进击的 AI 生成,创造性的新世界!
2022年,AI艺术生成文本生成图像的AI绘画生成器如雨后春笋般涌现,以一幅幅“不明觉厉”的AI作品进入大众视野。从2月Disco Diffusion爆火,仅两个月后OpenAI发布DALL-E 2,谷歌和Meta紧随其后宣布了各自的AI”画家“Imagen和Make-A-Scene,再到7月MidJourney向公众付费开放,8月Stable Diffusion横空出世,AI绘画模型掀起了“人人都是艺术家”的一个个热潮。随之而来的视频生成AI模型更是让“人人都能是导演”。
文本-图像AI
由于其开源属性,以及突飞猛进的”艺术造诣”,Disco Diffusion最先引发了全民作画的热潮。只要输入文字提示(prompt),就能让AI输出它所理解的对应图像。虽然出图速度慢,在细节处理方面也比较抱歉,尤其是人脸生成,不过图片整体效果较为惊艳、氛围感强(更适合抽象艺术)。

在矩池云上生成的DD图片
相较于DD的”不拘小节“,OpenAI的DALL-E 2在细节方面拿捏比较到位,生成的图像比较精准逼真,而且作画速度提高了不少,为图像生成领域立了新的标杆。另外,DALL-E 2能对所生成的图像进行二次编辑。早期OpenAI只邀请了部分用户进行内测并且限制绘图次数,不过近期已全面开放所有人使用(中国地区账号暂不支持)。

Prompt: “a painting of a fox sitting in a field at sunrise in the style of Claude Monet
对标OpenAI的DALL-E 2,谷歌推出的Imagen声称提供了“前所未有的照片真实感和深度语言理解”。在为不同对象分配颜色、带引号文本、对象位置关系方面,Imagen表现似乎更优。不过,该模型未开放,谷歌给出的解释是:“系统太危险了,不能发布”。
同期还有另一科技巨头Meta的Make-a-scene,它的创新在于”交互+可控“,重点是用户控制。通过文本描述,再加上一张草图,让AI有针对性地生成图像。目前,只有部分艺术家受邀进行了使用。

而引发更多人关注AI绘画的是使用Midjourney生成的一副油画——

这幅使用MidJourney 生成的数字油画在美国科罗拉多州博览会(Colorado State Fair)的艺术比赛中夺得了第一名。这一新闻被报道后引发了圈内外的广泛讨论。
Midjourney也是不负众望,综合能力比较全面,图像生成速度极快,很多艺术家会借助Midjourney作为创作灵感。另外,因为 Midjourney 搭载在 Discord 频道上,所以有非常良好的社区讨论环境和用户基础。不过,表现不俗、简单上手也意味着Midjourney需要付费使用。
| AI绘画模型 | 模型 | 是否开源 | 生成速度 | 生成内容限制 | 运行设备 |
|---|---|---|---|---|---|
| Disco Diffusion | CLIP+Diffusion | 开源 | 分/时 | 无限制 | >显存10G,Nvidia 1080ti级别 |
| DALL-E 2 | CLIP+改进版GLIDE(Diffusion模型的一种) | 部分开源 | 秒/分 | 无法生成暴力、裸体或真实面孔的图像 | / |
| Stable Diffusion | Latent Diffusion | 开源 | 秒/分 | 无限制 | >显存6G,RTX 2060级别 |
“三代”AI绘画模型对比
紧接着,“更上一层楼”的Stable Diffusion来了。Stable Diffusion不仅开源免费,上手还足够简单,出图速度也极快,图片效果更为精准写实,掀起了AI绘画的又一个高潮。

