手把手教你用 NebulaGraph AI 全家桶跑图算法

前段时间 NebulaGraph 3.5.0 发布,@whitewum 吴老师建议我把前段时间 NebulaGraph 社区里开启的新项目 ng_ai 公开给大家。
所以,就有了这个系列文章,本文是该系列的开篇之作。
ng_ai 是什么
ng_ai 的全名是:Nebulagraph AI Suite,顾名思义,它是在 NebulaGraph 之上跑算法的 Python 套件,希望能给 NebulaGraph 的用户一个自然、简洁的高级 API。简单来说,用很少的代码量就可以执行图上的算法相关的任务。
ng_ai 这个开源项目的目标是,快速迭代、公开讨论、持续演进,一句话概述便是:
Simplifying things in surprising ways.
这个 ng_ai 的专属 url:https://github.com/wey-gu/nebulagraph-ai 可以帮你了解更全面的它。
ng_ai 的特点
为了让 NebulaGraph 社区的小伙伴拥有顺滑的算法体验,ng_ai 有以下特点:
- 与 NebulaGraph 紧密结合,方便从其中读、写图数据
- 支持多引擎、后端,目前支持 Spark(NebulaGraph Algorithm)、NetworkX,之后会支持 DGL、PyG
- 友好、符合直觉的 API 设计
- 与 NebulaGraph 的 UDF 无缝结合,支持从 Query 中调用 ng_ai 任务
- 友好的自定义算法接口,方便用户自己实现算法(尚未完成)
- 一键试玩环境(基于 Docker Extensions)
你可以这么用 ng_ai
跑分布式 PageRank 算法
可以在一个大图上,基于 nebula-algorithm 分布式地跑 PageRank 算法,像是这样:
from ng_ai import NebulaReader
# scan 模式,通过 Spark 引擎读取数据
reader = NebulaReader(engine="spark")
reader.scan(edge="follow", props="degree")
df = reader.read()
# 运行 PageRank 算法
pr_result = df.algo.pagerank(reset_prob=0.15, max_iter=10)
写回算法结果到 NebulaGraph
假设我们要跑一个 Label Propagation 算法,然后把结果写回 NebulaGraph,我们可以这么做:
先确保结果中要写回图数据库的数据 Schema 已经创建好了,像是下面的示例,便是写到 label_propagation.cluster_id 字段里:
CREATE TAG IF NOT EXISTS label_propagation (
cluster_id string NOT NULL
);
下面,我们来看下具体流程。执行算法:
df_result = df.algo.label_propagation()
再看一下结果的 Schema:
df_result.printSchema()
root
|-- _id: string (nullable = false)
|-- lpa: string (nullable = false)
参考下面的代码,把 lpa 的结果写回 NebulaGraph 中的 cluster_id 字段里({"lpa": "cluster_id"}):
from ng_ai import NebulaWriter
from ng_ai.config import NebulaGraphConfig
config = NebulaGraphConfig()
writer = NebulaWriter(
data=df_result, sink="nebulagraph_vertex", config=config, engine="spark"
)
# 将 lpa 同 cluster_id 进行映射
properties = {"lpa": "cluster_id"}
writer.set_options(
tag="label_propagation",
vid_field="_id",
properties=properties,
batch_size=256,
write_mode="insert",
)
# 将数据写回到 NebulaGraph
writer.write()
最后,验证一下:
USE basketballplayer;
MATCH (v:label_propagation)
RETURN id(v), v.label_propagation.cluster_id LIMIT 3;
结果:
+-------------+--------------------------------+
