对比python学julia(第四章:人工智能)--(第三节)目标检测
1.1. 项目简介
目标检测(Object Detection)的任务是在图像中找出检测对象的位置和犬小,是计算机视觉领域的核心问题之一,在自动驾驶、机器人和无人机等许多领域极具研究价值。
随着深度学习的兴起,基于深度学习的目标检测算法逐渐成为主流。深度学习是指在多层神经网络上运用各种机器学习算法决图像、文本等各种问题的算法集合。因此,基于深度学习的目标检测算法又披称为目标检测网络。
本项目使用一种名为 MobileNet-SSD的目标检测网络对图像进行目标捡测。
MobileNet-SSD 能够在图像中检测出飞机、自行车、鸟、船、瓶子、公交车、汽车、猫、椅子、奶牛、餐桌、狗、马、摩托车、人、盆栽、羊、沙发、火车和电视机共 20 种物体和 1 种背景,平均准确率能达到72. 7%。由于训练神经网络需要大量的数据和强大的算力,这里将使用一个已经训练好的目
标检测网络模型。在 Python 中,可以通过OpenCV 的dnn模块使用训练好的模型对图像进行目标检测,其步骤如下。
(1) 加载 MobileNet_SSD目标检测网络模型。
(2) 读入待检测图像,并将其转换成 blob 数据包。
(3) 将 blob 数据包传入目标检测网络,并进行前向传播。
(4) 根据返回结果标注图像中被检测出的对象。
1.2. 准备工作
在磁盘上创建一个名为“object-detect”的文件夹作项目目录,用于存放本项目的模型、源程序、图像和视频等文件,然后从原书“资源包/第 34 课”文件夹中把 model、images 和 videos3 个文件夹复制到“object-detect”文件夹中。
在model文件夹中提供 MobileNetSSD目标捡测网络模型文件,包括神经网络模型文件 MobileNetSSD_deploy.caffemodel 和网络结构 描述文件MobileNetSSD_deploy.prdtotxt。
在images文件夹中提供一些用于进行目标检测的图像,这些图像里含有汽车、飞机、行人、马、猫等。
1.3. 目标检测过程
新建一个空白源文件,以object_detection.jl作为文件名保存至“object-detect”文件夹中,然后编写程序检测图像中的物体,具体过程如下。
(1) 导入cv2和其他模块
using PyCall
using Printf
using Distributions
cv2=pyimport("cv2")
说明:Printf库主要用于字符串的格式化输出。Distributions库是用于概率分布和相关函数的Julia包,这里用于配合随机数发生器,生成一定分布范围的随机数。Distributions库需要安装。
(2) 创建表示图像文件、网络描述文件和网络模型文件等的变量。
#指定图像和模型文件路径
image_path = "./images/example_1.jpg"
prototxt = "./model/MobileNetSSD_deploy.prototxt"
model = "./model/MobileNetSSD_deploy.caffemodel"
(3) 创建物体分类标签、颜色和字体等的变量。
#设定目标名称
CLASSES = ("background", "aeroplane", "bicycle", "bird", "boat",
"bottle", "bus", "car", "cat", "chair", "cow", "dining-table",
"dog", "horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor")
COLORS =rand(Uniform(0, 255),length(CLASSES),3)#
FONT = cv2.FONT_HERSHEY_SIMPLEX
CLASSES 变量中这些分类标签是通过 MobileNet-SSD 网络训练的能够被检测的物体的名称,包括20种物体和1种背景。
COLORS 变量存放的是随机分配的标签颜色。这里原python代码是这样的:
COLORS =numpy.random.uniform(0, 255, size=(len(CLASSES), 3))