在AI绘画模型“墙外开花”的同时,这股浪潮也席卷了国内,百度等科技巨头以及一大批艺术、AI从业者和爱好者也不甘其后,纷纷发布文本输入生成图像的国产AI绘画产品文心一格(暂时免费)、6pen(部分免费)、MuseArt(付费+看广告)、盗梦师(免费次数+付费微信小程序)等等。
文本-视频AI
当我们还在鉴赏(挑刺)AI生成的图像时,“下笔生花”的算法研究员们早已不满足于二维创作/图像生成,在三维甚至视频生成这一赛道上,大家也在摩拳擦掌……
Google Research的DreamFusion模型,可以通过输入简单的文本提示生成3D模型,甚至可以把生成的多个3D模型融合到一个场景里。
清华大学和智源研究院早在今年5月发布了基于Transformer的AI生成模型CogVideo,能够根据文本直接合成视频。
9月29日,Meta发布了基于AI的短视频生成模型Make-A-Video,是对其Make-A-Scene文本到图像工具的升级,可以通过文本提示生成新的视频内容。
仅一周后,谷歌接连发布了两个AI生成视频模型——Imagen Video和Phenaki。和Meta的Make-A-Video相比,谷歌的Imagen Video更高清,能生成1280*768分辨率、每秒24帧的视频片段。
Phenaki则能根据200个词左右的提示语生成2分钟以上的长镜头,就是说,人人都能是”导演”了。Phenaki还可以任意切换视频风格,高清视频或卡通。
在视频风格转换方面,几天前来自新加坡南洋理工大学的研究团队发布了一个能够进行可控高分辨率人像视频风格转换的框架——VToonify。基于StyleGAN的VToonify满足了很多人在短视频平台上使用卡通形象录制视频的需求,可以实现对人像进行高度可调的卡通风格切换。
AI生成技术的迭代
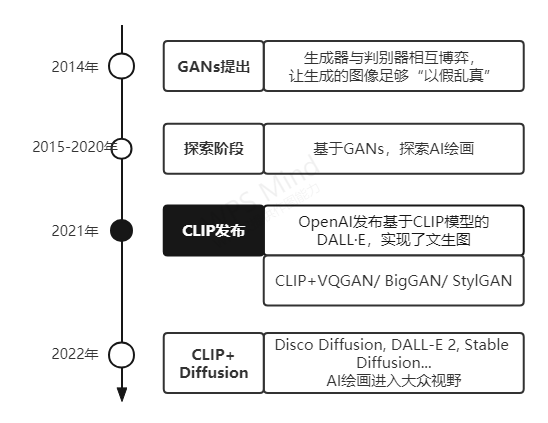
AI生成图像的表现越来越出色,得益于深度学习模型的快速迭代。2012年,AI大牛吴恩达和Jeff Dean等人通过1000台电脑创造出多达10亿个连接的“神经网络”,基于上千万张猫脸图片进行训练后,最终生成了一个模糊的猫脸,这意味着机器自主学会了识别猫脸。
在这一开创性猫脸生成实验后,AI科学家们在图像生成方向上继续摸索。两年后大名鼎鼎的对抗生成网络GANs诞生,它通过生成器和判别器两者的互相对抗不断提升生成能力。自此,AI生成领域主要基于GANs进行了不断的尝试。
彼时,AI绘画还无法实现通过文字输入提示(prompt)进行图像生成。
直到2021年,OpenAI发布了一个新的深度学习模型CLIP(Contrastive Language-Image Pre-Training),实现了图像与文本的匹配。CLIP基于大规模图文数据集进行了对比学习训练,学习给定文本片段与图像的关联。也就是说,CLIP并不是试图预测给定图像的对应文字说明,而是只学习任何给定文本与图像之间的关联。好的,自然语言和视觉任务的跨界界限自此被CLIP打破!
生成式AI会让艺术家们失业吗
而每当技术爆炸迭代到令人瞠目结舌的地步,“人类会不会被机器取代”这一永恒命题又悄然而至——AI会让艺术家们失业吗?AI会冲击短视频行业吗?
就像其他职业的AI威胁论一样,AI取代部分机械重复性较高的工作可能不可避免,但天马行空的想象力和四季三餐的情感共鸣对于AI来说想得而不可得。正如Midjourney创始人David Holz评论AI绘画,
“汽车比人的速度快,但这并不意味着我们不再行走。远距离移动大量物体时,我们需要用到发动机,无论是飞机、轮船还是汽车。我们认为AI绘画技术就是想象力的引擎。”
参考链接
https://mp.weixin.qq.com/s/LsJwRMSqPXSjSyhoNgzi6w
https://github.com/OpenAI/CLIP
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
进击的 AI 生成,创造性的新世界!的更多相关文章
- 都在用 AI 生成美少女,而我却。。。
最近 AI 画画特别的火,你能从网上看到非常多好看的图片,于是我就开始了我的安装之旅,我看到的图是这样的. 这样的. 还有这样的. 然后我就开始了我的 AI 安装生成计划. 安装环境 首先我们需要安装 ...
- AI生万物,新世界的大门已敞开
四月是万物复苏的时节,一年一度的GMIC全球移动互联网大会也在这个时间如期而至,在4月26日-28日的会议期间,有超过三百位行业专家进行了精彩的演讲,更有数万名现场观众感受到思维碰撞迸发出的火花. 作 ...
- 在矩池云使用Disco Diffusion生成AI艺术图
在 Disco Diffusion 官方说明的第一段,其对自身是这样定义: AI Image generating technique called CLIP-Guided Diffusion.DD ...
