简述HBase的Bulk Load
为什么用Bulk load?
批量加载数据到HBase集群,有很多种方式,比如利用 HBase API 进行批量写入数据、使用Sqoop工具批量导数到HBase集群、使用MapReduce批量导入等等,但是这些方法都有一个问题:导入数据的过程如果数据量过大,可能耗时会比较严重或者占用HBase集群资源较多(如磁盘IO、HBase Handler数等)
使用 HBase BulkLoad的方式来进行海量数据批量写入到HBase集群,可以对大数据量的情况下做一些优化,提高性能。
在使用BulkLoad之前,我们先来了解一下HBase的存储机制。HBase存储数据其底层使用的是HDFS来作为存储介质,HBase的每一张表对应的HDFS目录上的一个文件夹,文件夹名以HBase表进行命名(如果没有使用命名空间,则默认在default目录下),在表文件夹下存放在若干个Region命名的文件夹,Region文件夹中的每个列簇也是用文件夹进行存储的,每个列簇中存储就是实际的数据,以HFile的形式存在,路径格式如下:
/hbase/data/default/<tbl_name>/<region_id>/<cf>/<hfile_id>
实现原理
按照HBase存储数据按照HFile格式存储在HDFS的原理,使用MapReduce直接生成HFile格式的数据文件,然后在通过RegionServer将HFile数据文件移动到相应的Region上面,实现流程如图所示:
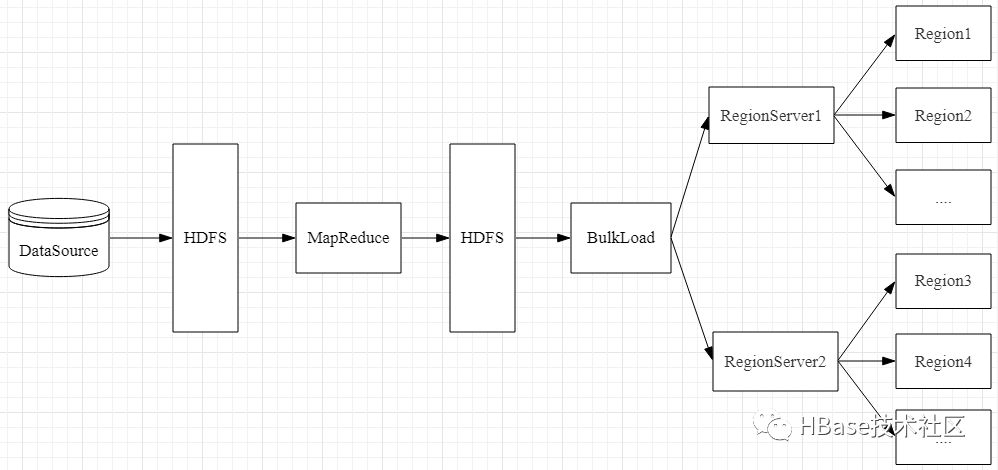
生成HFile文件
HFile文件的生成,可以使用MapReduce来进行实现,将数据源准备好,上传到HDFS进行存储,然后在程序中读取HDFS上的数据源,进行自定义封装,组装RowKey,然后将封装后的数据在回写到HDFS上,以HFile的形式存储到HDFS指定的目录中。实现代码:
public class GemeratorHFile2 {
static class HFileImportMapper2 extends Mapper<LongWritable, Text, ImmutableBytesWritable, KeyValue> {
protected final String CF_KQ = "cf";
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println("line : " + line);
String[] datas = line.split(" ");
String row = new Date().getTime() + "_" + datas[1];
ImmutableBytesWritable rowkey = new ImmutableBytesWritable(Bytes.toBytes(row));
KeyValue kv = new KeyValue(Bytes.toBytes(row), this.CF_KQ.getBytes(), datas[1].getBytes(), datas[2].getBytes());
context.write(rowkey, kv);
}
}
public static void main(String[] args) {
if (args.length != 1) {
System.out.println("<Usage>Please input hbase-site.xml path.</Usage>");
return;
}
Configuration conf = new Configuration();
conf.addResource(new Path(args[0]));
conf.set("hbase.fs.tmp.dir", "partitions_" + UUID.randomUUID());
String tableName = "person";
String input = "hdfs://nna:9000/tmp/person.txt";
String output = "hdfs://nna:9000/tmp/pres";
System.out.println("table : " + tableName);
HTable table;
try {
try {
FileSystem fs = FileSystem.get(URI.create(output), conf);
fs.delete(new Path(output), true);
fs.close();
} catch (IOException e1) {
e1.printStackTrace();
}
Connection conn = ConnectionFactory.createConnection(conf);
table = (HTable) conn.getTable(TableName.valueOf(tableName));
Job job = Job.getInstance(conf);
job.setJobName("Generate HFile");
job.setJarByClass(GemeratorHFile2.class);
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(HFileImportMapper2.class);
FileInputFormat.setInputPaths(job, input);
FileOutputFormat.setOutputPath(job, new Path(output));
