Doris(一) -- 简介和安装
Doris 简介
Doris 概述
Apache Doris 由百度大数据部研发 (之前叫百度 Palo,2018 年贡献到 Apache 社区后,更名为 Doris), 在百度内部,有超过 200 个产品线在使用,部署机器超过 1000 台,单一业务最大可达到上百 TB。
Apache Doris 是一个现代化的 MPP(Massively Parallel Processing,即大规模并行处理)分析型(OLAP)数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。
Apache Doris 的分布式架构非常简洁,易于运维,并且可以支持 10PB 以上的超大数据集。
Apache Doris 可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。
OLAP和OLTP
联机事务处理OLTP(On-Line Transaction Processing)
公司业务系统使用数据库的场景,针对业务系统数据库有大量随机的增删改查
要求: 高并发 速度快 支持事务
联机分析处理OLAP(On-Line Analytical Processing)
公司的数据分析使用数据库的场景,对已经生成好的数据进行统计分析
要求:
- 一次操作都是针对的整个数据集
- 只有查这个动作,不会去增删改
- 查询的响应速度相对慢点也能接受
- 并发量要求不是太高
比较
| OLTP | OLAP | |
|---|---|---|
| 数据源 | 仅包含当前运行日常业务数据 | 整合来自多个来源的数据,包括OLTP和外部来源 |
| 目的 | 面向应用,面向业务,支撑事务 | 面向主题,面向分析,支持分析决策 |
| 焦点 | 当下 | 主要面向过去,面向历史(实时数仓除外) |
| 任务 | 增删改查 | 要是用于读,select查询,写操作很少 |
| 响应时间 | 毫秒 | 秒,分钟,小时 取决于数据量和查询的复杂程度 |
| 数据量 | 小数据,MB,GB | 大数据,TP,PB |
使用场景
- 报表分析
- 实时看板 (Dashboards)
- 面向企业内部分析师和管理者的报表
- 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS ,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 亿行数据,查询并发 QPS 上万,99 分位的查询延时 150ms。
- 即席查询(Ad-hoc Query):面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
- 统一数仓构建 :一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由 Spark、Hive、Hbase、Phoenix 组成的旧架构,架构大大简化。
- 数据湖联邦查询:通过外表的方式联邦分析位于 Hive、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升
优势

架构
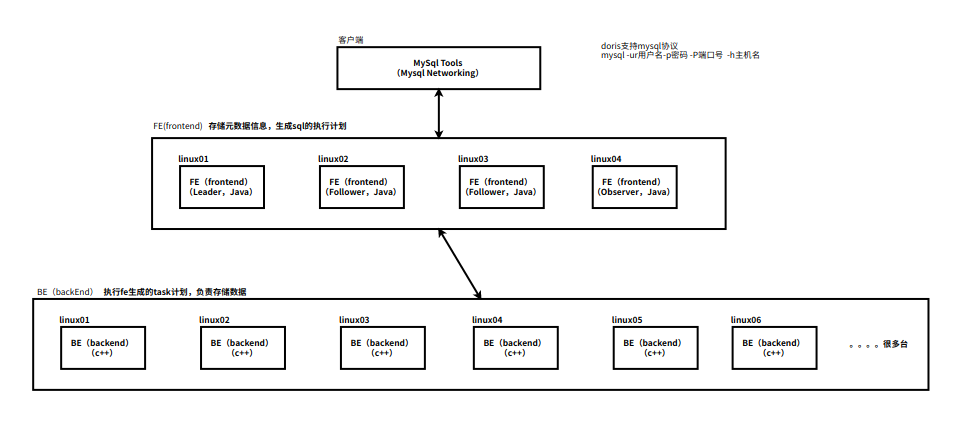
Doris 的架构很简洁,只设 FE(Frontend)前端进程、BE(Backend)后端进程两种角色、两个后台的服务进程,不依赖于外部组件,方便部署和运维,FE、BE 都可在线性扩展。
- FE(Frontend):存储、维护集群元数据;负责接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果。主要有三个角色:
- Leader 和 Follower:主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
- Observer:用来扩展查询节点,同时起到元数据备份的作用。如果在发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取。
- BE(Backend):负责物理数据的存储和计算;依据 FE 生成的物理计划,分布式地执行查询。数据的可靠性由 BE 保证,BE 会对整个数据存储多副本或者是三副本。副本数可根据需求动态调整。
- MySQL Client:Doris 借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC 以及 MySQL 的客户端,都可以直接访问 Doris。
- Broker:一个独立的无状态进程。封装了文件系统接口,提供 Doris 读取远端存储系统中文件的能力,包括 HDFS,S3,BOS 等。
默认端口
| 实例名称 | 端口名称 | 默认端口 | 通讯方向 | 说明 |
|---|---|---|---|---|
| BE | be_port | 9060 | FE-->BE | BE 上 thrift server 的端口,用于接收来自 FE 的请求 |
