双引擎驱动Quick BI十亿数据0.3秒分析,首屏展示时间缩短30%
简介:在规划中,Quick BI制定了产品竞争力建设的三大方向,包括Quick(快)能力、移动端能力和集成能力。针对其中的产品“报表查看打开慢”“报表开发数据同步慢”等性问题开展专项战役——Quick战役,以实现展现快、计算快,为使用者提供顺滑体验为目标。
“Quick”是产品始终追求的目标
Quick BI数据可视化分析平台,在2021年二次入选了Gartner ABI魔力象限,这是对产品本身能力强有力的认证。在不断夯实B I的可视化体验和权限管控能力之外,推进Quick BI的全场景数据消费能力,让数据在企业内最大限度的流转起来。
在规划中,Quick BI制定了产品竞争力建设的三大方向,包括Quick(快)能力、移动端能力和集成能力。针对其中的产品“报表查看打开慢”“报表开发数据同步慢”等性问题开展专项战役——Quick战役,以实现展现快、计算快,为使用者提供顺滑体验为目标。
双引擎成就Quick全新体验
无论是开发者还是阅览者,若想要在使用Quick BI的过程中获得流畅快速的体验,可能在这两个方面进行优化:
在数据报表开发的过程中,大量级数据需要在一定范围的时间内响应,即计算要快;
面对报表的查看者,首屏打开和下拉加载的时间需要在一定范围内完成,即展现要快。
Quick BI推出计算引擎和渲染引擎,以双引擎的方式为产品全力加速。
1、计算引擎(Quick引擎)
包含原有直连模式,新增加速模式、抽取模式、智能缓存模式,用户按照不同场景的不同需求,通过配置开关进行模式的选择。在数据集开发和数据作品制作的过程中获得加速体验,可以有效提升用户报表的数据查询速度,减少用户的数据库查询压力。
