聊聊GLM基座模型的理论知识
概述
大模型有两个流程:预训练和推理。
- 预训练是在某种神经网络模型架构上,导入大规模语料数据,通过一系列的神经网络隐藏层的矩阵计算、微分计算等,输出权重,学习率,模型参数等超参数信息。
- 推理是在预训练的成果上,应用超参数文件,基于预训练结果,根据用户的输入信息,推理预测其行为。
GLM模型原理的理解,就是预训练流程的梳理,如下流程所示:
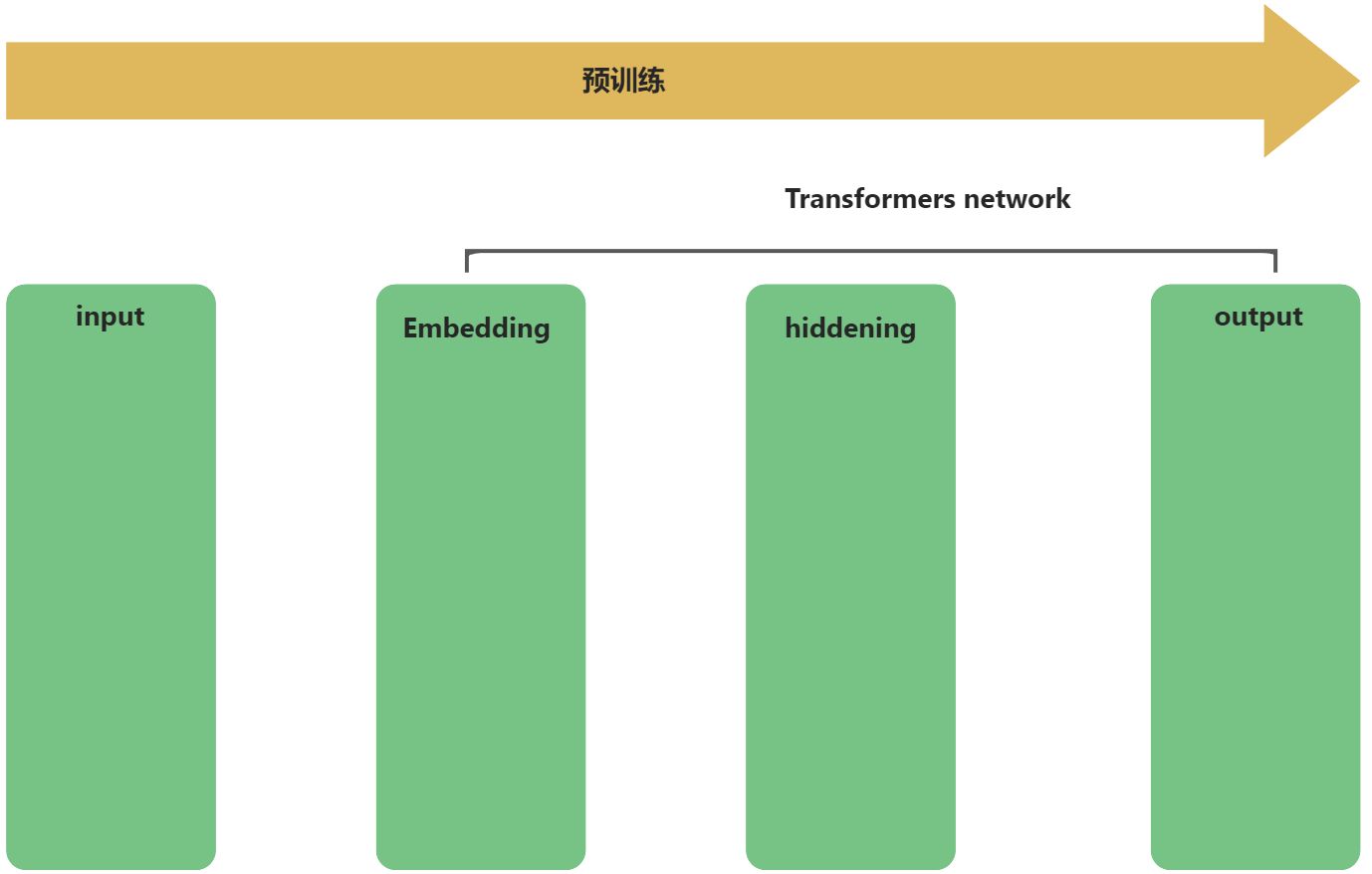
input输入层会预处理输入数据,在预训练过程中,该输入数据,其实就是预先准备好的预料数据集,也就是常说的6B,130B大小的数据集。
掩码处理
GLM统一了自编码模型与自回归模型,主要是在该处理过程实现的。该过程也被成为自回归空格填充。该过程体现了自编码与自回归思想:
1、自编码思想:在输入文本中,随机删除连续的tokens,做成掩码[MASK]。
2、自回归思想:顺序重建连续tokens。在使用自回归方式预测缺失tokens时,模型既可以访问带掩码的文本,又可以访问之前已经被采样的spans。
输入 可以被分成两部分:Part A是被损坏的文本
可以被分成两部分:Part A是被损坏的文本 ,Part B由masked spans组成。
,Part B由masked spans组成。
假设原始输入文本是 ,采样的两个文本片段是
,采样的两个文本片段是 以及
以及 。那么mask后的文本序列是:
。那么mask后的文本序列是: ,即Part A;
,即Part A; 、
、 即PartB。
即PartB。
再对Part B的片段进行shuffle。每个片段使用 填充在开头作为输入,使用
填充在开头作为输入,使用 填充在末尾作为输出。如论文中的图所示:
填充在末尾作为输出。如论文中的图所示:

掩码处理时,会随机选择输入序列中的某些词语进行掩码(mask)处理。掩码的目的是让模型学习预测那些被掩码的词语。让模型能够在预训练过程中更好地学习语言规律和上下文信息。
掩码处理的流程如下:
- 输入数据采样:首先,从输入文本中随机采样多个片段,这些片段包含了多个需要被预测的词(即[mask]标记)。
- 掩码替换:在这些采样片段中,用[mask]标记替换掉部分词语,形成一个被掩码的文本。这样,模型需要根据已给出的上下文信息来预测被掩码的词语。
- 自回归预测:GLM模型采用自回归的方式,从已给出的片段中预测被掩码的词语。这意味着在预测[mask]中原来的词的同时,模型可以参考之前片段的信息。
- 上下文信息利用:为了让模型能够更好地理解上下文信息,GLM模型将被掩码的片段的顺序打乱。这样,模型在预测时需要参考更广泛的上下文信息,从而提高其语言理解能力。
- 预训练任务:通过这种方式,GLM模型实现了自监督训练,让模型能够在不同的任务(如NLU、NLG和条件NLG)中表现更好。
从结构化来思考,剖析下这个过程所涉及到的一些开发知识点。
- 随机抽样:在掩码处理中,需要从输入数据中随机选择一部分数据进行掩码。遵循泊松分布,重复采样,直到原始tokens中有15%被mask。