HFileOutputFormat2.configureIncrementalLoad(job, table);
try {
job.waitForCompletion(true);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
在HDFS目录/tmp/person.txt中,准备数据源如下:
1 smartloli 100
2 smartloli2 101
3 smartloli3 102
然后将上述代码编译打包成jar,上传到Hadoop集群进行执行,执行以下命令:
hadoop jar GemeratorHFile2.jar /data/soft/new/apps/hbaseapp/hbase-site.xml
如果在执行命令的过程中,出现找不到类的异常信息,可能是本地没有加载HBase依赖jar包,当前用户配置如下环境变量信息:
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*:classpath
然后执行source命令使配置的内容立即生效。
执行预览
成功提交任务Linux控制台打印执行任务进度,也可以到YARN的资源监控界面查看执行进度,结果如图所示:
等待任务的执行,执行完成后在对应HDFS路径上会生成相应的HFile数据文件,如图所示:
使用BulkLoad导入到HBase
使用BulkLoad的方式将生成的HFile文件导入到HBase集群中,这里有两种导入方式。一种是写代码实现导入,另一种是使用HBase命令进行导入。
写代码实现导入
通过LoadIncrementalHFiles类来实现导入,具体代码:
public class BulkLoad2HBase {
public static void main(String[] args) throws Exception {
if (args.length != 1) {
System.out.println("<Usage>Please input hbase-site.xml path.</Usage>");
return;
}
String output = "hdfs://cluster1/tmp/pres";
Configuration conf = new Configuration();
conf.addResource(new Path(args[0]));
HTable table = new HTable(conf, "person");
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(conf);
loader.doBulkLoad(new Path(output), table);
}
}
执行上述代码运行结果:
使用HBase命令进行导入
先将生成好的HFile文件迁移到目标集群(即HBase集群所在的HDFS上),然后使用HBase命令进行导入,执行以下命令:
# 先使用distcp迁移hfile
hadoop distcp -Dmapreduce.job.queuename=queue_1024_01 -update -skipcrccheck -m 10 /tmp/pres hdfs://nns:9000/tmp/pres
# 使用bulkload方式导入数据
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /tmp/pres person
最后,我们可以到指定的RegionServer节点上查看导入的日志信息,导入成功的日志信息:
2018-08-19 16:30:34,969 INFO [B.defaultRpcServer.handler=7,queue=1,port=16020] regionserver.HStore: Successfully loaded store file hdfs://cluster1/tmp/pres/cf/7b455535f660444695589edf509935e9 into store cf (new location: hdfs://cluster1/hbase/data/default/person/2d7483d4abd6d20acdf16533a3fdf18f/cf/d72c8846327d42e2a00780ac2facf95b_SeqId_4_)
2.5 验证
使用BulkLoad方式导入数据后,可以进入到HBase集群,使用HBase Shell来查看数据是否导入成功,预览结果如图所示:

总结
本篇文章为了演示实战效果,将生成HFile文件和使用BulkLoad方式导入HFile到HBase集群的步骤进行分解,实际情况可以将这两个步骤合并为一个,实现自动化生成与HFile自动导入。如果在执行的过程中出现RpcRetryingCaller的异常,可以到对应RegionServer节点查看日志信息,这里面记录出现这种异常的详细原因。
简述HBase的Bulk Load的更多相关文章
- 【hbase】——bulk load导入数据时value=\x00\x00\x00\x01问题解析
一.存入数据类型 Hbase里面,rowkey是按照字典序进行排序.存储的value值,当用filter进行数据筛选的时候,所用的比较算法也是字典序的. 1.当存储的value值是float类型的时候 ...
- Bulk Load-HBase数据导入最佳实践
一.概述 HBase本身提供了非常多种数据导入的方式,通常有两种经常使用方式: 1.使用HBase提供的TableOutputFormat,原理是通过一个Mapreduce作业将数据导入HBase 2 ...
