用 C 语言开发一门编程语言 — 语法解析器
目录
前文列表
《用 C 语言开发一门编程语言 — 交互式解释器l》
《用 C 语言开发一门编程语言 — 跨平台的可移植性》
编程语言的本质
在 19 世纪 50 年代,语言学家 Noam Chomsky 定义了一系列关于语言的重要理论。这些理论支撑了我们今天对于语言结构的基本理解。其中重要的一条结论就是:自然语言都是建立在递归和重复的子结构之上的。Chomsky 提出的理论是非常重要的。它意味着,虽然一门语言可以表达无限的内容,我们仍然可以使用有限的规则去解析所有用该门语言写就的东西。这些有限的规则就叫语法(grammar)。
当我们学习一门自然语言的时候,我们往往从语法开始。当我们学习一门编程语言的时候也一样,当我们尝试开发一门编程语言的时候亦如此,首先要考虑的就是语言的语法、及其语义。
词法分析
大多数编程语言开发的第一步是词法分析或分词。通常使用 “Lex” 或 “Tokenizer” 来进行描述,表示将一大堆文本分解成多个符号。

词法分析器将包含源码的文件作为输入字符串,输出包含标记符号的列表。那么,在编译的后半阶段将不再参考这些字符串源代码,所以词法分析器必须产生所有后面各阶段需要的信息。之所以会有这样相对严格的格式设计,是因为这个阶段词法分析器可以做一些工作,比如移除注释或检测标识符或数字等。如果你将这些逻辑规则放在词法分析器里,那么在构造语言的其它部分时就不必再考虑这些规则了,而且你可以方便地在同一个地方集中修改这些语法规则。
语法分析
编译的第二阶段就是语法分析。语法分析器把标识符列表解析为一个带结点的树。用于存储这种数据的树称为 AST(抽象语法树)。

为了定义一门编程语言的语法,首先需要能够正确解析用户按照语法规则编写的程序。为此,需要编程语言程序就需要一个语法解析器,用来判断用户的输入是否合法,并产生解析后的内部表示。内部表示是一种计算机更容易理解的表示形式,有了它,我们后面的解析、求值等工作会变得更加的简单可行。
使用 MPC 解析器组合库
MPC(Micro Parser Combinators)是一个用于 C 的轻量且强大的解析器组合库。你可以使用这个库为任何语言编写语法解析器。编写语法解析器的方法有很多,使用解析器组合库的好处就在于,它极大地简化了原本枯燥无聊的工作,你只需要关注编写高层的抽象语法规则就可以了。
注:MPC 的开发者就是《Build Your Own Lisp》的原作者。
MPC 可用于:
- 解析现有的,或开发新的编程语言
- 解析现有的,或开发新的数据格式
MPC 的特性:
- 正则表达式分析器生成器
- 语法分析器生成器
- 易于集成到 C 语言项目(以一个源文件的形式存在)
- 自动生成错误消息
- Type-Generic(泛式类型)
- Predictive, Recursive Descent
安装
在我们正式编写这个语法解析器之前,首先需要安装 MPC 库。MPC 库的安装非常简单,只需要将源码下载,把源文件 Copy 到我们的 C 语言项目中,然后在项目中包含 mpc 的头文件并链接 MPC 库即可。
下载:
$ git clone https://github.com/orangeduck/mpc.git
Copy:
$ ll
总用量 140
-rw-r--r-- 1 root root 111731 4月 7 18:12 mpc.c
-rw-r--r-- 1 root root 11194 4月 7 18:12 mpc.h
-rwxr-xr-x 1 root root 8632 4月 7 18:08 parsing
-rw-r--r-- 1 root root 1203 4月 7 18:11 parsing.c
引入到 parsing.c:
#include "mpc.h"
编译:
gcc -std=c99 -Wall parsing.c mpc.c -lreadline -lm -o parsing
- -lm:链接数学库。
快速入门
下面我们以编写一个 Doge(the language of Shiba Inu,柴犬语)语言的语法解析器为例,来快速熟悉 MPC 的用法。

首先解构一下 Doge 语言的语法结构:
- Adjective(形容词):wow、many、so、such。
- Noun(名词):lisp、language、c、book、build。
- Phrase(短语):由 Adjective + Noun 组成。
- Doge(柴犬语):由若干个 Phrase 组成。
再来解释一下 Doge 语言的语法描述:
- Phrase 由 Adjective 和 Noun 组成。
- Doge 由任意个 Phrase 组成。
最后,我们就可以尝试使用 MPC 来定义 Doge 语言的语法解析器了:
- Step 1. 使用 MPC 定义 Adjective 和 Noun,为此我们创建两个解析器。其中,mpc_or 函数会返回一个解析器,该解析器表示 “取其一”,因为我们需要从 Adjective 和 Noun 中 “各取其一” 来组成 Phrase,所以分别定义了两个解析器。
/* Build a parser 'Adjective' to recognize descriptions */
mpc_parser_t *Adjective = mpc_or(4,
mpc_sym("wow"), mpc_sym("many"),
mpc_sym("so"), mpc_sym("such")
);
/* Build a parser 'Noun' to recognize things */
mpc_parser_t *Noun = mpc_or(5,
mpc_sym("lisp"), mpc_sym("language"),
mpc_sym("book"),mpc_sym("build"),
mpc_sym("c")
);
- Step 2. 使用已经定义好的 Adjective 、 Noun 解析器来定义 Phrase 解析器。mpc_and 函数会返回一个解析器,该解析器只接受各 “子句” 按照顺序出现的语句。所以我们将先前定义的 Adjective 和 Noun 传递给它,表示:形容词后面紧跟着名词组成的短语。mpcf_strfold 和 free 指定了各个语句的组织(Fold)及删除(Free)方式。在 mpcf_strfold 和 free 函数的帮助下,我们不用担心什么时候加入和丢弃输入,它们将自动帮助我们完成。
mpc_parser_t *Phrase = mpc_and(2, mpcf_strfold, Adjective, Noun, free);
- Step 3. 使用 Phrase 解析器来最终定义 Doge 语言的解析器,Doge 是由若干个 Phrase 组成的,mpc_many 函数表达的正是这种逻辑关系。
mpc_parser_t *Doge = mpc_many(mpcf_strfold, Phrase);
上述语句表明 Doge 可以接受任意多条语句。这也意味着 Doge 语言是无穷的。下面列出了一些符合 Doge 语法的例子:
/* 一条 Doge 语句由若干个 Phrase 组成,一个 Phrase 由一个 Adjective + 一个 Noun 构成。 */
"wow book such language many lisp"
"so c such build such language"
"many build wow c"
""
"wow lisp wow c many language"
"so c"
通过上述步骤,我们简单的定义了一门 Doge 语言的描述自己实现了一门 Doge 语言的语法解析器。还可以继续使用 mpc 提供的其他函数,一步一步地编写能解析更加复杂的语法的解析器。
但是很显然的,上述的代码实现方式并不友好,随着语法的复杂度的增加,代码的可读性也会越来越差。所以 mpc 还提供了一系列的函数来帮助用户更加简单地完成常见的任务,使用这些函数能够更好更快地构建复杂语言的解析器,并能够提供更加精细地控制。具体的文档说明可以参见项目主页*(https://github.com/orangeduck/mpc)*。
下面,我们使用 MPC 提供的另一种更加简易的代码实现方式来编写 Doge 语法解析器:将整个语言的语法规则写在一个长字符串中,而不是使用啰嗦难懂的 C 语句。我们也不再需要关心如何使用 mpcf_strfold 或是 free 参数组织或删除各个语句。所有的这些工作都是都是自动完成的。
mpc_parser_t* Adjective = mpc_new("adjective");
mpc_parser_t* Noun = mpc_new("noun");
mpc_parser_t* Phrase = mpc_new("phrase");
mpc_parser_t* Doge = mpc_new("doge");
mpca_lang(MPCA_LANG_DEFAULT,
" \
adjective : \"wow\" | \"many\" \
| \"so\" | \"such\"; \
noun : \"lisp\" | \"language\" \
| \"book\" | \"build\" | \"c\"; \
phrase : <adjective> <noun>; \
doge : <phrase>*; \
",
Adjective, Noun, Phrase, Doge);
/* Do some parsing here... */
mpc_cleanup(4, Adjective, Noun, Phrase, Doge);
- 使用 mpc_new 函数定义解析器的名字。
- 使用 mpca_lang 函数定义这些解析器的内涵和解析器之间的逻辑关系,从而最终构成一门语言的语法规则。