对于Julia,我们安装了Distributions库,就可以配合rand函数生成0-255范围内的随机数。
(4) 使用dnn模块从文件中加载神经网络模型。
#加载网络模型
net = cv2.dnn.readNetFromCaffe(prototxt, model)
(5) 从文件中加载待检测的图像,用来构造一个 blob 数据包。
#读取图像并进行预处理
image = cv2.imread(image_path)
(h, w) = size(image)[1:2]
input_img = cv2.resize(image, (300, 300))
blob = cv2.dnn.blobFromImage(input_img, 0.007843, (300, 300), 127.5 rimg = permutedims(image, ndims(image):-1:1)
pyimg = PyReverseDims(rimg)
cv2.dnn.blobFromImage函数返回一个blob 数据包,它是经过均值减法、归一化和通道交换之后的输人图。由于训练 MobileNet-SSD 网络时使用的是 300 * 300 大小的图像,所以这里也需要使用相同尺寸的图像。
(6) 将 blob 数据包传人 MobileNet-SSD目标检测网络,并进行前向传播,然后等待返回检测结果。
#将图像传入网络
net.setInput(blob)
detections = net.forward()
(7) 用循环结构读取检测结果中的检测区域,并标注出矩形框、分类名称和可信度。
#对结果进行处理
for i in 1:size(detections)[3]
idx =floor(Int,detections[1, 1, i, 2])
confidence = detections[1, 1, i, 3]
if confidence > 0.2
#画矩形框
#println(size(detections))
box = detections[1, 1, i, 4:7].* [w, h, w, h]
(x1, y1, x2, y2) = floor.(Int,box)#.astype("int")
#println(idx)
cv2.rectangle(pyimg, (x1, y1), (x2, y2), COL-ORS[idx], 2)
#标注信任度
label =label=@sprintf("[INFO] %s: %0.2f%%",CLASSES[idx], confidence * 100)
#print(label)
cv2.putText(pyimg, label, (x1, y1), FONT, 1, COLORS[idx], 1)
end
end
(8) 将检测结果图像显示在窗口中。
#显示图像并等待
cv2.imshow("Image", pyimg)
cv2.waitKey(0)
cv2.destroyAllWindows()
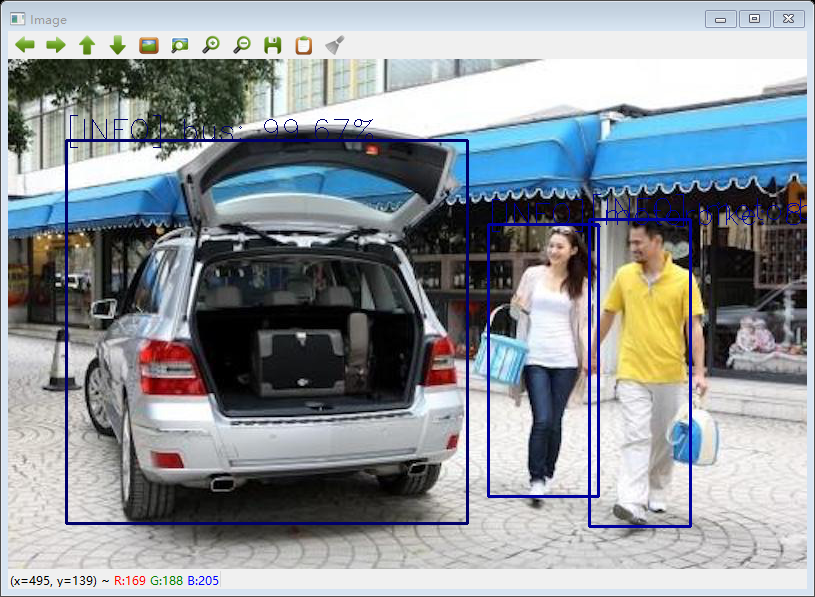
至此 目标检测程序编写完毕。运程程序,对图像(example_1.jpg)的检测结果如图所示:
由于源码包比较大,博客园限制上传。我把源码放在了这里:
julia+OpenCV目标检测代码-深度学习文档类资源-CSDN文库
对比python学julia(第四章:人工智能)--(第三节)目标检测的更多相关文章
- python学习心得第四章
python 学习心得第四章 1.lambda表达式 1:什么是lambda表达式 为了简化简单函数的代码,选择使用lambda表达式 上面两个函数的表达式虽然不一样,但是本质是一样的,并且lamb ...
- 进击的Python【第十四章】:Web前端基础之Javascript
进击的Python[第十四章]:Web前端基础之Javascript 一.javascript是什么 JavaScript 是一种轻量级的编程语言. JavaScript 是可插入 HTML 页面的编 ...
- 《Python CookBook2》 第四章 Python技巧 对象拷贝 && 通过列表推导构建列表
(先学第四章) 对象拷贝 任务: Python通常只是使用指向原对象的引用,并不是真正的拷贝. 解决方案: >>> a = [1,2,3] >>> import c ...