| id(v) | v.label_propagation.cluster_id |
+-------------+--------------------------------+
| "player103" | "player101" |
| "player113" | "player129" |
| "player121" | "player129" |
+-------------+--------------------------------+
更详细的例子参考:ng_ai/examples
通过 nGQL 调用算法
自 NebulaGraph v3.5.0 开始,用户可从 nGQL 中调用自己实现的函数。而 ng_ai 也用这个能力来实现了一个自己的 ng_ai 函数,让它从 nGQL 中调用 ng_ai 的算法,例如:
-- 准备将要写入数据的 Schema
USE basketballplayer;
CREATE TAG IF NOT EXISTS pagerank(pagerank string);
:sleep 20;
-- 回调 ng_ai()
RETURN ng_ai("pagerank", ["follow"], ["degree"], "spark", {space: "basketballplayer", max_iter: 10}, {write_mode: "insert"})
更详细的例子参考:ng_ai/examples
单机运行算法
在单机、本地的环境,ng_ai 支持基于 NetworkX 运行算法。
举个例子,读取图为 ng_ai graph 对象:
from ng_ai import NebulaReader
from ng_ai.config import NebulaGraphConfig
# query 模式,通过 NebulaGraph 或是 NetworkX 引擎读取数据
config_dict = {
"graphd_hosts": "graphd:9669",
"user": "root",
"password": "nebula",
"space": "basketballplayer",
}
config = NebulaGraphConfig(**config_dict)
reader = NebulaReader(engine="nebula", config=config)
reader.query(edges=["follow", "serve"], props=[["degree"], []])
g = reader.read()
查看、画图:
g.show(10)
g.draw()
运行算法:
pr_result = g.algo.pagerank(reset_prob=0.15, max_iter=10)
写回 NebulaGraph:
from ng_ai import NebulaWriter
writer = NebulaWriter(
data=pr_result,
sink="nebulagraph_vertex",
config=config,
engine="nebula",
)
# 待写入的属性
properties = ["pagerank"]
writer.set_options(
tag="pagerank",
properties=properties,
batch_size=256,
write_mode="insert",
)
# 将数据写回到 NebulaGraph
writer.write()
其他算法:
# 获取所有算法
g.algo.get_all_algo()
# 获取相关算法的帮助信息
help(g.algo.node2vec)
# 调用算法
g.algo.node2vec()
更详细的例子参考:ng_ai/examples
可视化图算法结果
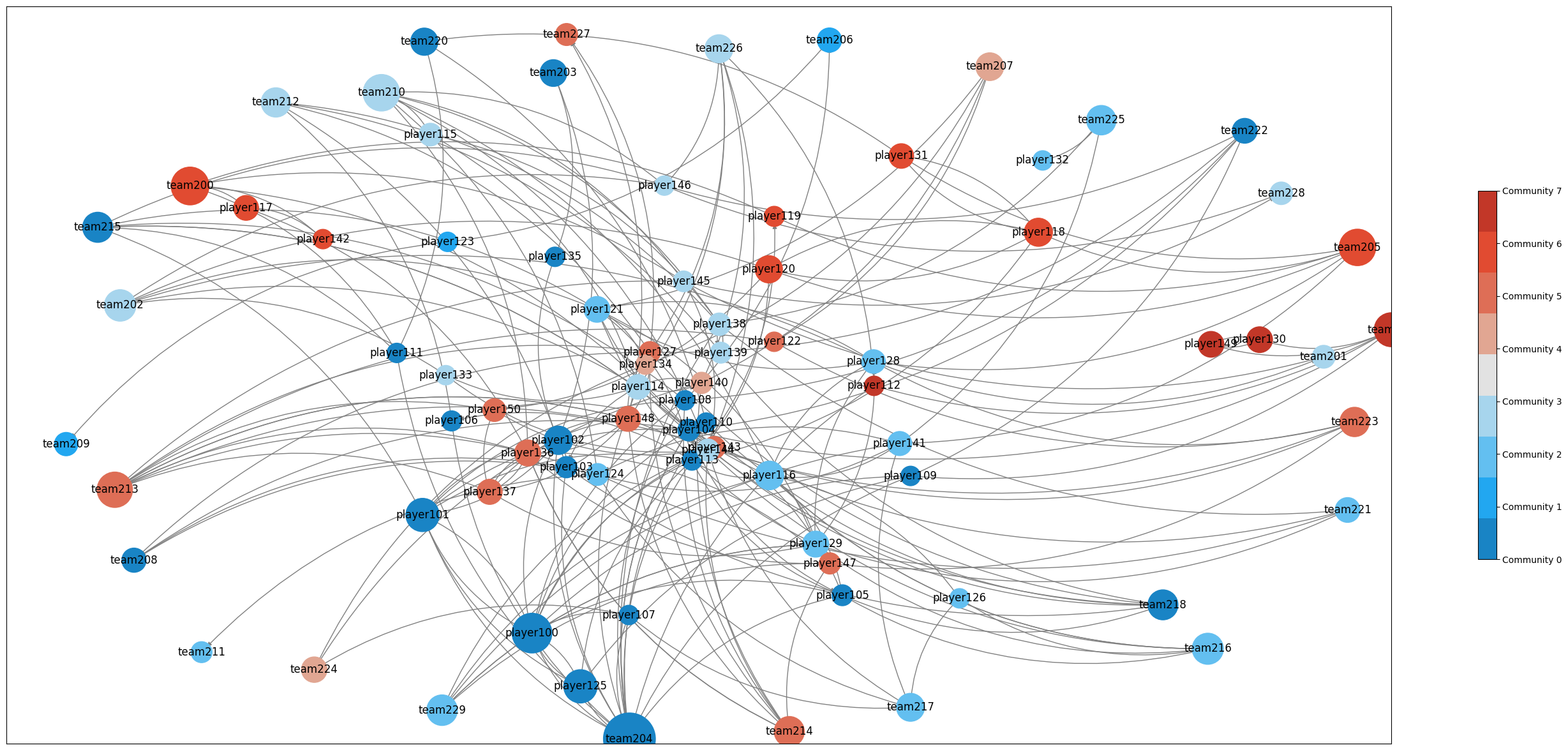
这里演示一个 NetworkX 引擎情况下,计算 Louvain、PageRank 并可视化的例子:
先执行两个图算法:
pr_result = g.algo.pagerank(reset_prob=0.15, max_iter=10)
louvain_result = g.algo.louvain()
再手写一个画图好看的函数:
from matplotlib.colors import ListedColormap
def draw_graph_louvain_pr(G, pr_result, louvain_result, colors=["#1984c5", "#22a7f0", "#63bff0", "#a7d5ed", "#e2e2e2", "#e1a692", "#de6e56", "#e14b31", "#c23728"]):