mpca_lang 函数的第一个参数是操作标记,在这里我们使用默认选项 MPCA_LANG_DEFAULT。第二个参数是 C 语言的一个长字符串。这个字符串中定义了具体的语法规则。每个规则分为两部分,用冒号 : 隔开,使用 ; 表示规则结束:
- 冒号左边是语法规则的名字,e.g. adjective、noun、phrase、doge。
- 右边是语法规则的定义,e.g. adjective:wow、many、so、such。
mpca_lang 函数就是对 mpc_many、mpc_and 、 mpc_or 这些函数的封装,自动地完成这些函数的工作,让解析器定义的代码变得干净利落,不拖泥带水。
定义语法规则的一些特殊符号的作用如下:
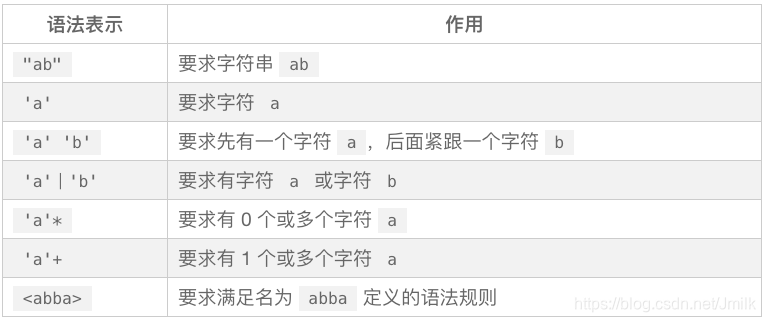
实现波兰表达式的语法解析
波兰表达式
就如我们常见的算数表达式 1+1 = 2。波兰表达式也是一种数学标记语言,它的特点是运算符会在操作数的前面。我们考虑将波兰表达式作为 Lisp 编程语言的数学运算部分。

在编写这种数据标记语言的语法规则之前,我们还是先对其进行语法解构以及语法描述:我们观察到,波兰表达式总是以操作符开头,后面跟着操作数或其他包裹在圆括号中的表达式。也就是说,波兰表达式是由:程序(Program)是由一个操作符(Operator)加上一个或多个表达式(Expression)组成的。而每个表达式又可以是一个数字或者是包裹在圆括号中的一个操作符加上一个或多个表达式。
所以我们对波兰表达式进行了如下解构和描述:

正则表达式
有了语法规则的描述之后,我们还需要对针对语法的输入进行约束(e.g. 如何表达开始和结束输入、如何规定可选字符和字符范围等),因为一个任意的输入中,很可能包含了一些解析器还没定义清楚的结构。我们考虑使用正则表达式(Regular Expression)来实现这一目的。
正则表达式适合定义一些小型的语法规则,例如单词或是数字等。正则表达式不支持复杂的规则,但它清晰且精确地界定了输入是否符合规则。在 mpc 中,我们需要将正则表达式包裹在一对 / 中。例如,Number 可以用 /-?[0-9]+/ 来表示。

代码实现
根据上面的分析,我们可以定义波兰表达式最终的语法规则:
#include <stdio.h>
#include <stdlib.h>
#include "mpc.h"
#ifdef _WIN32
#include <string.h>
static char buffer[2048];
char *readline(char *prompt) {
fputs(prompt, stdout);
fgets(buffer, 2048, stdin);
char *cpy = malloc(strlen(buffer) + 1);
strcpy(cpy, buffer);
cpy[strlen(cpy) - 1] = '\0';
return cpy;
}
void add_history(char *unused) {}
#else
#ifdef __linux__
#include <readline/readline.h>
#include <readline/history.h>
#endif
#ifdef __MACH__
#include <readline/readline.h>
#endif
#endif
int main(int argc, char *argv[]) {
/* Create Some Parsers */
mpc_parser_t *Number = mpc_new("number");
mpc_parser_t *Operator = mpc_new("operator");
mpc_parser_t *Expr = mpc_new("expr");
mpc_parser_t *Lispy = mpc_new("lispy");
/* Define them with the following Language */
mpca_lang(MPCA_LANG_DEFAULT,
" \
number : /-?[0-9]+/ ; \
operator : '+' | '-' | '*' | '/' ; \
expr : <number> | '(' <operator> <expr>+ ')' ; \
lispy : /^/ <operator> <expr>+ /$/ ; \
",
Number, Operator, Expr, Lispy);
puts("Lispy Version 0.1");
puts("Press Ctrl+c to Exit\n");
while(1) {
char *input = NULL;
input = readline("lispy> ");
add_history(input);
/* Attempt to parse the user input.