- [Python学习笔记][第四章Python字符串]
2016/1/28学习内容 第四章 Python字符串与正则表达式之字符串 编码规则 UTF-8 以1个字节表示英语字符(兼容ASCII),以3个字节表示中文及其他语言,UTF-8对全世界所有国家需要 ...
- 《零压力学Python》 之 第四章知识点归纳
第四章(决策和循环)知识点归纳 if condition: indented_statements [ elif condition: Indented_statements] [else: Inde ...
- python 教程 第十四章、 地址薄作业
第十四章. 地址薄作业 #A Byte of Python #!/usr/bin/env python import cPickle import os #define the contacts fi ...
- 2018-06-20 中文代码示例视频演示Python入门教程第四章 控制流
知乎原链 续前作: 中文代码示例视频演示Python入门教程第三章 简介Python 对应在线文档: 4. More Control Flow Tools 录制中出了不少岔子. 另外, 输入法确实是一 ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week3 目标检测
一.目标定位 这一小节视频主要介绍了我们在实现目标定位时标签该如何定义. 上图左下角给出了损失函数的计算公式(这里使用的是平方差) 如图示,加入我们需要定位出图像中是否有pedestrian,car, ...
- 【Learning Python】【第四章】Python代码结构(一)
这一章的主旨在于介绍python的代码结构 缩进 在很多的编程语言中,一般{}用于控制代码块,比如以下的一段C代码 if(var <= 10) { printf("....." ...
- Python开发【第四章】:Python函数剖析
一.Python函数剖析 1.函数的调用顺序 #!/usr/bin/env python # -*- coding:utf-8 -*- #-Author-Lian #函数错误的调用方式 def fun ...
随机推荐
- HMI-Board上手指南
介绍 HMI-Board为 RT-Thread 联合瑞萨推出的高性价比图形评估套件,取代传统的 HMI+主控板硬件,一套硬件即可实现 HMI+IoT+控制的全套能力.依托于瑞萨高性能芯片 RA6M3 ...
- 让Easysearch运行在Kylin V10 (Lance)-aarch64上
简介 本文主要介绍在国产操作系统 Kylin V10 (Lance)-aarch64 上安装单机版 Easysearch/Console/Agent/Gateway/Loadgen 系统配置 在安装之 ...
- 命运2 Cross Save
epic 上免费领的命运2,进不去,界面提示要扫码. 解决方法: 1.手机或电脑浏览器进入:https://www.bungie.net/. 2.使用epic 账号登录 ,然后设置一个邮箱,邮箱收到验 ...
- Redis数据类型有哪些?
a.String(字符串) b.Hash(hash表) c.List(链表) d.Set(集合) e.SortedSet(有序集合zset)
- Javascript高级程序设计第二章 | ch2 | 阅读笔记
HTML中的Javascript <script>元素 值得注意的几个关键字: async:立即开始下载脚本,仅对外部脚本有效.给脚本添加 async 属性的目的是告诉浏览器,不必等脚本下 ...
- 3个月搞定计算机二级C语言!高效刷题系列进行中
前言 大家好,我是梁国庆. 计算机二级应该是每一位大学生的必修课,相信很多同学的大学flag中都会有它的身影. 我在大学里也不止一次的想要考计算机二级office,但由于种种原因,备考了几次都不了了之 ...
- 字符串— trim()、trimStart() 和 trimEnd()
在今天的教程中,我们将一起来学习JavaScript 字符串trim().trimStart() 和 trimEnd(). 01.trim() 学习如何使用 JavaScript trim()方法从 ...
- 3D捕鱼大富翁源码分析
今天接受了一个捕鱼的源码,技术栈采用: 客户端:Unity 服务端:Java 数据库:mysql 缓存:redis 先来几张成品图 编辑编辑 编辑编辑 编辑 在代码中看到有腾讯推广渠道, ...
- HTTP 协议学习:1-HTTP概述
背景 原文:HTTP概述 HTTP是一种能够获取如 HTML 这样的网络资源的 protocol(通讯协议).它是在 Web 上进行数据交换的基础,是一种 client-server 协议,也就是说, ...
- 一文带你深入理解SpringMVC的执行原理
今天大致来看一下Spring MVC的执行流程是什么样的 执行流程:也就是一个请求是怎么到我们Controller的,返回值是怎么给客户端的 本文分析的问题: 文件上传的请求是怎么处理的 跨域是怎么处 ...