# 设定节点的位置
pos = nx.spring_layout(G)
# 新建一个图形并设置坐标轴
fig, ax = plt.subplots(figsize=(35, 15))
ax.set_xlim(-1, 1)
ax.set_ylim(-1, 1)
# 从颜色列表中创建一个 colormap
cmap = ListedColormap(colors)
# 将图中的节点和边进行绘图
node_colors = [louvain_result[node] for node in G.nodes()]
node_sizes = [70000 * pr_result[node] for node in G.nodes()]
nx.draw_networkx_nodes(G, pos=pos, ax=ax, node_color=node_colors, node_size=node_sizes, cmap=cmap, vmin=0, vmax=max(louvain_result.values()))
nx.draw_networkx_edges(G, pos=pos, ax=ax, edge_color='gray', width=1, connectionstyle='arc3, rad=0.2', arrowstyle='-|>', arrows=True)
# 提取边数据中的 label 数据作为字典
edge_labels = nx.get_edge_attributes(G, 'label')
# 在图中加入边的 label 数据
for edge, label in edge_labels.items():
ax.text((pos[edge[0]][0] + pos[edge[1]][0])/2,
(pos[edge[0]][1] + pos[edge[1]][1])/2,
label, fontsize=12, color='black', ha='center', va='center')
# 在图中加入点的 label 数据
node_labels = {n: G.nodes[n]['label'] if 'label' in G.nodes[n] else n for n in G.nodes()}
nx.draw_networkx_labels(G, pos=pos, ax=ax, labels=node_labels, font_size=12, font_color='black')
# 为同社区数据添加相同颜色
sm = plt.cm.ScalarMappable(cmap=cmap, norm=plt.Normalize(vmin=0, vmax=max(louvain_result.values())))
sm.set_array([])
cbar = plt.colorbar(sm, ax=ax, ticks=range(max(louvain_result.values()) + 1), shrink=0.5)
cbar.ax.set_yticklabels([f'Community {i}' for i in range(max(louvain_result.values()) + 1)])
# 数据展示
plt.show()
draw_graph_louvain_pr(G, pr_result=pr_result, louvain_result=louvain_result)
效果如下所示:
更详细的例子参考:ng_ai/examples
更方便的 Notebook 操作 NebulaGraph
结合 NebulaGraph 的 Jupyter Notebook 插件: https://github.com/wey-gu/ipython-ngql,我们还可以更便捷地操作 NebulaGraph:
可通过 ng_ai 的 extras 在 Jupyter Notbook 中安装插件:
%pip install ng_ai[jupyter]
%load_ext ngql
当然,也可以单独安装插件:
%pip install ipython-ngql
%load_ext ngql
安装完成后,就可以在 Notebook 里直接使用 %ngql 命令来执行 nGQL 语句:
%ngql --address 127.0.0.1 --port 9669 --user root --password nebula
%ngql USE basketballplayer;
%ngql MATCH (v:player{name:"Tim Duncan"})-->(v2:player) RETURN v2.player.name AS Name;
注,多行的 Query 用两个百分号就好了
%%ngql
最后,我们还能在 Jupyter Notebook 里直接可视化渲染结果!只需要 %ng_draw 就可以啦!