- 掩码策略:在GLM模型中,采用了自回归空白填充(Autoregressive Blank Infilling)的自监督训练方式。这需要根据掩码策略来生成掩码,如根据预先设定的规则来选择掩码的长度和位置。这个过程涉及到组合数学和离散数学的知识。
- 掩码填充:在生成掩码后,需要对掩码进行填充。在GLM模型中,采用了特殊的填充方式,如span shuffling和2D positional encoding。这个过程涉及到线性代数和矩阵运算的知识。
- 损失函数:在掩码处理过程中,需要根据损失函数来计算掩码处理的效果。在GLM模型中,采用了交叉熵损失函数来衡量模型在掩码处理任务上的表现。这个过程涉及到优化理论和数值分析的知识。
位置编码
在基于Transformer网络架构的模型中,位置编码是必不可少的一个处理,其作用简单来说就是在没有显式顺序信息的情况下,为模型提供关于词的相对位置的信息,以便让模型理解输入序列中的序列信息以及上下文信息。
位置编码在GLM中,通过采用一种称为"旋转位置编码"(RoPE)的方法来处理的。RoPE是一种相对位置编码技术,它能够有效地捕捉输入序列中不同token之间的相对位置信息。相较于传统的绝对位置编码,RoPE具有更好的外推性和远程衰减特性,能够更好地处理长文本。
在GLM中,使用二维位置编码,第一个位置id用来标记Part A中的位置,第二个位置id用来表示跨度内部的相对位置。这两个位置id会通过embedding表被投影为两个向量,最终都会被加入到输入token的embedding表达中。如论文中的图所示:

自注意力计算
自注意力机制中的 矩阵计算如图所示:
矩阵计算如图所示:

这里面的道道暂时还没有摸清,不过计算的逻辑还是基于Tranformer网络中的自注意力计算,只是这框出来的蓝黄绿,其表征有点道道。
其它
GLM在原始single Transformer的基础上进行了一些修改:
1)重组了LN和残差连接的顺序;
2)使用单个线性层对输出token进行预测;
3)激活函数从ReLU换成了GeLUS。
这些修改是比较常见的,简单了解下即可。
参考
清华ChatGLM底层原理详解
GLM(General Language Model)论文阅读笔记
聊聊GLM基座模型的理论知识的更多相关文章
- 图形学理论知识 BRDF 双向反射分布函数(Bidirectional Reflectance Distribution Function)
图形学理论知识 BRDF 双向反射分布函数 Bidirectional Reflectance Distribution Function BRDF理论 BRDF表示的是双向反射分布函数(Bidire ...
- [转] DDD领域驱动设计(三) 之 理论知识收集汇总
最近一直在学习领域驱动设计(DDD)的理论知识,从网上搜集了一些个人认为比较有价值的东西,贴出来和大家分享一下: 我一直觉得不要盲目相信权威,比如不能一谈起领域驱动设计,就一定认为国外的那个Eric ...