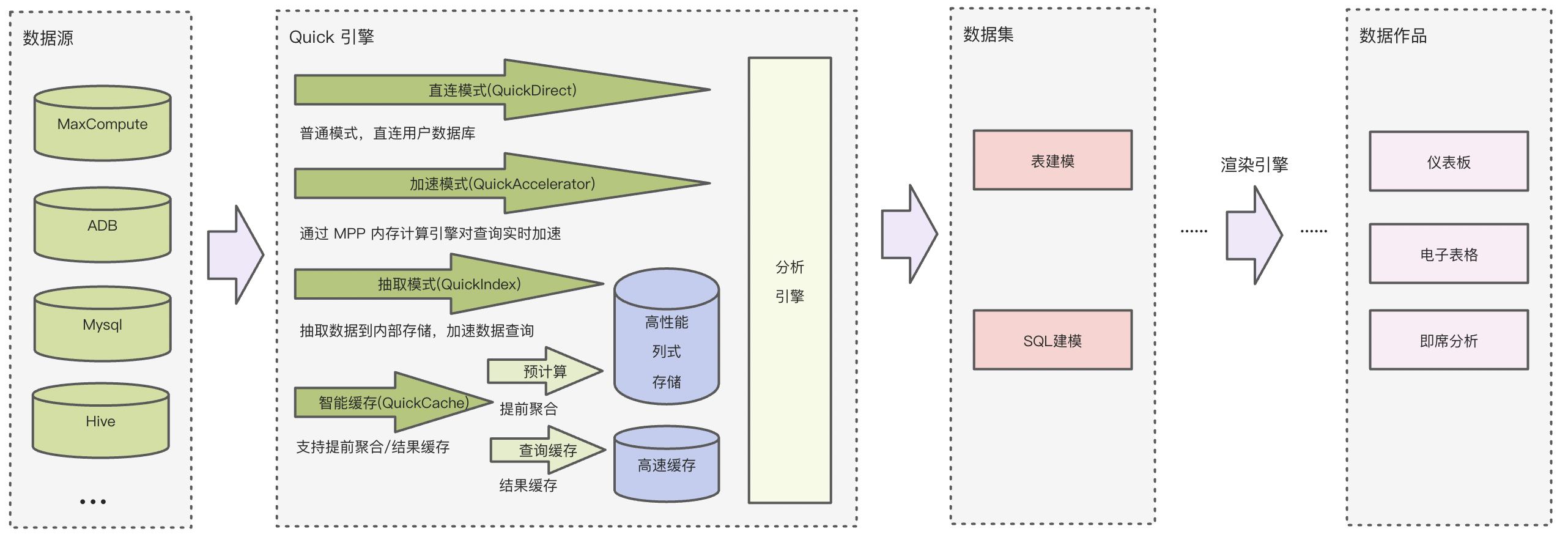

实时加速
基于 MPP 内存计算引擎,查询中实时从数据库(调/读)取数据,并在计算引擎的内存中进行计算,有效提升用户数据计算的性能,适用于对数据时效有高要求的情况。
抽取模式
把数据库或数仓的数据抽取到Quick引擎的高性能列式存储引擎中,支持全量模式和增量模式,分析计算负载直接在Quick BI引擎中进行,充分利用Quick引擎性能的同时,降低用户数仓的负担,适用于没有独立数仓或数仓负载过重的情况。
智能缓存
提供的2种缓存模式都可以直接返回结果,提升用户查询速度,减少数据库访问次数。
数据集缓存
将用户已经查询过的结果缓存在 Quick BI 高速缓存组件内,一段时间内完全一致的查询可以直接返回查询结果。
智能预计算
算法根据用户的历史查询记录,对数据集的查询进行预聚合,提前计算出用户所需的结果,保存在高性能存储中。一旦用户查询命中,则直接返回结果。
2、渲染引擎
负责取得肉眼可见页面的内容,包括图像、图表等,并进行数据信息整理,以及计算网页的显示方式,然后输出并展现。由于BI场景的报表(仪表板、电子表格、门户等)内容相当复杂,渲染引擎的加速可以非常直接的影响Quick BI报表的打开速度,优化用户的报表阅览体验。渲染引擎的加速动作无需进行任何配置,无声地服务整个分析流程。
渲染引擎进行了如下整体升级:
- 资源(js/css/ajax等)加载优化:包括预加载、按需加载、任务调度、TreeShaking等
- 前端计算&执行优化:数据流节流、懒数据策略、mutable改造、深克隆等计算优化等