%ngql match p=(:player)-[]->() return p LIMIT 5
%ng_draw
效果如下:

未来工作
现在 ng_ai 还在开发中,我们还有很多工作要做:
- 完善 Reader 模式,现在 NebulaGraph / NetworkX 的读取数据只支持 Query-Mode,还需要支持 Scan-Mode
- 实现基于 dgl(GNN)的链路预测、节点分类等算法,例如:
model = g.algo.gnn_link_prediction()
result = model.train()
# query src, dst to be predicted
model.predict(src_vertex, dst_vertices)
- UDA,自定义算法
- 快速部署工具
ng_ai 完全 build in public,欢迎社区的大家们来参与,一起来完善 ng_ai,让 NebulaGraph 上的 AI 算法更加简单、易用!
试玩 ng_ai
我们已经准备好了一键部署的 NebulaGraph + NebulaGraph Studio + ng_ai in Jupyter 的环境,只需要大家从 Docker Desktop 的 Extension(扩展)中搜索 NebulaGraph,就可以试玩了。
在 Docker Desktop 的插件市场搜索 NebulaGraph,点击安装:
- 安装 ng_ai Playground
进入 NebulaGraph 插件,点击 Install NX Mode,安装 ng_ai 的 NetworkX Playground,通常要等几分钟等待安装完成。
- 进入 NetworkX Playground
点击 Jupyter NB NetworkX,进入 NetworkX Playground。
ng_ai 的架构
ng_ai 的架构如下,它的核心模块有:
- Reader:负责从 NebulaGraph 读取数据
- Writer:负责将数据写入 NebulaGraph
- Engine:负责适配不同运行时,例如 Spark、DGL、NetowrkX 等
- Algo:算法模块,例如 PageRank、Louvain、GNN_Link_Predict 等
此外,为了支持 nGQL 中的调用,还有两个模块:
- ng_ai-udf:负责将 UDF 注册到 NebulaGraph,接受 ng_ai 的 Query 调用,访问 ng_ai API
- ng_ai-api:ng_ai 的 API 服务,接受 UDF 的调用,访问 ng_ai 核心模块
┌───────────────────────────────────────────────────┐
│ Spark Cluster │
│ .─────. .─────. .─────. .─────. │
│ ; : ; : ; : ; : │
┌─│ : ; : ; : ; : ; │
│ │ ╲ ╱ ╲ ╱ ╲ ╱ ╲ ╱ │
│ │ `───' `───' `───' `───' │
Algo Spark │
Engine└───────────────────────────────────────────────────┘
│ ┌────────────────────────────────────────────────────┬──────────┐
└──┤ │ │
│ NebulaGraph AI Suite(ngai) │ ngai-api │─┐
│ │ │ │
│ └──────────┤ │
│ ┌────────┐ ┌──────┐ ┌────────┐ ┌─────┐ │ │
│ │ Reader │ │ Algo │ │ Writer │ │ GNN │ │ │
┌───────│ └────────┘ └──────┘ └────────┘ └─────┘ │ │
│ │ │ │ │ │ │ │
│ │ ├────────────┴───┬────────┴─────┐ └──────┐ │ │
│ │ ▼ ▼ ▼ ▼ │ │
│ │ ┌─────────────┐ ┌──────────────┐ ┌──────────┐ ┌──────────┐ │ │
│ ┌──┤ │ SparkEngine │ │ NebulaEngine │ │ NetworkX │ │ DGLEngine│ │ │
│ │ │ └─────────────┘ └──────────────┘ └──────────┘ └──────────┘ │ │
│ │ └──────────┬────────────────────────────────────────────────────┘ │