| BE | webserver_port | 8040 | BE<-->FE | BE 上的 http server 端口 |
| BE | heartbeat_service_port | 9050 | FE-->BE | BE 上心跳服务端口,用于接收来自 FE 的心跳 |
| BE | brpc_prot* | 8060 | FE<-->BE,BE<-->BE | BE 上的 brpc 端口,用于 BE 之间通信 |
| FE | http_port | 8030 | FE<-->FE ,用户<--> FE | FE 上的 http_server 端口 |
| FE | rpc_port | 9020 | BE-->FE ,FE<-->FE | FE 上 thirft server 端口 |
| FE | query_port | 9030 | 用户<--> FE | FE 上的 mysql server 端口 |
| FE | edit_log_port | 9010 | FE<-->FE | FE 上 bdbje 之间通信用的端口 |
| Broker | broker_ipc_port | 8000 | FE-->BROKER,BE-->BROKER | Broker 上的 thrift server,用于接收请求 |
安装
安装前准备
Linux 操作系统版本需求
CentOS 7.1及以上版本
Ubuntu 16.04及以上版本软件需求
java 1.8及以上版本
GCC 4.8.2及以上版本操作系统环境要求
vi /etc/security/limits.conf
# 在文件最后添加下面几行信息(注意* 也要复制进去)
* soft nofile 65535
* hard nofile 65535
* soft nproc 65535
* hard nproc 65535
# ulimit -n 65535 临时生效
# 重启永久生效。
# 如果不修改这个句柄数大于等于60000,启动doris be节点时会报如下错误
File descriptor number is less than 60000. Please use (ulimit -n) to set a value equal or greater than 60000
W1120 18:14:20.934705 3437 storage_engine.cpp:188] check fd number failed, error: Internal error: file descriptors limit is too small
W1120 18:14:20.934713 3437 storage_engine.cpp:102] open engine failed, error: Internal error: file descriptors limit is too small
F1120 18:14:20.935087 3437 doris_main.cpp:404] fail to open StorageEngine, res=file descriptors limit is too small
- 时钟同步
Doris 的元数据要求时间精度要小于5000ms,所以所有集群所有机器要进行时钟同步,避免因为时钟问题引发的元数据不一致导致服务出现异常。
# ntpdate是一个向互联网上的时间服务器进行时间同步的软件
yum install ntpdate -y
# 然后开始三台机器自己同步时间
ntpdate ntp.sjtu.edu.cn
# 美国标准技术院时间服务器:time.nist.gov(192.43.244.18)
# 上海交通大学网络中心NTP服务器地址:ntp.sjtu.edu.cn(202.120.2.101)
# 中国国家授时中心服务器地址:cn.pool.ntp.org(210.72.145.44)
# 将当前时间写入bios,这样才能永久生效不变,不然reboot后还会恢复到原来的时间
clock -w
- 关闭交换分区(swap)
交换分区是linux用来当做虚拟内存用的磁盘分区;
linux可以把一块磁盘分区当做内存来使用(虚拟内存、交换分区);
Linux使用交换分区会给Doris带来很严重的性能问题,建议在安装之前禁用交换分区;
# 临时关闭交换分区
swapoff -a
# 永久删除Swap挂载
vim /etc/fstab
注释 swap 行
- mysql
安装FE
1.官网下载源码包,官网地址:https://doris.apache.org
2.下载后上传到linux并解压
3.修改配置文件
# 去自己的路劲中找到fe.conf文件
vi /opt/apps/doris/fe/conf/fe.conf
#配置文件中指定元数据路径: 注意这个文件夹要自己创建
meta_dir = /opt/data/dorisdata/doris-meta