- 可视化升级:底层可视化统一,桑基图等大数据量下解析优化、渲染次数收敛等
- 移动端升级:包体积优化(压缩前20.6M减少至5.6M)、图表预加载、资源本地化缓存等
- 查询链路优化:支持 MaxCompute 加速查询、登录层优化、防止配置查询缓存穿透、缓存优化等
- 性能工具升级:SQL诊断支持 MaxCompute 数据源,并支持 SQL 诊断工具的国际化等
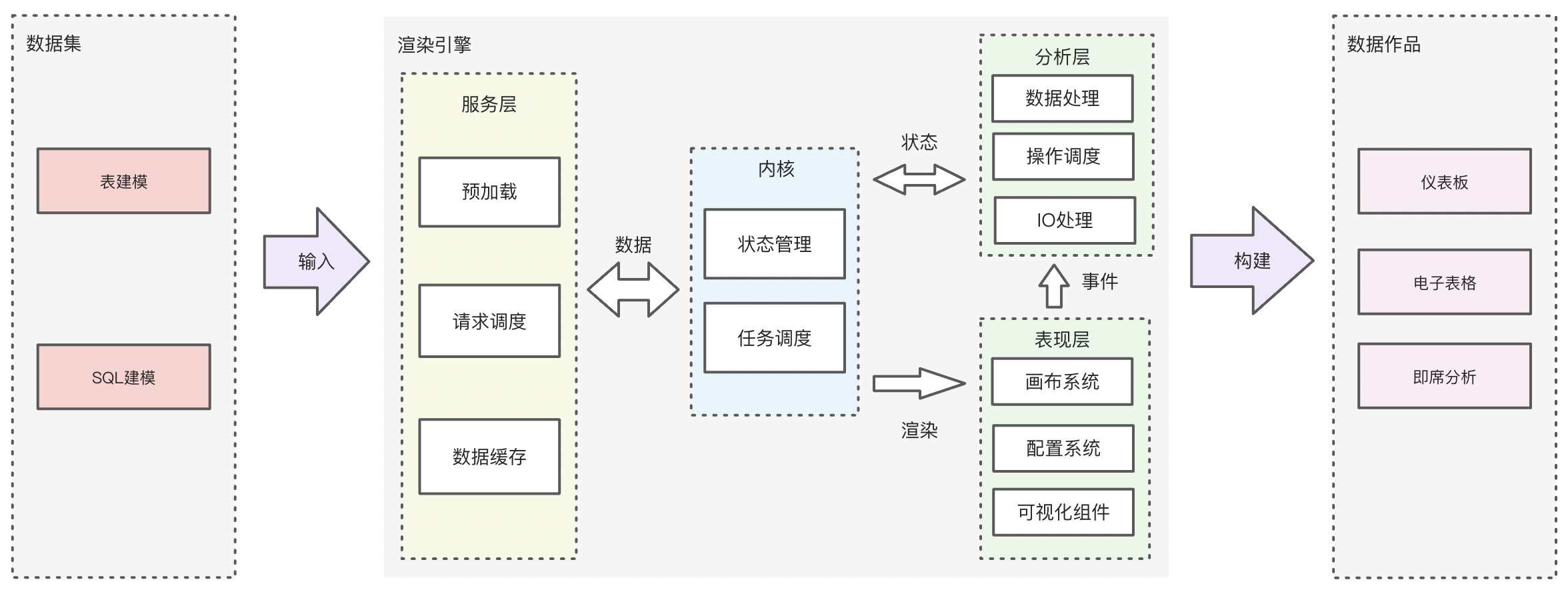
利用五种机制整体提升渲染引擎作业效果
任务调度机制
支持在各段加载和执行流程中利用组件或函数控制CPU时间和网络占用优先级,从而将首屏内容的展示时间点缩短至少了30%。
截流渲染机制
支持Redux类数据流体系,以配置化方式控制单位时间组件渲染次数,组件平均渲染次数减少90%以上。
按需计算机制
按需加载和执行JS逻辑组件及其资源,利用LazyObject思路(即:使用时初始化执行,而非定义时)进行按需调用,LazyCache思路(即:命中时计算和缓存,而非实时)进行数据流模型计算,节省约30%的CPU时间以及40%的网络占用。
预加载机制
通过将原本串行依赖的流程逻辑按不同时机并行(如:当页面拉取JS资源时同时拉取后端数据,在空闲时预加载下一屏内容),根据历史使用习惯预先加载后续可能访问的内容,达到瞬时查看的效果。
资源本地化缓存机制
将js等资源本地化的形式,加上根据不同设备(移动端等)的资源管理策略,有效解决系统内存释放导致的缓存失效,弱网环境导致的资源加载缓慢等问题。
