[转帖]备份与恢复工具 BR 简介
https://docs.pingcap.com/zh/tidb/v4.0/backup-and-restore-tool
BR 全称为 Backup & Restore,是 TiDB 分布式备份恢复的命令行工具,用于对 TiDB 集群进行数据备份和恢复。BR 只支持在 TiDB v3.1 及以上版本使用。
相比 Dumpling,BR 更适合大数据量的场景。
本文介绍了 BR 的工作原理、推荐部署配置、使用限制以及几种使用方式。
工作原理
BR 将备份或恢复操作命令下发到各个 TiKV 节点。TiKV 收到命令后执行相应的备份或恢复操作。
在一次备份或恢复中,各个 TiKV 节点都会有一个对应的备份路径,TiKV 备份时产生的备份文件将会保存在该路径下,恢复时也会从该路径读取相应的备份文件。
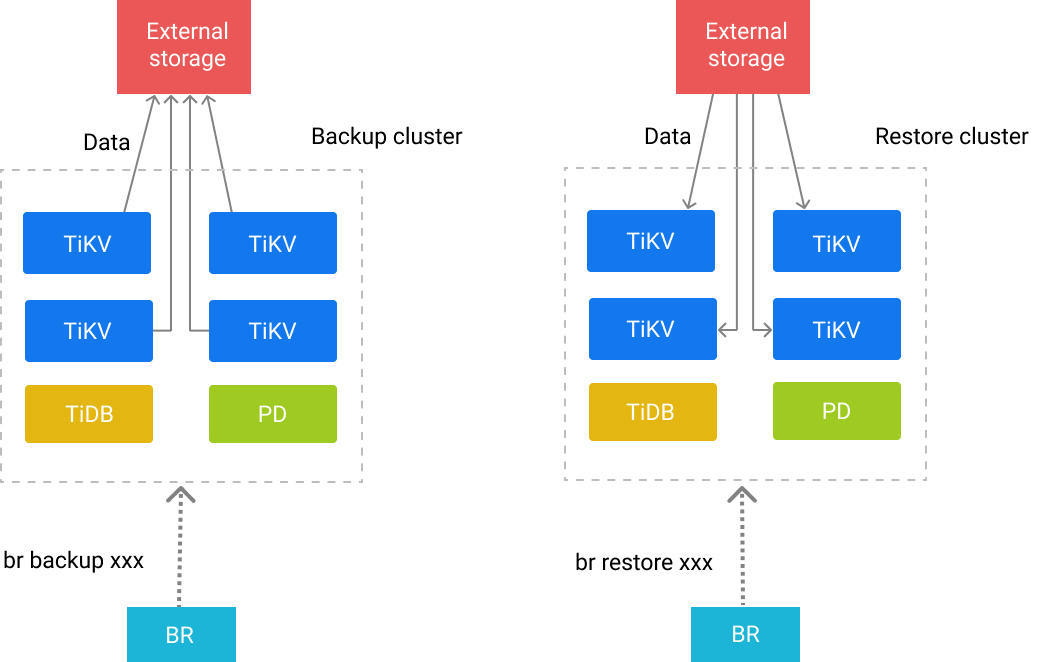
更多信息请参阅备份恢复设计方案。
备份文件类型
备份路径下会生成以下两种类型文件:
- SST 文件:存储 TiKV 备份下来的数据信息
backupmeta文件:存储本次备份的元信息,包括备份文件数、备份文件的 Key 区间、备份文件大小和备份文件 Hash (sha256) 值backup.lock文件:用于防止多次备份到同一目录
SST 文件命名格式
SST 文件以 storeID_regionID_regionEpoch_keyHash_cf 的格式命名。格式名的解释如下:
- storeID:TiKV 节点编号
- regionID:Region 编号
- regionEpoch:Region 版本号
- keyHash:Range startKey 的 Hash (sha256) 值,确保唯一性
- cf:RocksDB 的 ColumnFamily(默认为
default或write)
部署使用 BR 工具
推荐部署配置
- 推荐 BR 部署在 PD 节点上。
- 推荐使用一块高性能 SSD 网盘,挂载到 BR 节点和所有 TiKV 节点上,网盘推荐万兆网卡,否则带宽有可能成为备份恢复时的性能瓶颈。
- 如果没有挂载网盘或者使用其他共享存储,那么 BR 备份的数据会生成在各个 TiKV 节点上。由于 BR 只备份 leader 副本,所以各个节点预留的空间需要根据 leader size 来预估。
- 同时由于 v4.0 默认使用 leader count 进行平衡,所以会出现 leader size 差别大的问题,导致各个节点备份数据不均衡。
使用限制
下面是使用 BR 进行备份恢复的几条限制:
- BR 恢复到 TiCDC / Drainer 的上游集群时,恢复数据无法由 TiCDC / Drainer 同步到下游。
- BR 只支持在
new_collations_enabled_on_first_bootstrap开关值相同的集群之间进行操作。这是因为 BR 仅备份 KV 数据。如果备份集群和恢复集群采用不同的排序规则,数据校验会不通过。所以恢复集群时,你需要确保select VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME='new_collation_enabled';语句的开关值查询结果与备份时的查询结果相一致,才可以进行恢复。
兼容性
BR 和 TiDB 集群的兼容性问题分为以下两方面:
- BR 部分版本和 TiDB 集群的接口不兼容
- 某些功能在开启或关闭状态下,会导致 KV 格式发生变化,因此备份和恢复期间如果没有统一开启或关闭,就会带来不兼容的问题
下表整理了会导致 KV 格式发生变化的功能。
| 功能 | 相关 issue | 解决方式 |
|---|---|---|
| New collation | #352 | 确保恢复时集群的 new_collations_enabled_on_first_bootstrap 变量值和备份时的一致,否则会导致数据索引不一致和 checksum 通不过。 |