#修改绑定 ip(每台机器修改成自己的 ip)
priority_networks = 192.168.22.0/24
安装BE
1.官网下载源码包,官网地址:https://doris.apache.org
2.下载后上传到linux并解压
3.修改配置文件
# 去自己的路劲中找到be.conf文件
vi /opt/apps/doris/be/conf/be.conf
#配置文件中指定数据存放路径: 需在启动前创建目录
storage_root_path = /opt/data/doris/be/storage.HDD;/opt/data/doris/be/storage.SSD
#修改绑定 ip(每台机器修改成自己的 ip)
priority_networks = 192.168.17.0/24
分发集群
for i in 2 3
do
scp /et/profile linux0$i:/etc/profile
scp -r /opt/apps/doris/ linux0$i:/opt/apps/
done
Mysql CLient连接FE
# 进入到fe的bin目录下执行
./start_fe.sh --daemon
mysql -h linux01 -P 9030 -uroot
# 设置密码
SET PASSWORD FOR 'root' = PASSWORD('123');
# 查看fe的运行状态
SHOW PROC '/frontends'\G;
# 添加BE节点
ALTER SYSTEM ADD BACKEND "linux01:9050";
ALTER SYSTEM ADD BACKEND " linux02:9050";
ALTER SYSTEM ADD BACKEND " linux03:9050";
# 查看BE状态
SHOW PROC '/backends';
# 添加环境变量
vi /etc/profile
#doris_fe
export DORIS_FE_HOME=/opt/app/doris1.1.4/fe
export PATH=$PATH:$DORIS_FE_HOME/bin
#doris_be
export DORIS_BE_HOME=/opt/app/doris1.1.4/be
export PATH=$PATH:$DORIS_BE_HOME/bin
source /etc/profile
# 启动 BE(每个节点)
start_be.sh --daemon
# 启动后再次查看BE的节点
SHOW PROC '/backends';
# Alive 为 true 表示该 BE 节点存活
部署FS_Broker
Broker 以插件的形式,独立于 Doris 部署。如果需要从第三方存储系统导入数据,需要部署相应的 Broker,默认提供了读取 HDFS、百度云 BOS 及 Amazon S3 的 fs_broker。fs_broker 是无状态的,建议每一个 FE 和 BE 节点都部署一个 Broker。
# 启动 Broker
/opt/apps/doris/fe/apache_hdfs_broker/bin/start_broker.sh --daemon
# 使用 mysql-client 连接启动的 FE,执行以下命令:
mysql -h linux01 -P 9030 -uroot -p 123
ALTER SYSTEM ADD BROKER broker_name "linux01:8000","linux02:8000","linux03:8000";
# broker_name 这只是一个名字,可以自己取
# 查看 Broker 状态
# 使用 mysql-client 连接任一已启动的 FE,执行以下命令查看 Broker 状态:
SHOW PROC "/brokers";
扩容和缩容
FE 扩容和缩容
可以通过将 FE 扩容至 3 个以上节点来实现 FE 的高可用。
使用 MySQL 登录客户端后,可以使用 sql 命令 SHOW PROC '/frontends'\G; 查看 FE 状态,目前就一台 FE
FE 分为 Leader,Follower 和 Observer 三种角色。 默认一个集群,只能有一个 Leader,可以有多个 Follower 和 Observer。其中 Leader 和 Follower 组成一个 Paxos 选择组,如果Leader 宕机,则剩下的 Follower 会自动选出新的 Leader,保证写入高可用。Observer 同步 Leader 的数据,但是不参加选举。
如果只部署一个 FE,则 FE 默认就是 Leader。在此基础上,可以添加若干 Follower 和 Observer。
-- 添加FE的新节点
ALTER SYSTEM ADD FOLLOWER "linux02:9010";
ALTER SYSTEM ADD OBSERVER "linux03:9010";
在linux01和linux02分别启动FE