经过一系列核心能力的升级和特定场景的针对性优化,操作平均FPS(每秒传输帧数)可达55左右,较复杂报表下,首屏加载时间也从最初18秒降至3秒以内(中等简单报表2秒内),结合Quick引擎,还可以支持10亿级数据量的报表3秒内展现。
典型场景下的性能体验全面提升
1、数据开发视角的场景方案
(1)报表展示的数据在一定时间内固定不变
有些客户对数据需要每天进行一次汇总,并通过 Quick BI 的可视化图表以日报形式展示出来。这些展示的数据在下一次汇总之前都不会发生变化,同时这些汇总数据比较固定,不需要阅览报表的人主动更改查询条件。
如是场景,推荐开启数据集上的缓存功能。用户可以自行设置缓存的有效期,在有效期内,相同的查询会命中缓存,直接将该周期内第一次查询的结果毫秒级返回。以上述场景为例,用户可以开启 12 小时的缓存,这样日报只会在第一次打开时进行数据查询,之后一整天的时间,一旦客户点击打开,报表就会立刻展现。

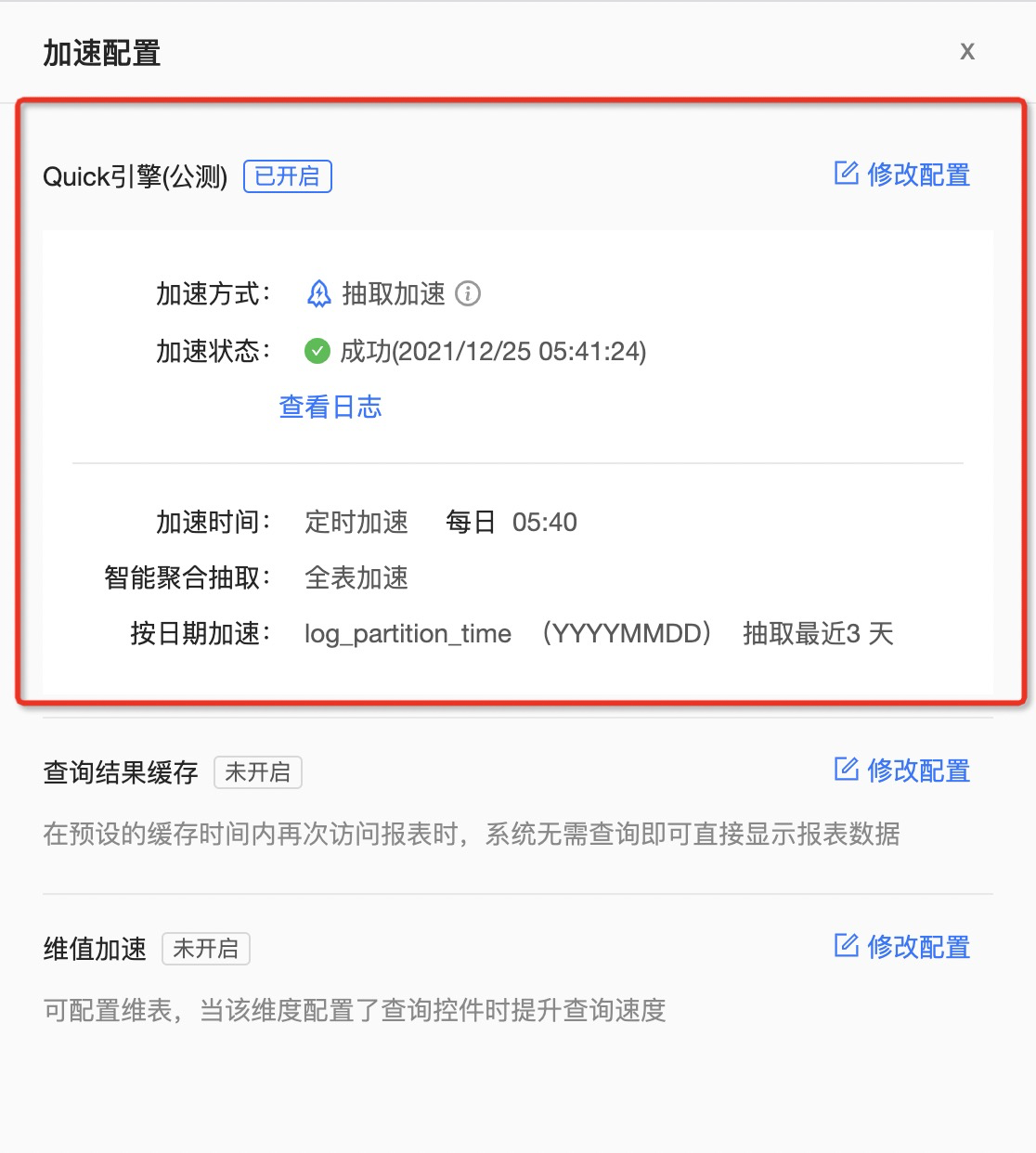
(2)报表数据存在较多变化,对非实时数据进行分析
以大促为例,商家在活动结束后,对大促期间的销量、营业额以及营销投放效果进行复盘。数据分析包含很多维度,比如类目、地区、部门等等。商家的分析师或者决策者在查看报表时,往往会对维度进行调整、变更、钻取,来获得更加深入的洞察。这个场景下用户数据查询的动作多变,上述的缓存策略往往很难命中。
此时,可以在数据集的 Quick 引擎中开启抽取加速。抽取加速默认全表加速,允许用户同步T-1 的数据到 Quick 引擎高性能存储及分析模块中,后续的查询和计算会直接在 Quick 引擎中进行,减少用户数据库的性能压力。抽取加速可以做到亿级数据,亚秒级响应。
