解析SparkStreaming和Kafka集成的两种方式
spark streaming是基于微批处理的流式计算引擎,通常是利用spark core或者spark core与spark sql一起来处理数据。在企业实时处理架构中,通常将spark streaming和kafka集成作为整个大数据处理架构的核心环节之一。
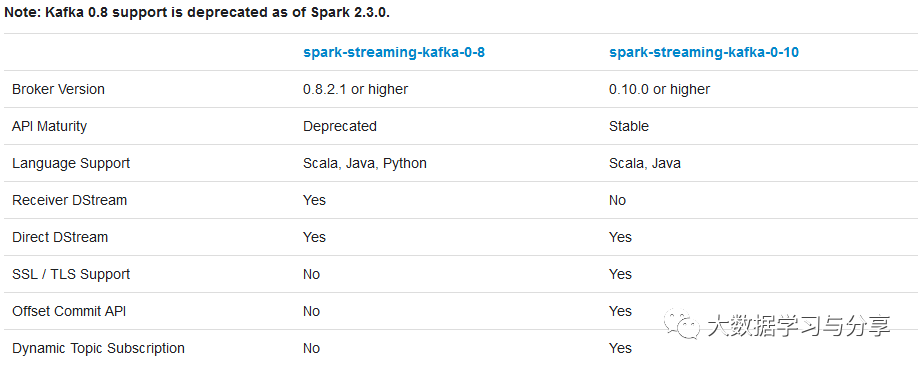
针对不同的spark、kafka版本,集成处理数据的方式分为两种:Receiver based Approach和Direct Approach,不同集成版本处理方式的支持,可参考下图:
Receiver based Approach
基于receiver的方式是使用kafka消费者高阶API实现的。对于所有的receiver,它通过kafka接收的数据会被存储于spark的executors上,底层是写入BlockManager中,默认200ms生成一个block(通过配置参数spark.streaming.blockInterval决定)。然后由spark streaming提交的job构建BlockRdd,最终以spark core任务的形式运行。关于receiver方式,有以下几点需要注意:
1. receiver作为一个常驻线程调度到executor上运行,占用一个cpu
2. receiver个数由KafkaUtils.createStream调用次数决定,一次一个receiver
3. kafka中的topic分区并不能关联产生在spark streaming中的rdd分区增加在KafkaUtils.createStream()中的指定的topic分区数,仅仅增加了单个receiver消费的topic的线程数,它不会增加处理数据中的并行的spark的数量【topicMap[topic,num_threads]map的value对应的数值是每个topic对应的消费线程数】
4. receiver默认200ms生成一个block,建议根据数据量大小调整block生成周期
5. receiver接收的数据会放入到BlockManager,每个executor都会有一个BlockManager实例,由于数据本地性,那些存在receiver的executor会被调度执行更多的task,就会导致某些executor比较空闲
建议通过参数spark.locality.wait调整数据本地性。该参数设置的不合理,比如设置为10而任务2s就处理结束,就会导致越来越多的任务调度到数据存在的executor上执行,导致任务执行缓慢甚至失败(要和数据倾斜区分开)
6. 多个kafka输入的DStreams可以使用不同的groups、topics创建,使用多个receivers接收处理数据
7. 两种receiver
可靠的receiver:可靠的receiver在接收到数据并通过复制机制存储在spark中时准确的向可靠的数据源发送ack确认
不可靠的receiver:不可靠的receiver不会向数据源发送数据已接收确认。这适用于用于不支持ack的数据源当然,我们也可以自定义receiver。
8. receiver处理数据可靠性默认情况下,receiver是可能丢失数据的
可以通过设置spark.streaming.receiver.writeAheadLog.enable为true开启预写日志机制,将数据先写入一个可靠地分布式文件系统如hdfs,确保数据不丢失,但会失去一定性能
9. 限制消费者消费的最大速率
涉及三个参数:
spark.streaming.backpressure.enabled:默认是false,设置为true,就开启了背压机制
spark.streaming.backpressure.initialRate:默认没设置初始消费速率,第一次启动时每个receiver接收数据的最大值
spark.streaming.receiver.maxRate:默认值没设置,每个receiver接收数据的最大速率(每秒记录数)。每个流每秒最多将消费此数量的记录,将此配置设置为0或负数将不会对最大速率进行限制
10. 在产生job时,会将当前job有效范围内的所有block组成一个BlockRDD,一个block对应一个分区
11. kafka082版本消费者高阶API中,有分组的概念,建议使消费者组内的线程数(消费者个数)和kafka分区数保持一致。如果多于分区数,会有部分消费者处于空闲状态
Direct Approach
direct approach是spark streaming不使用receiver集成kafka的方式,一般在企业生产环境中使用较多。相较于receiver,有以下特点:
1. 不使用receiver
a. 不需要创建多个kafka streams并聚合它们
b. 减少不必要的CPU占用
c. 减少了receiver接收数据写入BlockManager,然后运行时再通过blockId、网络传输、磁盘读取等来获取数据的整个过程,提升了效率
d. 无需wal,进一步减少磁盘IO操作
2. direct方式生的rdd是KafkaRDD,它的分区数与kafka分区数保持一致一样多的rdd分区来消费,更方便我们对并行度进行控制注意:在shuffle或者repartition操作后生成的rdd,这种对应关系会失效
3. 可以手动维护offset,实现exactly once语义
4. 数据本地性问题。在KafkaRDD在compute函数中,使用SimpleConsumer根据指定的topic、分区、offset去读取kafka数据。但在010版本后,又存在假如kafka和spark处于同一集群存在数据本地性的问题
5. 限制消费者消费的最大速率
spark.streaming.kafka.maxRatePerPartition:从每个kafka分区读取数据的最大速率(每秒记录数)。这是针对每个分区进行限速,需要事先知道kafka分区数,来评估系统的吞吐量
关注微信公众号:大数据学习与分享,获取更对技术干货
解析SparkStreaming和Kafka集成的两种方式的更多相关文章
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- SparkStreaming获取kafka数据的两种方式:Receiver与Direct
简介: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以简单理解成: Receiver方式是通过zookeeper来连接kafka队列, Dire ...
