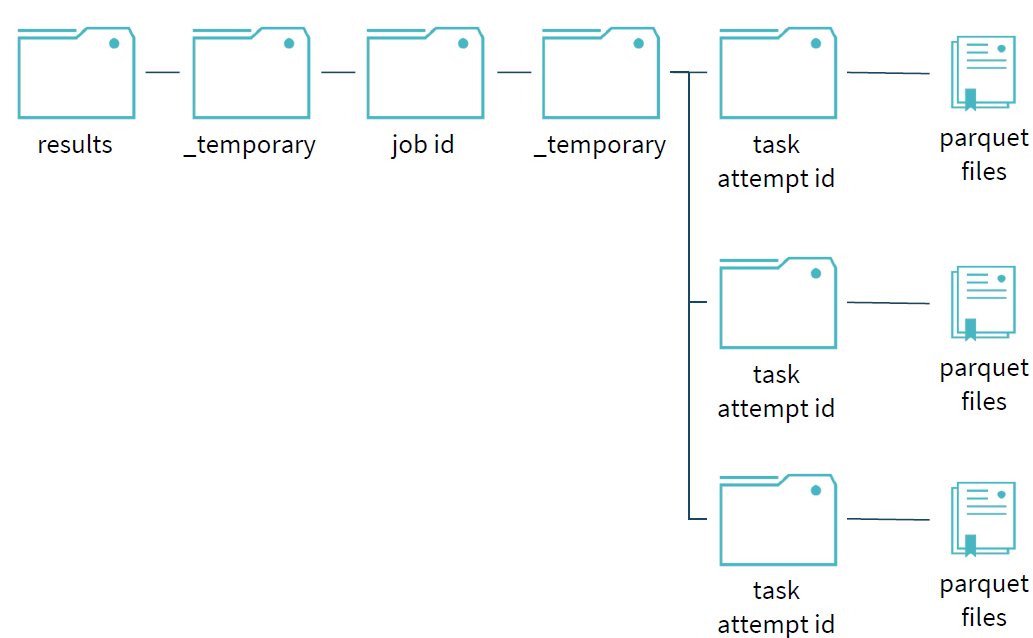
当task完成自己的写任务时,会进行commit操作,commit成功后,该任务目录下的临时文件夹会移动,写文件移到对应的位置,表示该任务已经写完成。
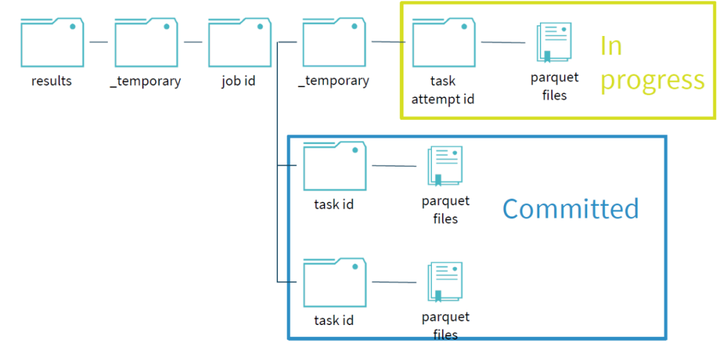
当写任务失败时,首先需要删除之前写任务的临时文件夹和未完成的文件,之后重新发起该写任务(relaunch),直到写任务commit提交完成。
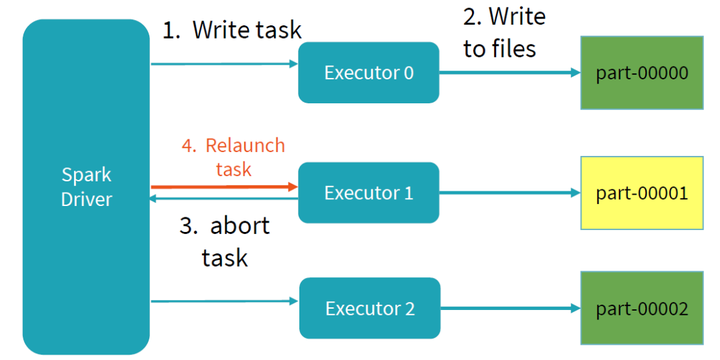
整个任务的描述可用下图表示,如果commit成功,将写完成文件移动到最终的文件夹;如果未commit成功,写失败,删除对应的文件,重新发起写任务。当写未完成时,所有写数据都存在对应的临时文件中,其他任务不可见,直到整个写commit成功,保证了写操作的事务性。
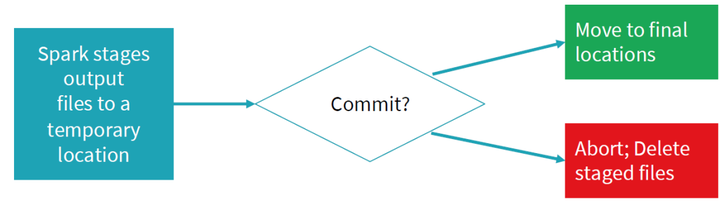
当所有任务完成时,所有的临时文件夹都移动,留下最终的数据文件,它是最终commitJob之后的结果。
本文介绍的算法是 FileOutputCommitter v1的实现,它的commitJob阶段由Driver负责依次移动数据到最终的目录。但是在当前广泛应用的云环境下,通常采取存算分离的架构,这时数据一般存放在对象存储中(如AWS S3,华为云OBS),Spark FileOutputCommitter中的数据移动并不像HDFS文件系统移动那么高效,v1的commitJob过程耗时可能会非常长。为了提升FileOutputCommitter 的性能,业界提出了FileOutputCommitter v2的实现,它们可以通过 spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version = 1或2 配置项来设置,它和v1的不同点在于,每个Task在commitTask时就将文件移动到最终的目录,而在commitJob时,Driver只需要负责将Task留下来的空目录删除,这样相比 v1 带来好处是性能提升, 但是由于commit task时直接写最终目录,在执行未完成时,部分数据就对外可见。同时,如果job失败了,成功的那部分task产生的数据也会残留下来。这些情况导致spark写作业的事务性和一致性无法得到保障。