- 生成式AI会成为是人工智能的未来吗
生成式 AI 是一项创新技术,可帮助算法人员生成以前依赖于业务员的模型,提供创造性的结果,而不会因业务员思想和经验而产生任何差错. 人工智能中的这项新技术确定了输入的原始模型,以生成演示训练数据特征. ...
- 生成式AI对业务流程有哪些影响?企业如何应用生成式AI?一文看懂
集成与融合类ChatGPT工具与技术,以生成式AI变革业务流程 ChatGPT背后的生成式AI,聊聊生成式AI如何改变业务流程 ChatGPT月活用户过亿,生成式AI对组织的业务流程有哪些影响? 生成 ...
- 五毛党可能要失业了,因为AI水军来了
当AI已经开始写稿.唱歌.翻译文章.把语音转录为文字的时候,我们其实应该清醒的认识到,五毛党要消亡了. 相信大部分人和小编一样,现在只要出门吃饭,就会打开大众点评搜好吃的,看评分,看网友的评论.一般来 ...
- Python开发AI应用-国际象棋应用
AI 部分总述 AI在做出决策前经过三个不同的步骤.首先,他找到所有规则允许的棋步(通常在开局时会有20-30种,随后会降低到几种).其次,它生成一个棋步树用来随后决定最佳决策.虽然树的大小随 ...
- 会议更流畅,表情更生动!视频生成编码 VS 国际最新 VVC 标准
阿里云视频云的标准与实现团队与香港城市大学联合开发了基于 AI 生成的人脸视频压缩体系,相比于 VVC 标准,两者质量相当时可以取得 40%-65% 的码率节省,旨在用最前沿的技术,普惠视频通话.视频 ...
- AI 智能写情诗、藏头诗
一.AI 智能情诗.藏头诗展示 最近使用PyTorch的LSTM训练一个写情诗(七言)的模型,可以随机生成情诗.也可以生成藏头情诗. 在特殊的日子用AI生成一首这样的诗,是不是很酷!下面分享下AI 智 ...
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- [转帖]linux时间戳转换成时间指令_时间戳转换公式
原文地址:http://wanping.blogbus.com/logs/28663569.html 1.时间戳转换为正常显示的时间格式 Freebsd 系统下: 转换命令为: date -r 111 ...
- [转帖]⭐万字长篇超详细的图解Tomcat中间件方方面面储备知识⭐
https://developer.aliyun.com/article/885079?spm=a2c6h.24874632.expert-profile.321.7c46cfe9h5DxWK 202 ...
- [转帖]Java 内存管理
https://www.cnblogs.com/xiaojiesir/p/15590092.html Java 内存模型简称 JMM,全名 Java Memory Model .Java 内存模型 ...
- Lectures
Copy and Paste 3(P9523) Problem Solution 转移方程中的"父问题枚举子问题寻找转移"可以转成"子问题寻找父问题主动转移"处 ...
- vue动画 <transition-group> 使用半场动画
<style> /* 给动画添加一组过度效果 */ .v-enter, .v-leave-to { opacity: 0.8; /* 从右向左进入 */ transform: transl ...
- 2022美亚杯个人wp
检材文件下载链接:https://pan.baidu.com/s/1kg8FMeMaj6BIBmuvUZHA3Q?pwd=ngzs 提取码:ngzs 个人赛与团队赛下载文件解压密码:MeiyaCup2 ...
- TienChin 创建菜单页面
上一节当中我们只是给后台添加了对应的菜单,实际上对应的页面还没有存在这节主要就是创建出来页面: 促销活动: activity 统计分析: analysis 商机管理: business 渠道管理: c ...
- Python 检测PE所启用保护方式
Python 通过pywin32模块调用WindowsAPI接口,实现对特定进程加载模块的枚举输出并检测该PE程序模块所启用的保护方式,此处枚举输出的是当前正在运行进程所加载模块的DLL模块信息,需要 ...
- PE格式:新建节并插入DLL
首先老样子,我们先来到PE节表位置处,并仿写一个.hack的节,该节大小为0x1000字节,在仿写前我们需要先来计算出.hack的虚拟偏移与实际偏移,先来查询一下当前节表结构,如下: 接着我们通过公式 ...
- (python)代码学习||2024.2.3||题目是codewars上的【Validate Sudoku with size `NxN`】
题目的要求是写一个Sudoku类,类中要有一个实例函数判断传给对象的二维数组是否符合数独规则 题目链接:https://www.codewars.com/kata/540afbe2dc9f615d5e ...