- 图解JanusGraph系列 - 关于JanusGraph图数据批量快速导入的方案和想法(bulk load data)
大家好,我是洋仔,JanusGraph图解系列文章,实时更新~ 图数据库文章总目录: 整理所有图相关文章,请移步(超链):图数据库系列-文章总目录 源码分析相关可查看github(码文不易,求个sta ...
- MySQL Backup--xtrabackup与Bulk Load for Create Index
场景描述:主从使用MySQL 5.7.19 1.从库上使用xtrabackup进行热备. 2.主库行执行DDL创建索引: ALTER TABLE `tb_xxx` ADD INDEX idx_good ...
- Spark写入HBase(Bulk方式)
在使用Spark时经常需要把数据落入HBase中,如果使用普通的Java API,写入会速度很慢.还好Spark提供了Bulk写入方式的接口.那么Bulk写入与普通写入相比有什么优势呢? BulkLo ...
- Using SQLXML Bulk Load in the .NET Environment
http://msdn.microsoft.com/en-us/library/ms171878.aspx 1.首先创建一张表 CREATE TABLE Ord ( OrderID ,) PRIMAR ...
- 【hbase】——HBase 写优化之 BulkLoad 实现数据快速入库
1.为何要 BulkLoad 导入?传统的 HTableOutputFormat 写 HBase 有什么问题? 我们先看下 HBase 的写流程: 通常 MapReduce 在写HBase时使用的是 ...
- hbase运行mapreduce设置及基本数据加载方法
hbase与mapreduce集成后,运行mapreduce程序,同时需要mapreduce jar和hbase jar文件的支持,这时我们需要通过特殊设置使任务可以同时读取到hadoop jar和h ...
- 批量导入数据到HBase
hbase一般用于大数据的批量分析,所以在很多情况下需要将大量数据从外部导入到hbase中,hbase提供了一种导入数据的方式,主要用于批量导入大量数据,即importtsv工具,用法如下: Us ...
随机推荐
- Python三引号
Python三引号:多用作注释.数据库语句.编写 HTML 文本. strs = ''' 使用了三引号的字符串 ''' print (strs) # 在 ‘’‘ 里可以使用转义字符 strs = '' ...
- Python os.tmpnam() 方法
概述 os.tmpnam() 方法用于为创建一个临时文件返回一个唯一的路径.高佣联盟 www.cgewang.com 语法 tmpnam()方法语法格式如下: os.tmpnam 参数 无 返回值 返 ...
- PHP date_timezone_set() 函数
------------恢复内容开始------------ 实例 设置 DateTime 对象的时区: <?php$date=date_create("2013-05-25" ...
- PHP preg_replace() 函数
preg_replace 函数执行一个正则表达式的搜索和替换.高佣联盟 www.cgewang.com 语法 mixed preg_replace ( mixed $pattern , mixed $ ...
- luogu P5633 最小度限制生成树 wqs二分
LINK:最小度限制生成树 还是WQS二分的模板题 不过相当于我WQS二分的复习题. 对于求出强制k个的答案 dp能做不过复杂度太高了. 世界上定义F(x)表示选出x个的答案 画成图像 其实形成了一个 ...
- bzoj 4448 [Scoi2015]情报传递 主席树
比较套路的题目. 可以发现难点在于某个点的权值动态修改 且我们要维护树上一条路径上的点权>x的个数. 每个点都在动态修改 这意味着我们的只能暴力的去查每个点. 考虑将所有可以动态修改的点变成静态 ...
- OKHttp 官方文档【二】
OkHttp 是这几年比较流行的 Http 客户端实现方案,其支持HTTP/2.支持同一Host 连接池复用.支持Http缓存.支持自动重定向 等等,有太多的优点. 一直想找时间了解一下 OkHttp ...
- Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.8.1:testCompile (default-testCompile) on project docker_springcloud_demo: Fatal error compiling: 无效的标记: -parameters -> [Help 1]
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.8.1:testCompile (def ...
- 打开桌面的Eclipse闪退,打不开
参考了网上说的方法: .在C:/WINDOWS/system32 系统文件夹中ctrl+F 然后搜索java.exe,如果存在java.exe, javaw.exe etc.全部删除. 2.内存不足, ...
- Android Studio--家庭记账本(四)
今天,实现了在数据库中的删除功能,但是无法实现对表单的删除与自动更新.需要重新启动虚拟机重新从数据库中读取数据才可以实现表单的更新.List表单中的remove功能不太会用.