其实v1也不完全一定能保证数据一致性,文件移动过程中完成的数据对外是可见的,这部分数据外部已经可以读取,但是正在移动和还未移动的数据对外是不可见的,而在云环境下,这个移动耗时会进一步加长,加重数据不一致的情况。
那么有没有能够使得Spark 分析在云环境下也可以保证数据的事务性和一致性的解决方案呢?华为云数据湖探索DLI(Data Lake Insight)改进了v1和v2这两种算法,使得Spark 分析在云环境下也可以保证数据的事务性和一致性,同时做到高性能,并且完全兼容Apache Spark和Apache Flink生态, 是实现批流一体的Serverless大数据计算分析服务,欢迎点击体验。
参考
【1】Databricks. 2020. Apache Spark's Built-In File Sources In Depth - Databricks. [online] Available at: <https://databricks.com/session_eu19/apache-sparks-built-in-file-sources-in-depth>.
大数据实践解析(下):Spark的读写流程分析的更多相关文章
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- spark block读写流程分析
之前分析了spark任务提交以及计算的流程,本文将分析在计算过程中数据的读写过程.我们知道:spark抽象出了RDD,在物理上RDD通常由多个Partition组成,一个partition对应一个bl ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据为什么要选择Spark
大数据为什么要选择Spark Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析. Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- Hadoop优势,组成的相关架构,大数据生态体系下的模式
Hadoop优势,组成的相关架构,大数据生态体系下的模式 一.Hadoop的优势 二.Hadoop的组成 2.1 HDFS架构 2.2 Yarn架构 2.3 MapReduce架构 三.大数据生态体系 ...