| 恢复集群开启 TiCDC 同步 | #364 | TiKV 暂不能将 BR ingest 的 SST 文件下推到 TiCDC,因此使用 BR 恢复时候需要关闭 TiCDC。 |
在上述功能确保备份恢复一致的前提下,BR 和 TiKV/TiDB/PD 还可能因为版本内部协议不一致/接口不一致出现不兼容的问题,因此 BR 内置了版本检查。
版本检查
BR 内置版本会在执行备份和恢复操作前,对 TiDB 集群版本和自身版本进行对比检查。如果大版本不匹配(比如 BR v4.x 和 TiDB v5.x 上),BR 会提示退出。如要跳过版本检查,可以通过设置 --check-requirements=false 强行跳过版本检查,但是这样可能会引入版本不兼容的问题。TiDB v4.0 用 BR 备份后,不完全支持恢复到 v5.0 以及之后版本,详细信息见 BR 版本检查(stable 版文档)。
运行 BR 的最低机型配置要求
运行 BR 的最低机型配置要求如下:
| CPU | 内存 | 硬盘类型 | 网络 |
|---|---|---|---|
| 1 核 | 4 GB | HDD | 千兆网卡 |
一般场景下(备份恢复的表少于 1000 张),BR 在运行期间的 CPU 消耗不会超过 200%,内存消耗不会超过 1 GB。但在备份和恢复大量数据表时,BR 的内存消耗可能会上升到 3 GB 以上。在实际测试中,备份 24000 张表大概需要消耗 2.7 GB 内存,CPU 消耗维持在 100% 以下。
最佳实践
下面是使用 BR 进行备份恢复的几种推荐操作:
- 推荐在业务低峰时执行备份操作,这样能最大程度地减少对业务的影响。
- BR 支持在不同拓扑的集群上执行恢复,但恢复期间对在线业务影响很大,建议低峰期或者限速 (
rate-limit) 执行恢复。 - BR 备份最好串行执行。不同备份任务并行会导致备份性能降低,同时也会影响在线业务。
- BR 恢复最好串行执行。不同恢复任务并行会导致 Region 冲突增多,恢复的性能降低。
- 推荐在
-s指定的备份路径上挂载一个共享存储,例如 NFS。这样能方便收集和管理备份文件。 - 在使用共享存储时,推荐使用高吞吐的存储硬件,因为存储的吞吐会限制备份或恢复的速度。
使用方式
目前支持以下几种方式来运行 BR 工具,分别是通过 SQL 语句、命令行工具或在 Kubernetes 环境下进行备份恢复。
通过 SQL 语句
在 v4.0.2 及以上版本的 TiDB 中,支持直接通过 SQL 语句进行备份恢复,具体使用示例见:
通过命令行工具
在 v3.1 以上的 TiDB 版本中,支持通过命令行工具进行备份恢复。
首先需要下载一个 BR 工具的二进制包,详见下载链接。
通过命令行工具进行备份恢复的具体操作见使用备份与恢复工具 BR。
在 Kubernetes 环境下
目前支持使用 BR 工具备份 TiDB 集群数据到兼容 S3 的存储、Google Cloud Storage 以及持久卷,并作恢复:
Amazon S3 和 Google Cloud Storage (GCS) 参数描述见外部存储文档。
- 备份 TiDB 集群数据到兼容 S3 的存储
- 恢复 S3 兼容存储上的备份数据
- 备份 TiDB 集群到 Google Cloud Storage
- 恢复 Google Cloud Storage 上的备份数据
- 备份 TiDB 集群到持久卷
- 恢复持久卷上的备份数据
BR 相关文档
[转帖]备份与恢复工具 BR 简介的更多相关文章
- 部分GDAL工具功能简介
主要转自http://blog.csdn.net/liminlu0314?viewmode=contents 部分GDAL工具功能简介 gdalinfo.exe 显示GDAL支持的各种栅格文件的信息. ...
- Apache Jakarta Commons 工具集简介
Apache Jakarta Commons 工具集简介[转] Apache Commons包含了很多开源的工具,用于解决平时编程经常会遇到的问题,减少重复劳动.我选了一些比较常用的项目做简单介绍.文 ...