│ │ │ Spark │
│ │ └────────Reader ────────────┐ │
│ Spark Query Mode │ │
│ Reader │ │
│Scan Mode ▼ ┌─────────┐
│ │ ┌───────────────────────────────────────────────────┬─────────┤ ngai-udf│─────────────┐
│ │ │ │ └─────────┤ │
│ │ │ NebulaGraph Graph Engine Nebula-GraphD │ ngai-GraphD │ │
│ │ ├──────────────────────────────┬────────────────────┼───────────────────┘ │
│ │ │ │ │ │
│ │ │ NebulaGraph Storage Engine │ │ │
│ │ │ │ │ │
│ └─│ Nebula-StorageD │ Nebula-Metad │ │
│ │ │ │ │
│ └──────────────────────────────┴────────────────────┘ │
│ │
│ ┌───────────────────────────────────────────────────────────────────────────────────────┐ │
│ │ RETURN ng_ai("pagerank", ["follow"], ["degree"], "spark", {space:"basketballplayer"}) │──┘
│ └───────────────────────────────────────────────────────────────────────────────────────┘
│ ┌─────────────────────────────────────────────────────────────┐
│ │ from ng_ai import NebulaReader │
│ │ │
│ │ # read data with spark engine, scan mode │
│ │ reader = NebulaReader(engine="spark") │
│ │ reader.scan(edge="follow", props="degree") │
└──│ df = reader.read() │
│ │
│ # run pagerank algorithm │
│ pr_result = df.algo.pagerank(reset_prob=0.15, max_iter=10) │
│ │
└─────────────────────────────────────────────────────────────┘
谢谢你读完本文 (///▽///)
欢迎前往 GitHub 来阅读 NebulaGraph 源码,或是尝试用它解决你的业务问题 yo~ GitHub 地址:https://github.com/vesoft-inc/nebula
手把手教你用 NebulaGraph AI 全家桶跑图算法的更多相关文章
- 手把手教你全家桶之React(一)
前言 最近项目用到react,其实前年我就开始接触react,时光匆匆,一直没有时间整理下来(太懒啦)!如今再次用到,称工作间隙,对全家桶做一次总结,项目源码地址.废话不多说,上码. 创建一个文件目录 ...
- 手把手教你全家桶之React(二)
前言 上一篇已经讲了一些react的基本配置,本遍接着讲热更新以及react+redux的配置与使用. 热更新 我们在实际开发时,都有用到热更新,在修改代码后,不用每次都重启服务,而是自动更新.并而不 ...
- 手把手教你全家桶之React(三)--完结篇
前言 本篇主要是讲一些全家桶的优化与完善,基础功能上一篇已经讲得差不多了.直接开始: Source Maps 当javaScript抛出异常时,我们会很想知道它发生在哪个文件的哪一行.但是webpac ...
- 教你干掉win10全家桶
原文: 教你干掉win10全家桶 这些并不好用的自带应用例如:groove音乐,相片,股票……一直占据着我们的默认应用.如果它们是一直静静的躺在那里还好,最多不用就是了.当我们想要浏览图片或者看视频的 ...
- 【转】手把手教你读取Android版微信和手Q的聊天记录(仅作技术研究学习)
1.引言 特别说明:本文内容仅用于即时通讯技术研究和学习之用,请勿用于非法用途.如本文内容有不妥之处,请联系JackJiang进行处理! 我司有关部门为了获取黑产群的动态,有同事潜伏在大量的黑产群 ...