* 解析用户的每一条输入。
* 调用了 mpc_parse 函数,并将 Lispy 解析器和用户输入 input 作为参数。
* 它将解析的结果保存到 &r 中,如果解析成功,函数返回值为 1,失败为 0。
*/
mpc_result_t r;
if (mpc_parse("<stdin>", input, Lispy, &r)) {
/* On success print and delete the AST.
* 解析成功时会产生一个内部结构,并保存到 r 的 output 字段中。
* 我们可以使用 mpc_ast_print 将这个结构打印出来,使用 mpc_ast_delete 将其删除。
*/
mpc_ast_print(r.output);
mpc_ast_delete(r.output);
} else {
/* Otherwise print and delete the Error.
* 解析失败时则会将错误信息保存在 r 的 error 字段中。
* 我们可以使用 mpc_err_print 将这个结构打印出来,使用 mpc_err_delete 将其删除。
*/
mpc_err_print(r.error);
mpc_err_delete(r.error);
}
free(input);
}
/* Undefine and delete our parsers */
mpc_cleanup(4, Number, Operator, Expr, Lispy);
return 0;
}
编译:
gcc -std=c99 -Wall parsing.c mpc.c -lreadline -lm -o parsing
运行,尝试解析一条波兰表达式 + 5 (* 2 2)。
$ ./parsing
Lispy Version 0.1
Press Ctrl+c to Exit
lispy> + 5 (* 2 2)
>
regex
operator|char:1:1 '+'
expr|number|regex:1:3 '5'
expr|>
char:1:5 '('
operator|char:1:6 '*'
expr|number|regex:1:8 '2'
expr|number|regex:1:10 '2'
char:1:11 ')'
regex
lispy> hello
<stdin>:1:1: error: expected '+', '-', '*' or '/' at 'h'
lispy> / 1dog
<stdin>:1:4: error: expected one of '0123456789', '-', one or more of one of '0123456789', '(', newline or end of input at 'd'
lispy>
<stdin>:1:1: error: expected '+', '-', '*' or '/' at end of input
lispy> ^C
可以看见,上述的正常输出就是一个 AST(Abstract Syntax Tree,抽象语法树),它用来表示用户输入的表达式的结构。操作数(Number)和操作符(Operator)等需要被处理的实际数据都位于叶子节点上。而非叶子节点上则包含了遍历和求值的信息。
用 C 语言开发一门编程语言 — 语法解析器的更多相关文章
- Anrlr4 生成C++版本的语法解析器
一. 写在前面 我最早是在2005年,首次在实际开发中实现语法解析器,当时调研了Yacc&Lex,觉得风格不是太好,关键当时yacc对多线程也支持的不太好,接着就又学习了Bison&F ...
- 在.NET Core中使用Irony实现自己的查询语言语法解析器
在之前<在ASP.NET Core中使用Apworks快速开发数据服务>一文的评论部分,.NET大神张善友为我提了个建议,可以使用Compile As a Service的Roslyn为语 ...
- Boost学习之语法解析器--Spirit
Boost.Spirit能使我们轻松地编写出一个简单脚本的语法解析器,它巧妙利用了元编程并重载了大量的C++操作符使得我们能够在C++里直接使用类似EBNF的语法构造出一个完整的语法解析器(同时也把C ...
- 使用 java 实现一个简单的 markdown 语法解析器
1. 什么是 markdown Markdown 是一种轻量级的「标记语言」,它的优点很多,目前也被越来越多的写作爱好者,撰稿者广泛使用.看到这里请不要被「标记」.「语言」所迷惑,Markdown 的 ...
- C# 语言的两个html解析器
基于C# 语言的两个html解析器 基于C# 语言的两个html解析器 1)Html Agility Pack http://nsoup.codeplex.com/ 代码段示例: HtmlDocu ...
