PyTorch 实战(模型训练、模型加载、模型测试)
本次将一个使用Pytorch的一个实战项目,记录流程:自定义数据集->数据加载->搭建神经网络->迁移学习->保存模型->加载模型->测试模型
自定义数据集
参考我的上一篇博客:自定义数据集处理数据加载
默认小伙伴有对深度学习框架有一定的了解,这里就不做过多的说明了。
好吧,还是简单的说一下吧:
我们在做好了自定义数据集之后,其实数据的加载和MNSIT 、CIFAR-10 、CIFAR-100等数据集的都是相似的,过程如下所示:- 导入必要的包
import torch
from torch import optim, nn
import visdom
from torch.utils.data import DataLoader
- 加载数据
可以发现和MNIST 、CIFAR的加载基本上是一样的
train_db = Pokemon('pokeman', 224, mode='train')
val_db = Pokemon('pokeman', 224, mode='val')
test_db = Pokemon('pokeman', 224, mode='test')
train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True,
num_workers=4)
val_loader = DataLoader(val_db, batch_size=batchsz, num_workers=2)
test_loader = DataLoader(test_db, batch_size=batchsz, num_workers=2)
- 搭建神经网络
ResNet-18网络结构:

ResNet全名Residual Network残差网络。Kaiming He 的《Deep Residual Learning for Image Recognition》获得了CVPR最佳论文。他提出的深度残差网络在2015年可以说是洗刷了图像方面的各大比赛,以绝对优势取得了多个比赛的冠军。而且它在保证网络精度的前提下,将网络的深度达到了152层,后来又进一步加到1000的深度。论文的开篇先是说明了深度网络的好处:特征等级随着网络的加深而变高,网络的表达能力也会大大提高。因此论文中提出了一个问题:是否可以通过叠加网络层数来获得一个更好的网络呢?作者经过实验发现,单纯的把网络叠起来的深层网络的效果反而不如合适层数的较浅的网络效果。因此何恺明等人在普通平原网络的基础上增加了一个shortcut, 构成一个residual block。此时拟合目标就变为F(x),F(x)就是残差:
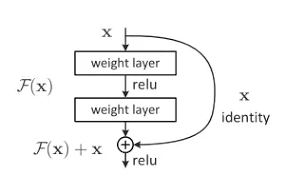
- 训练模型
def evalute(model, loader):
model.eval()
correct = 0
total = len(loader.dataset)
for x, y in loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
logits = model(x)
pred = logits.argmax(dim=1)
correct += torch.eq(pred, y).sum().float().item()
return correct / total
def main():
model = ResNet18(5).to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
criteon = nn.CrossEntropyLoss()
best_acc, best_epoch = 0, 0
global_step = 0
viz.line([0], [-1], win='loss', opts=dict(title='loss'))
viz.line([0], [-1], win='val_acc', opts=dict(title='val_acc'))
for epoch in range(epochs):
for step, (x, y) in enumerate(train_loader):
x, y = x.to(device), y.to(device)
model.train()
logits = model(x)
loss = criteon(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
if epoch % 1 == 0:
val_acc = evalute(model, val_loader)
if val_acc > best_acc:
best_epoch = epoch
best_acc = val_acc
viz.line([val_acc], [global_step], win='val_acc', update='append')
print('best acc:', best_acc, 'best epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evalute(model, test_loader)
- 迁移学习
提升模型的准确率:
# model = ResNet18(5).to(device)
trained_model=resnet18(pretrained=True) # 此时是一个非常好的model
model = nn.Sequential(*list(trained_model.children())[:-1], # 此时使用的是前17层的网络 0-17 *:随机打散
Flatten(),
nn.Linear(512,5)
).to(device)
# x=torch.randn(2,3,224,224)
# print(model(x).shape)
optimizer = optim.Adam(model.parameters(), lr=lr)
criteon = nn.CrossEntropyLoss()
- 保存、加载模型
pytorch保存模型的方式有两种:
第一种:将整个网络都都保存下来
第二种:仅保存和加载模型参数(推荐使用这样的方法)
# 保存和加载整个模型
torch.save(model_object, 'model.pkl')
model = torch.load('model.pkl')
# 仅保存和加载模型参数(推荐使用)
torch.save(model_object.state_dict(), 'params.pkl')
model_object.load_state_dict(torch.load('params.pkl'))
可以看到这是我保存的模型:
其中best.mdl是第二中方法保存的
model.pkl则是第一种方法保存的

- 测试模型
这里是训练时的情况

看这个数据准确率还是不错的,但是还是需要实际的测试这个模型,看它到底学到东西了没有,接下来简单的测试一下:
import torch
from PIL import Image
from torchvision import transforms
device = torch.device('cuda')
transform=transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],
std=[0.229,0.224,0.225])
])
def prediect(img_path):
net=torch.load('model.pkl')
net=net.to(device)
torch.no_grad()
img=Image.open(img_path)
img=transform(img).unsqueeze(0)
img_ = img.to(device)
outputs = net(img_)
_, predicted = torch.max(outputs, 1)
# print(predicted)
print('this picture maybe :',classes[predicted[0]])
if __name__ == '__main__':
prediect('./test/name.jpg')
实际的测试结果:


效果还是可以的,完整的代码:
https://github.com/huzixuan1/Loader_DateSet
数据集下载链接:
https://pan.baidu.com/s/12-NQiF4fXEOKrXXdbdDPCg
由于笔者能力水平有限,在表述上可能有些不准确;有问题可以联系QQ:1017190168
PyTorch 实战(模型训练、模型加载、模型测试)的更多相关文章
- Pytorch实战学习(四):加载数据集
<PyTorch深度学习实践>完结合集_哔哩哔哩_bilibili Dataset & Dataloader 1.Dataset & Dataloader作用 ※Datas ...
- 深度学习-05(tensorflow模型保存与加载、文件读取、图像分类:手写体识别、服饰识别)
文章目录 深度学习-05 模型保存于加载 什么是模型保存与加载 模型保存于加载API 案例1:模型保存/加载 读取数据 文件读取机制 文件读取API 案例2:CSV文件读取 图片文件读取API 案例3 ...
- [译]Vulkan教程(31)加载模型
[译]Vulkan教程(31)加载模型 Loading models 加载模型 Introduction 入门 Your program is now ready to render textured ...
- PyTorch保存模型与加载模型+Finetune预训练模型使用
Pytorch 保存模型与加载模型 PyTorch之保存加载模型 参数初始化参 数的初始化其实就是对参数赋值.而我们需要学习的参数其实都是Variable,它其实是对Tensor的封装,同时提供了da ...
- [PyTorch 学习笔记] 7.1 模型保存与加载
本章代码: https://github.com/zhangxiann/PyTorch_Practice/blob/master/lesson7/model_save.py https://githu ...
- 全面解析Pytorch框架下模型存储,加载以及冻结
最近在做试验中遇到了一些深度网络模型加载以及存储的问题,因此整理了一份比较全面的在 PyTorch 框架下有关模型的问题.首先咱们先定义一个网络来进行后续的分析: 1.本文通用的网络模型 import ...
- 深度学习原理与框架-猫狗图像识别-卷积神经网络(代码) 1.cv2.resize(图片压缩) 2..get_shape()[1:4].num_elements(获得最后三维度之和) 3.saver.save(训练参数的保存) 4.tf.train.import_meta_graph(加载模型结构) 5.saver.restore(训练参数载入)
1.cv2.resize(image, (image_size, image_size), 0, 0, cv2.INTER_LINEAR) 参数说明:image表示输入图片,image_size表示变 ...
- [Pytorch]Pytorch 保存模型与加载模型(转)
转自:知乎 目录: 保存模型与加载模型 冻结一部分参数,训练另一部分参数 采用不同的学习率进行训练 1.保存模型与加载 简单的保存与加载方法: # 保存整个网络 torch.save(net, PAT ...
- tensorflow 模型保存与加载 和TensorFlow serving + grpc + docker项目部署
TensorFlow 模型保存与加载 TensorFlow中总共有两种保存和加载模型的方法.第一种是利用 tf.train.Saver() 来保存,第二种就是利用 SavedModel 来保存模型,接 ...
- tensorflow实现线性回归、以及模型保存与加载
内容:包含tensorflow变量作用域.tensorboard收集.模型保存与加载.自定义命令行参数 1.知识点 """ 1.训练过程: 1.准备好特征和目标值 2.建 ...
随机推荐
- 《CTFshow-Web入门》05. Web 41~50
@ 目录 web41 题解 原理 web42 题解 原理 web43 题解 原理 web44 题解 原理 web45 题解 原理 web46 题解 原理 web47 题解 web48 题解 web49 ...
- [译]2023年 Web Coponent 现状
本文为翻译 原文地址:2023 State of Web Components: Today's standards and a glimpse into the future. 最近,我写了关于如何 ...
- MindSponge分子动力学模拟——计算单点能(2023.08)
技术背景 在前面的几篇文章中,我们分别介绍了MindSponge的软件架构.MindSponge的安装与使用和如何在MindSponge中定义一个分子系统.那么就像深度学习中的损失函数,或者目标函数, ...
- 遗传算法解决航路规划问题(MATLAB)
遗传算法 文章部分图片和思路来自司守奎,孙兆亮<数学建模算法与应用>第二版 定义:遗传算法是一种基于自然选择原理和自然遗传机制的搜索(寻优)算法,模拟自然界中的声明进化机制,在人工系统中实 ...
- 从零开始:Spring Security Oauth2 讲解及实战
OAuth2.0的四种授权模式: https://blog.csdn.net/weixin_30849403/article/details/101958273 1.授权服务配置: 配置一个授权服务, ...
- C++ 重载运算符在HotSpot VM中的应用
C++支持运算符重载,对于Java开发者来说,这个可能比较陌生一些,因为Java不支持运算符重载.运算符重载本质上来说就是函数重载.下面介绍一下HotSpot VM中的运算符重载. 1.内存分配与释放 ...
- 2023-10-07:用go语言,给定n个二维坐标,表示在二维平面的n个点, 坐标为double类型,精度最多小数点后两位, 希望在二维平面上画一个圆,圈住其中的k个点,其他的n-k个点都要在圆外。
2023-10-07:用go语言,给定n个二维坐标,表示在二维平面的n个点, 坐标为double类型,精度最多小数点后两位, 希望在二维平面上画一个圆,圈住其中的k个点,其他的n-k个点都要在圆外. ...
- MySQL5.7版本单节点大数据量迁移到PXC8.0版本集群全记录-1
一个5.7版本的MySQL单点数据库,版本信息是: Server version: 5.7.31-log MySQL Community Server (GPL) 数据量已达到760G,日常存在性能问 ...
- SOA认知和方法论
1 前言 1.1 架构分类 在软件设计领域,企业架构通常被划分为如下五种分类: 如何理解架构分类依据及其彼此之间的关系?业务是企业赖以生存之本,因此业务架构是基础.是灵魂,其他一切均是对业务架构的支撑 ...
- LGPL协议原文及中文翻译
LGPL协议原文及中文翻译 参考链接 原文: GNU LESSER GENERAL PUBLIC LICENSE Version 3, 29 June 2007 Copyright (C) 2007 ...