- 大数据实践:ODI 和 Twitter (二)
大数据实践:ODI和Twitter(二) 在前面的文章中,我们已经使用flume将数据从twitter抓取到Hive中,现在我们来看看ODI(Oracle Data Integrator)如何在HIV ...
- 大数据入门第二十二天——spark(一)入门与安装
一.概述 1.什么是spark 从官网http://spark.apache.org/可以得知: Apache Spark™ is a fast and general engine for larg ...
- 大众点评的大数据实践-CSDN.NET
大众点评的大数据实践-CSDN.NET 大众点评的大数据实践 爬虫工程师成大数据时代的"宠儿" - 杭州新闻中心 - 杭州网 爬虫工程师成大数据时代的"宠儿"
- S3C6410 SPI全双工读写流程分析(原创)【转】
转自:http://blog.csdn.net/hustyangju/article/details/21165721 原创博文,知识共享!转载请注明出处:http://blog.csdn.net/h ...
随机推荐
- 关于Android Stuido2.3和Eclipse4.4
近3年没有做Android开发了,当时用是ECLISPE电脑配置2g,用的还可以. 现在又重新开始做安卓程序,发现大家都用AS了,作为技术人员,也就开始用了. (几年前AS已经发布,不过是0.x版本, ...
- 关于 Python 字符串切片的小领悟
1. 什么是 Python 字符串切片? 例如存在字符串 str2 = "abcd1234" ,有以下简单的切片应用. str2[0] # a str2[0:3] # abc st ...
- 生成CSR和自签名证书
CSR,全称Certificate Signing Request(证书签发请求),是一种包含了公钥和与主题(通常是实体的信息,如个人或组织)相关的其他信息的数据结构.CSR通常用于向证书颁发机构(C ...
- Unity - UIWidgets 7. Redux接入(二) 把Redux划分为不同数据模块
参考QF.UIWidgets 参考Unity官方示例 - ConnectAppCN 前面说过,当时没想明白一个问题,在reducer中每次返回一个new State(), 会造成极大浪费,没想到用什么 ...
- Godot引擎的一些踩坑记录(不断更新中)
版本号 Godot 3.1.2 文件夹名称使用小写.编译\导出时有的tscn文件的引用路径, 有可能会变成小写路径(怀疑是bug),导致启动失败. ttc字体(文泉驿微米黑)导出时需要手动设置包含*. ...
- CF1610B [Kalindrome Array]
Problem 题目简述 给你一个数列 \(a\),有这两种情况,这个数列是「可爱的」. 它本身就是回文的. 定义变量 \(x\),满足:序列 \(a\) 中所有值等于 \(x\) 的元素删除之后,它 ...
- ensp小实验——浮动路由
依靠优先级来保证多路径的连通性. #AR1中<Huawei>u t m<Huawei>sys[Huawei]sys r1[r1]int g0/0/1 [r1-GigabitEt ...
- sed 原地替换文件时遇到的趣事
哈喽大家好,我是咸鱼 在文章<三剑客之 sed>中咸鱼向大家介绍了文本三剑客中的 sed sed 全名叫 stream editor,流编辑器,用程序的方式来编辑文本 那么今天咸鱼打算讲一 ...
- 1. 手动移植FreeRTOS V9.00到 Stm32F103C8T6
记录移植过程,以便以后查看: 附上FreeRTOS源码和 测试文件: 链接:https://pan.baidu.com/s/1v6nvDOk4-2NILYqN3njGjQ 提取码:1234 1.使用 ...
- 解密Prompt系列19. LLM Agent之数据分析领域的应用:Data-Copilot & InsightPilot
在之前的 LLM Agent+DB 的章节我们已经谈论过如何使用大模型接入数据库并获取数据,这一章我们聊聊大模型代理在数据分析领域的应用.数据分析主要是指在获取数据之后的数据清洗,数据处理,数据建模, ...