与此同时还可以开启智能预计算模式, 会对用户的查询历史进行分析, 提前对可能的查询进行预聚合。用户的查询如果命中,则会直接返回聚合结果。
(3)用户数据源查询慢,但对数据实时性有要求
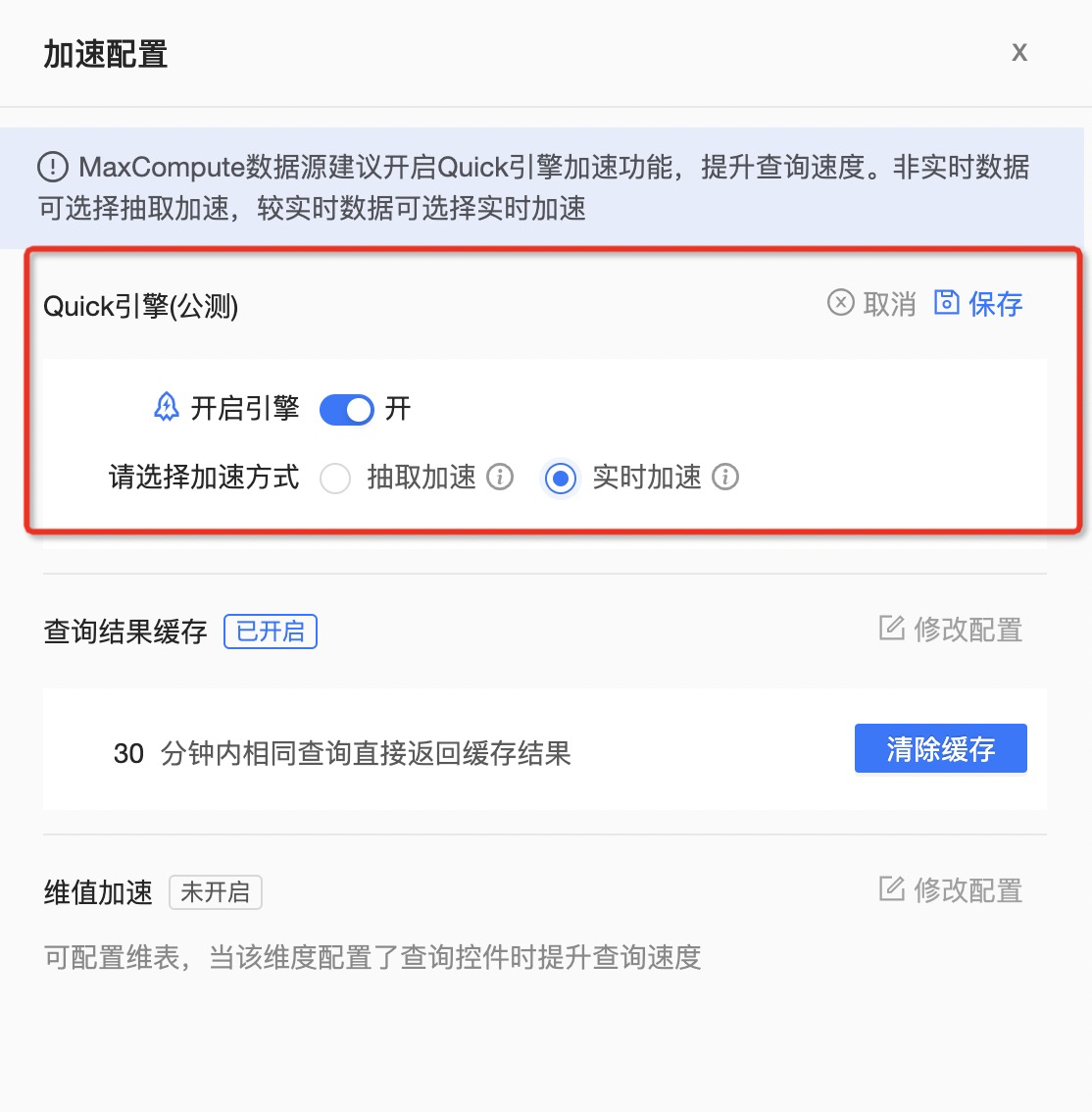
有的用户,数仓里的数据每天都在实时变化。以仓储管理为例,仓库里每天货物的进出是动态的,这些数据会实时落到数据库里,而客户希望能够通过 Quick BI 的报表,对这些动态数据进行分析。显然,上面提到的缓存方案以及抽取加速都无法达成这个目的。
对于这类用户来说,他们可以在数据集的 Quick 引擎里开启实时加速, 通过引擎内置的 MPP 内存计算引擎,对数据进行实时的内存计算,从而达到加速的目的。
开启了 Quick 引擎的实时加速,可以做到亿级数据,秒级响应。
(4)用户查询依赖维度值的获取
企业如果需要以产品类目为维度,对销售记录进行分析。这个时候,就会用到 Quick BI 的查询控件,以下拉列表的方式对“类目”这个维度的值进行展示和选择。
以服装公司为例,共有100 个产品类目,销售记录上千万条。这个时候从完整的销售记录里获取类目值,效率太低。可以使用 Quick BI 提供的维值加速方案, 将类目的维度表配置进维值加速功能,此时100 个类目仅对应 100 行数据,而不再是原来的上千万条。
再获取类目下拉列表时,就会直接从维度表中读取,大大提升下拉列表里维度值的获取效率。

2、Quick BI阅览者视角的加速效果
(1)即席分析表格
500W单元格,秒级渲染完毕(60 FPS),操作流畅:

(2)报表首屏打开
基于双引擎,在1亿行数据,20个图表组件,常规聚合类查询下进行标准测试,一个标准复杂报表可在2秒内展现:

本文为阿里云原创内容,未经允许不得转载。
双引擎驱动Quick BI十亿数据0.3秒分析,首屏展示时间缩短30%的更多相关文章
- 阿里云中quick bi用地图分析数据时维度需转换为地理区域类型
1.到数据集里面点击编辑要做地图分析的数据集 2.找到要分析的地理维度字段,选择转换为对应的类型,这里为市级,所以选择转换为市,其它类似,然后点击右上角保存即可. 3.返回数据集,点击新建仪表板 4. ...
- 数据可视化界面UI设计大屏展示
- 厉害了,ES 如何做到几十亿数据检索 3 秒返回!
一.前言 数据平台已迭代三个版本,从头开始遇到很多常见的难题,终于有片段时间整理一些已完善的文档,在此分享以供所需朋友的 实现参考,少走些弯路,在此篇幅中偏重于ES的优化,关于HBase,Hadoop ...
- [翻译] C# 8.0 新特性 Redis基本使用及百亿数据量中的使用技巧分享(附视频地址及观看指南) 【由浅至深】redis 实现发布订阅的几种方式 .NET Core开发者的福音之玩转Redis的又一傻瓜式神器推荐
[翻译] C# 8.0 新特性 2018-11-13 17:04 by Rwing, 1179 阅读, 24 评论, 收藏, 编辑 原文: Building C# 8.0[译注:原文主标题如此,但内容 ...
- 148_赠送300家门店260亿销售额的零售企业Power BI实战示例数据
焦棚子的文章目录 一背景 2022年即将到来之际,笔者准备在Power BI中做一个实战专题,作为实战专题最基础的就是demo数据,于是我们赠送大家一个300家门店,260亿+销售额,360万行+的零 ...