- Spark-Streaming获取kafka数据的两种方式:Receiver与Direct的方式
简单理解为:Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据 Receiver 使用Kafka的高层次Consumer API来 ...
- spark-streaming获取kafka数据的两种方式
简单理解为:Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据 一.Receiver方式: 使用kafka的高层次Consumer ...
- 工具篇-Spark-Streaming获取kafka数据的两种方式(转载)
转载自:https://blog.csdn.net/weixin_41615494/article/details/7952173 一.基于Receiver的方式 原理 Receiver从Kafka中 ...
- spring boot集成pagehelper(两种方式)
当spring boot集成好mybatis时候需要进行分页,我们首先添加maven支持 <dependency> <groupId>com.github.pagehelper ...
- Java解析Json数据的两种方式
JSON数据解析的有点在于他的体积小,在网络上传输的时候可以更省流量,所以使用越来越广泛,下面介绍使用JsonObject和JsonArray的两种方式解析Json数据. 使用以上两种方式解析json ...
- sparkStreaming读取kafka的两种方式
概述 Spark Streaming 支持多种实时输入源数据的读取,其中包括Kafka.flume.socket流等等.除了Kafka以外的实时输入源,由于我们的业务场景没有涉及,在此将不会讨论.本篇 ...
- spark-streaming-连接kafka的两种方式
推荐系统的在线部分往往使用spark-streaming实现,这是一个很重要的环节. 在线流程的实时数据一般是从kafka获取消息到spark streaming spark连接kafka两种方式在面 ...
随机推荐
- swagger2注解详细说明
@Api:用在请求的类上,表示对类的说明 tags="说明该类的作用,可以在UI界面上看到的注解" value="该参数没什么意义,在UI界面上也看到,所以不需要配置&q ...
- Shell学习(二)Shell变量
一.Shell变量 变量的定义 例子: my_job="Learn Shell" PS:变量名和等号之间不能有空格!!! 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头 ...
- 利用new Object方式创建对象
var obj = new Object(); //创建了一个空的对象obj.uname = 'zhangsanfeng';obj.name = 18; //字面量方式创建对象不 ...
- 如何高雅的使用redis去获取一个值
//场景,给定一个订单号来从缓存中查询一个订单信息; 步骤: 1从redis中直接获取,有数据就返回 2.如果redis中没有值,就查数据库 3.数据库查到的数据不为空,就刷到redis中 4.返回查 ...
- Java基于POI实现excel任意多级联动下拉列表——支持从数据库查询出多级数据后直接生成【附源码】
Excel相关知识点 (1)名称管理器--Name Manager [CoderBaby]首先需要创建多个名称(包含key及value),作为下拉列表的数据源,后续通过名称引用.可通过菜单:&quo ...
- 082 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 02 构造方法介绍 01 构造方法-无参构造方法
082 01 Android 零基础入门 02 Java面向对象 01 Java面向对象基础 02 构造方法介绍 01 构造方法-无参构造方法 本文知识点:构造方法-无参构造方法 说明:因为时间紧张, ...
- matlab中num2str 将数字转换为字符数组
参考:https://ww2.mathworks.cn/help/matlab/ref/num2str.html?searchHighlight=num2str&s_tid=doc_srcht ...
- Jmeter5.3源码编译
下载源码 https://jmeter.apache.org/download_jmeter.cgi 配置网络环境(重要) 下载 Proxifier 配置上网条件 导入Idea 通过 Idea 的 O ...
- Django Croppie
下载 Django CroppieDjango Croppie django -croppie是一个简单集成croppie.js图像cropper到django项目的应用程序. 安装 安装与pip安装 ...
- Prometheus第一篇:Prometheus架构解析
Prometheus是新一代的监控系统解决方案,原生支持云环境,和kubernetes无缝对接,的却是容器化监控解决方案的不二之选.当然对传统的监控方案也能够兼容,通过自定义或是用开源社区提供的各种e ...