# 第一次添加,一定要加这两个参数 --helper linux01:9010
/opt/apps/doris/fe/bin/start_fe.sh --helper linux01:9010 --daemon
此时,再在linux01的mysql客户端中使用 SHOW PROC '/frontends'\G; 命令查看FE的状态
删除FE节点命令
-- 删除 Follower FE 时,确保最终剩余的 Follower(包括 Leader)节点最好为奇数。
ALTER SYSTEM DROP FOLLOWER[OBSERVER] "fe_host:edit_log_port";
ALTER SYSTEM DROP FOLLOWER "linux03:9010";
BE 扩容和缩容
增加 BE 节点
-- 在 MySQL 客户端,通过 ALTER SYSTEM ADD BACKEND 命令增加 BE 节点。
ALTER SYSTEM ADD BACKEND "linux01:9050";
-- DROP 方式删除 BE 节点(不推荐)
ALTER SYSTEM DROP BACKEND "be_host:be_heartbeat_service_port";
ALTER SYSTEM DROP BACKEND "linux03:9050";
-- 注意:DROP BACKEND 会直接删除该 BE,并且其上的数据将不能再恢复!!!所以我们强烈不推荐使用 DROP BACKEND 这种方式删除 BE 节点。当你使用这个语句时,会有对应的防误操作提示。
-- DECOMMISSION 方式删除 BE 节点(推荐)
ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";
ALTER SYSTEM DECOMMISSION BACKEND "linux03:9050";
-- 1.该命令用于安全删除 BE 节点。命令下发后,Doris 会尝试将该 BE 上的数据向其 他 BE 节点迁移,当所有数据都迁移完成后,Doris 会自动删除该节点。
-- 2.该命令是一个异步操作。执行后,可以通过 SHOW PROC '/backends'; 看到该 BE节点的 isDecommission 状态为 true。表示该节点正在进行下线。
-- 3.该命令不一定执行成功。比如剩余 BE 存储空间不足以容纳下线 BE 上的数据,或者剩余机器数量不满足最小副本数时,该命令都无法完成,并且 BE 会一直处于isDecommission 为 true 的状态。
-- 4.DECOMMISSION 的进度,可以通过 SHOW PROC '/backends'; 中的 TabletNum 查看,如果正在进行,TabletNum 将不断减少。
-- 5.该操作可以通过如下命令取消:CANCEL DECOMMISSION BACKEND "be_host:be_heartbeat_service_port"; 取消0后,该 BE 上的数据将维持当前剩余的数据量。后续 Doris 重新进行负载均衡。
Broker 扩容缩容
-- Broker 实例的数量没有硬性要求。通常每台物理机部署一个即可。Broker 的添加和删除可以通过以下命令完成:
ALTER SYSTEM ADD BROKER broker_name "broker_host:broker_ipc_port";
ALTER SYSTEM DROP BROKER broker_name "broker_host:broker_ipc_port";
ALTER SYSTEM DROP ALL BROKER broker_name;
-- Broker 是无状态的进程,可以随意启停。当然,停止后,正在其上运行的作业会失败,重试即可。
Doris(一) -- 简介和安装的更多相关文章
- Node.js 教程 01 - 简介、安装及配置
系列目录: Node.js 教程 01 - 简介.安装及配置 Node.js 教程 02 - 经典的Hello World Node.js 教程 03 - 创建HTTP服务器 Node.js 教程 0 ...
- Java Gradle入门指南之简介、安装与任务管理
这是一篇Java Gradle入门级的随笔,主要介绍Gradle的安装与基本语法,这些内容是理解和创建build.gradle的基础,关于Gradle各种插件的使用将会在其他随笔中介绍. ...
- 细细品味Storm_Storm简介及安装
Storm是由专业数据分析公司BackType开发的一个分布式实时数据处理软件,可以简单.高效.可靠地处理大量的数据流.Twitter在2011年7月收购该公司,并于2011年9月底正式将Storm项 ...
- VMware vSphere 5.1 简介与安装
虚拟化系列-VMware vSphere 5.1 简介与安装 标签: 虚拟化 esxi5.1 VMware vSphere 5.1 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 . ...