- 大数据计算:如何仅用1.5KB内存为十亿对象计数
大数据计算:如何仅用1.5KB内存为十亿对象计数 Big Data Counting: How To Count A Billion Distinct Objects Using Only 1.5K ...
- sql索引从入门到精通(十亿行数据测试报告)
原文:sql索引从入门到精通(十亿行数据测试报告) 导读部分 --------------------------------------------------------------------- ...
- 替代或者与 Redis 配合存储十亿级别列表的数据.
http://ssdb.io/docs/zh_cn/index.html 用户案例 如果你在生产环境中使用 SSDB, 欢迎你给我发邮件(ssdb#udpwork.com), 我很愿意把你加入到下面的 ...
- Quick BI 3.0 - 强大的多维分析表格:交叉表
写在开头 对于普通的表格展示数据,相信大家都非常熟悉了,今天给大家介绍的是BI领域的分析利器-交叉表,这个在BI分析场景中使用占比最多的分析利器.通过交叉表对数据的承载和管理,用户可以一目了然地分析出 ...
- 解析如何利用ElasticSearch和Redis检索和存储十亿信息
如果从企业应用的生存率来看,选择企业团队信息作为主要业务,HipChat的起点绝非主流:但是如果从赚钱的角度上看,企业市场的高收益确实值得任何公司追逐,这也正是像JIRA和Confluence这样的智 ...
随机推荐
- View事件机制源码分析
目录介绍 01.Android中事件分发顺序 02.Activity的事件分发机制 2.1 源码分析 2.2 点击事件调用顺序 2.3 得出结论 03.ViewGroup事件的分发机制 3.1 看一下 ...
- ChatGPT 指令大全
1.写报告 报告开头 我现在正在 报告的情境与目的 .我的简报主题是 主题 ,请提供 数字 种开头方式,要简单到 目标族群 能听懂,同时要足够能吸引人,让他们愿意专心听下去. 我现在正在修台大的简报课 ...
- management.endpoints.web.exposure.include
yml配置文件中 management: endpoints: web: exposure: include: '*' properties配置文件中 management.endpoints.web ...
- JSON.stringify() 第三个参数的使用
语法 JSON.stringify(value[, replacer[, space]]) 参数说明: value: 必需, 要转换的 JavaScript 值(通常为对象或数组). replacer ...
- ZYNQ7000系列学习
ZYNQ7000-系列知识学习 一.ZYNQ7000简介 ZYNQ7000是xilinx推出的具有ARM内核的FPGA芯片,可用于常见SOC开发.基于此,通过学习ZYNQ7000的各种设置和开发,可以 ...
- KingbaseES 实现 MySQL 函数 last_insert_id
用户从mysql迁移到金仓数据库过程中,应用中使用了mysql函数last_insert_id()来获取最近insert的那行记录的自增字段值. mysql文档中关于函数的说明和例子: LAST_IN ...
- 基于rv1126 rkmeida 一路多出 原理
基于rv1126 rkmeida 一路多出的坑 首先说要的是介绍一下rkmedia 相关内容 RKMedia提供了一种媒体处理方案,可支持应用软件快速开发.RKMedia在各模块基础API上做进一 ...
- 学习Python前要了解的tips
学习Python前要了解的tips 对后续的学习来说很重要,否则后续会出现一些奇奇怪怪的问题,而且很难找到解决方法.嘿嘿,就不要问我怎么知道的了吧,好多都是我踩过的坑 卸载电脑内软件 之前我一直用电脑 ...
- #模型转换#洛谷 6075 [JSOI2015]子集选取
题目 分析 \(n\)个元素可以独立操作,考虑单个元素, 则选不选择一定有一道分界线, 而这条分界线正好要走\(k\)次, 每次可以选择向上走或向右走,所以为\(2^k\), 由于\(n\)个元素相互 ...
- ArkUI中的线程和看门狗机制
一.前言 本文主要分析ArkUI中涉及的线程和看门狗机制. 二.ArkUI中的线程 应用Ability首次创建界面的流程大致如下: 说明: • AceContainer是一个容器类,由前端.任务执行器 ...