- 手把手教你读取Android版微信和手Q的聊天记录(仅作技术研究学习)
1.引言 特别说明:本文内容仅用于即时通讯技术研究和学习之用,请勿用于非法用途.如本文内容有不妥之处,请联系JackJiang进行处理! 我司有关部门为了获取黑产群的动态,有同事潜伏在大量的黑产群 ...
- mac设计师系列 Adobe “全家桶” 15款设计软件 值得收藏!
文章素材来源:风云社区.简书 文章收录于:风云社区 www.scoee.com,提供1700多款mac软件下载 Adobe Creative Cloud 全线产品均可开放下载(简称Adobe CC 全 ...
- NN入门,手把手教你用Numpy手撕NN(三)
NN入门,手把手教你用Numpy手撕NN(3) 这是一篇包含极少数学的CNN入门文章 上篇文章中简单介绍了NN的反向传播,并利用反向传播实现了一个简单的NN,在这篇文章中将介绍一下CNN. CNN C ...
- win10 uwp 手把手教你使用 asp dotnet core 做 cs 程序
本文是一个非常简单的博客,让大家知道如何使用 asp dot net core 做后台,使用 UWP 或 WPF 等做前台. 本文因为没有什么业务,也不想做管理系统,所以看到起来是很简单. Visua ...
- 2020版Adobe全家桶介绍及免费下载安装
前言 Adobe公司创建于1982年,是世界领先的数字媒体和在线营销解决方案供应商.公司总部位于美国加利福尼亚州圣何塞.Adobe 的 客户包括世界各地的企业.知识工作者.创意人士和设计者.OEM合作 ...
随机推荐
- linux线程调度策略
linux线程调度策略 这是一篇非常好的关于线程调度的资料,翻译自shed 目录 linux线程调度策略 Scheduling policies SCHED_FIFO: First in-first ...
- TypeScript中Never类型和类型断言
Never 类型 never类型表示:那些永不存在的值的类型. 例如:never类型是那些总是会[抛出异常]或根本就[不会有返回值的函数表达式]或[箭头函数表达式的返回值类型] never类型是任何类 ...
- 【JS 逆向百例】有道翻译接口参数逆向
逆向目标 目标:有道翻译接口参数 主页:https://fanyi.youdao.com/ 接口:https://fanyi.youdao.com/translate_o?smartresult=di ...
- 【第4个渗透靶机项目】 Tr0ll
每天都要加油哦! 0x00 信息搜集 首先找到一下靶机的ip,并扫描端口. 靶机和kali都是桥接. 那么先看一下kali的ifconfig信息. nmap -sn 192.168.0.0/24 ...
- 每日一库:Memcache
Memcache 是一个高性能.分布式的内存缓存系统,常用于缓存数据库查询结果.API调用结果.页面内容等,以提升应用程序的性能和响应速度.下面详细介绍一些 Memcache 的特点和使用方式: 内存 ...
- python截取字符串(字符串切片)
python中使用[]来截取字符串,语法: 字符串[起始位置:结束位置] 一.起始位置:结束位置 先看几个例子: s = 'python' print(s) #输出 python 直接输出字符串 #从 ...
- AI PC两年要大卖1亿台!就靠它了
Intel在中国北京召开了主题为"AI无处不在,创芯无所不及"的2023Intel新品发布会暨AI技术创新派对,正式发布了代号为"Meteor Lake"的面向 ...
- 教你用Java实现动态调色板
案例介绍 欢迎来到我的小院,我是霍大侠,恭喜你今天又要进步一点点了!我们来用Java编程实战案例,做一个动态调色板.案例界面会出现三个滑动组块以及对应的数值,通过移动滑块可以改变颜色区域的显示.通过实 ...
- 深入浅出 Application Insights--学习笔记
摘要 介绍如何将 Application Insights 用于生产上实践,并透过它发现/诊断问题.同时也会介绍如何将 Application Insighs 与其他体系相集成实现 Devops(与发 ...
- CF1886
A 分类讨论. B 二分. C 题意:给定一个字符串 \(s\).记 \(s_i\) 为将 \(s\) 删去 \(i\) 个字符,使得剩余字符串字典序最小得到的字符串.令 \(S=s_0+s_1+\d ...