- Nutch搜索引擎(第2期)_ Solr简介及安装
1.Solr简介 Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器.同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置.可扩展并对查询性能进行了优化 ...
- Node.js的简介和安装
一.Node.js的简介和安装 a) 什么是Node.js? Node.js是一个开发平台 让JavaScript运行在服务器端的开发平台 ---简单点说就是用JavaScript写服务器 ...
- Nutch之简介与安装
初学Nutch之简介与安装 初学Nutch之简介与安装 1.Nutch简介 Nutch是一个由Java实 现的,开放源代码(open-source)的web搜索引擎.主要用于收集网页数据,然后对其 ...
- Nutch搜索引擎Solr简介及安装
Nutch搜索引擎(第2期)_ Solr简介及安装 1.Solr简介 Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器.同时对其进行了扩展,提供了比Lucene更为丰富的 ...
- DNN简介以及安装
开源框架DNN简介以及安装 donetnuke 是一款免费的开源cms框架,目前也有收费版,不过免费版也可以适应大家大部分的需求.我前些阵子是老板让我在20天内,做好一个官网并且发布,并且指定使用dn ...
- Grant简介以及安装
Grant简介以及安装 1. 安装Grunt-cli需要使用npm,全局安装 命令:npm install –g grunt-cli(可能会涉及权限问题) 注意,安装grunt-cli并不等于安 ...
随机推荐
- 11.4 显示窗口(harib08d)11.5 小实验(hearib08e) 11.6 高速计数器(harib08f)
11.4 显示窗口(harib08d) 书P206 11.5 小实验(hearib08e) 书P208 11.6 高速计数器(harib08f) 书P209
- 马志强:语音识别技术研究进展和应用落地分享丨RTC Dev Meetup
本文内容源自「RTC Dev Meetup 丨语音处理在实时互动领域的技术实践和应用]的演讲分享,分享讲师为寰语科技语音识别研究主管马志强. 01 语音识别技术现状 1.语音成为万物互联时代人机交互关 ...
- IntelliJ IDEA 下载安装及配置使用教程(图文步骤详解)
前言 壹哥在前面的文章中,带大家下载.安装.配置了Eclipse这个更好用的IDE开发工具,并教会了大家如何在Eclipse中进行项目的创建和代码编写.运行.但是实际上,在各种IDE开发工具中,Ecl ...
- Java面试——Spring Boot
更多内容,移步IT-BLOG 一.谈谈你对 SpringBoot 的理解 简单说说我的理解:Java是一个静态语言,相比动态语言,它相对笨重,体现在我们搭建 SSM 框架写一个 Helloword 的 ...
- Spring 的核心组件详解
Spring 总共有十几个组件,但是真正核心的组件只有三个:Core.Context 和 Bean.它们构建起了整个 Spring的骨骼架构,没有它们就不可能有 AOP.Web 等上层的特性功能. 一 ...
- MyBatis 版本升级引发的线上问题
MyBatis上线前后的版本:上线前(3.2.3)上线后(3.4.6) 服务上线后,开始陆续出现了一些更新系统交互日志方面的报警,这属于系统的辅助流程,报警如下代码所示.我们发现都是跟 MyBatis ...
- 算法学习笔记(20): AC自动机
AC自动机 前置知识: 字典树:可以参考我的另一篇文章 算法学习笔记(15): Trie(字典树) KMP:可以参考 KMP - Ricky2007,但是不理解KMP算法并不会对这个算法的理解产生影响 ...
- 集合-HashMap 源码详细分析(JDK1.8)
1. 概述 本篇文章我们来聊聊大家日常开发中常用的一个集合类 - HashMap.HashMap 最早出现在 JDK 1.2中,底层基于散列算法实现.HashMap 允许 null 键和 null 值 ...
- [Linux]常用命令之【source|export/env】#点命令/环境变量#
1 source 1-1 source 命令概述 source命令用法:source FileName 简述 source命令(从 C Shell 而来)是bash shell的内置命令. sourc ...
- telnet命令安装
1.[root@pld3bomdb01 ~]# yum install telnet-server 2.[root@pld3bomdb01 ~]# rpm -qa telnet* telnet-ser ...