- 基于C# 语言的两个html解析器
基于C# 语言的两个html解析器 1)Html Agility Pack http://nsoup.codeplex.com/ 代码段示例: HtmlDocument doc = new HtmlD ...
- 用java实现编译器-算术表达式及其语法解析器的实现
大家在参考本节时,请先阅读以下博文,进行预热: http://blog.csdn.net/tyler_download/article/details/50708807 本节代码下载地址: http: ...
- 手写token解析器、语法解析器、LLVM IR生成器(GO语言)
最近开始尝试用go写点东西,正好在看LLVM的资料,就写了点相关的内容 - 前端解析器+中间代码生成(本地代码的汇编.执行则靠LLVM工具链完成) https://github.com/daibinh ...
- 邵国际: C 语言对象化设计实例 —— 命令解析器
本文系转载,著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 作者: 邵国际 来源: 微信公众号linux阅码场(id: linuxdev) 内容简介 单片机工程师常常疑惑为什么 ...
- 语法解析器续:case..when..语法解析计算
之前写过一篇博客,是关于如何解析类似sql之类的解析器实现参考:https://www.cnblogs.com/yougewe/p/13774289.html 之前的解析器,更多的是是做语言的翻译转换 ...
随机推荐
- #模拟#洛谷 5957 [POI2017]Flappy Bird
题目 分析 小鸟所在坐标的奇偶性一定相同, 考虑每次维护一个可行区间表示小鸟在当前列可以进入的纵坐标区间, 那么它有\(x_i-x_{i-1}\)的纵坐标最大改变差,然后根据奇偶性以及限制区间缩小范围 ...
- OpenHarmony 分布式硬件关键技术
本文转载自 OpenHarmony TSC 官方微信公众号<峰会回顾第8期 | OpenHarmony 分布式硬件关键技术> 演讲嘉宾 | 李 刚 回顾整理 | 廖 涛 排版校对 ...
- 记一次 .NET某管理局检测系统 内存暴涨分析
一:背景 1. 讲故事 前些天有位朋友微信找到我,说他们的WPF程序有内存泄漏的情况,让我帮忙看下怎么回事?并且dump也抓到了,网上关于程序内存泄漏,内存暴涨的文章不计其数,看样子这个dump不是很 ...
- Java break、continue 详解与数组深入解析:单维数组和多维数组详细教程
Java Break 和 Continue Java Break: break 语句用于跳出循环或 switch 语句. 在循环中使用 break 语句可以立即终止循环,并继续执行循环后面的代码. 在 ...
- Numpy随机数组(random)
numpy.random()模块补充了Python内置random模块的一些功能,用于高效/高速生成一些概率分布的样本数组数据. In [1]: import numpy as np In [2]: ...
- openGauss2.1.0在openEuler 20.03 LTS SP2 安装后,yum无法使用的问题解决
openGauss2.1.0 在 openEuler 20.03 LTS SP2 安装后,yum 无法使用的问题解决 一.环境描述 操作系统: openEuler 20.03 LTS openEule ...
- mmdetection训练voc数据集
首先需要准备好数据集,这里有xml标签数据转voc数据集格式的说明以及免费分享的数据集:xml转voc数据集 - 一届书生 - 博客园 (cnblogs.com) 1. 准备工作目录 我们的工作目录, ...
- setTimeout(fn, 0) // it works - JavaScript 事件循环 动画演示
在前端代码中很经常看到使用 setTimeout(fn, 0),如下面代码所示,乍一看很多余,但是移除了可能会出现一些奇奇怪怪的问题.要解释这个就需要理解 事件循环(Event Loop),下面会通过 ...
- 华为云CodeArts IDE For Python 快速使用指南
本文分享自华为云社区<华为云CodeArts IDE For Python 快速使用指南>,作者:为云PaaS服务小智. CodeArts IDE 带有 Python 扩展,为 Pytho ...
- 第 7章 Python 爬虫框架 Scrapy(上)
第 7章 Python 爬虫框架 Scrapy(上) 编写爬虫可以看成行军打仗,基本的角色有两个:士兵和将军,士兵冲锋陷阵,而将军更多地是调兵遣将.框架就像一个将军,里面包含了爬虫的全部流程.异常处理 ...