- nmon 及nmon analyser工具使用简介
nmon及nmon analyser工具使用简介 by:授客 QQ:1033553122 下载地址 http://nmon.sourceforge.net/pmwiki.php?n=Site.Down ...
- Postman Postman接口测试工具使用简介
Postman接口测试工具使用简介 by:授客 QQ:1033553122 本文主要是对Postman这个接口测试工具的使用做个简单的介绍,仅供参考. 插件安装 1)下载并安装chrome浏览器 2) ...
- Golang包管理工具glide简介
Golang包管理工具glide简介 前言 Golang是一个十分有趣,简洁而有力的开发语言,用来开发并发/并行程序是一件很愉快的事情.在这里我感受到了其中一些好处: 没有少了许多代码格式风格的争论, ...
- 34、Collections工具类简介
Collections工具类简介 就像数组中的Arrays工具类一样,在集合里面也有跟Arrays类似的工具类Collections package com.sutaoyu.Collections; ...
- Apache—dbutils开源JDBC工具类库简介
Apache—dbutils开源JDBC工具类库简介 一.前言 commons-dbutils 是 Apache 组织提供的一个开源 JDBC工具类库,它是对JDBC的简单封装,学习成本极低,并且使用 ...
- 【linux】串口通讯工具-minicom简介+简单操作
目录 前言 简介 尝试运行 配置 minicom 运行 minicom minicom 其它操作 前言 windows 上有不少的串口通信工具了,今天介绍一个linux下的一个串口通信工具-minic ...
- [转帖]linux lsof 用法简介
linux lsof 用法简介 https://www.cnblogs.com/saneri/p/5333333.html 1.简介: lsof(list open files)是一个列出当前系统打开 ...
- zookeeper工作原理、安装配置、工具命令简介
1.Zookeeper简介 Zookeeper 是分布式服务框架,主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置项的管理等等. 2.zo ...
随机推荐
- 案例分享-Exception.getMessage突然为null
背景 之前做的小工具一个jsqlparse+git做的小工具帮我节省时间摸鱼昨天突然停止工作,看了下jvm并没有退出,但是看日志确实有不少Error输出,虽说是一个普通的NPE,但是分析了一下却疑点重 ...
- JavaFx Maven配置推荐(七)
JavaFx Maven配置推荐(七) JavaFX 从入门到入土系列 开发Java Fx,推荐使用Maven管理项目,下面是常用到的配置基于jdk11+ <!-- 打成 jar 包 --> ...
- 面试官:禁用Cookie后Session还能用吗?
Cookie 和 Session 是 Web 应用程序中用于保持用户状态的两种常见机制,它们之间既有联系也有区别. Cookie 是由服务器在 HTTP 响应中发送给客户端(通常是浏览器)的一小段数据 ...
- MongoDB系列:C#、Java驱动连接MongoDB以及封装(C#的MongoDBHelper,Java的MongoDBUtil)
一.C#驱动连接MongoDB 1.创建项目 执行命令:dotnet new console -n MongoDbDriverDemo 2.添加依赖包 执行命令:dotnet add package ...
- Linux系统快速入门
LINUX基础知识 I.Linux概述 linux是啥? 一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和Unix的多用户.多任务.支持多线程和多CPU的操作系统.它能运行主要的Un ...
- 过亿云资源运维管控难?华为云CloudMap带你喝着咖啡做运维
摘要:华为云站点数字化平台CloudMap携手华为云图引擎GES打造云服务全栈拓扑,网络流量路径和云服务动态依赖等空间关系数据,支撑现网运行态风险识别和分钟级定位定界,构建业界领先的数字化能力. 本文 ...
- 30亿参数,华为云发布全球最大预训练模型,开启工业化AI开发新模式
摘要: 4月25日,华为云发布盘古系列超大规模预训练模型,包括30亿参数的全球最大视觉(CV)预训练模型,以及与循环智能.鹏城实验室联合开发的千亿参数.40TB训练数据的全球最大中文语言(NLP)预训 ...
- 华为云GaussDB(for openGauss)推出重磅内核新特性
摘要:华为云新一代金融级分布式数据库GaussDB(for openGauss)正式推出了Ustore存储引擎.基于Paxos协议的DCF高可用组件等多个重大内核新特性. 数字化时代,技术迭代更新比以 ...
- 带你读顶会论文丨基于溯源图的APT攻击检测
摘要:本次分享主要是作者对APT攻击部分顶会论文阅读的阶段性总结,将从四个方面开展. 本文分享自华为云社区<[论文阅读] (10)基于溯源图的APT攻击检测安全顶会总结>,作者:eastm ...
- JS的深浅复制,原来如此!
摘要:之所以会出现深浅拷贝的问题,实质上是由于JS对基本类型和引用类型的处理不同. 本文分享自华为云社区<js的深浅复制,一看就明白>,作者: 鑫2020. 浅复制的意思 浅复制是仅仅对数 ...