- 线程概念( 线程的特点,进程与线程的关系, 线程和python理论知识,线程的创建)
参考博客: https://www.cnblogs.com/xiao987334176/p/9041318.html 线程概念的引入背景 进程 之前我们已经了解了操作系统中进程的概念,程序并不能单独运 ...
- 分析技术和方法论营销理论知识框架,营销方面4P、用户使用行为、STP,管理方面5W2H、逻辑树、金字塔、生命周期
原文:五种分析框架:PEST.5W2H.逻辑树.4P.用户使用行为 最近在一点点的啃<谁说菜鸟不懂得数据分析>,相当慢,相当的费脑力,总之,真正的学习伴随着痛苦:) 最初拿到这本书的时候, ...
- 商业智能BI-基础理论知识总结 ZT
因为要加入一个BI项目,所以最近在研究BI相关的知识体系,由于这个方面的知识都是比较零散,开始都很多概念,不知道从何入手,网上找的资料也不多,特别是实战案例方面更少,这里还是先把理论知识理解下吧,分享 ...
- python 全栈开发,Day41(线程概念,线程的特点,进程和线程的关系,线程和python 理论知识,线程的创建)
昨日内容回顾 队列 队列 : 先进先出.数据进程安全 队列实现方式: 管道 + 锁 生产者消费者模型 : 解决数据供需不平衡 管道 双向通信 数据进程不安全 EOFError: 管道是由操作系统进行引 ...
- Web前端理论知识记录
Web前端理论知识记录 Elena· 5 个月前 cookies,sessionStorage和localStorage的区别? sessionStorage用于本地存储一个会话(session) ...
- 关于DDD领域驱动设计的理论知识收集汇总
原文:关于DDD领域驱动设计的理论知识收集汇总 最近一直在学习领域驱动设计(DDD)的理论知识,从网上搜集了一些个人认为比较有价值的东西,贴出来和大家分享一下: 我一直觉得不要盲目相信权威,比如不能一 ...
- python全栈开发,Day41(线程概念,线程的特点,进程和线程的关系,线程和python理论知识,线程的创建)
昨日内容回顾 队列 队列:先进先出.数据进程安全 队列实现方式:管道+锁 生产者消费者模型:解决数据供需不平衡 管道 双向通信,数据进程不安全 EOFError: 管道是由操作系统进行引用计数的 必须 ...
- js中函数的一些理论知识
函数的一些理论知识 1. 函数: 执行一个明确的动作并提供一个返回值的独立代码块.同时函数也是javascript中的一级公民(就是函数和其它变量一样). 2.函数的 ...
随机推荐
- (2023.8.28)Hi铁布衫-CM Ver 0.001 - Cracked-writeup
Hi铁布衫-CM Ver 0.001 WriteUp 本文作者:XDbgPYG(小吧唧) 发布时间:2023年8月28日 内容概要:Hi铁布衫-CM Ver 0.001 WriteUp 收集信息 有一 ...
- 基于velero及minio实现etcd数据备份与恢复
1.Velero简介 Velero 是vmware开源的一个云原生的灾难恢复和迁移工具,它本身也是开源的,采用Go语言编写,可以安全的备份.恢复和迁移Kubernetes集群资源数据:官网https: ...
- 对比 MyBatis 和 MyBatis-Plus 批量插入、批量更新的性能和区别
1 环境准备 demo 地址:learn-mybatis · Sean/spring-cloud-alibaba - 码云(gitee.com) 1.1 搭建 MyBatis-Plus 环境 创建 m ...
- Linux下Python环境安装
Linux通常都附带Python环境,但是Linux附带的大多数Python都是2.7.5版本.如果我们想使用Python3或者Anaconda3,最好安装一个新的Python3环境,但不要尝试删除P ...
- 搭建eureka服务注册中心,单机版
单独搭建的 搭建springboot项目 (1)pom文件 <?xml version="1.0" encoding="UTF-8"?> <p ...
- angular + express 实现websocket通信
最近需要实现一个功能,后端通过TCP协议连接雷达硬件的控制器,前端通过websocket连接后端,当控制器触发消息的时候,把信息通知给所以前端: 第一个思路是单独写一个后端服务用来实现websocke ...
- 将Python程序打包成Linux可执行文件
将Python程序打包成Linux可执行文件 安装环境 首先我们要安装pip,命令如下: sudo apt install python3-pip 使用的工具是pyinstaller,打开终端输入su ...
- Springboot简单功能示例-3 实现基本登录验证
springboot-sample 介绍 springboot简单示例 跳转到发行版 查看发行版说明 软件架构(当前发行版使用) springboot hutool-all 非常好的常用java工具库 ...
- ElasticSearch系列——文档操作
文章目录 Elasticsearch的增删查改(CURD) 一 CURD之Create 二 CURD之Update 三 CURD之Delete 四 CURD之Retrieve Elasticsearc ...
- linux常用命令(六)
用于查找系统文件的相关命令 grep find locate grep:查找文件中符号条件的字符串(关键词) 命令语法:grep [选项] 查找模式 [文件名] 选项 选项含义 -E 模式是一个可扩展 ...